 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeavy-Tailed Regularization of Weight Matrices in Deep Neural Networks
Apr 07, 2023



Unraveling the reasons behind the remarkable success and exceptional generalization capabilities of deep neural networks presents a formidable challenge. Recent insights from random matrix theory, specifically those concerning the spectral analysis of weight matrices in deep neural networks, offer valuable clues to address this issue. A key finding indicates that the generalization performance of a neural network is associated with the degree of heavy tails in the spectrum of its weight matrices. To capitalize on this discovery, we introduce a novel regularization technique, termed Heavy-Tailed Regularization, which explicitly promotes a more heavy-tailed spectrum in the weight matrix through regularization. Firstly, we employ the Weighted Alpha and Stable Rank as penalty terms, both of which are differentiable, enabling the direct calculation of their gradients. To circumvent over-regularization, we introduce two variations of the penalty function. Then, adopting a Bayesian statistics perspective and leveraging knowledge from random matrices, we develop two novel heavy-tailed regularization methods, utilizing Powerlaw distribution and Frechet distribution as priors for the global spectrum and maximum eigenvalues, respectively. We empirically show that heavytailed regularization outperforms conventional regularization techniques in terms of generalization performance.
Fair-CDA: Continuous and Directional Augmentation for Group Fairness
Apr 01, 2023In this work, we propose {\it Fair-CDA}, a fine-grained data augmentation strategy for imposing fairness constraints. We use a feature disentanglement method to extract the features highly related to the sensitive attributes. Then we show that group fairness can be achieved by regularizing the models on transition paths of sensitive features between groups. By adjusting the perturbation strength in the direction of the paths, our proposed augmentation is controllable and auditable. To alleviate the accuracy degradation caused by fairness constraints, we further introduce a calibrated model to impute labels for the augmented data. Our proposed method does not assume any data generative model and ensures good generalization for both accuracy and fairness. Experimental results show that Fair-CDA consistently outperforms state-of-the-art methods on widely-used benchmarks, e.g., Adult, CelebA and MovieLens. Especially, Fair-CDA obtains an 86.3\% relative improvement for fairness while maintaining the accuracy on the Adult dataset. Moreover, we evaluate Fair-CDA in an online recommendation system to demonstrate the effectiveness of our method in terms of accuracy and fairness.
Boosting Out-of-Distribution Detection with Multiple Pre-trained Models
Dec 24, 2022



Out-of-Distribution (OOD) detection, i.e., identifying whether an input is sampled from a novel distribution other than the training distribution, is a critical task for safely deploying machine learning systems in the open world. Recently, post hoc detection utilizing pre-trained models has shown promising performance and can be scaled to large-scale problems. This advance raises a natural question: Can we leverage the diversity of multiple pre-trained models to improve the performance of post hoc detection methods? In this work, we propose a detection enhancement method by ensembling multiple detection decisions derived from a zoo of pre-trained models. Our approach uses the p-value instead of the commonly used hard threshold and leverages a fundamental framework of multiple hypothesis testing to control the true positive rate of In-Distribution (ID) data. We focus on the usage of model zoos and provide systematic empirical comparisons with current state-of-the-art methods on various OOD detection benchmarks. The proposed ensemble scheme shows consistent improvement compared to single-model detectors and significantly outperforms the current competitive methods. Our method substantially improves the relative performance by 65.40% and 26.96% on the CIFAR10 and ImageNet benchmarks.
ZooD: Exploiting Model Zoo for Out-of-Distribution Generalization
Oct 17, 2022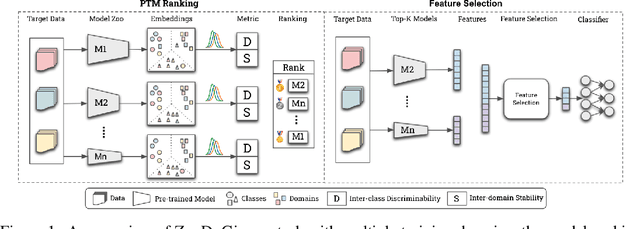

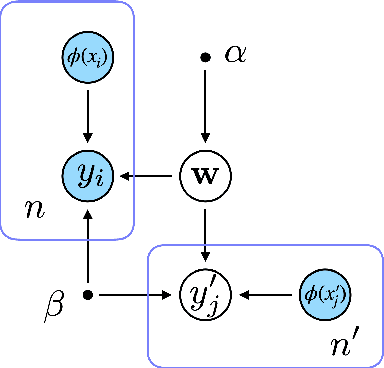
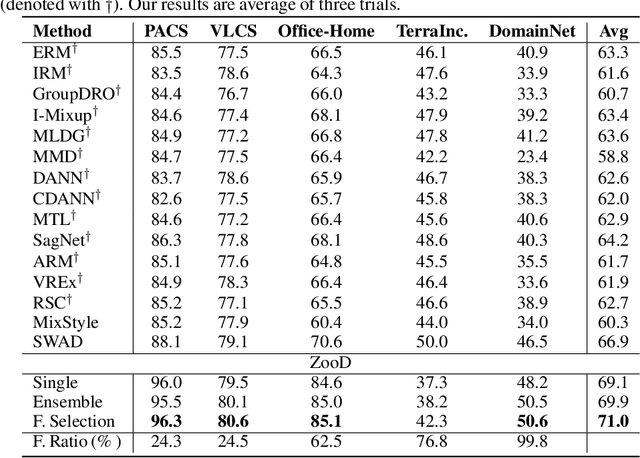
Recent advances on large-scale pre-training have shown great potentials of leveraging a large set of Pre-Trained Models (PTMs) for improving Out-of-Distribution (OoD) generalization, for which the goal is to perform well on possible unseen domains after fine-tuning on multiple training domains. However, maximally exploiting a zoo of PTMs is challenging since fine-tuning all possible combinations of PTMs is computationally prohibitive while accurate selection of PTMs requires tackling the possible data distribution shift for OoD tasks. In this work, we propose ZooD, a paradigm for PTMs ranking and ensemble with feature selection. Our proposed metric ranks PTMs by quantifying inter-class discriminability and inter-domain stability of the features extracted by the PTMs in a leave-one-domain-out cross-validation manner. The top-K ranked models are then aggregated for the target OoD task. To avoid accumulating noise induced by model ensemble, we propose an efficient variational EM algorithm to select informative features. We evaluate our paradigm on a diverse model zoo consisting of 35 models for various OoD tasks and demonstrate: (i) model ranking is better correlated with fine-tuning ranking than previous methods and up to 9859x faster than brute-force fine-tuning; (ii) OoD generalization after model ensemble with feature selection outperforms the state-of-the-art methods and the accuracy on most challenging task DomainNet is improved from 46.5\% to 50.6\%. Furthermore, we provide the fine-tuning results of 35 PTMs on 7 OoD datasets, hoping to help the research of model zoo and OoD generalization. Code will be available at https://gitee.com/mindspore/models/tree/master/research/cv/zood.
Boosting Out-of-distribution Detection with Typical Features
Oct 09, 2022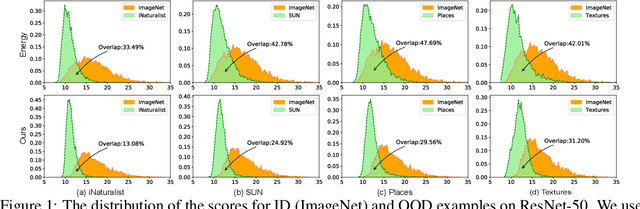
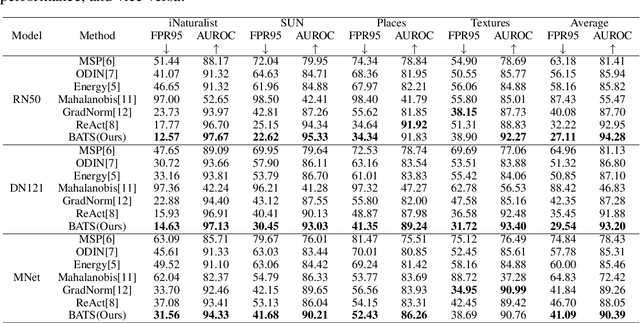

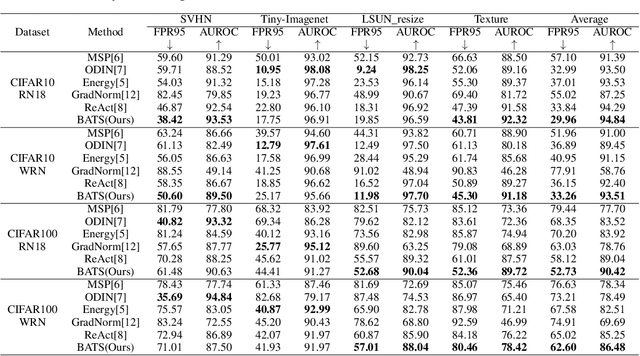
Out-of-distribution (OOD) detection is a critical task for ensuring the reliability and safety of deep neural networks in real-world scenarios. Different from most previous OOD detection methods that focus on designing OOD scores or introducing diverse outlier examples to retrain the model, we delve into the obstacle factors in OOD detection from the perspective of typicality and regard the feature's high-probability region of the deep model as the feature's typical set. We propose to rectify the feature into its typical set and calculate the OOD score with the typical features to achieve reliable uncertainty estimation. The feature rectification can be conducted as a {plug-and-play} module with various OOD scores. We evaluate the superiority of our method on both the commonly used benchmark (CIFAR) and the more challenging high-resolution benchmark with large label space (ImageNet). Notably, our approach outperforms state-of-the-art methods by up to 5.11$\%$ in the average FPR95 on the ImageNet benchmark.
MixACM: Mixup-Based Robustness Transfer via Distillation of Activated Channel Maps
Nov 09, 2021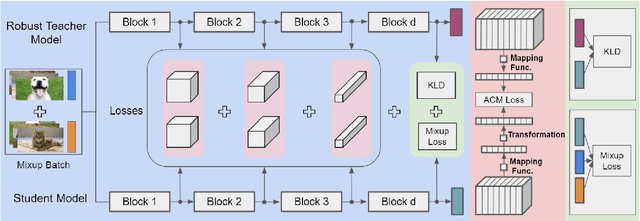
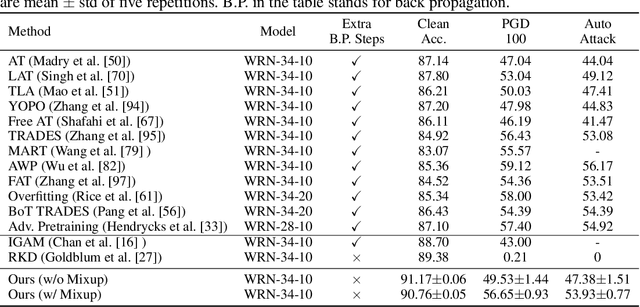

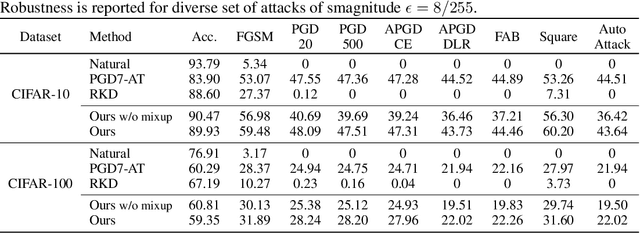
Deep neural networks are susceptible to adversarially crafted, small and imperceptible changes in the natural inputs. The most effective defense mechanism against these examples is adversarial training which constructs adversarial examples during training by iterative maximization of loss. The model is then trained to minimize the loss on these constructed examples. This min-max optimization requires more data, larger capacity models, and additional computing resources. It also degrades the standard generalization performance of a model. Can we achieve robustness more efficiently? In this work, we explore this question from the perspective of knowledge transfer. First, we theoretically show the transferability of robustness from an adversarially trained teacher model to a student model with the help of mixup augmentation. Second, we propose a novel robustness transfer method called Mixup-Based Activated Channel Maps (MixACM) Transfer. MixACM transfers robustness from a robust teacher to a student by matching activated channel maps generated without expensive adversarial perturbations. Finally, extensive experiments on multiple datasets and different learning scenarios show our method can transfer robustness while also improving generalization on natural images.
NASOA: Towards Faster Task-oriented Online Fine-tuning with a Zoo of Models
Aug 07, 2021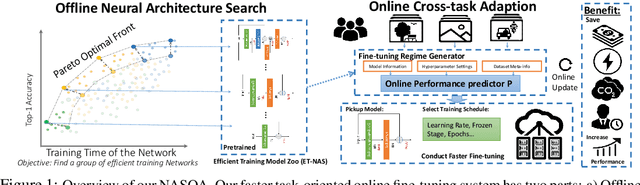

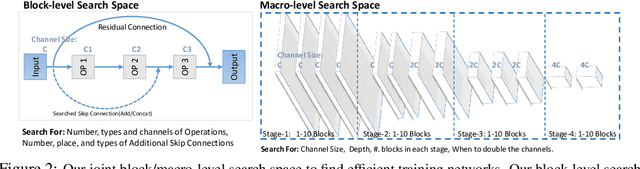
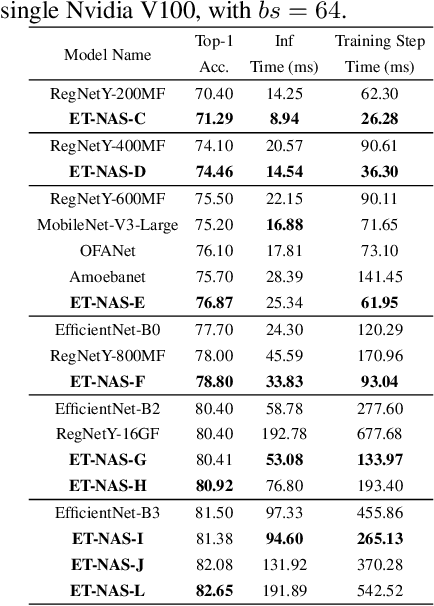
Fine-tuning from pre-trained ImageNet models has been a simple, effective, and popular approach for various computer vision tasks. The common practice of fine-tuning is to adopt a default hyperparameter setting with a fixed pre-trained model, while both of them are not optimized for specific tasks and time constraints. Moreover, in cloud computing or GPU clusters where the tasks arrive sequentially in a stream, faster online fine-tuning is a more desired and realistic strategy for saving money, energy consumption, and CO2 emission. In this paper, we propose a joint Neural Architecture Search and Online Adaption framework named NASOA towards a faster task-oriented fine-tuning upon the request of users. Specifically, NASOA first adopts an offline NAS to identify a group of training-efficient networks to form a pretrained model zoo. We propose a novel joint block and macro-level search space to enable a flexible and efficient search. Then, by estimating fine-tuning performance via an adaptive model by accumulating experience from the past tasks, an online schedule generator is proposed to pick up the most suitable model and generate a personalized training regime with respect to each desired task in a one-shot fashion. The resulting model zoo is more training efficient than SOTA models, e.g. 6x faster than RegNetY-16GF, and 1.7x faster than EfficientNetB3. Experiments on multiple datasets also show that NASOA achieves much better fine-tuning results, i.e. improving around 2.1% accuracy than the best performance in RegNet series under various constraints and tasks; 40x faster compared to the BOHB.
Towards a Theoretical Framework of Out-of-Distribution Generalization
Jun 13, 2021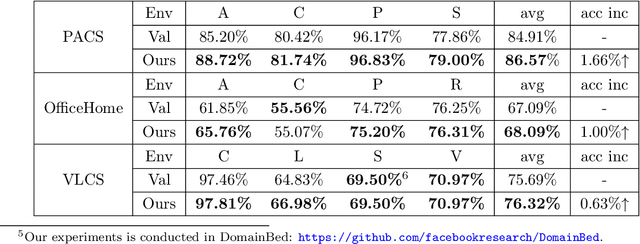
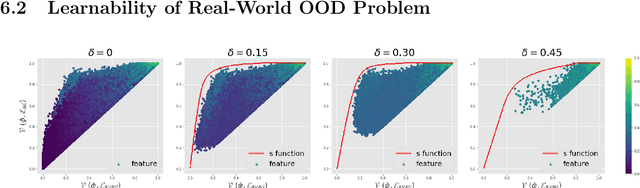

Generalization to out-of-distribution (OOD) data, or domain generalization, is one of the central problems in modern machine learning. Recently, there is a surge of attempts to propose algorithms for OOD that mainly build upon the idea of extracting invariant features. Although intuitively reasonable, theoretical understanding of what kind of invariance can guarantee OOD generalization is still limited, and generalization to arbitrary out-of-distribution is clearly impossible. In this work, we take the first step towards rigorous and quantitative definitions of 1) what is OOD; and 2) what does it mean by saying an OOD problem is learnable. We also introduce a new concept of expansion function, which characterizes to what extent the variance is amplified in the test domains over the training domains, and therefore give a quantitative meaning of invariant features. Based on these, we prove OOD generalization error bounds. It turns out that OOD generalization largely depends on the expansion function. As recently pointed out by Gulrajani and Lopez-Paz (2020), any OOD learning algorithm without a model selection module is incomplete. Our theory naturally induces a model selection criterion. Extensive experiments on benchmark OOD datasets demonstrate that our model selection criterion has a significant advantage over baselines.
Out-of-Distribution Generalization Analysis via Influence Function
Jan 21, 2021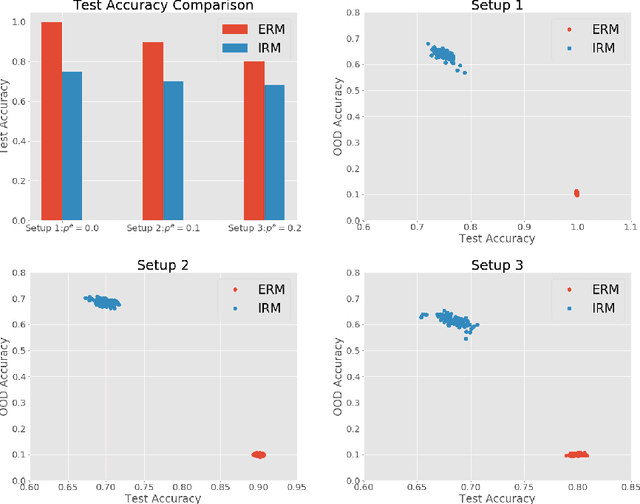
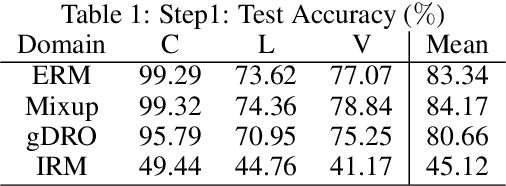
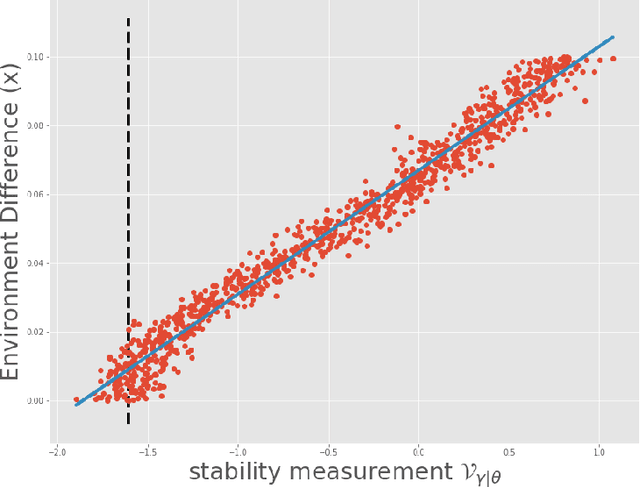

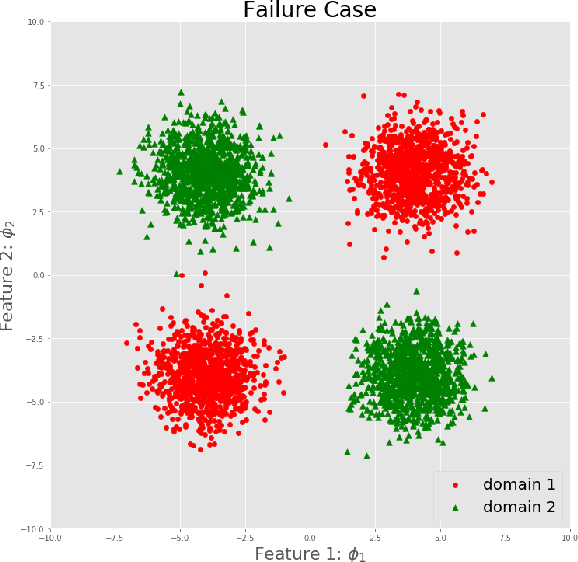
The mismatch between training and target data is one major challenge for current machine learning systems. When training data is collected from multiple domains and the target domains include all training domains and other new domains, we are facing an Out-of-Distribution (OOD) generalization problem that aims to find a model with the best OOD accuracy. One of the definitions of OOD accuracy is worst-domain accuracy. In general, the set of target domains is unknown, and the worst over target domains may be unseen when the number of observed domains is limited. In this paper, we show that the worst accuracy over the observed domains may dramatically fail to identify the OOD accuracy. To this end, we introduce Influence Function, a classical tool from robust statistics, into the OOD generalization problem and suggest the variance of influence function to monitor the stability of a model on training domains. We show that the accuracy on test domains and the proposed index together can help us discern whether OOD algorithms are needed and whether a model achieves good OOD generalization.
MetaAugment: Sample-Aware Data Augmentation Policy Learning
Dec 22, 2020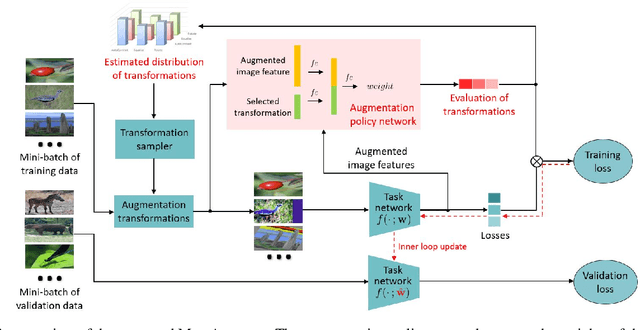
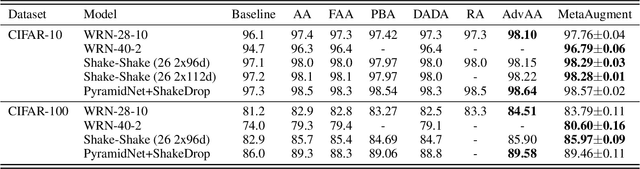
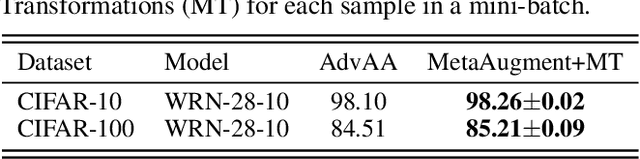
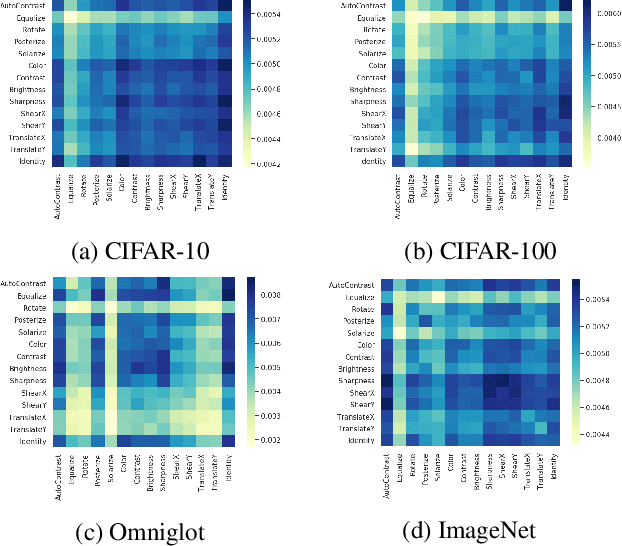
Automated data augmentation has shown superior performance in image recognition. Existing works search for dataset-level augmentation policies without considering individual sample variations, which are likely to be sub-optimal. On the other hand, learning different policies for different samples naively could greatly increase the computing cost. In this paper, we learn a sample-aware data augmentation policy efficiently by formulating it as a sample reweighting problem. Specifically, an augmentation policy network takes a transformation and the corresponding augmented image as inputs, and outputs a weight to adjust the augmented image loss computed by a task network. At training stage, the task network minimizes the weighted losses of augmented training images, while the policy network minimizes the loss of the task network on a validation set via meta-learning. We theoretically prove the convergence of the training procedure and further derive the exact convergence rate. Superior performance is achieved on widely-used benchmarks including CIFAR-10/100, Omniglot, and ImageNet.