 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Cross-Point Embeddings for 3D Dense Uncertainty Estimation
Sep 29, 2022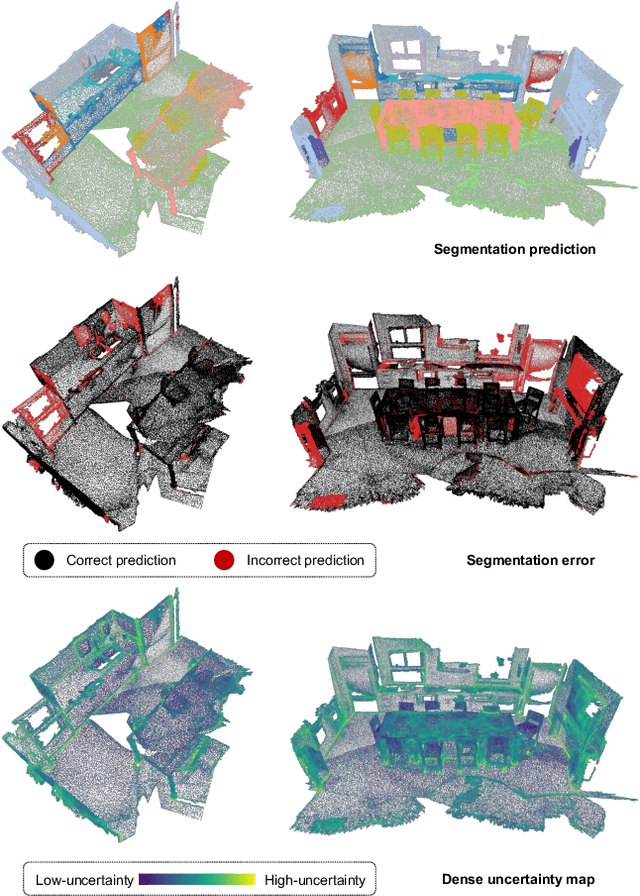
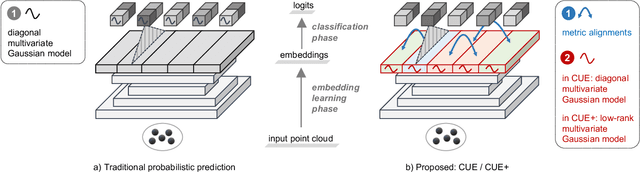
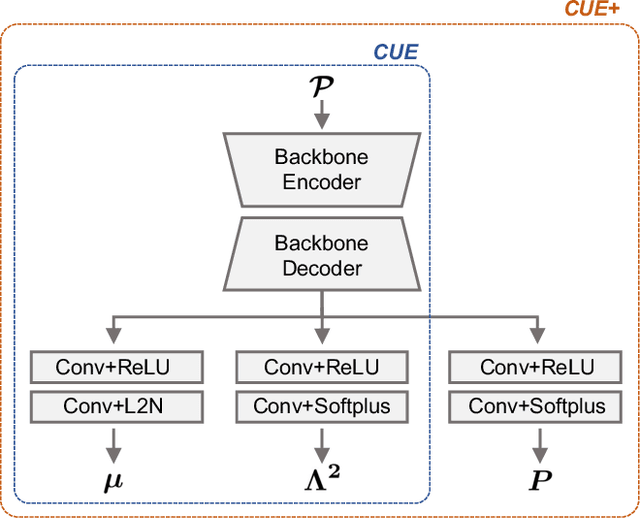
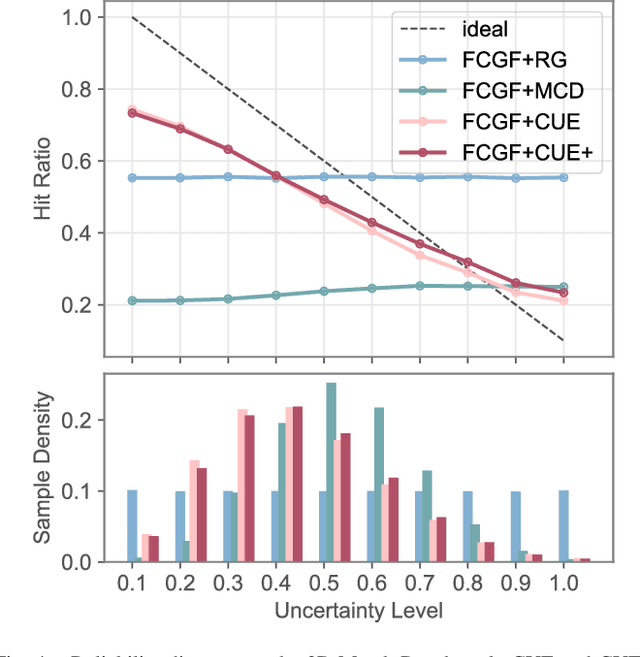
Dense prediction tasks are common for 3D point clouds, but the inherent uncertainties in massive points and their embeddings have long been ignored. In this work, we present CUE, a novel uncertainty estimation method for dense prediction tasks of 3D point clouds. Inspired by metric learning, the key idea of CUE is to explore cross-point embeddings upon a conventional dense prediction pipeline. Specifically, CUE involves building a probabilistic embedding model and then enforcing metric alignments of massive points in the embedding space. We demonstrate that CUE is a generic and effective tool for dense uncertainty estimation of 3D point clouds in two different tasks: (1) in 3D geometric feature learning we for the first time obtain well-calibrated dense uncertainty, and (2) in semantic segmentation we reduce uncertainty`s Expected Calibration Error of the state-of-the-arts by 43.8%. All uncertainties are estimated without compromising predictive performance.
GaitFi: Robust Device-Free Human Identification via WiFi and Vision Multimodal Learning
Aug 30, 2022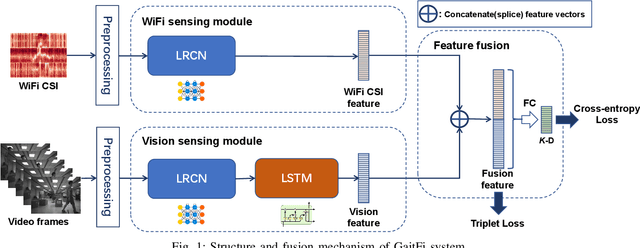

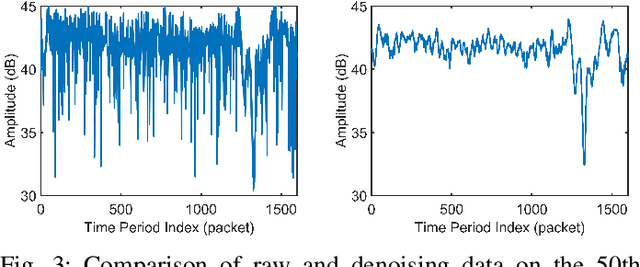
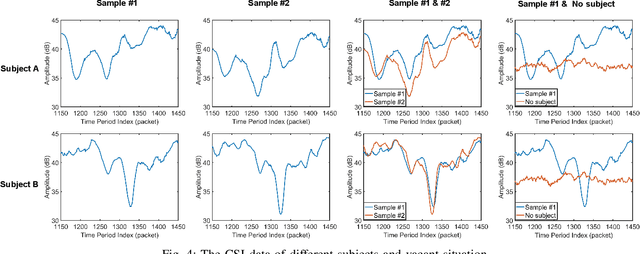
As an important biomarker for human identification, human gait can be collected at a distance by passive sensors without subject cooperation, which plays an essential role in crime prevention, security detection and other human identification applications. At present, most research works are based on cameras and computer vision techniques to perform gait recognition. However, vision-based methods are not reliable when confronting poor illuminations, leading to degrading performances. In this paper, we propose a novel multimodal gait recognition method, namely GaitFi, which leverages WiFi signals and videos for human identification. In GaitFi, Channel State Information (CSI) that reflects the multi-path propagation of WiFi is collected to capture human gaits, while videos are captured by cameras. To learn robust gait information, we propose a Lightweight Residual Convolution Network (LRCN) as the backbone network, and further propose the two-stream GaitFi by integrating WiFi and vision features for the gait retrieval task. The GaitFi is trained by the triplet loss and classification loss on different levels of features. Extensive experiments are conducted in the real world, which demonstrates that the GaitFi outperforms state-of-the-art gait recognition methods based on single WiFi or camera, achieving 94.2% for human identification tasks of 12 subjects.
Cross Vision-RF Gait Re-identification with Low-cost RGB-D Cameras and mmWave Radars
Jul 16, 2022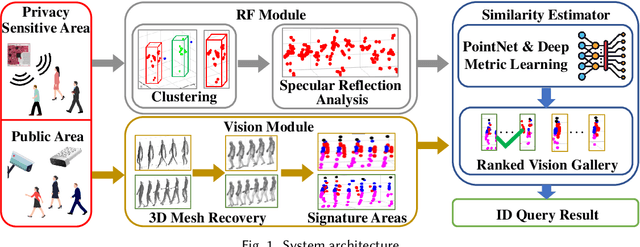
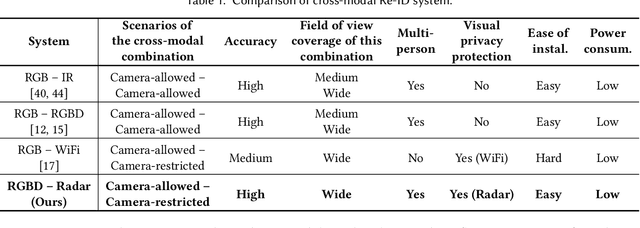
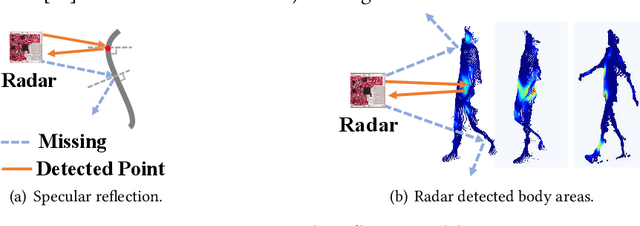
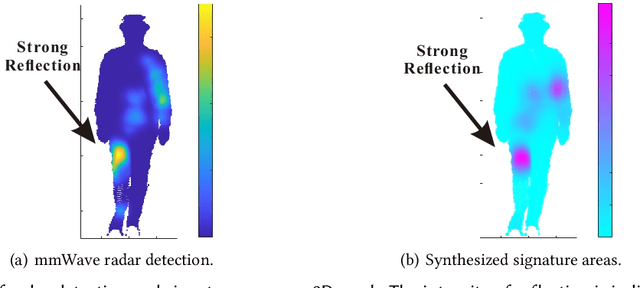
Human identification is a key requirement for many applications in everyday life, such as personalized services, automatic surveillance, continuous authentication, and contact tracing during pandemics, etc. This work studies the problem of cross-modal human re-identification (ReID), in response to the regular human movements across camera-allowed regions (e.g., streets) and camera-restricted regions (e.g., offices) deployed with heterogeneous sensors. By leveraging the emerging low-cost RGB-D cameras and mmWave radars, we propose the first-of-its-kind vision-RF system for cross-modal multi-person ReID at the same time. Firstly, to address the fundamental inter-modality discrepancy, we propose a novel signature synthesis algorithm based on the observed specular reflection model of a human body. Secondly, an effective cross-modal deep metric learning model is introduced to deal with interference caused by unsynchronized data across radars and cameras. Through extensive experiments in both indoor and outdoor environments, we demonstrate that our proposed system is able to achieve ~92.5% top-1 accuracy and ~97.5% top-5 accuracy out of 56 volunteers. We also show that our proposed system is able to robustly reidentify subjects even when multiple subjects are present in the sensors' field of view.
Deep Learning and Its Applications to WiFi Human Sensing: A Benchmark and A Tutorial
Jul 16, 2022
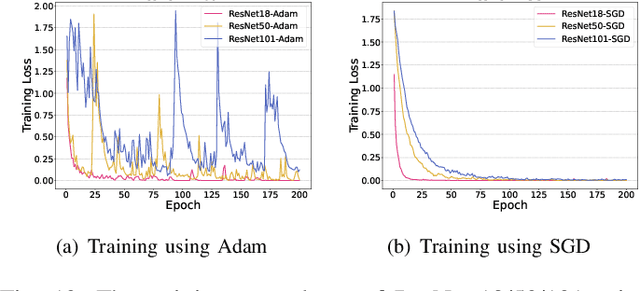
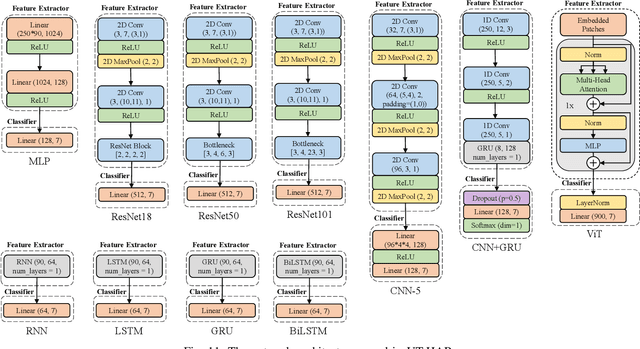
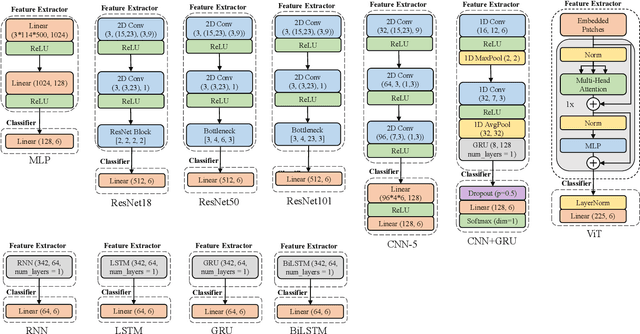
WiFi sensing has been evolving rapidly in recent years. Empowered by propagation models and deep learning methods, many challenging applications are realized such as WiFi-based human activity recognition and gesture recognition. However, in contrast to deep learning for visual recognition and natural language processing, no sufficiently comprehensive public benchmark exists. In this paper, we highlight the recent progress on deep learning enabled WiFi sensing, and then propose a benchmark, SenseFi, to study the effectiveness of various deep learning models for WiFi sensing. These advanced models are compared in terms of distinct sensing tasks, WiFi platforms, recognition accuracy, model size, computational complexity, feature transferability, and adaptability of unsupervised learning. It is also regarded as a tutorial for deep learning based WiFi sensing, starting from CSI hardware platform to sensing algorithms. The extensive experiments provide us with experiences in deep model design, learning strategy skills and training techniques for real-world applications. To the best of our knowledge, this is the first benchmark with an open-source library for deep learning in WiFi sensing research. The benchmark codes are available at https://github.com/CHENXINYAN-sg/WiFi-CSI-Sensing-Benchmark.
OdomBeyondVision: An Indoor Multi-modal Multi-platform Odometry Dataset Beyond the Visible Spectrum
Jun 03, 2022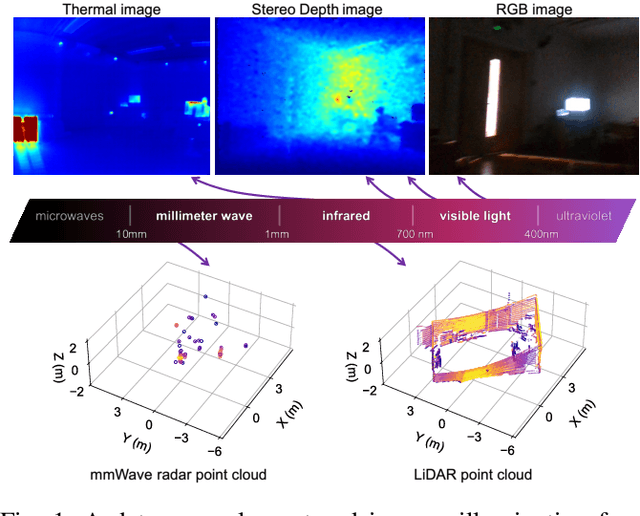
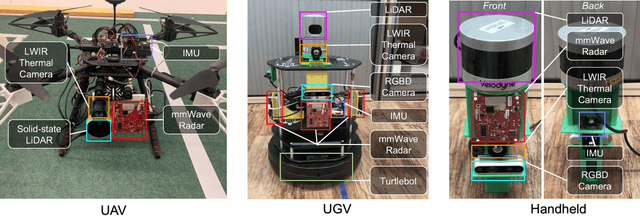


This paper presents a multimodal indoor odometry dataset, OdomBeyondVision, featuring multiple sensors across the different spectrum and collected with different mobile platforms. Not only does OdomBeyondVision contain the traditional navigation sensors, sensors such as IMUs, mechanical LiDAR, RGBD camera, it also includes several emerging sensors such as the single-chip mmWave radar, LWIR thermal camera and solid-state LiDAR. With the above sensors on UAV, UGV and handheld platforms, we respectively recorded the multimodal odometry data and their movement trajectories in various indoor scenes and different illumination conditions. We release the exemplar radar, radar-inertial and thermal-inertial odometry implementations to demonstrate their results for future works to compare against and improve upon. The full dataset including toolkit and documentation is publicly available at: https://github.com/MAPS-Lab/OdomBeyondVision.
STUN: Self-Teaching Uncertainty Estimation for Place Recognition
Mar 03, 2022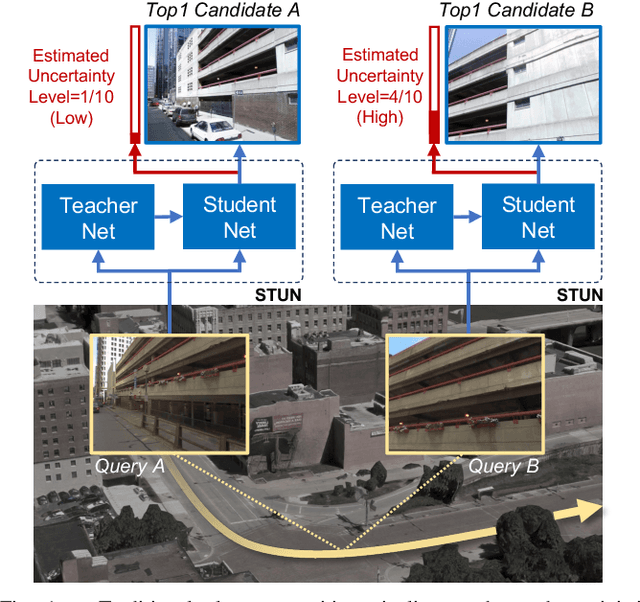
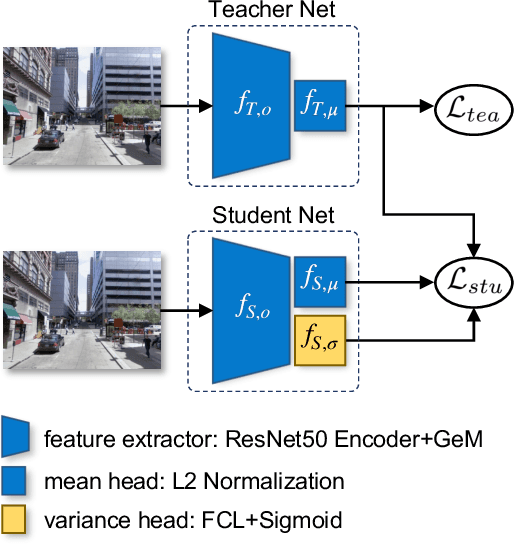
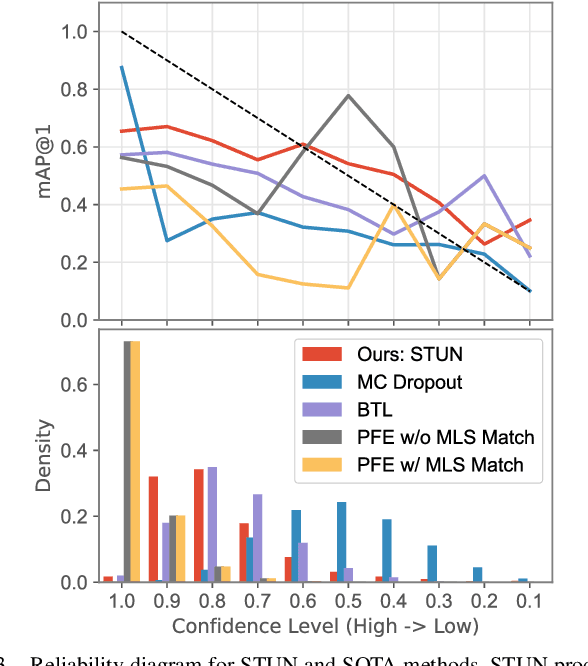
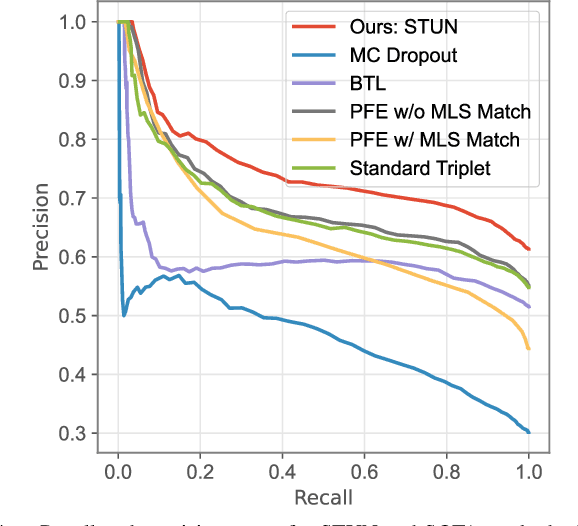
Place recognition is key to Simultaneous Localization and Mapping (SLAM) and spatial perception. However, a place recognition in the wild often suffers from erroneous predictions due to image variations, e.g., changing viewpoints and street appearance. Integrating uncertainty estimation into the life cycle of place recognition is a promising method to mitigate the impact of variations on place recognition performance. However, existing uncertainty estimation approaches in this vein are either computationally inefficient (e.g., Monte Carlo dropout) or at the cost of dropped accuracy. This paper proposes STUN, a self-teaching framework that learns to simultaneously predict the place and estimate the prediction uncertainty given an input image. To this end, we first train a teacher net using a standard metric learning pipeline to produce embedding priors. Then, supervised by the pretrained teacher net, a student net with an additional variance branch is trained to finetune the embedding priors and estimate the uncertainty sample by sample. During the online inference phase, we only use the student net to generate a place prediction in conjunction with the uncertainty. When compared with place recognition systems that are ignorant to the uncertainty, our framework features the uncertainty estimation for free without sacrificing any prediction accuracy. Our experimental results on the large-scale Pittsburgh30k dataset demonstrate that STUN outperforms the state-of-the-art methods in both recognition accuracy and the quality of uncertainty estimation.
Self-Supervised Scene Flow Estimation with 4D Automotive Radar
Mar 02, 2022
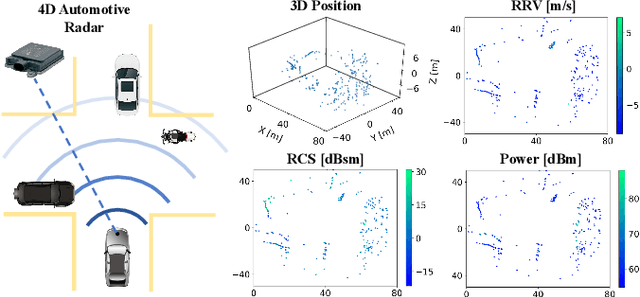
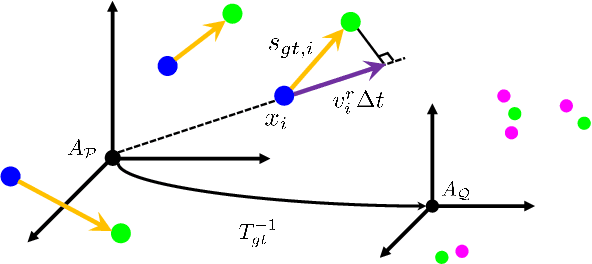
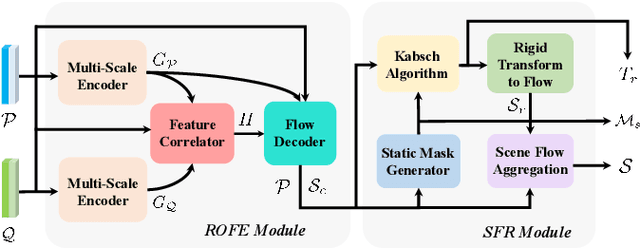
Scene flow allows autonomous vehicles to reason about the arbitrary motion of multiple independent objects which is the key to long-term mobile autonomy. While estimating the scene flow from LiDAR has progressed recently, it remains largely unknown how to estimate the scene flow from a 4D radar - an increasingly popular automotive sensor for its robustness against adverse weather and lighting conditions. Compared with the LiDAR point clouds, radar data are drastically sparser, noisier and in much lower resolution. Annotated datasets for radar scene flow are also in absence and costly to acquire in the real world. These factors jointly pose the radar scene flow estimation as a challenging problem. This work aims to address the above challenges and estimate scene flow from 4D radar point clouds by leveraging self-supervised learning. A robust scene flow estimation architecture and three novel losses are bespoken designed to cope with intractable radar data. Real-world experimental results validate that our method is able to robustly estimate the radar scene flow in the wild and effectively supports the downstream task of motion segmentation.
Accurate Automotive Radar Based Metric Localization with Explicit Doppler Compensation
Dec 30, 2021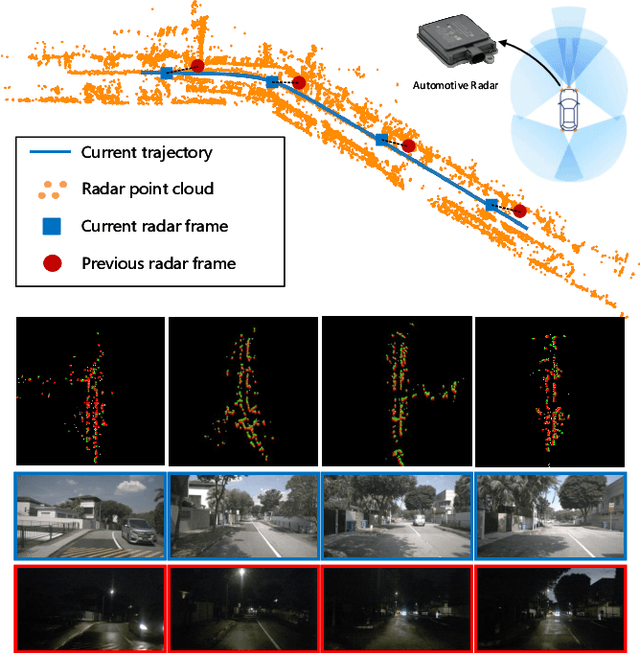
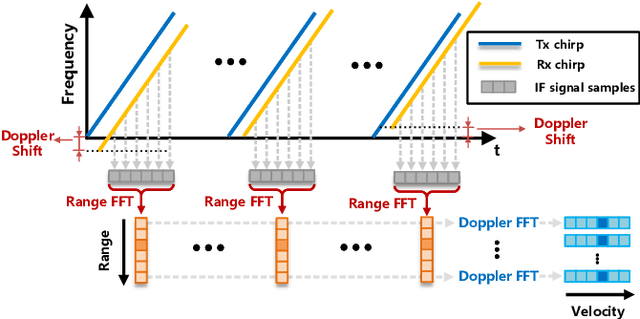
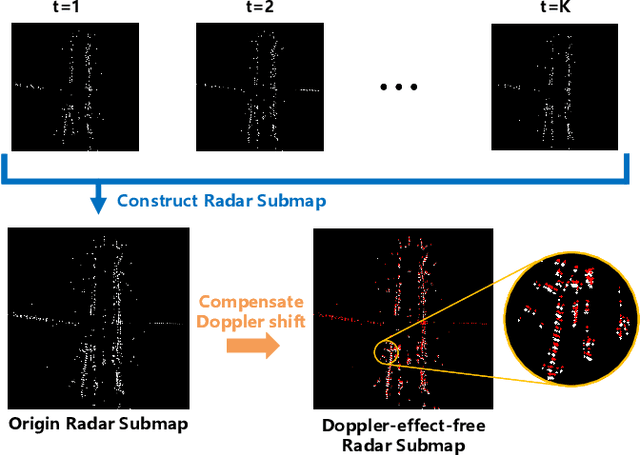

Automotive mmWave radar has been widely used in the automotive industry due to its small size, low cost, and complementary advantages to optical sensors (cameras, LiDAR, etc.) in adverse weathers, e.g., fog, raining, and snowing. On the other side, its large wavelength also poses fundamental challenges to perceive the environment. Recent advances have made breakthroughs on its inherent drawbacks, i.e., the multipath reflection and the sparsity of mmWave radar's point clouds. However, the lower frequency of mmWave signals is more sensitive to vehicles' mobility than that of the visual and laser signals. This work focuses on the problem of frequency shift, i.e., the Doppler effect distorts the radar ranging measurements and its knock-on effect on metric localization. We propose a new radar-based metric localization framework that obtains more accurate location estimation by restoring the Doppler distortion. Specifically, we first design a new algorithm that explicitly compensates the Doppler distortion of radar scans and then model the measurement uncertainty of the Doppler-compensated point cloud to further optimize the metric localization. Extensive experiments using the public nuScenes dataset and Carla simulator demonstrate that our method outperforms the state-of-the-art approach by 19.2\% and 13.5\% improvements in terms of translation and rotation errors, respectively.
Multiagent Model-based Credit Assignment for Continuous Control
Dec 27, 2021
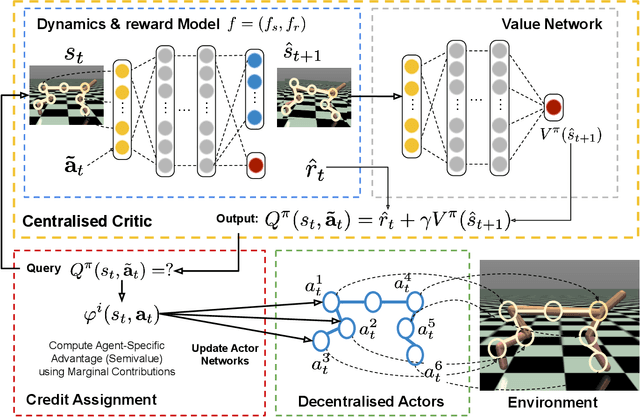
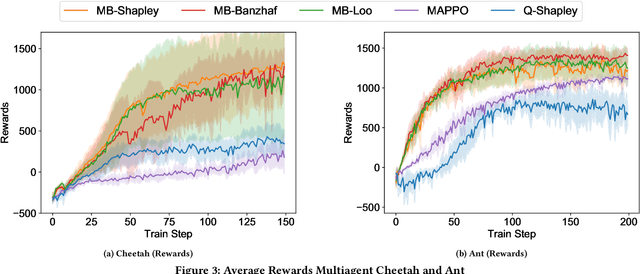
Deep reinforcement learning (RL) has recently shown great promise in robotic continuous control tasks. Nevertheless, prior research in this vein center around the centralized learning setting that largely relies on the communication availability among all the components of a robot. However, agents in the real world often operate in a decentralised fashion without communication due to latency requirements, limited power budgets and safety concerns. By formulating robotic components as a system of decentralised agents, this work presents a decentralised multiagent reinforcement learning framework for continuous control. To this end, we first develop a cooperative multiagent PPO framework that allows for centralized optimisation during training and decentralised operation during execution. However, the system only receives a global reward signal which is not attributed towards each agent. To address this challenge, we further propose a generic game-theoretic credit assignment framework which computes agent-specific reward signals. Last but not least, we also incorporate a model-based RL module into our credit assignment framework, which leads to significant improvement in sample efficiency. We demonstrate the effectiveness of our framework on experimental results on Mujoco locomotion control tasks. For a demo video please visit: https://youtu.be/gFyVPm4svEY.
Deep Odometry Systems on Edge with EKF-LoRa Backend for Real-Time Positioning in Adverse Environment
Dec 10, 2021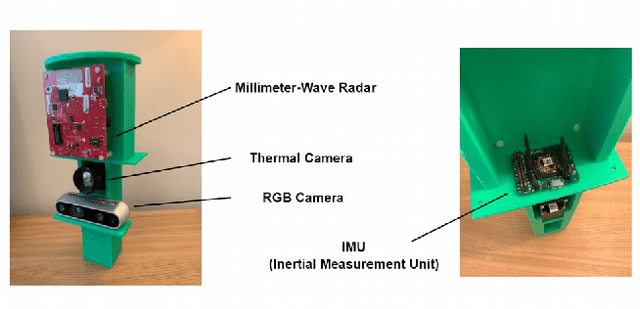
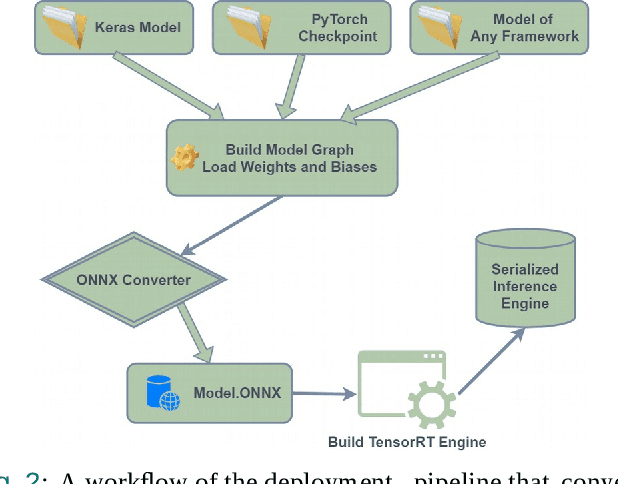
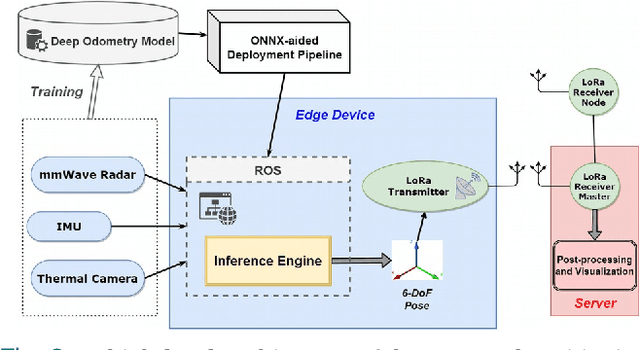
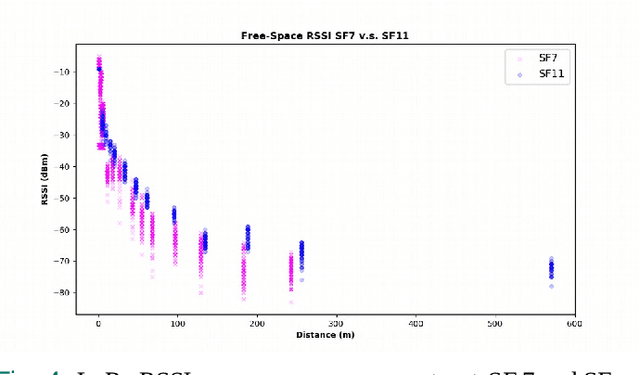
Ubiquitous positioning for pedestrian in adverse environment has served a long standing challenge. Despite dramatic progress made by Deep Learning, multi-sensor deep odometry systems yet pose a high computational cost and suffer from cumulative drifting errors over time. Thanks to the increasing computational power of edge devices, we propose a novel ubiquitous positioning solution by integrating state-of-the-art deep odometry models on edge with an EKF (Extended Kalman Filter)-LoRa backend. We carefully compare and select three sensor modalities, i.e., an Inertial Measurement Unit (IMU), a millimetre-wave (mmWave) radar, and a thermal infrared camera, and realise their deep odometry inference engines which runs in real-time. A pipeline of deploying deep odometry considering accuracy, complexity, and edge platform is proposed. We design a LoRa link for positional data backhaul and projecting aggregated positions of deep odometry into the global frame. We find that a simple EKF based fusion module is sufficient for generic positioning calibration with over 34% accuracy gains against any standalone deep odometry system. Extensive tests in different environments validate the efficiency and efficacy of our proposed positioning system.