 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured learning of metric ensembles with application to person re-identification
May 24, 2016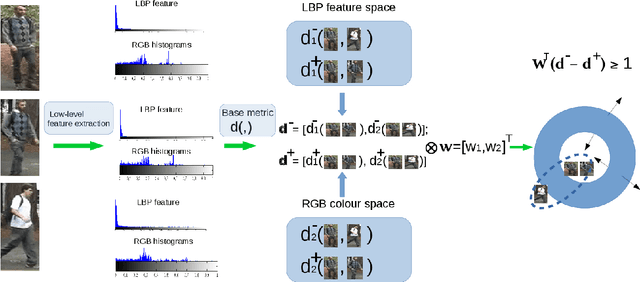
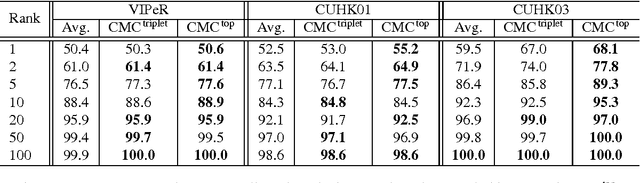
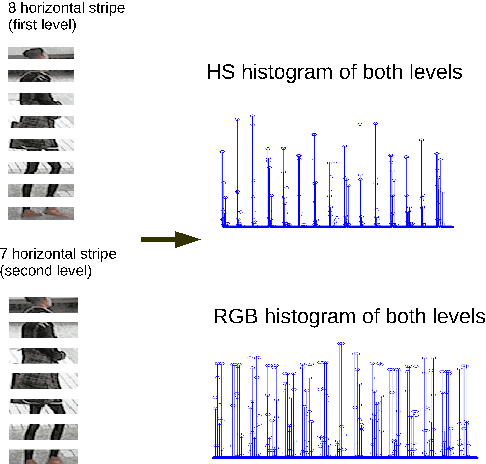
Matching individuals across non-overlapping camera networks, known as person re-identification, is a fundamentally challenging problem due to the large visual appearance changes caused by variations of viewpoints, lighting, and occlusion. Approaches in literature can be categoried into two streams: The first stream is to develop reliable features against realistic conditions by combining several visual features in a pre-defined way; the second stream is to learn a metric from training data to ensure strong inter-class differences and intra-class similarities. However, seeking an optimal combination of visual features which is generic yet adaptive to different benchmarks is a unsoved problem, and metric learning models easily get over-fitted due to the scarcity of training data in person re-identification. In this paper, we propose two effective structured learning based approaches which explore the adaptive effects of visual features in recognizing persons in different benchmark data sets. Our framework is built on the basis of multiple low-level visual features with an optimal ensemble of their metrics. We formulate two optimization algorithms, CMCtriplet and CMCstruct, which directly optimize evaluation measures commonly used in person re-identification, also known as the Cumulative Matching Characteristic (CMC) curve.
Fast detection of multiple objects in traffic scenes with a common detection framework
Oct 12, 2015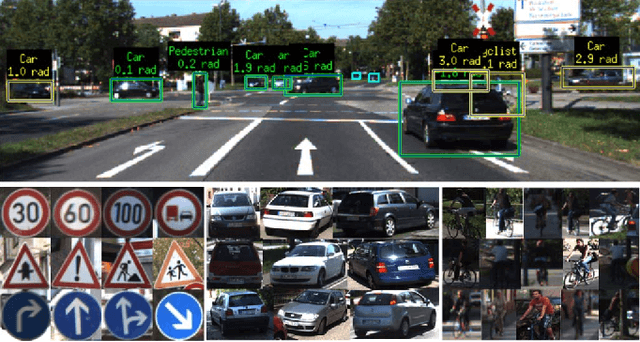
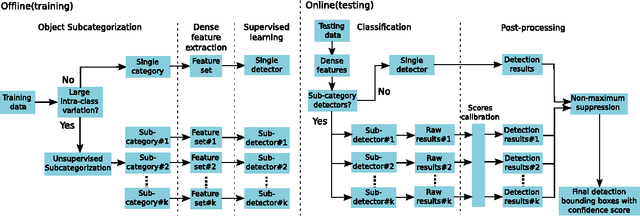
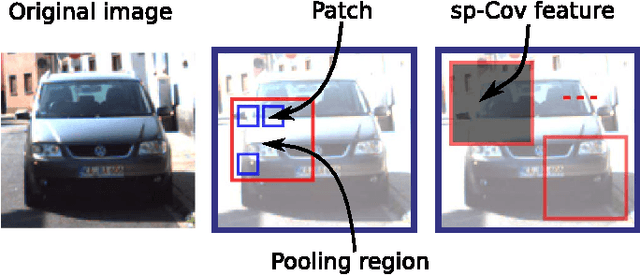
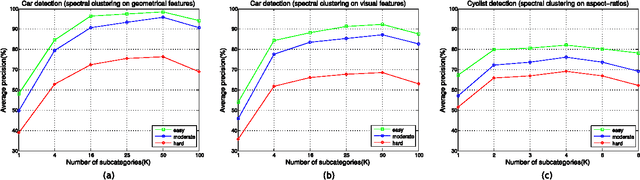
Traffic scene perception (TSP) aims to real-time extract accurate on-road environment information, which in- volves three phases: detection of objects of interest, recognition of detected objects, and tracking of objects in motion. Since recognition and tracking often rely on the results from detection, the ability to detect objects of interest effectively plays a crucial role in TSP. In this paper, we focus on three important classes of objects: traffic signs, cars, and cyclists. We propose to detect all the three important objects in a single learning based detection framework. The proposed framework consists of a dense feature extractor and detectors of three important classes. Once the dense features have been extracted, these features are shared with all detectors. The advantage of using one common framework is that the detection speed is much faster, since all dense features need only to be evaluated once in the testing phase. In contrast, most previous works have designed specific detectors using different features for each of these objects. To enhance the feature robustness to noises and image deformations, we introduce spatially pooled features as a part of aggregated channel features. In order to further improve the generalization performance, we propose an object subcategorization method as a means of capturing intra-class variation of objects. We experimentally demonstrate the effectiveness and efficiency of the proposed framework in three detection applications: traffic sign detection, car detection, and cyclist detection. The proposed framework achieves the competitive performance with state-of- the-art approaches on several benchmark datasets.
Pedestrian Detection with Spatially Pooled Features and Structured Ensemble Learning
Jun 28, 2015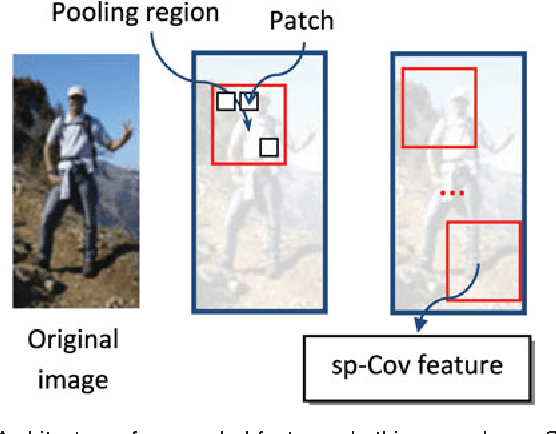
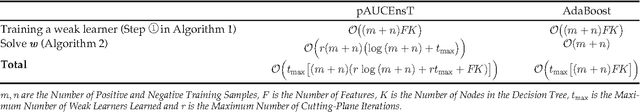

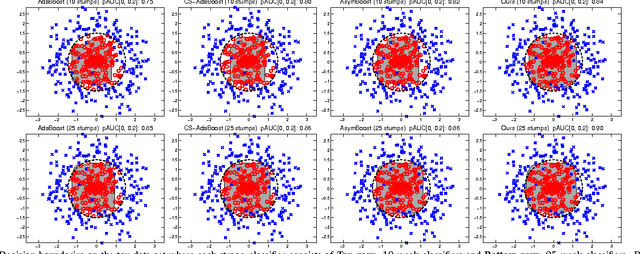
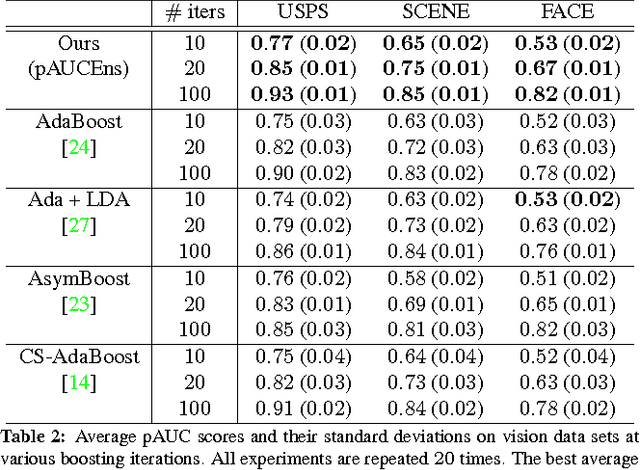
Many typical applications of object detection operate within a prescribed false-positive range. In this situation the performance of a detector should be assessed on the basis of the area under the ROC curve over that range, rather than over the full curve, as the performance outside the range is irrelevant. This measure is labelled as the partial area under the ROC curve (pAUC). We propose a novel ensemble learning method which achieves a maximal detection rate at a user-defined range of false positive rates by directly optimizing the partial AUC using structured learning. In order to achieve a high object detection performance, we propose a new approach to extract low-level visual features based on spatial pooling. Incorporating spatial pooling improves the translational invariance and thus the robustness of the detection process. Experimental results on both synthetic and real-world data sets demonstrate the effectiveness of our approach, and we show that it is possible to train state-of-the-art pedestrian detectors using the proposed structured ensemble learning method with spatially pooled features. The result is the current best reported performance on the Caltech-USA pedestrian detection dataset.
Learning to rank in person re-identification with metric ensembles
Mar 05, 2015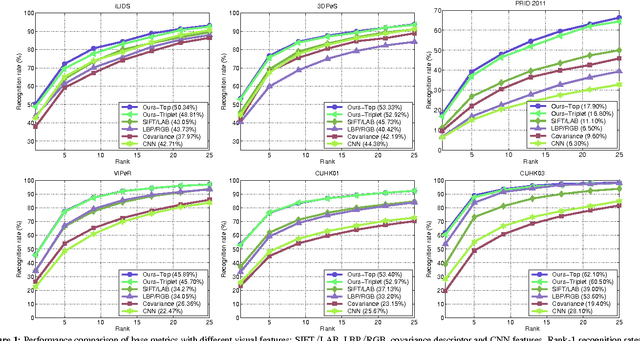
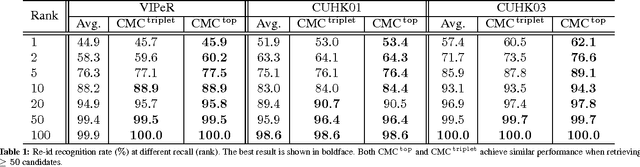
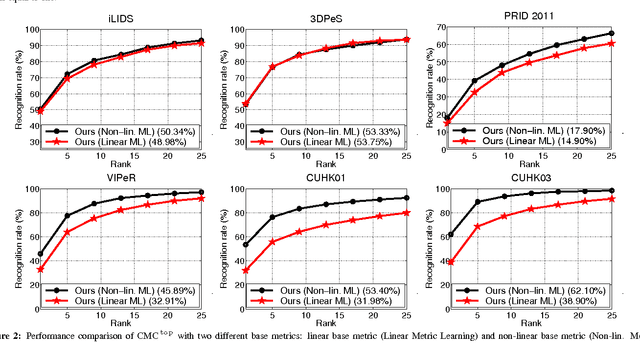
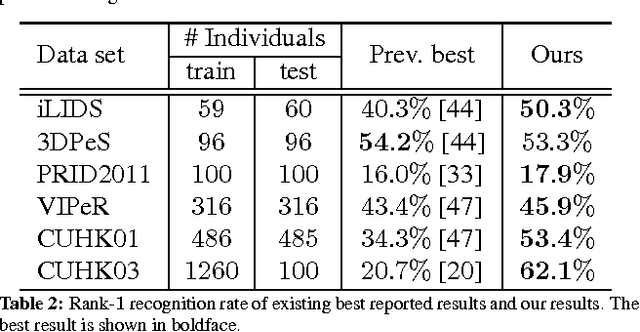
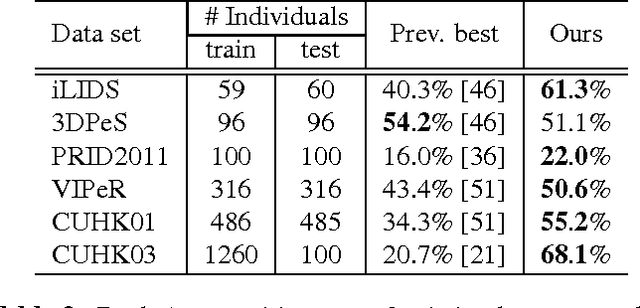
We propose an effective structured learning based approach to the problem of person re-identification which outperforms the current state-of-the-art on most benchmark data sets evaluated. Our framework is built on the basis of multiple low-level hand-crafted and high-level visual features. We then formulate two optimization algorithms, which directly optimize evaluation measures commonly used in person re-identification, also known as the Cumulative Matching Characteristic (CMC) curve. Our new approach is practical to many real-world surveillance applications as the re-identification performance can be concentrated in the range of most practical importance. The combination of these factors leads to a person re-identification system which outperforms most existing algorithms. More importantly, we advance state-of-the-art results on person re-identification by improving the rank-$1$ recognition rates from $40\%$ to $50\%$ on the iLIDS benchmark, $16\%$ to $18\%$ on the PRID2011 benchmark, $43\%$ to $46\%$ on the VIPeR benchmark, $34\%$ to $53\%$ on the CUHK01 benchmark and $21\%$ to $62\%$ on the CUHK03 benchmark.
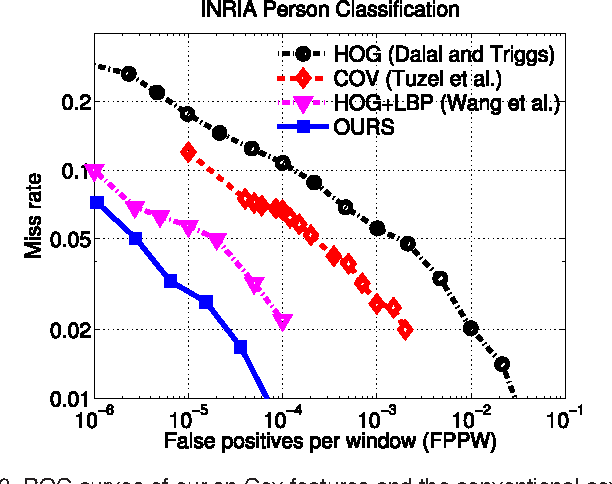
Strengthening the Effectiveness of Pedestrian Detection with Spatially Pooled Features
Jul 03, 2014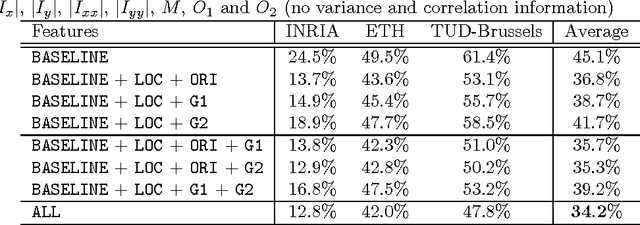
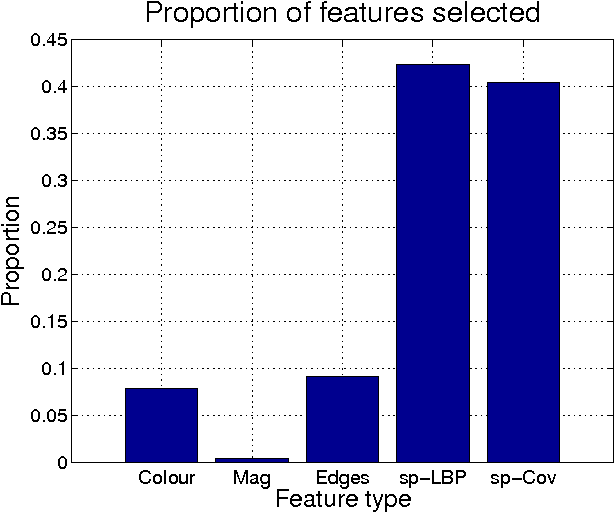
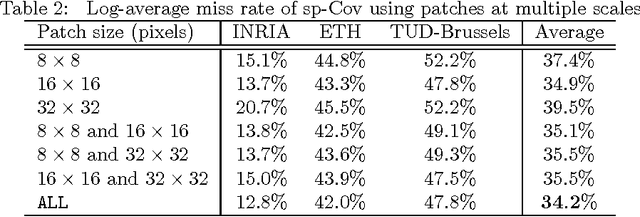

We propose a simple yet effective approach to the problem of pedestrian detection which outperforms the current state-of-the-art. Our new features are built on the basis of low-level visual features and spatial pooling. Incorporating spatial pooling improves the translational invariance and thus the robustness of the detection process. We then directly optimise the partial area under the ROC curve (\pAUC) measure, which concentrates detection performance in the range of most practical importance. The combination of these factors leads to a pedestrian detector which outperforms all competitors on all of the standard benchmark datasets. We advance state-of-the-art results by lowering the average miss rate from $13\%$ to $11\%$ on the INRIA benchmark, $41\%$ to $37\%$ on the ETH benchmark, $51\%$ to $42\%$ on the TUD-Brussels benchmark and $36\%$ to $29\%$ on the Caltech-USA benchmark.
Large-margin Learning of Compact Binary Image Encodings
Feb 26, 2014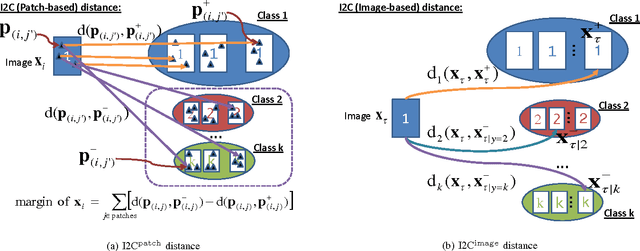
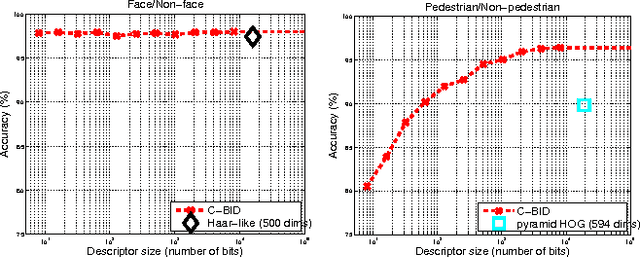
The use of high-dimensional features has become a normal practice in many computer vision applications. The large dimension of these features is a limiting factor upon the number of data points which may be effectively stored and processed, however. We address this problem by developing a novel approach to learning a compact binary encoding, which exploits both pair-wise proximity and class-label information on training data set. Exploiting this extra information allows the development of encodings which, although compact, outperform the original high-dimensional features in terms of final classification or retrieval performance. The method is general, in that it is applicable to both non-parametric and parametric learning methods. This generality means that the embedded features are suitable for a wide variety of computer vision tasks, such as image classification and content-based image retrieval. Experimental results demonstrate that the new compact descriptor achieves an accuracy comparable to, and in some cases better than, the visual descriptor in the original space despite being significantly more compact. Moreover, any convex loss function and convex regularization penalty (e.g., $ \ell_p $ norm with $ p \ge 1 $) can be incorporated into the framework, which provides future flexibility.
Asymmetric Pruning for Learning Cascade Detectors
Feb 25, 2014



Cascade classifiers are one of the most important contributions to real-time object detection. Nonetheless, there are many challenging problems arising in training cascade detectors. One common issue is that the node classifier is trained with a symmetric classifier. Having a low misclassification error rate does not guarantee an optimal node learning goal in cascade classifiers, i.e., an extremely high detection rate with a moderate false positive rate. In this work, we present a new approach to train an effective node classifier in a cascade detector. The algorithm is based on two key observations: 1) Redundant weak classifiers can be safely discarded; 2) The final detector should satisfy the asymmetric learning objective of the cascade architecture. To achieve this, we separate the classifier training into two steps: finding a pool of discriminative weak classifiers/features and training the final classifier by pruning weak classifiers which contribute little to the asymmetric learning criterion (asymmetric classifier construction). Our model reduction approach helps accelerate the learning time while achieving the pre-determined learning objective. Experimental results on both face and car data sets verify the effectiveness of the proposed algorithm. On the FDDB face data sets, our approach achieves the state-of-the-art performance, which demonstrates the advantage of our approach.
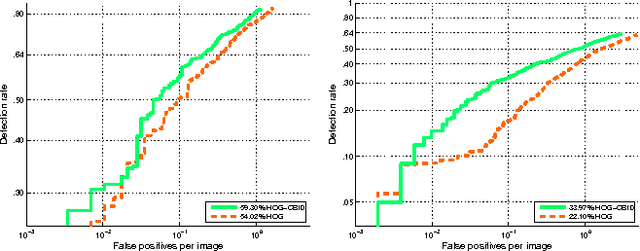
Efficient pedestrian detection by directly optimize the partial area under the ROC curve
Oct 03, 2013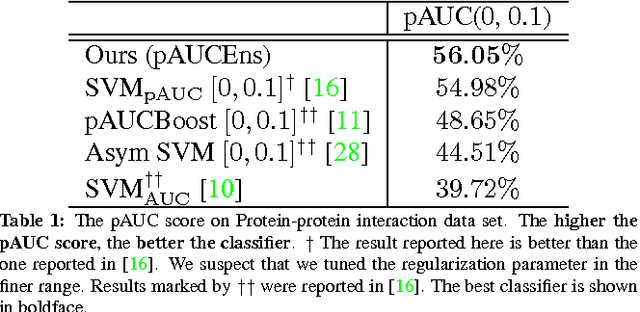
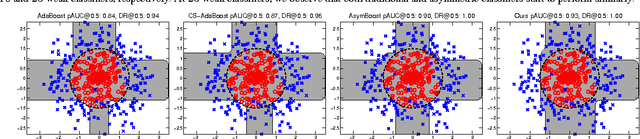
Many typical applications of object detection operate within a prescribed false-positive range. In this situation the performance of a detector should be assessed on the basis of the area under the ROC curve over that range, rather than over the full curve, as the performance outside the range is irrelevant. This measure is labelled as the partial area under the ROC curve (pAUC). Effective cascade-based classification, for example, depends on training node classifiers that achieve the maximal detection rate at a moderate false positive rate, e.g., around 40% to 50%. We propose a novel ensemble learning method which achieves a maximal detection rate at a user-defined range of false positive rates by directly optimizing the partial AUC using structured learning. By optimizing for different ranges of false positive rates, the proposed method can be used to train either a single strong classifier or a node classifier forming part of a cascade classifier. Experimental results on both synthetic and real-world data sets demonstrate the effectiveness of our approach, and we show that it is possible to train state-of-the-art pedestrian detectors using the proposed structured ensemble learning method.
A scalable stage-wise approach to large-margin multi-class loss based boosting
Jul 21, 2013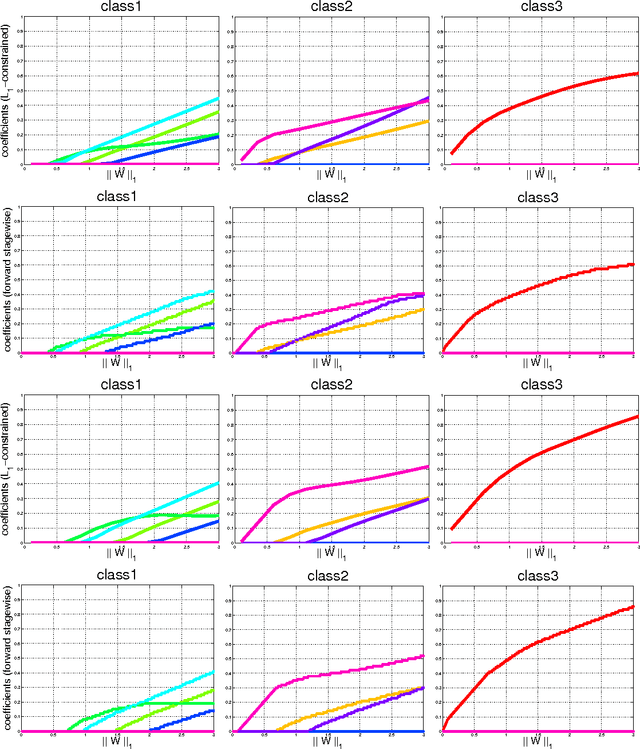
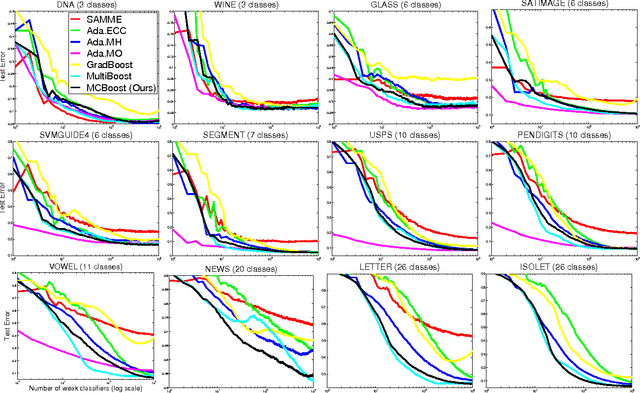
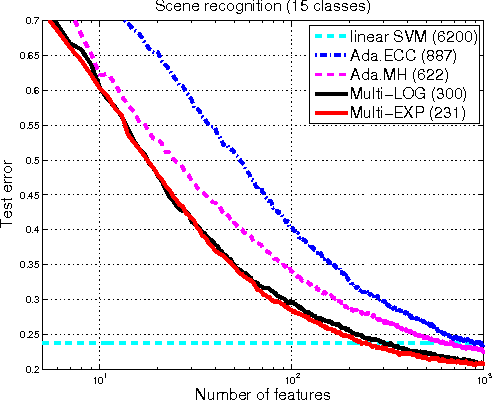
We present a scalable and effective classification model to train multi-class boosting for multi-class classification problems. Shen and Hao introduced a direct formulation of multi- class boosting in the sense that it directly maximizes the multi- class margin [C. Shen and Z. Hao, "A direct formulation for totally-corrective multi- class boosting", in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2011]. The major problem of their approach is its high computational complexity for training, which hampers its application on real-world problems. In this work, we propose a scalable and simple stage-wise multi-class boosting method, which also directly maximizes the multi-class margin. Our approach of- fers a few advantages: 1) it is simple and computationally efficient to train. The approach can speed up the training time by more than two orders of magnitude without sacrificing the classification accuracy. 2) Like traditional AdaBoost, it is less sensitive to the choice of parameters and empirically demonstrates excellent generalization performance. Experimental results on challenging multi-class machine learning and vision tasks demonstrate that the proposed approach substantially improves the convergence rate and accuracy of the final visual detector at no additional computational cost compared to existing multi-class boosting.
RandomBoost: Simplified Multi-class Boosting through Randomization
Feb 05, 2013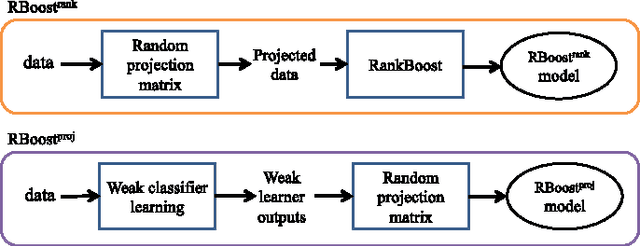
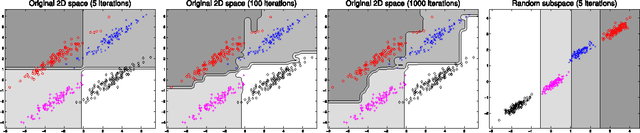
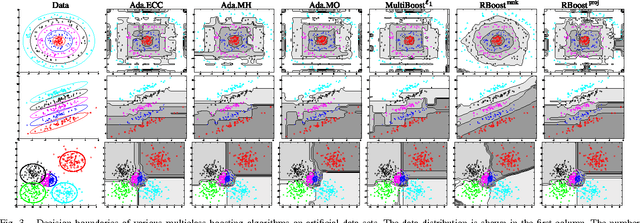
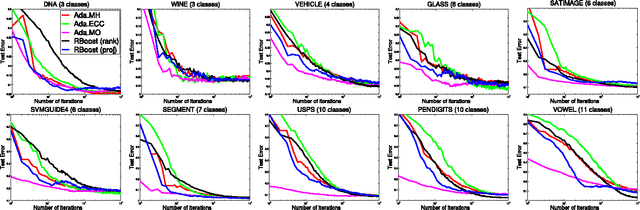
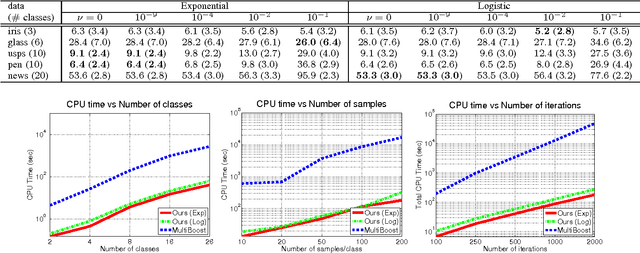
We propose a novel boosting approach to multi-class classification problems, in which multiple classes are distinguished by a set of random projection matrices in essence. The approach uses random projections to alleviate the proliferation of binary classifiers typically required to perform multi-class classification. The result is a multi-class classifier with a single vector-valued parameter, irrespective of the number of classes involved. Two variants of this approach are proposed. The first method randomly projects the original data into new spaces, while the second method randomly projects the outputs of learned weak classifiers. These methods are not only conceptually simple but also effective and easy to implement. A series of experiments on synthetic, machine learning and visual recognition data sets demonstrate that our proposed methods compare favorably to existing multi-class boosting algorithms in terms of both the convergence rate and classification accuracy.