 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Reinforcement Learning with a Short-Term Memory
Feb 08, 2022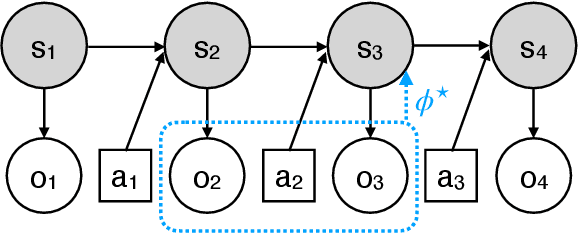
Real-world sequential decision making problems commonly involve partial observability, which requires the agent to maintain a memory of history in order to infer the latent states, plan and make good decisions. Coping with partial observability in general is extremely challenging, as a number of worst-case statistical and computational barriers are known in learning Partially Observable Markov Decision Processes (POMDPs). Motivated by the problem structure in several physical applications, as well as a commonly used technique known as "frame stacking", this paper proposes to study a new subclass of POMDPs, whose latent states can be decoded by the most recent history of a short length $m$. We establish a set of upper and lower bounds on the sample complexity for learning near-optimal policies for this class of problems in both tabular and rich-observation settings (where the number of observations is enormous). In particular, in the rich-observation setting, we develop new algorithms using a novel "moment matching" approach with a sample complexity that scales exponentially with the short length $m$ rather than the problem horizon, and is independent of the number of observations. Our results show that a short-term memory suffices for reinforcement learning in these environments.
Near-Optimal Learning of Extensive-Form Games with Imperfect Information
Feb 03, 2022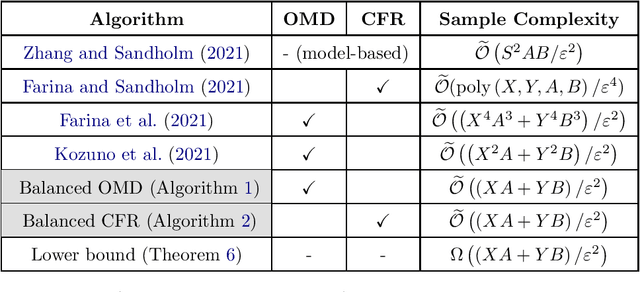
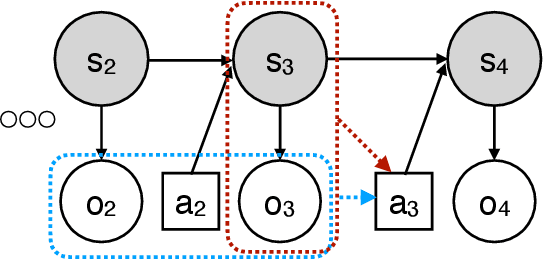
This paper resolves the open question of designing near-optimal algorithms for learning imperfect-information extensive-form games from bandit feedback. We present the first line of algorithms that require only $\widetilde{\mathcal{O}}((XA+YB)/\varepsilon^2)$ episodes of play to find an $\varepsilon$-approximate Nash equilibrium in two-player zero-sum games, where $X,Y$ are the number of information sets and $A,B$ are the number of actions for the two players. This improves upon the best known sample complexity of $\widetilde{\mathcal{O}}((X^2A+Y^2B)/\varepsilon^2)$ by a factor of $\widetilde{\mathcal{O}}(\max\{X, Y\})$, and matches the information-theoretic lower bound up to logarithmic factors. We achieve this sample complexity by two new algorithms: Balanced Online Mirror Descent, and Balanced Counterfactual Regret Minimization. Both algorithms rely on novel approaches of integrating \emph{balanced exploration policies} into their classical counterparts. We also extend our results to learning Coarse Correlated Equilibria in multi-player general-sum games.
Globally convergent visual-feature range estimation with biased inertial measurements
Dec 23, 2021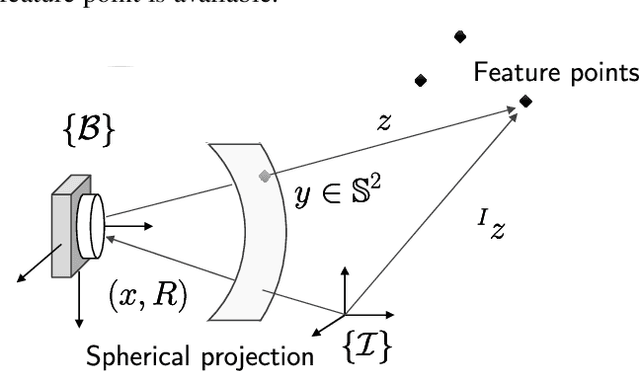
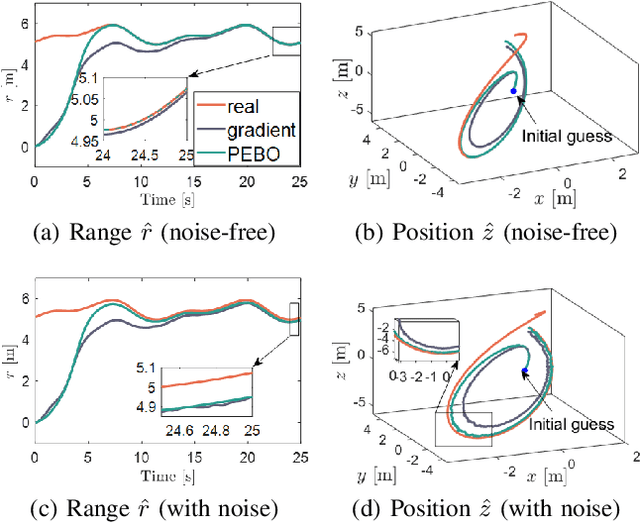
The design of a globally convergent position observer for feature points from visual information is a challenging problem, especially for the case with only inertial measurements and without assumptions of uniform observability, which remained open for a long time. We give a solution to the problem in this paper assuming that only the bearing of a feature point, and biased linear acceleration and rotational velocity of a robot -- all in the body-fixed frame -- are available. Further, in contrast to existing related results, we do not need the value of the gravitational constant either. The proposed approach builds upon the parameter estimation-based observer recently developed in (Ortega et al., Syst. Control. Lett., vol.85, 2015) and its extension to matrix Lie groups in our previous work. Conditions on the robot trajectory under which the observer converges are given, and these are strictly weaker than the standard persistency of excitation and uniform complete observability conditions. Finally, we apply the proposed design to the visual inertial navigation problem. Simulation results are also presented to illustrate our observer design.
V-Learning -- A Simple, Efficient, Decentralized Algorithm for Multiagent RL
Oct 27, 2021
A major challenge of multiagent reinforcement learning (MARL) is the curse of multiagents, where the size of the joint action space scales exponentially with the number of agents. This remains to be a bottleneck for designing efficient MARL algorithms even in a basic scenario with finitely many states and actions. This paper resolves this challenge for the model of episodic Markov games. We design a new class of fully decentralized algorithms -- V-learning, which provably learns Nash equilibria (in the two-player zero-sum setting), correlated equilibria and coarse correlated equilibria (in the multiplayer general-sum setting) in a number of samples that only scales with $\max_{i\in[m]} A_i$, where $A_i$ is the number of actions for the $i^{\rm th}$ player. This is in sharp contrast to the size of the joint action space which is $\prod_{i=1}^m A_i$. V-learning (in its basic form) is a new class of single-agent RL algorithms that convert any adversarial bandit algorithm with suitable regret guarantees into a RL algorithm. Similar to the classical Q-learning algorithm, it performs incremental updates to the value functions. Different from Q-learning, it only maintains the estimates of V-values instead of Q-values. This key difference allows V-learning to achieve the claimed guarantees in the MARL setting by simply letting all agents run V-learning independently.
Understanding Domain Randomization for Sim-to-real Transfer
Oct 07, 2021


Reinforcement learning encounters many challenges when applied directly in the real world. Sim-to-real transfer is widely used to transfer the knowledge learned from simulation to the real world. Domain randomization -- one of the most popular algorithms for sim-to-real transfer -- has been demonstrated to be effective in various tasks in robotics and autonomous driving. Despite its empirical successes, theoretical understanding on why this simple algorithm works is limited. In this paper, we propose a theoretical framework for sim-to-real transfers, in which the simulator is modeled as a set of MDPs with tunable parameters (corresponding to unknown physical parameters such as friction). We provide sharp bounds on the sim-to-real gap -- the difference between the value of policy returned by domain randomization and the value of an optimal policy for the real world. We prove that sim-to-real transfer can succeed under mild conditions without any real-world training samples. Our theory also highlights the importance of using memory (i.e., history-dependent policies) in domain randomization. Our proof is based on novel techniques that reduce the problem of bounding the sim-to-real gap to the problem of designing efficient learning algorithms for infinite-horizon MDPs, which we believe are of independent interest.
A Simple Reward-free Approach to Constrained Reinforcement Learning
Jul 12, 2021
In constrained reinforcement learning (RL), a learning agent seeks to not only optimize the overall reward but also satisfy the additional safety, diversity, or budget constraints. Consequently, existing constrained RL solutions require several new algorithmic ingredients that are notably different from standard RL. On the other hand, reward-free RL is independently developed in the unconstrained literature, which learns the transition dynamics without using the reward information, and thus naturally capable of addressing RL with multiple objectives under the common dynamics. This paper bridges reward-free RL and constrained RL. Particularly, we propose a simple meta-algorithm such that given any reward-free RL oracle, the approachability and constrained RL problems can be directly solved with negligible overheads in sample complexity. Utilizing the existing reward-free RL solvers, our framework provides sharp sample complexity results for constrained RL in the tabular MDP setting, matching the best existing results up to a factor of horizon dependence; our framework directly extends to a setting of tabular two-player Markov games, and gives a new result for constrained RL with linear function approximation.
The Power of Exploiter: Provable Multi-Agent RL in Large State Spaces
Jun 07, 2021Modern reinforcement learning (RL) commonly engages practical problems with large state spaces, where function approximation must be deployed to approximate either the value function or the policy. While recent progresses in RL theory address a rich set of RL problems with general function approximation, such successes are mostly restricted to the single-agent setting. It remains elusive how to extend these results to multi-agent RL, especially due to the new challenges arising from its game-theoretical nature. This paper considers two-player zero-sum Markov Games (MGs). We propose a new algorithm that can provably find the Nash equilibrium policy using a polynomial number of samples, for any MG with low multi-agent Bellman-Eluder dimension -- a new complexity measure adapted from its single-agent version (Jin et al., 2021). A key component of our new algorithm is the exploiter, which facilitates the learning of the main player by deliberately exploiting her weakness. Our theoretical framework is generic, which applies to a wide range of models including but not limited to tabular MGs, MGs with linear or kernel function approximation, and MGs with rich observations.
Minimax Optimization with Smooth Algorithmic Adversaries
Jun 02, 2021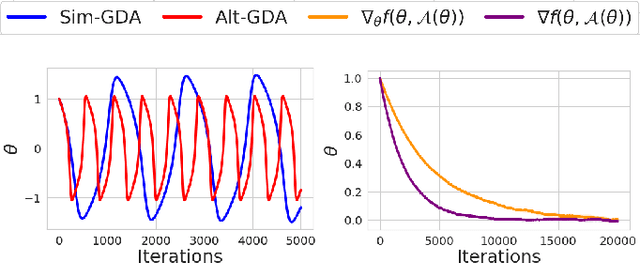

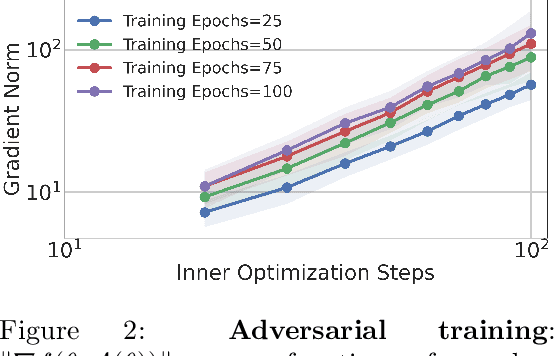

This paper considers minimax optimization $\min_x \max_y f(x, y)$ in the challenging setting where $f$ can be both nonconvex in $x$ and nonconcave in $y$. Though such optimization problems arise in many machine learning paradigms including training generative adversarial networks (GANs) and adversarially robust models, many fundamental issues remain in theory, such as the absence of efficiently computable optimality notions, and cyclic or diverging behavior of existing algorithms. Our framework sprouts from the practical consideration that under a computational budget, the max-player can not fully maximize $f(x,\cdot)$ since nonconcave maximization is NP-hard in general. So, we propose a new algorithm for the min-player to play against smooth algorithms deployed by the adversary (i.e., the max-player) instead of against full maximization. Our algorithm is guaranteed to make monotonic progress (thus having no limit cycles), and to find an appropriate "stationary point" in a polynomial number of iterations. Our framework covers practical settings where the smooth algorithms deployed by the adversary are multi-step stochastic gradient ascent, and its accelerated version. We further provide complementing experiments that confirm our theoretical findings and demonstrate the effectiveness of the proposed approach in practice.
An almost globally convergent observer for visual SLAM without persistent excitation
Apr 07, 2021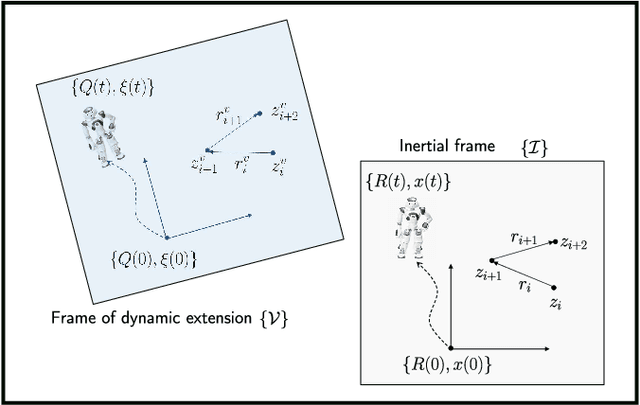
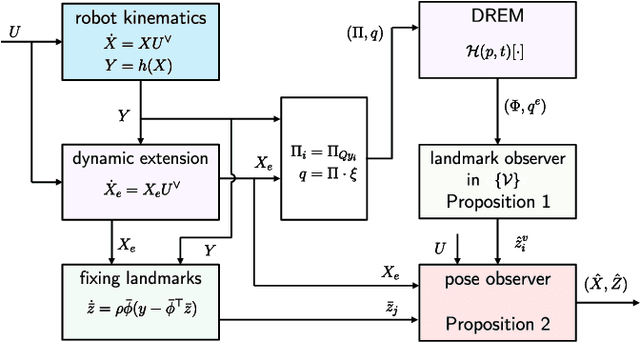
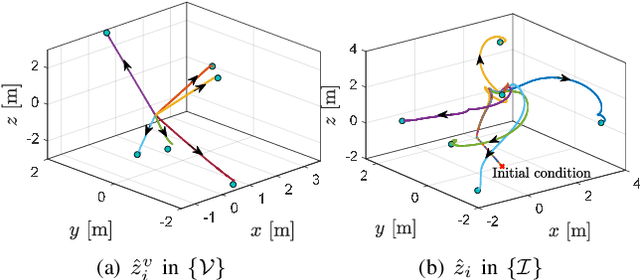
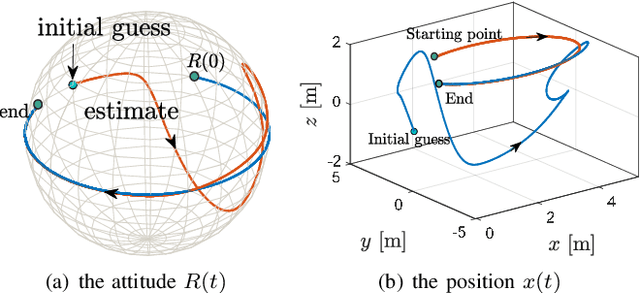
In this paper we propose a novel observer to solve the problem of visual simultaneous localization and mapping, using the information of only the bearing vectors of landmarks observed from a single monocular camera and body-fixed velocities. The system state evolves on the manifold $SE(3)\times \mathbb{R}^{3n}$, on which we design dynamic extensions carefully in order to generate an invariant foliation, such that the problem is reformulated into online parameter identification. Then, following the recently introduced parameter estimation-based observer, we provide a novel and simple solution to address the problem. A notable merit is that the proposed observer guarantees almost global asymptotic stability requiring neither persistent excitation nor uniform complete observability, which, however, are widely adopted in the existing works.
Risk Bounds and Rademacher Complexity in Batch Reinforcement Learning
Mar 25, 2021
This paper considers batch Reinforcement Learning (RL) with general value function approximation. Our study investigates the minimal assumptions to reliably estimate/minimize Bellman error, and characterizes the generalization performance by (local) Rademacher complexities of general function classes, which makes initial steps in bridging the gap between statistical learning theory and batch RL. Concretely, we view the Bellman error as a surrogate loss for the optimality gap, and prove the followings: (1) In double sampling regime, the excess risk of Empirical Risk Minimizer (ERM) is bounded by the Rademacher complexity of the function class. (2) In the single sampling regime, sample-efficient risk minimization is not possible without further assumptions, regardless of algorithms. However, with completeness assumptions, the excess risk of FQI and a minimax style algorithm can be again bounded by the Rademacher complexity of the corresponding function classes. (3) Fast statistical rates can be achieved by using tools of local Rademacher complexity. Our analysis covers a wide range of function classes, including finite classes, linear spaces, kernel spaces, sparse linear features, etc.