 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Semidefinite Branch-and-Cut for MAP-MRF Inference
Sep 09, 2015
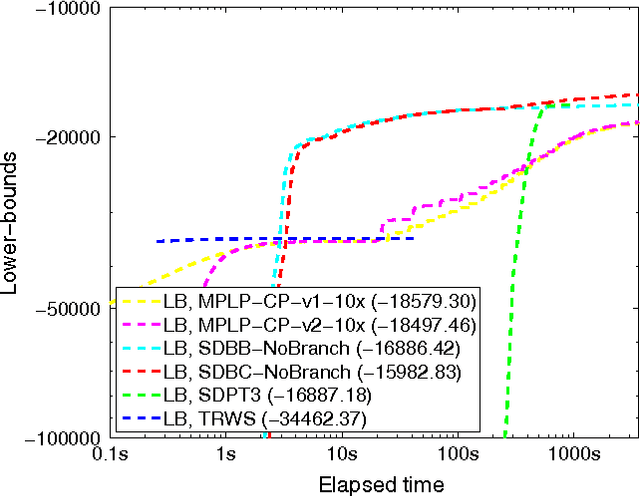
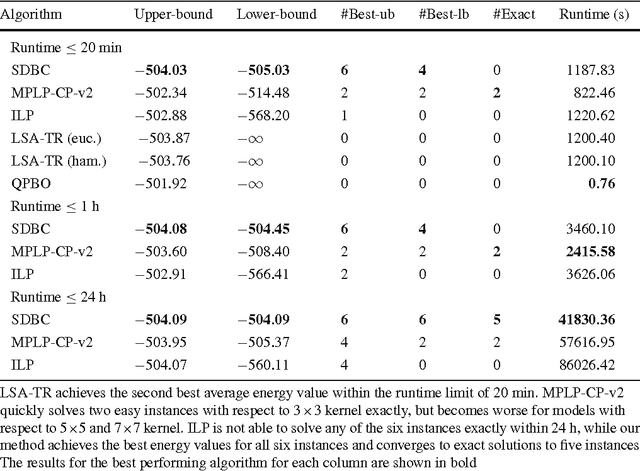
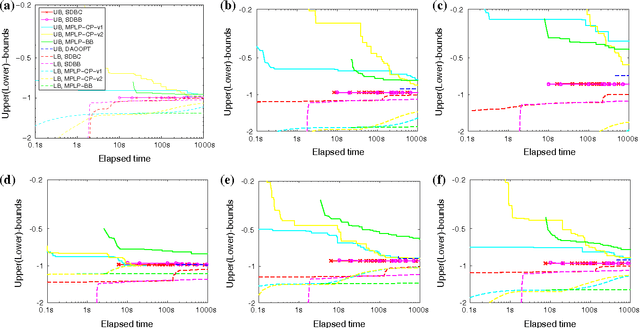
We propose a Branch-and-Cut (B&C) method for solving general MAP-MRF inference problems. The core of our method is a very efficient bounding procedure, which combines scalable semidefinite programming (SDP) and a cutting-plane method for seeking violated constraints. In order to further speed up the computation, several strategies have been exploited, including model reduction, warm start and removal of inactive constraints. We analyze the performance of the proposed method under different settings, and demonstrate that our method either outperforms or performs on par with state-of-the-art approaches. Especially when the connectivities are dense or when the relative magnitudes of the unary costs are low, we achieve the best reported results. Experiments show that the proposed algorithm achieves better approximation than the state-of-the-art methods within a variety of time budgets on challenging non-submodular MAP-MRF inference problems.
Deeply Learning the Messages in Message Passing Inference
Sep 08, 2015

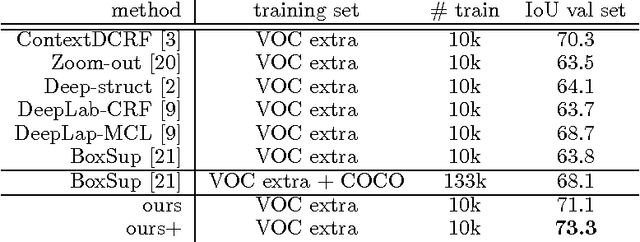

Deep structured output learning shows great promise in tasks like semantic image segmentation. We proffer a new, efficient deep structured model learning scheme, in which we show how deep Convolutional Neural Networks (CNNs) can be used to estimate the messages in message passing inference for structured prediction with Conditional Random Fields (CRFs). With such CNN message estimators, we obviate the need to learn or evaluate potential functions for message calculation. This confers significant efficiency for learning, since otherwise when performing structured learning for a CRF with CNN potentials it is necessary to undertake expensive inference for every stochastic gradient iteration. The network output dimension for message estimation is the same as the number of classes, in contrast to the network output for general CNN potential functions in CRFs, which is exponential in the order of the potentials. Hence CNN message learning has fewer network parameters and is more scalable for cases that a large number of classes are involved. We apply our method to semantic image segmentation on the PASCAL VOC 2012 dataset. We achieve an intersection-over-union score of 73.4 on its test set, which is the best reported result for methods using the VOC training images alone. This impressive performance demonstrates the effectiveness and usefulness of our CNN message learning method.
Online Metric-Weighted Linear Representations for Robust Visual Tracking
Jul 21, 2015

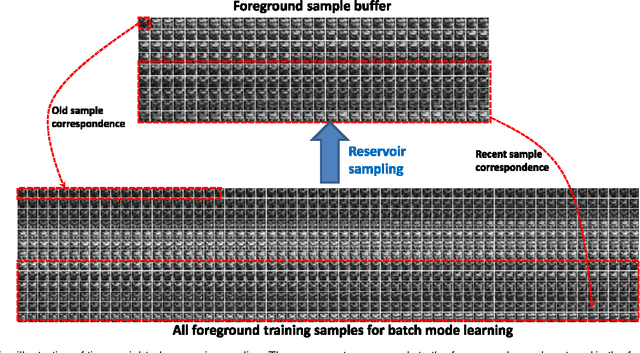

In this paper, we propose a visual tracker based on a metric-weighted linear representation of appearance. In order to capture the interdependence of different feature dimensions, we develop two online distance metric learning methods using proximity comparison information and structured output learning. The learned metric is then incorporated into a linear representation of appearance. We show that online distance metric learning significantly improves the robustness of the tracker, especially on those sequences exhibiting drastic appearance changes. In order to bound growth in the number of training samples, we design a time-weighted reservoir sampling method. Moreover, we enable our tracker to automatically perform object identification during the process of object tracking, by introducing a collection of static template samples belonging to several object classes of interest. Object identification results for an entire video sequence are achieved by systematically combining the tracking information and visual recognition at each frame. Experimental results on challenging video sequences demonstrate the effectiveness of the method for both inter-frame tracking and object identification.
Pedestrian Detection with Spatially Pooled Features and Structured Ensemble Learning
Jun 28, 2015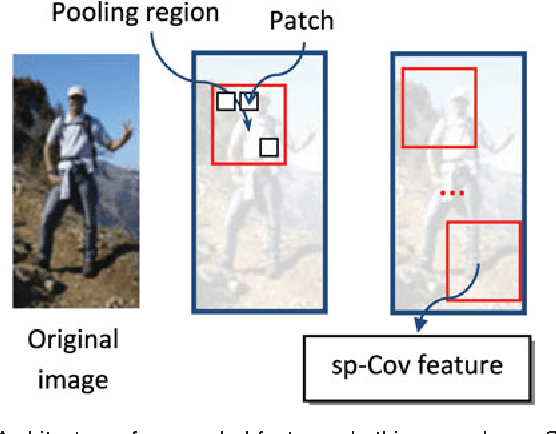
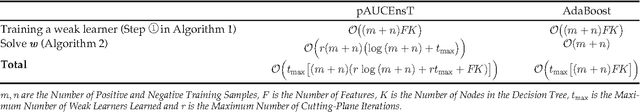

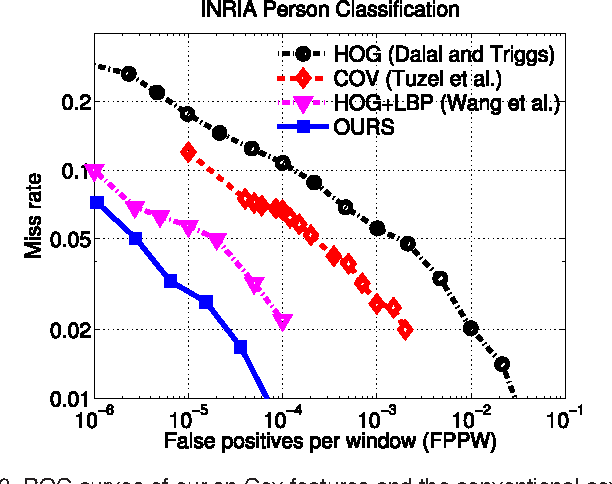
Many typical applications of object detection operate within a prescribed false-positive range. In this situation the performance of a detector should be assessed on the basis of the area under the ROC curve over that range, rather than over the full curve, as the performance outside the range is irrelevant. This measure is labelled as the partial area under the ROC curve (pAUC). We propose a novel ensemble learning method which achieves a maximal detection rate at a user-defined range of false positive rates by directly optimizing the partial AUC using structured learning. In order to achieve a high object detection performance, we propose a new approach to extract low-level visual features based on spatial pooling. Incorporating spatial pooling improves the translational invariance and thus the robustness of the detection process. Experimental results on both synthetic and real-world data sets demonstrate the effectiveness of our approach, and we show that it is possible to train state-of-the-art pedestrian detectors using the proposed structured ensemble learning method with spatially pooled features. The result is the current best reported performance on the Caltech-USA pedestrian detection dataset.
Extrinsic Methods for Coding and Dictionary Learning on Grassmann Manifolds
May 20, 2015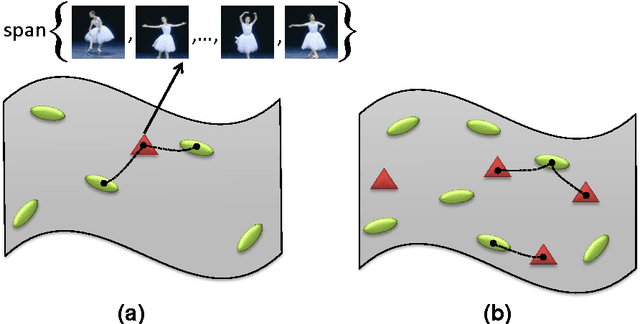
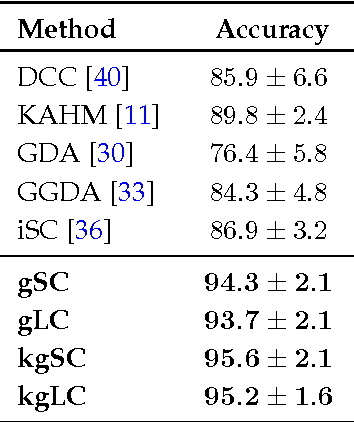
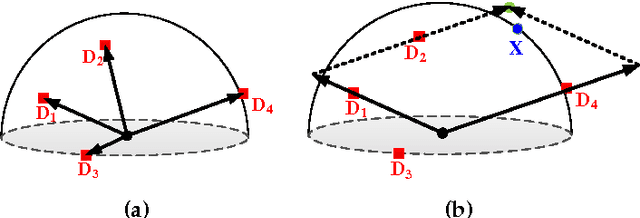
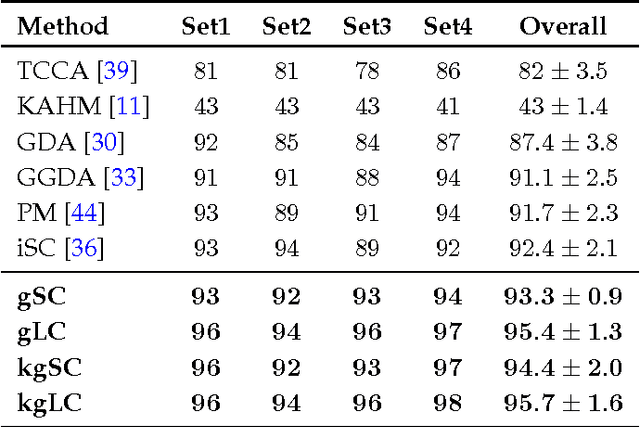
Sparsity-based representations have recently led to notable results in various visual recognition tasks. In a separate line of research, Riemannian manifolds have been shown useful for dealing with features and models that do not lie in Euclidean spaces. With the aim of building a bridge between the two realms, we address the problem of sparse coding and dictionary learning over the space of linear subspaces, which form Riemannian structures known as Grassmann manifolds. To this end, we propose to embed Grassmann manifolds into the space of symmetric matrices by an isometric mapping. This in turn enables us to extend two sparse coding schemes to Grassmann manifolds. Furthermore, we propose closed-form solutions for learning a Grassmann dictionary, atom by atom. Lastly, to handle non-linearity in data, we extend the proposed Grassmann sparse coding and dictionary learning algorithms through embedding into Hilbert spaces. Experiments on several classification tasks (gender recognition, gesture classification, scene analysis, face recognition, action recognition and dynamic texture classification) show that the proposed approaches achieve considerable improvements in discrimination accuracy, in comparison to state-of-the-art methods such as kernelized Affine Hull Method and graph-embedding Grassmann discriminant analysis.
Unsupervised Feature Learning for Dense Correspondences across Scenes
Apr 23, 2015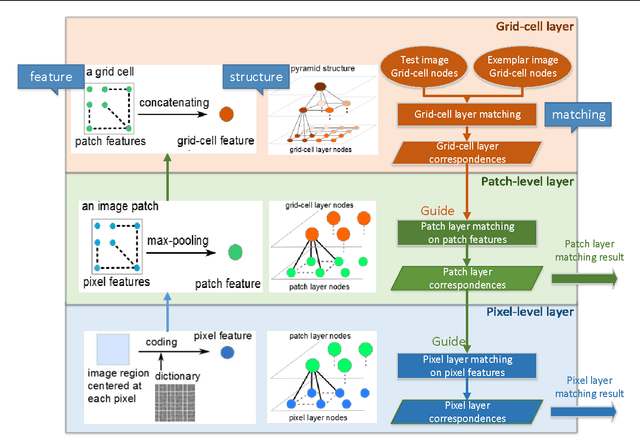
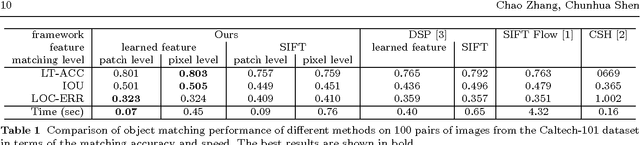
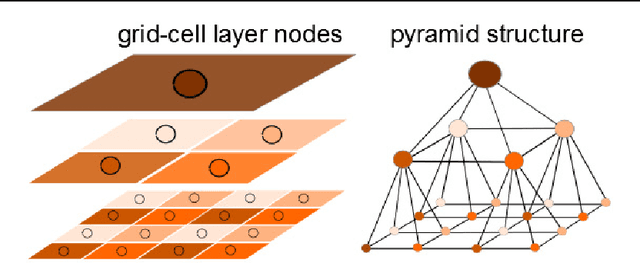
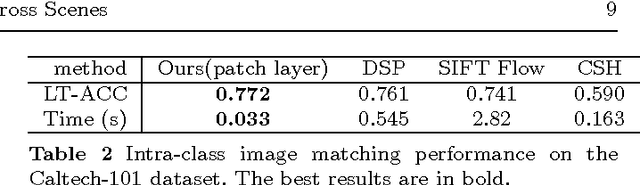
We propose a fast, accurate matching method for estimating dense pixel correspondences across scenes. It is a challenging problem to estimate dense pixel correspondences between images depicting different scenes or instances of the same object category. While most such matching methods rely on hand-crafted features such as SIFT, we learn features from a large amount of unlabeled image patches using unsupervised learning. Pixel-layer features are obtained by encoding over the dictionary, followed by spatial pooling to obtain patch-layer features. The learned features are then seamlessly embedded into a multi-layer match- ing framework. We experimentally demonstrate that the learned features, together with our matching model, outperforms state-of-the-art methods such as the SIFT flow, coherency sensitive hashing and the recent deformable spatial pyramid matching methods both in terms of accuracy and computation efficiency. Furthermore, we evaluate the performance of a few different dictionary learning and feature encoding methods in the proposed pixel correspondences estimation framework, and analyse the impact of dictionary learning and feature encoding with respect to the final matching performance.
Learning discriminative trajectorylet detector sets for accurate skeleton-based action recognition
Apr 20, 2015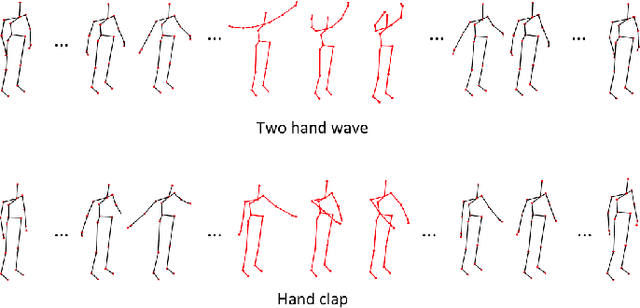
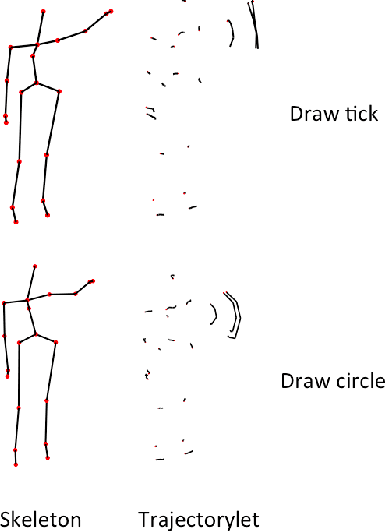
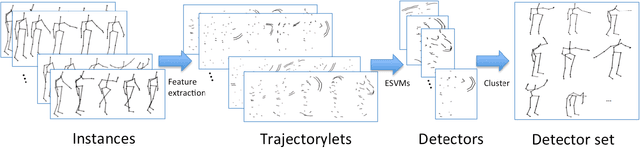
The introduction of low-cost RGB-D sensors has promoted the research in skeleton-based human action recognition. Devising a representation suitable for characterising actions on the basis of noisy skeleton sequences remains a challenge, however. We here provide two insights into this challenge. First, we show that the discriminative information of a skeleton sequence usually resides in a short temporal interval and we propose a simple-but-effective local descriptor called trajectorylet to capture the static and kinematic information within this interval. Second, we further propose to encode each trajectorylet with a discriminative trajectorylet detector set which is selected from a large number of candidate detectors trained through exemplar-SVMs. The action-level representation is obtained by pooling trajectorylet encodings. Evaluating on standard datasets acquired from the Kinect sensor, it is demonstrated that our method obtains superior results over existing approaches under various experimental setups.
Supervised Discrete Hashing
Apr 19, 2015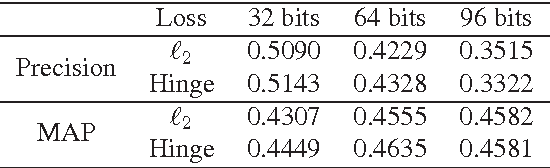
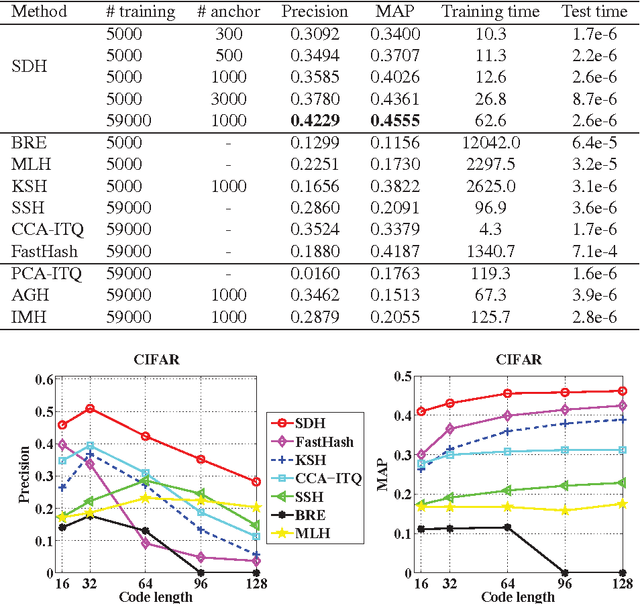
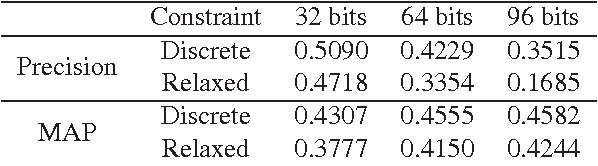
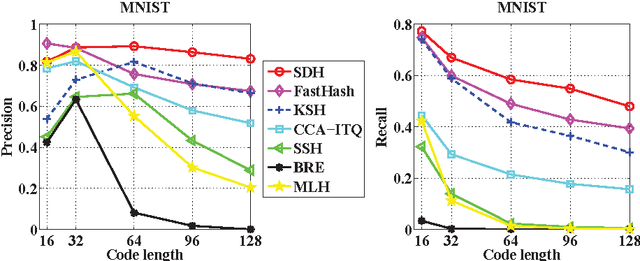
This paper has been withdrawn by the authour.
Temporal Pyramid Pooling Based Convolutional Neural Networks for Action Recognition
Apr 16, 2015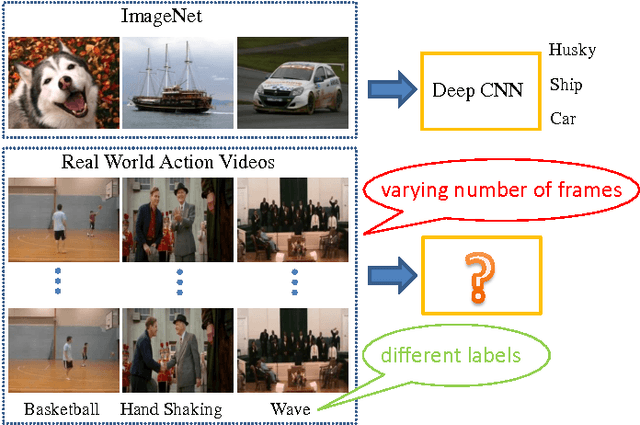
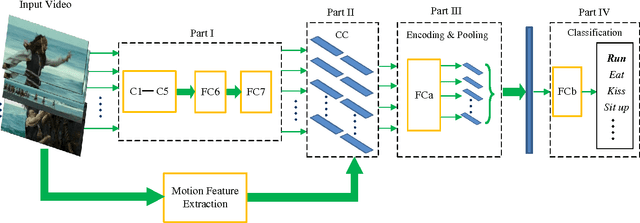
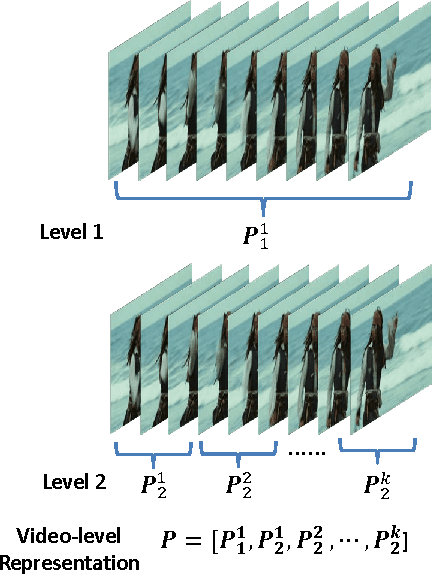
Encouraged by the success of Convolutional Neural Networks (CNNs) in image classification, recently much effort is spent on applying CNNs to video based action recognition problems. One challenge is that video contains a varying number of frames which is incompatible to the standard input format of CNNs. Existing methods handle this issue either by directly sampling a fixed number of frames or bypassing this issue by introducing a 3D convolutional layer which conducts convolution in spatial-temporal domain. To solve this issue, here we propose a novel network structure which allows an arbitrary number of frames as the network input. The key of our solution is to introduce a module consisting of an encoding layer and a temporal pyramid pooling layer. The encoding layer maps the activation from previous layers to a feature vector suitable for pooling while the temporal pyramid pooling layer converts multiple frame-level activations into a fixed-length video-level representation. In addition, we adopt a feature concatenation layer which combines appearance information and motion information. Compared with the frame sampling strategy, our method avoids the risk of missing any important frames. Compared with the 3D convolutional method which requires a huge video dataset for network training, our model can be learned on a small target dataset because we can leverage the off-the-shelf image-level CNN for model parameter initialization. Experiments on two challenging datasets, Hollywood2 and HMDB51, demonstrate that our method achieves superior performance over state-of-the-art methods while requiring much fewer training data.
Mid-level Deep Pattern Mining
Apr 09, 2015
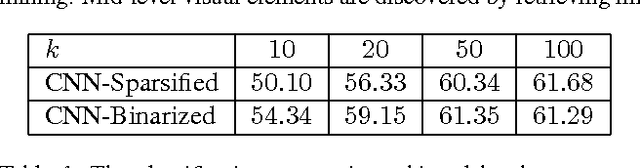
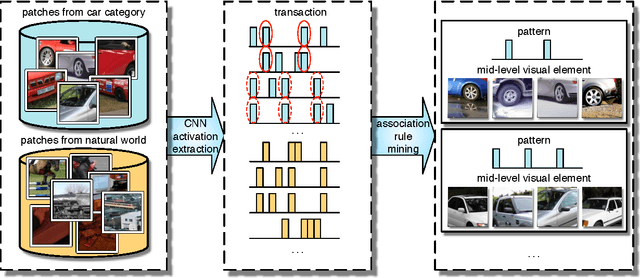
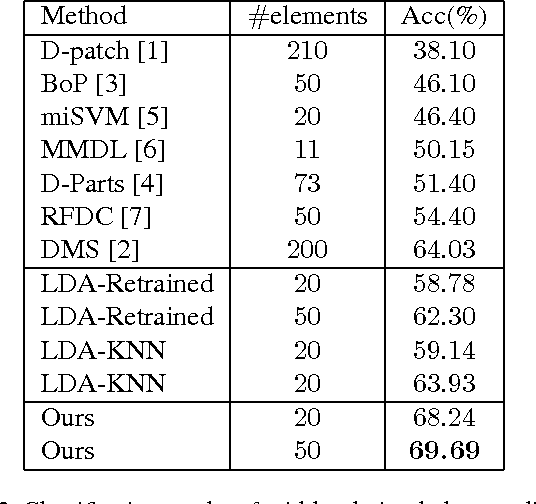
Mid-level visual element discovery aims to find clusters of image patches that are both representative and discriminative. In this work, we study this problem from the prospective of pattern mining while relying on the recently popularized Convolutional Neural Networks (CNNs). Specifically, we find that for an image patch, activations extracted from the first fully-connected layer of CNNs have two appealing properties which enable its seamless integration with pattern mining. Patterns are then discovered from a large number of CNN activations of image patches through the well-known association rule mining. When we retrieve and visualize image patches with the same pattern, surprisingly, they are not only visually similar but also semantically consistent. We apply our approach to scene and object classification tasks, and demonstrate that our approach outperforms all previous works on mid-level visual element discovery by a sizeable margin with far fewer elements being used. Our approach also outperforms or matches recent works using CNN for these tasks. Source code of the complete system is available online.