 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Learning of Experiential Rules and Policies for Large Language Model Agents
Jun 25, 2026For LLM agents in multi-step interactive environments, a key challenge is to make effective use of accumulated interaction experience. Existing work has typically separated two uses of such experience: keeping it outside the model as natural-language rules for later prompting, or using trajectories and feedback to update the model parameters. The former is easy to interpret but can fall out of sync with the evolving policy; the latter improves the policy more broadly but provides only limited correction for local mistakes in sparse-reward settings. We present Joint Learning of Experiential Rules and Policies for LLM Agents (JERP), which updates a long-term experiential-rule pool and the policy from the same interaction trajectories. At decision time, JERP retrieves task-relevant rules and conditions the agent on them together with the interaction history. After each episode, it uses the collected trajectories both to optimize the policy and to revise the rule pool by comparing current rollouts with reference successful trajectories. This coupling keeps the rule pool aligned with the evolving policy while allowing stable and effective behaviors to be gradually absorbed into the model itself. Experiments on AlfWorld and WebShop show that JERP yields consistent gains in decision performance for complex interactive tasks.
H$^2$R: Hierarchical Hindsight Reflection for Multi-Task LLM Agents
Sep 16, 2025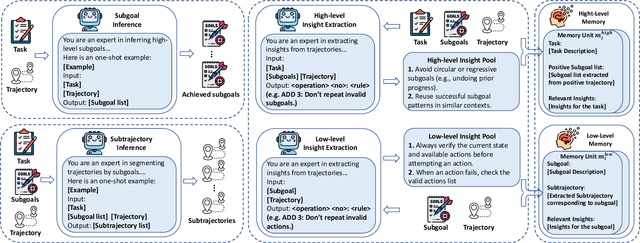
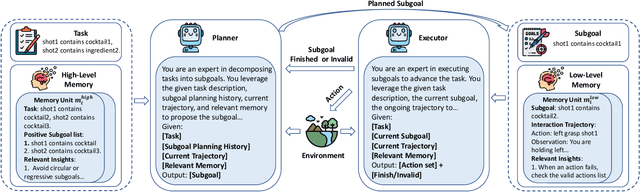
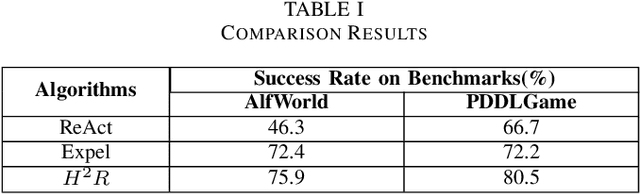

Large language model (LLM)-based agents have shown strong potential in multi-task scenarios, owing to their ability to transfer knowledge across diverse tasks. However, existing approaches often treat prior experiences and knowledge as monolithic units, leading to inefficient and coarse-grained knowledge transfer. In this work, we propose a novel hierarchical memory architecture that enables fine-grained knowledge transfer by decoupling high-level planning memory from low-level execution memory. To construct and refine these hierarchical memories, we introduce Hierarchical Hindsight Reflection (H$^2$R), a mechanism that distills reusable and hierarchical knowledge from past agent-environment interactions. At test time, H$^2$R performs retrievals of high-level and low-level memories separately, allowing LLM-based agents to efficiently access and utilize task-relevant knowledge for new tasks.Experimental results across two benchmarks demonstrate that H$^2$R can improve generalization and decision-making performance, outperforming prior baselines such as Expel.