 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Based Progressive Distillation for Adder Neural Networks
Oct 15, 2020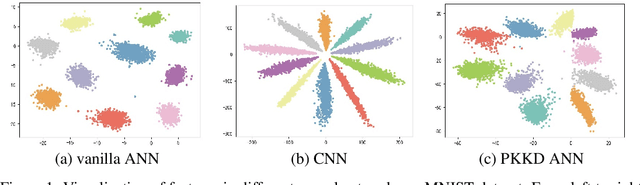
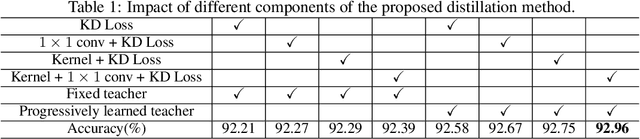
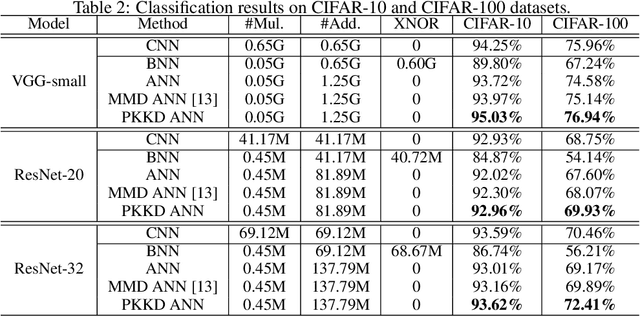
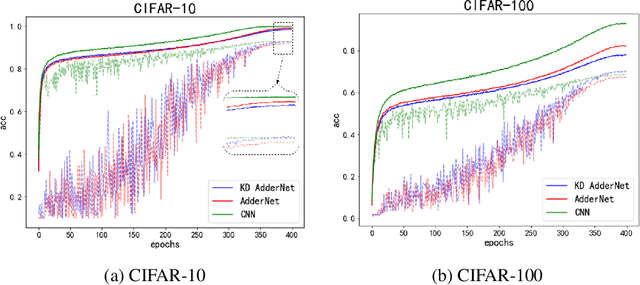
Adder Neural Networks (ANNs) which only contain additions bring us a new way of developing deep neural networks with low energy consumption. Unfortunately, there is an accuracy drop when replacing all convolution filters by adder filters. The main reason here is the optimization difficulty of ANNs using $\ell_1$-norm, in which the estimation of gradient in back propagation is inaccurate. In this paper, we present a novel method for further improving the performance of ANNs without increasing the trainable parameters via a progressive kernel based knowledge distillation (PKKD) method. A convolutional neural network (CNN) with the same architecture is simultaneously initialized and trained as a teacher network, features and weights of ANN and CNN will be transformed to a new space to eliminate the accuracy drop. The similarity is conducted in a higher-dimensional space to disentangle the difference of their distributions using a kernel based method. Finally, the desired ANN is learned based on the information from both the ground-truth and teacher, progressively. The effectiveness of the proposed method for learning ANN with higher performance is then well-verified on several benchmarks. For instance, the ANN-50 trained using the proposed PKKD method obtains a 76.8\% top-1 accuracy on ImageNet dataset, which is 0.6\% higher than that of the ResNet-50.
Training Binary Neural Networks through Learning with Noisy Supervision
Oct 10, 2020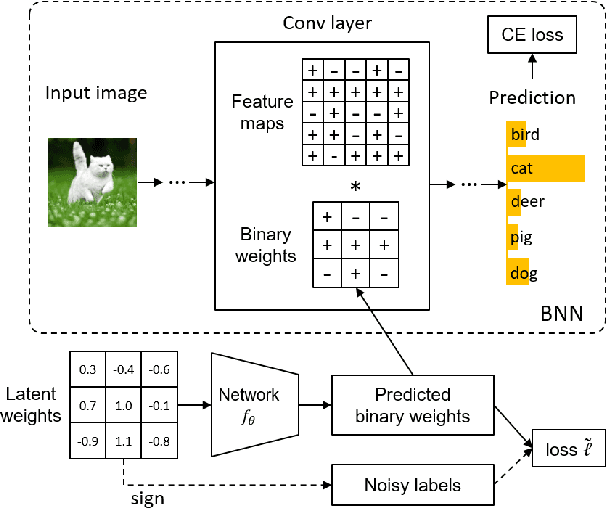

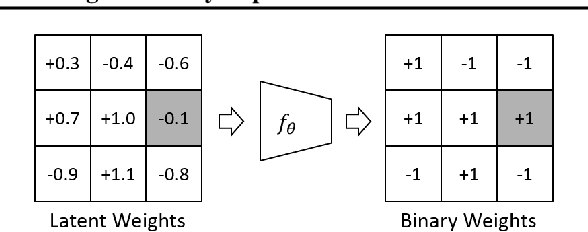
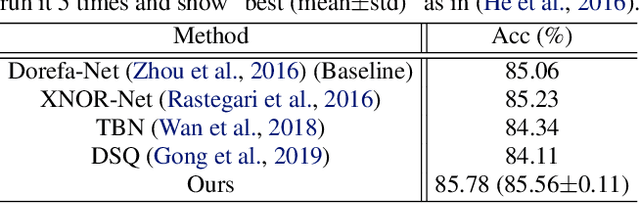
This paper formalizes the binarization operations over neural networks from a learning perspective. In contrast to classical hand crafted rules (\eg hard thresholding) to binarize full-precision neurons, we propose to learn a mapping from full-precision neurons to the target binary ones. Each individual weight entry will not be binarized independently. Instead, they are taken as a whole to accomplish the binarization, just as they work together in generating convolution features. To help the training of the binarization mapping, the full-precision neurons after taking sign operations is regarded as some auxiliary supervision signal, which is noisy but still has valuable guidance. An unbiased estimator is therefore introduced to mitigate the influence of the supervision noise. Experimental results on benchmark datasets indicate that the proposed binarization technique attains consistent improvements over baselines.
AdderSR: Towards Energy Efficient Image Super-Resolution
Sep 27, 2020
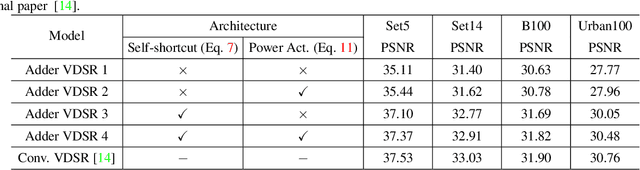

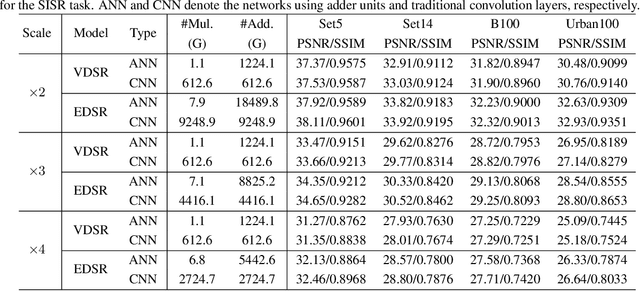
This paper studies the single image super-resolution problem using adder neural networks (AdderNet). Compared with convolutional neural networks, AdderNet utilizing additions to calculate the output features thus avoid massive energy consumptions of conventional multiplications. However, it is very hard to directly inherit the existing success of AdderNet on large-scale image classification to the image super-resolution task due to the different calculation paradigm. Specifically, the adder operation cannot easily learn the identity mapping, which is essential for image processing tasks. In addition, the functionality of high-pass filters cannot be ensured by AdderNet. To this end, we thoroughly analyze the relationship between an adder operation and the identity mapping and insert shortcuts to enhance the performance of SR models using adder networks. Then, we develop a learnable power activation for adjusting the feature distribution and refining details. Experiments conducted on several benchmark models and datasets demonstrate that, our image super-resolution models using AdderNet can achieve comparable performance and visual quality to that of their CNN baselines with an about 2$\times$ reduction on the energy consumption.
Searching for Low-Bit Weights in Quantized Neural Networks
Sep 18, 2020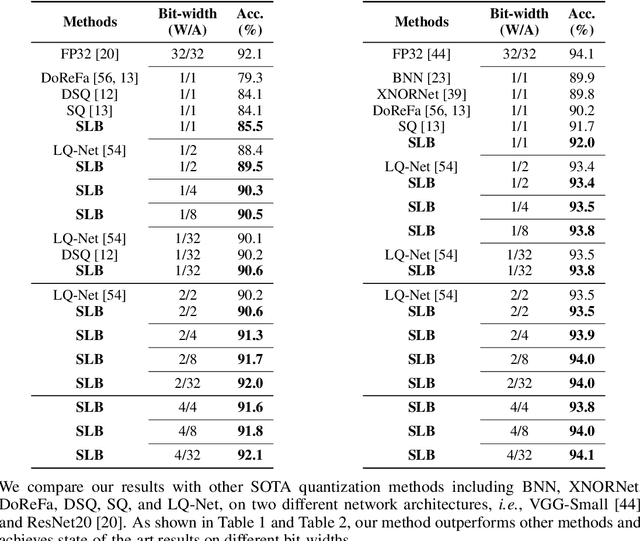
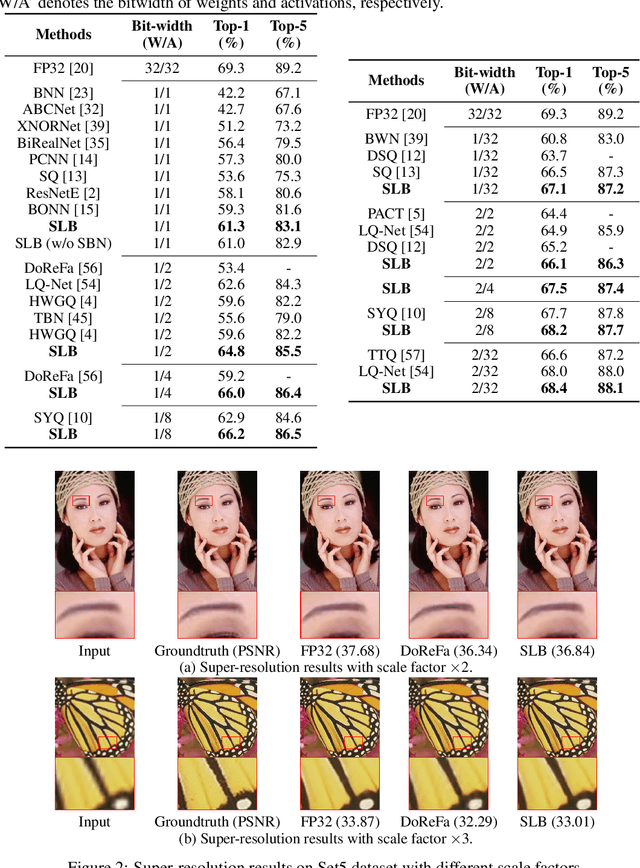
Quantized neural networks with low-bit weights and activations are attractive for developing AI accelerators. However, the quantization functions used in most conventional quantization methods are non-differentiable, which increases the optimization difficulty of quantized networks. Compared with full-precision parameters (i.e., 32-bit floating numbers), low-bit values are selected from a much smaller set. For example, there are only 16 possibilities in 4-bit space. Thus, we present to regard the discrete weights in an arbitrary quantized neural network as searchable variables, and utilize a differential method to search them accurately. In particular, each weight is represented as a probability distribution over the discrete value set. The probabilities are optimized during training and the values with the highest probability are selected to establish the desired quantized network. Experimental results on benchmarks demonstrate that the proposed method is able to produce quantized neural networks with higher performance over the state-of-the-art methods on both image classification and super-resolution tasks.
Video Super-resolution with Temporal Group Attention
Jul 21, 2020
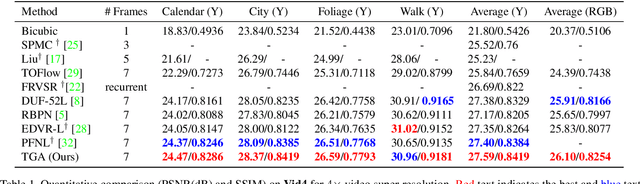
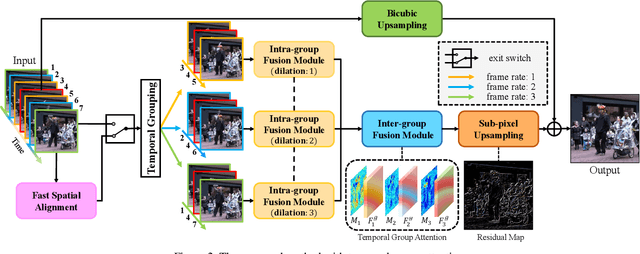

Video super-resolution, which aims at producing a high-resolution video from its corresponding low-resolution version, has recently drawn increasing attention. In this work, we propose a novel method that can effectively incorporate temporal information in a hierarchical way. The input sequence is divided into several groups, with each one corresponding to a kind of frame rate. These groups provide complementary information to recover missing details in the reference frame, which is further integrated with an attention module and a deep intra-group fusion module. In addition, a fast spatial alignment is proposed to handle videos with large motion. Extensive results demonstrate the capability of the proposed model in handling videos with various motion. It achieves favorable performance against state-of-the-art methods on several benchmark datasets.
Multi-Task Pruning for Semantic Segmentation Networks
Jul 16, 2020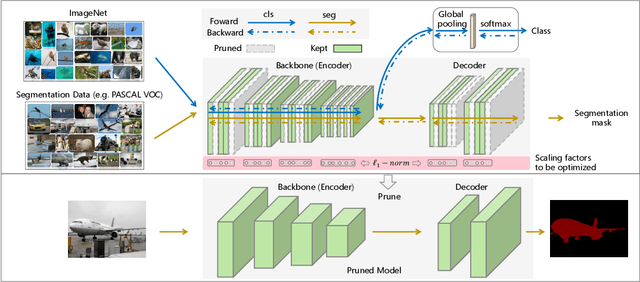

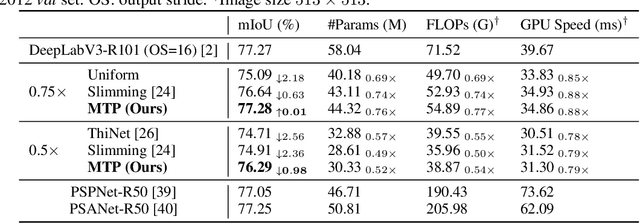
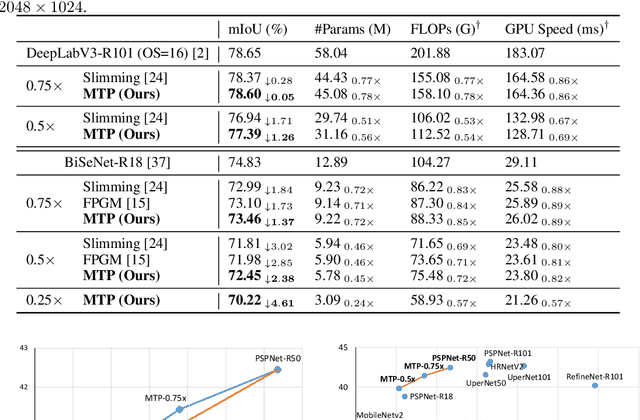
This paper focuses on channel pruning for semantic segmentation networks. There are a large number of works to compress and accelerate deep neural networks in the classification task (e.g., ResNet-50 on ImageNet), but they cannot be straightforwardly applied to the semantic segmentation network that involves an implicit multi-task learning problem. To boost the segmentation performance, the backbone of semantic segmentation network is often pre-trained on a large scale classification dataset (e.g., ImageNet), and then optimized on the desired segmentation dataset. Hence to identify the redundancy in segmentation networks, we present a multi-task channel pruning approach. The importance of each convolution filter w.r.t the channel of an arbitrary layer will be simultaneously determined by the classification and segmentation tasks. In addition, we develop an alternative scheme for optimizing importance scores of filters in the entire network. Experimental results on several benchmarks illustrate the superiority of the proposed algorithm over the state-of-the-art pruning methods. Notably, we can obtain an about $2\times$ FLOPs reduction on DeepLabv3 with only an about $1\%$ mIoU drop on the PASCAL VOC 2012 dataset and an about $1.3\%$ mIoU drop on Cityscapes dataset, respectively.
Optical Flow Distillation: Towards Efficient and Stable Video Style Transfer
Jul 10, 2020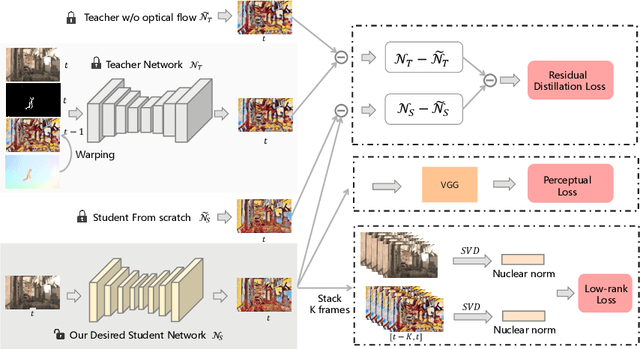
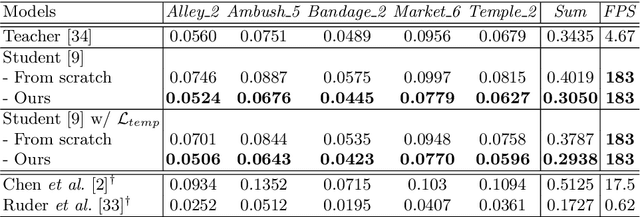
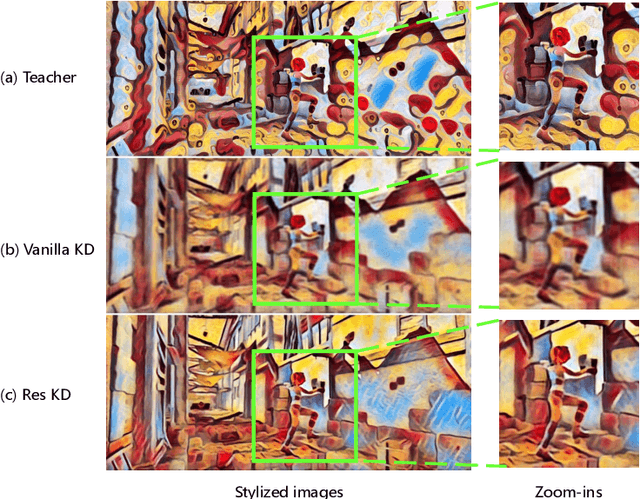
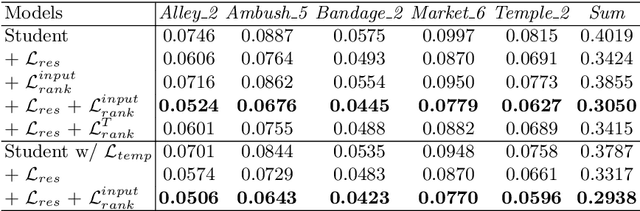
Video style transfer techniques inspire many exciting applications on mobile devices. However, their efficiency and stability are still far from satisfactory. To boost the transfer stability across frames, optical flow is widely adopted, despite its high computational complexity, e.g. occupying over 97% inference time. This paper proposes to learn a lightweight video style transfer network via knowledge distillation paradigm. We adopt two teacher networks, one of which takes optical flow during inference while the other does not. The output difference between these two teacher networks highlights the improvements made by optical flow, which is then adopted to distill the target student network. Furthermore, a low-rank distillation loss is employed to stabilize the output of student network by mimicking the rank of input videos. Extensive experiments demonstrate that our student network without an optical flow module is still able to generate stable video and runs much faster than the teacher network.
HourNAS: Extremely Fast Neural Architecture Search Through an Hourglass Lens
Jun 04, 2020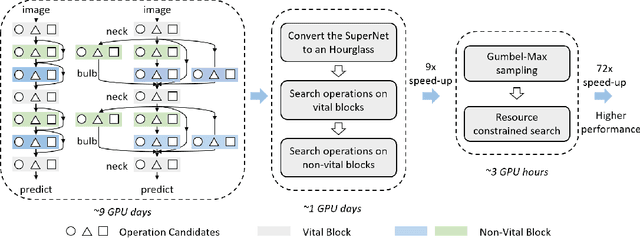
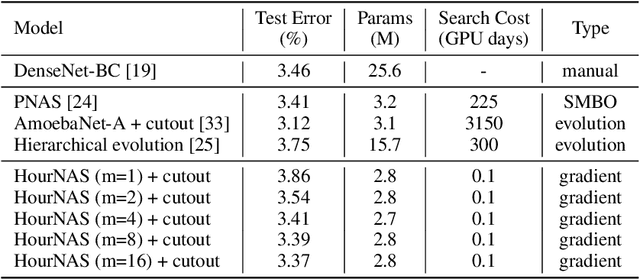
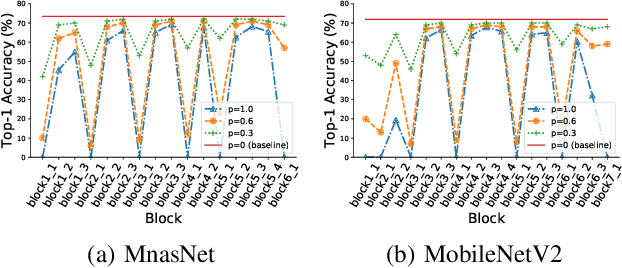
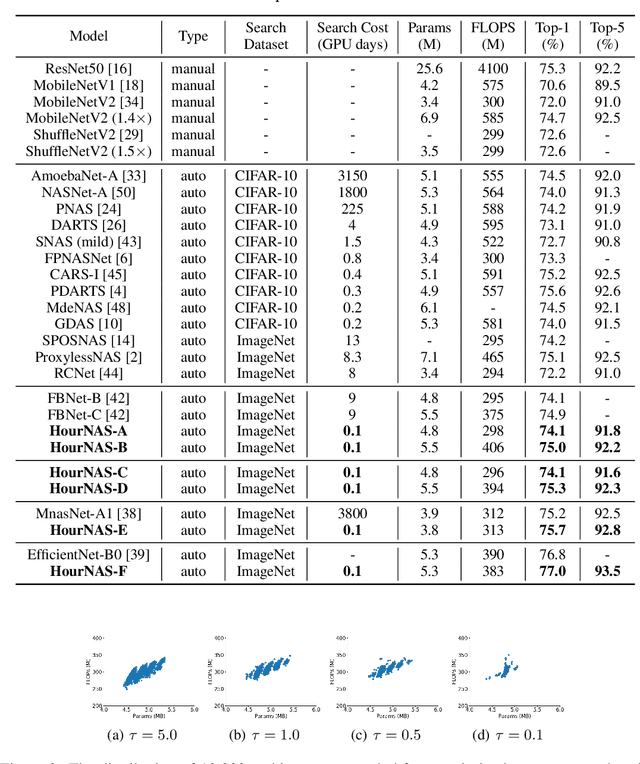
Neural Architecture Search (NAS) refers to automatically design the architecture. We propose an hourglass-inspired approach (HourNAS) for this problem that is motivated by the fact that the effects of the architecture often proceed from the vital few blocks. Acting like the narrow neck of an hourglass, vital blocks in the guaranteed path from the input to the output of a deep neural network restrict the information flow and influence the network accuracy. The other blocks occupy the major volume of the network and determine the overall network complexity, corresponding to the bulbs of an hourglass. To achieve an extremely fast NAS while preserving the high accuracy, we propose to identify the vital blocks and make them the priority in the architecture search. The search space of those non-vital blocks is further shrunk to only cover the candidates that are affordable under the computational resource constraints. Experimental results on the ImageNet show that only using 3 hours (0.1 days) with one GPU, our HourNAS can search an architecture that achieves a 77.0% Top-1 accuracy, which outperforms the state-of-the-art methods.
A Semi-Supervised Assessor of Neural Architectures
May 14, 2020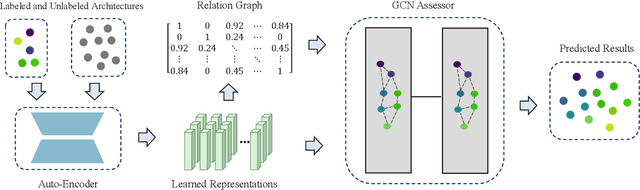
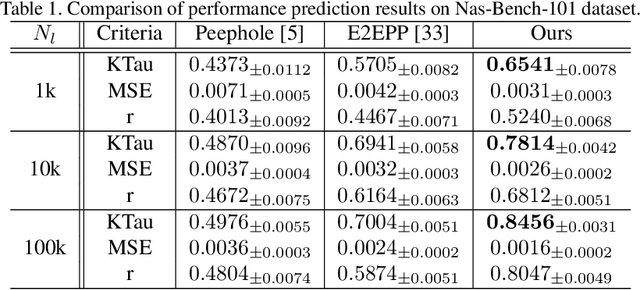
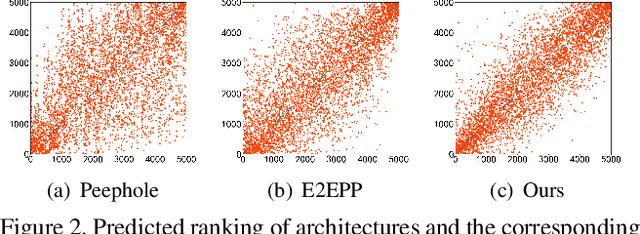
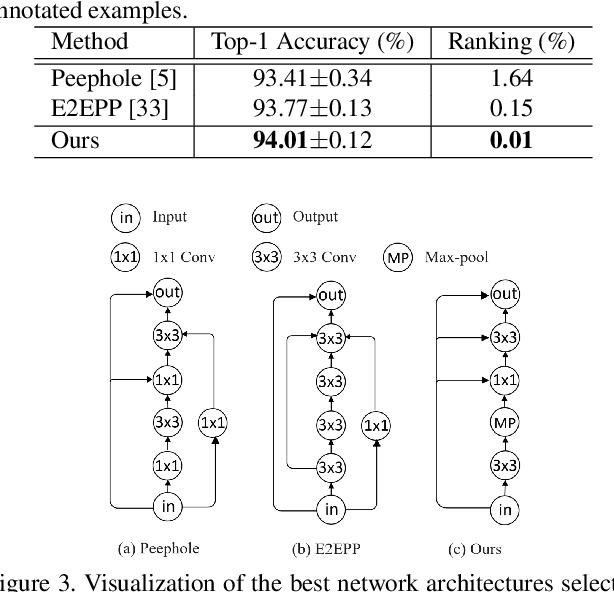
Neural architecture search (NAS) aims to automatically design deep neural networks of satisfactory performance. Wherein, architecture performance predictor is critical to efficiently value an intermediate neural architecture. But for the training of this predictor, a number of neural architectures and their corresponding real performance often have to be collected. In contrast with classical performance predictor optimized in a fully supervised way, this paper suggests a semi-supervised assessor of neural architectures. We employ an auto-encoder to discover meaningful representations of neural architectures. Taking each neural architecture as an individual instance in the search space, we construct a graph to capture their intrinsic similarities, where both labeled and unlabeled architectures are involved. A graph convolutional neural network is introduced to predict the performance of architectures based on the learned representations and their relation modeled by the graph. Extensive experimental results on the NAS-Benchmark-101 dataset demonstrated that our method is able to make a significant reduction on the required fully trained architectures for finding efficient architectures.
Distilling portable Generative Adversarial Networks for Image Translation
Mar 07, 2020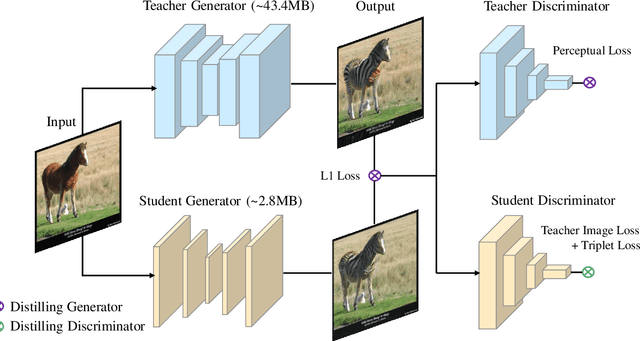
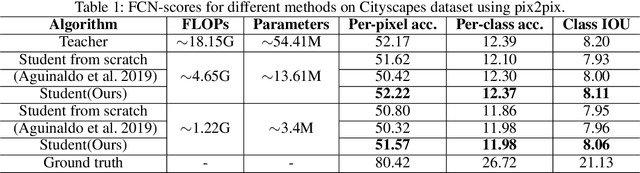

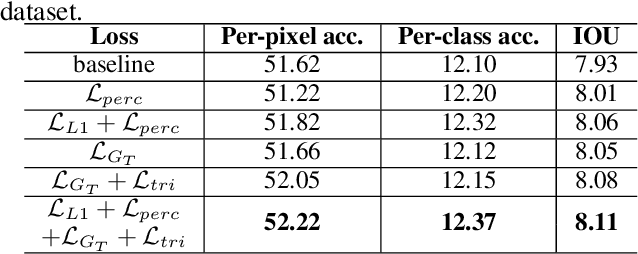
Despite Generative Adversarial Networks (GANs) have been widely used in various image-to-image translation tasks, they can be hardly applied on mobile devices due to their heavy computation and storage cost. Traditional network compression methods focus on visually recognition tasks, but never deal with generation tasks. Inspired by knowledge distillation, a student generator of fewer parameters is trained by inheriting the low-level and high-level information from the original heavy teacher generator. To promote the capability of student generator, we include a student discriminator to measure the distances between real images, and images generated by student and teacher generators. An adversarial learning process is therefore established to optimize student generator and student discriminator. Qualitative and quantitative analysis by conducting experiments on benchmark datasets demonstrate that the proposed method can learn portable generative models with strong performance.