 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCOB: Learning to Utilize and Evolve Agentic Skills via Credit-Aware On-Policy Bidirectional Self-Distillation
Jun 28, 2026Skill memories can improve agentic reinforcement learning by reusing past experience as textual guidance, but retrieved skills are not oracular: they may help in one state while misleading the same policy in another. This makes the common privileged-teacher assumption fragile, namely that a skill-conditioned prompt can be treated as a fixed teacher for the no-skill prompt. We introduce UCOB, a framework for learning to utilize and evolve agentic skills via credit-aware on-policy bidirectional self-distillation. UCOB treats skill-conditioned and no-skill prompts as two on-policy context views of the same model, compares their return-to-go within the same task and anchor state, and uses the higher-return view as the local teacher. This local credit signal internalizes useful skill-conditioned behavior, corrects misleading skill usage, and guides task/state skill memory updates, utility-aware retrieval, and reflection self-training. Experiments on agentic tasks, including ALFWorld, WebShop, and Search-QA, show that UCOB outperforms skill-free RL, skill-memory baselines, and self-distillation methods across model scales, with up to 23.5 and 18.0 point gains over SOTA baselines on ALFWorld and WebShop. Ablations and analyses further validate its core mechanisms and efficiency.
MotionHalluc: Diagnosing Kinematic Hallucinations in Fine-Grained Motion Reasoning
Jun 22, 2026Motion instruction generation in cross-video comparison aims to produce corrective feedback that describes the differences between a query and a reference motion. However, existing models often generate instructions that exhibit motion hallucinations, failing to reflect actual kinematic differences between paired videos. To systematically investigate these hallucinations, we introduce MotionHalluc, a dedicated benchmark for evaluating motion hallucinations in paired-video comparison. MotionHalluc comprises 1540 fine-grained questions over 553 video pairs, evaluating hallucinations along three core dimensions: (1)directional hallucination, (2)attributional hallucination, and (3)temporal hallucination. Extensive evaluations of state-of-the-art large multimodal models demonstrate high susceptibility to these hallucinations. Furthermore, we provide Perceive-Parse-Verify (PPV) as a training-free measurements extraction and verification baseline that converts candidate instructions into executable measurement queries and supplies kinematic measurements at inference time. Our results show that this simple measurements injection yields an average 10.6% performance gain across models, suggesting that motion reasoning with explicit quantitative measurements is a key factor in reducing hallucinations in cross-video comparison. Our code and dataset will be made publicly available upon acceptance.
Adaptive Coarse-to-Fine Subgoal Refinement for Long-Horizon Offline Goal-Conditioned Reinforcement Learning
May 27, 2026Offline goal-conditioned reinforcement learning (GCRL) is challenging in long-horizon tasks, where distant state--goal pairs provide weak supervision and value estimates become vulnerable to accumulated bootstrapping errors. Hierarchical methods mitigate this difficulty by introducing intermediate subgoals, but fixed temporal abstractions or fixed hierarchy depths can be mismatched to state--goal pairs with different reachability horizons. We propose Coarse-to-Fine Hierarchical Goal Reinforcement Learning (CFHRL), a fully offline GCRL framework that adaptively refines distant goals before execution. Starting from the final goal, CFHRL recursively proposes intermediate targets, trained from replay-supported candidates, and stops refinement once the current target is estimated to be locally executable by a learned reachability cost. The key idea is that a subgoal need not be an exact midpoint or globally optimal waypoint; it only needs to provide reliable progress and reduce the remaining reaching difficulty, enabling subsequent refinement over shorter horizons. A stylized analysis further supports the robustness of approximate recursive contraction. Experiments on OGBench show substantial gains on several long-horizon tasks, with ablations validating the proposed refinement and stopping mechanisms
Dynamic Dual-Granularity Skill Bank for Agentic RL
Mar 30, 2026Agentic reinforcement learning (RL) can benefit substantially from reusable experience, yet existing skill-based methods mainly extract trajectory-level guidance and often lack principled mechanisms for maintaining an evolving skill memory. We propose D2Skill, a dynamic dual-granularity skill bank for agentic RL that organizes reusable experience into task skills for high-level guidance and step skills for fine-grained decision support and error correction. D2Skill jointly trains the policy and skill bank through paired baseline and skill-injected rollouts under the same policy, using their performance gap to derive hindsight utility signals for both skill updating and policy optimization. Built entirely from training-time experience, the skill bank is continuously expanded through reflection and maintained with utility-aware retrieval and pruning. Experiments on ALFWorld and WebShop with Qwen2.5-7B-Instruct and Qwen3-4B-Instruct-2507 show that D2Skill consistently improves success rates over skill-free baselines by 10-20 points. Further ablations and analyses show that both dual-granularity skill modeling and dynamic skill maintenance are critical to these gains, while the learned skills exhibit higher utility, transfer across evaluation settings, and introduce only modest training overhead.
AndroTMem: From Interaction Trajectories to Anchored Memory in Long-Horizon GUI Agents
Mar 19, 2026Long-horizon GUI agents are a key step toward real-world deployment, yet effective interaction memory under prevailing paradigms remains under-explored. Replaying full interaction sequences is redundant and amplifies noise, while summaries often erase dependency-critical information and traceability. We present AndroTMem, a diagnostic framework for anchored memory in long-horizon Android GUI agents. Its core benchmark, AndroTMem-Bench, comprises 1,069 tasks with 34,473 interaction steps (avg. 32.1 per task, max. 65). We evaluate agents with TCR (Task Complete Rate), focusing on tasks whose completion requires carrying forward critical intermediate state; AndroTMem-Bench is designed to enforce strong step-to-step causal dependencies, making sparse yet essential intermediate states decisive for downstream actions and centering interaction memory in evaluation. Across open- and closed-source GUI agents, we observe a consistent pattern: as interaction sequences grow longer, performance drops are driven mainly by within-task memory failures, not isolated perception errors or local action mistakes. Guided by this diagnosis, we propose Anchored State Memory (ASM), which represents interaction sequences as a compact set of causally linked intermediate-state anchors to enable subgoal-targeted retrieval and attribution-aware decision making. Across multiple settings and 12 evaluated GUI agents, ASM consistently outperforms full-sequence replay and summary-based baselines, improving TCR by 5%-30.16% and AMS by 4.93%-24.66%, indicating that anchored, structured memory effectively mitigates the interaction-memory bottleneck in long-horizon GUI tasks. The code, benchmark, and related resources are publicly available at [https://github.com/CVC2233/AndroTMem](https://github.com/CVC2233/AndroTMem).
Context-Picker: Dynamic context selection using multi-stage reinforcement learning
Dec 16, 2025



In long-context question answering (LCQA), determining the optimal amount of context for a given query is a significant challenge. Including too few passages may omit critical information, while including too many can introduce noise and reduce the quality of the answer. Traditional approaches, such as fixed Top-$K$ retrieval and single-stage reranking, face the dilemma of selecting the right number of passages. This problem is particularly pronounced for factoid questions, which often require only a few specific pieces of evidence. To address this issue, we introduce \emph{Context-Picker}, a reasoning-aware framework that shifts the paradigm from similarity-based ranking to minimal sufficient subset selection. Context-Picker treats context selection as a decision-making process optimized via a human-inspired, two-stage reinforcement learning schedule: a \emph{recall-oriented} stage that prioritizes the coverage of reasoning chains, followed by a \emph{precision-oriented} stage that aggressively prunes redundancy to distill a compact evidence set. To resolve reward sparsity, we propose an offline evidence distillation pipeline that mines "minimal sufficient sets" via a Leave-One-Out (LOO) procedure, providing dense, task-aligned supervision. Experiments on five long-context and multi-hop QA benchmarks demonstrate that Context-Picker significantly outperforms strong RAG baselines, achieving superior answer accuracy with comparable or reduced context lengths. Ablation studies indicate that the coarse-to-fine optimization schedule, the redundancy-aware reward shaping, and the rationale-guided format all contribute substantially to these gains.
H$^2$R: Hierarchical Hindsight Reflection for Multi-Task LLM Agents
Sep 16, 2025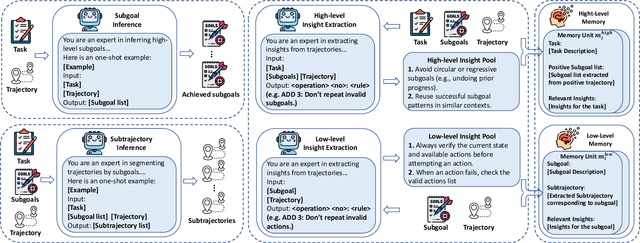
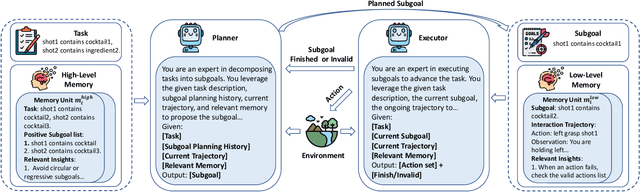
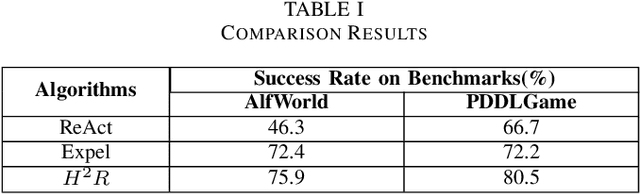

Large language model (LLM)-based agents have shown strong potential in multi-task scenarios, owing to their ability to transfer knowledge across diverse tasks. However, existing approaches often treat prior experiences and knowledge as monolithic units, leading to inefficient and coarse-grained knowledge transfer. In this work, we propose a novel hierarchical memory architecture that enables fine-grained knowledge transfer by decoupling high-level planning memory from low-level execution memory. To construct and refine these hierarchical memories, we introduce Hierarchical Hindsight Reflection (H$^2$R), a mechanism that distills reusable and hierarchical knowledge from past agent-environment interactions. At test time, H$^2$R performs retrievals of high-level and low-level memories separately, allowing LLM-based agents to efficiently access and utilize task-relevant knowledge for new tasks.Experimental results across two benchmarks demonstrate that H$^2$R can improve generalization and decision-making performance, outperforming prior baselines such as Expel.