 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Verdict to Process: Agentic Reinforcement Learning for Multi-Stage Fact Verification
Jun 11, 2026Recent approaches combining Large Language Models (LLMs) with retrieval-augmented reasoning have shown promise for automated fact verification. To process complex claims, these verification pipelines typically execute multi-stage workflows that coordinate tightly coupled modules, including claim decomposition, evidence gathering, and verdict prediction. However, existing methods optimize individual stages in isolation or rely on fixed heuristics, which limits adaptive coordination among stages and can lead to suboptimal outcomes. In this work, we propose ProFact, an agentic reinforcement learning framework for end-to-end optimization of multi-stage fact verification trajectories. ProFact trains a unified policy to coordinate claim decomposition, evidence seeking, answer generation, and verdict prediction. To address the sparse and delayed supervision provided by final veracity labels, ProFact introduces process-aware rewards that provide stage-level learning signals throughout the verification process. Empirical evaluation shows that ProFact consistently outperforms strong baselines in both verification performance and inference efficiency. These results highlight the effectiveness of process-aware trajectory optimization for multi-stage fact verification.
GAGPO: Generalized Advantage Grouped Policy Optimization
May 13, 2026Reinforcement learning has become a powerful paradigm for post-training large language model agents, yet credit assignment in multi-turn environments remains a challenge. Agents often receive sparse, trajectory-level rewards only at the end of an episode, making it difficult to determine which intermediate actions contributed to success or failure. As a result, propagating delayed outcomes back to individual decision steps without relying on costly auxiliary value models remains an open problem. We propose Generalized Advantage Grouped Policy Optimization (GAGPO), a critic-free reinforcement learning method for precise, step-aligned temporal credit assignment. GAGPO constructs a non-parametric grouped value proxy from sampled rollouts and uses it to compute TD/GAE-style temporal advantages, recursively propagating outcome supervision backward through time. Combined with group-wise advantage normalization and an action-level importance ratio, GAGPO extracts stable, localized optimization signals directly from multi-turn trajectories. Experiments on ALFWorld and WebShop show that GAGPO outperforms strong reinforcement learning baselines. Further analyses demonstrate faster early-stage learning, improved interaction efficiency, and smoother optimization dynamics, suggesting that GAGPO offers a simple yet effective framework for multi-turn agentic reinforcement learning.
Context-Picker: Dynamic context selection using multi-stage reinforcement learning
Dec 16, 2025



In long-context question answering (LCQA), determining the optimal amount of context for a given query is a significant challenge. Including too few passages may omit critical information, while including too many can introduce noise and reduce the quality of the answer. Traditional approaches, such as fixed Top-$K$ retrieval and single-stage reranking, face the dilemma of selecting the right number of passages. This problem is particularly pronounced for factoid questions, which often require only a few specific pieces of evidence. To address this issue, we introduce \emph{Context-Picker}, a reasoning-aware framework that shifts the paradigm from similarity-based ranking to minimal sufficient subset selection. Context-Picker treats context selection as a decision-making process optimized via a human-inspired, two-stage reinforcement learning schedule: a \emph{recall-oriented} stage that prioritizes the coverage of reasoning chains, followed by a \emph{precision-oriented} stage that aggressively prunes redundancy to distill a compact evidence set. To resolve reward sparsity, we propose an offline evidence distillation pipeline that mines "minimal sufficient sets" via a Leave-One-Out (LOO) procedure, providing dense, task-aligned supervision. Experiments on five long-context and multi-hop QA benchmarks demonstrate that Context-Picker significantly outperforms strong RAG baselines, achieving superior answer accuracy with comparable or reduced context lengths. Ablation studies indicate that the coarse-to-fine optimization schedule, the redundancy-aware reward shaping, and the rationale-guided format all contribute substantially to these gains.
Pointillism: Accurate 3D bounding box estimation with multi-radars
Mar 08, 2022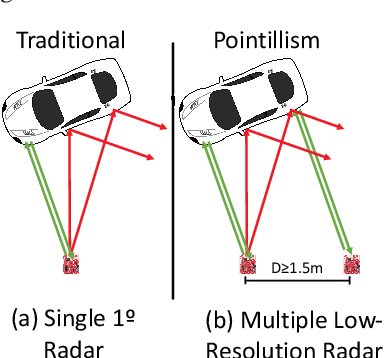
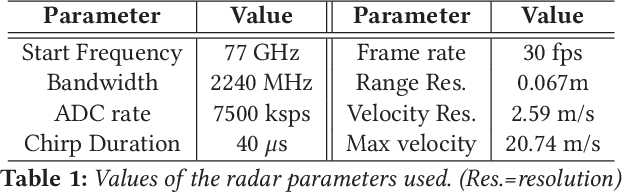
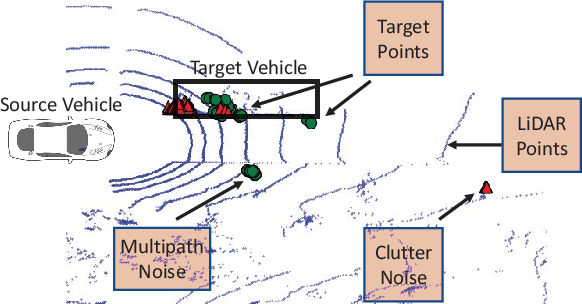
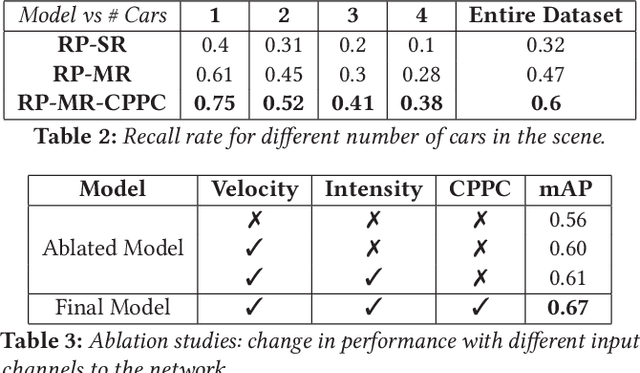
Autonomous perception requires high-quality environment sensing in the form of 3D bounding boxes of dynamic objects. The primary sensors used in automotive systems are light-based cameras and LiDARs. However, they are known to fail in adverse weather conditions. Radars can potentially solve this problem as they are barely affected by adverse weather conditions. However, specular reflections of wireless signals cause poor performance of radar point clouds. We introduce Pointillism, a system that combines data from multiple spatially separated radars with an optimal separation to mitigate these problems. We introduce a novel concept of Cross Potential Point Clouds, which uses the spatial diversity induced by multiple radars and solves the problem of noise and sparsity in radar point clouds. Furthermore, we present the design of RP-net, a novel deep learning architecture, designed explicitly for radar's sparse data distribution, to enable accurate 3D bounding box estimation. The spatial techniques designed and proposed in this paper are fundamental to radars point cloud distribution and would benefit other radar sensing applications.
* Accepted in SenSys '20. Dataset has been made publicly available
Joint Distribution across Representation Space for Out-of-Distribution Detection
Mar 30, 2021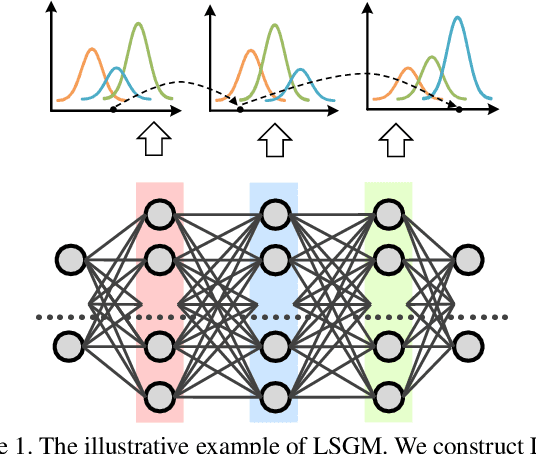
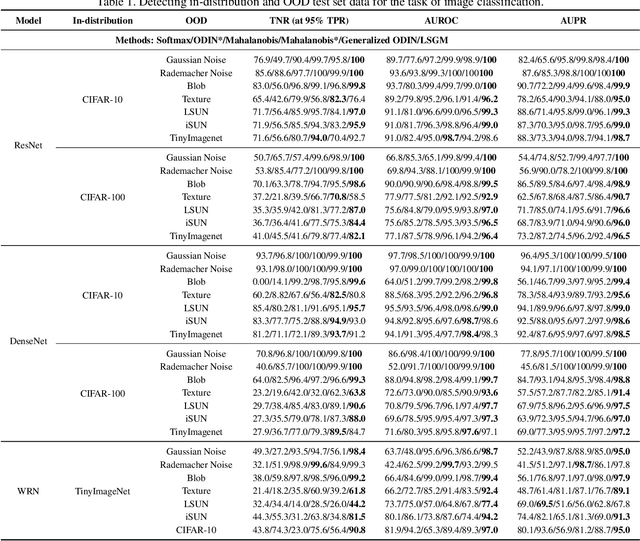
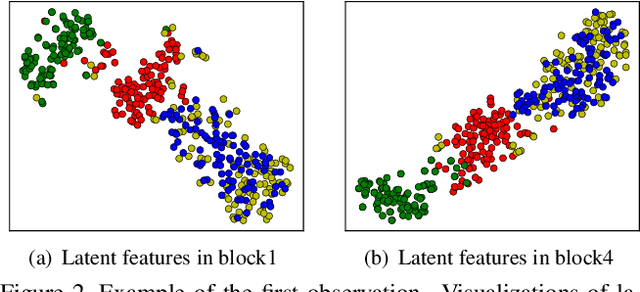
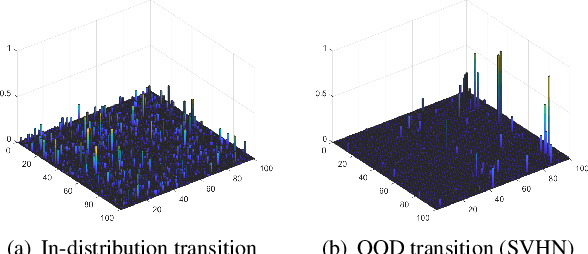
Deep neural networks (DNNs) have become a key part of many modern software applications. After training and validating, the DNN is deployed as an irrevocable component and applied in real-world scenarios. Although most DNNs are built meticulously with huge volumes of training data, data in the real world still remain unknown to the DNN model, which leads to the crucial requirement of runtime out-of-distribution (OOD) detection. However, many existing approaches 1) need OOD data for classifier training or parameter tuning, or 2) simply combine the scores of each hidden layer as an ensemble of features for OOD detection. In this paper, we present a novel outlook on in-distribution data in a generative manner, which takes their latent features generated from each hidden layer as a joint distribution across representation spaces. Since only the in-distribution latent features are comprehensively understood in representation space, the internal difference between in-distribution and OOD data can be naturally revealed without the intervention of any OOD data. Specifically, We construct a generative model, called Latent Sequential Gaussian Mixture (LSGM), to depict how the in-distribution latent features are generated in terms of the trace of DNN inference across representation spaces. We first construct the Gaussian Mixture Model (GMM) based on in-distribution latent features for each hidden layer, and then connect GMMs via the transition probabilities of the inference traces. Experimental evaluations on popular benchmark OOD datasets and models validate the superiority of the proposed method over the state-of-the-art methods in OOD detection.