 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Unlearnable: Adversarial Augmentations Suppress Unlearnable Example Attacks
Mar 27, 2023



Unlearnable example attacks are data poisoning techniques that can be used to safeguard public data against unauthorized use for training deep learning models. These methods add stealthy perturbations to the original image, thereby making it difficult for deep learning models to learn from these training data effectively. Current research suggests that adversarial training can, to a certain degree, mitigate the impact of unlearnable example attacks, while common data augmentation methods are not effective against such poisons. Adversarial training, however, demands considerable computational resources and can result in non-trivial accuracy loss. In this paper, we introduce the UEraser method, which outperforms current defenses against different types of state-of-the-art unlearnable example attacks through a combination of effective data augmentation policies and loss-maximizing adversarial augmentations. In stark contrast to the current SOTA adversarial training methods, UEraser uses adversarial augmentations, which extends beyond the confines of $ \ell_p $ perturbation budget assumed by current unlearning attacks and defenses. It also helps to improve the model's generalization ability, thus protecting against accuracy loss. UEraser wipes out the unlearning effect with error-maximizing data augmentations, thus restoring trained model accuracies. Interestingly, UEraser-Lite, a fast variant without adversarial augmentations, is also highly effective in preserving clean accuracies. On challenging unlearnable CIFAR-10, CIFAR-100, SVHN, and ImageNet-subset datasets produced with various attacks, it achieves results that are comparable to those obtained during clean training. We also demonstrate its efficacy against possible adaptive attacks. Our code is open source and available to the deep learning community: https://github.com/lafeat/ueraser.
LiDAR-CS Dataset: LiDAR Point Cloud Dataset with Cross-Sensors for 3D Object Detection
Jan 29, 2023LiDAR devices are widely used in autonomous driving scenarios and researches on 3D point cloud achieve remarkable progress over the past years. However, deep learning-based methods heavily rely on the annotation data and often face the domain generalization problem. Unlike 2D images whose domains are usually related to the texture information, the feature extracted from the 3D point cloud is affected by the distribution of the points. Due to the lack of a 3D domain adaptation benchmark, the common practice is to train the model on one benchmark (e.g, Waymo) and evaluate it on another dataset (e.g. KITTI). However, in this setting, there are two types of domain gaps, the scenarios domain, and sensors domain, making the evaluation and analysis complicated and difficult. To handle this situation, we propose LiDAR Dataset with Cross-Sensors (LiDAR-CS Dataset), which contains large-scale annotated LiDAR point cloud under 6 groups of different sensors but with same corresponding scenarios, captured from hybrid realistic LiDAR simulator. As far as we know, LiDAR-CS Dataset is the first dataset focused on the sensor (e.g., the points distribution) domain gaps for 3D object detection in real traffic. Furthermore, we evaluate and analyze the performance with several baseline detectors on the LiDAR-CS benchmark and show its applications.
Flareon: Stealthy any2any Backdoor Injection via Poisoned Augmentation
Dec 20, 2022Open software supply chain attacks, once successful, can exact heavy costs in mission-critical applications. As open-source ecosystems for deep learning flourish and become increasingly universal, they present attackers previously unexplored avenues to code-inject malicious backdoors in deep neural network models. This paper proposes Flareon, a small, stealthy, seemingly harmless code modification that specifically targets the data augmentation pipeline with motion-based triggers. Flareon neither alters ground-truth labels, nor modifies the training loss objective, nor does it assume prior knowledge of the victim model architecture, training data, and training hyperparameters. Yet, it has a surprisingly large ramification on training -- models trained under Flareon learn powerful target-conditional (or "any2any") backdoors. The resulting models can exhibit high attack success rates for any target choices and better clean accuracies than backdoor attacks that not only seize greater control, but also assume more restrictive attack capabilities. We also demonstrate the effectiveness of Flareon against recent defenses. Flareon is fully open-source and available online to the deep learning community: https://github.com/lafeat/flareon.
MORA: Improving Ensemble Robustness Evaluation with Model-Reweighing Attack
Nov 15, 2022Adversarial attacks can deceive neural networks by adding tiny perturbations to their input data. Ensemble defenses, which are trained to minimize attack transferability among sub-models, offer a promising research direction to improve robustness against such attacks while maintaining a high accuracy on natural inputs. We discover, however, that recent state-of-the-art (SOTA) adversarial attack strategies cannot reliably evaluate ensemble defenses, sizeably overestimating their robustness. This paper identifies the two factors that contribute to this behavior. First, these defenses form ensembles that are notably difficult for existing gradient-based method to attack, due to gradient obfuscation. Second, ensemble defenses diversify sub-model gradients, presenting a challenge to defeat all sub-models simultaneously, simply summing their contributions may counteract the overall attack objective; yet, we observe that ensemble may still be fooled despite most sub-models being correct. We therefore introduce MORA, a model-reweighing attack to steer adversarial example synthesis by reweighing the importance of sub-model gradients. MORA finds that recent ensemble defenses all exhibit varying degrees of overestimated robustness. Comparing it against recent SOTA white-box attacks, it can converge orders of magnitude faster while achieving higher attack success rates across all ensemble models examined with three different ensemble modes (i.e., ensembling by either softmax, voting or logits). In particular, most ensemble defenses exhibit near or exactly 0% robustness against MORA with $\ell^\infty$ perturbation within 0.02 on CIFAR-10, and 0.01 on CIFAR-100. We make MORA open source with reproducible results and pre-trained models; and provide a leaderboard of ensemble defenses under various attack strategies.
Semi-supervised 3D Object Detection with Proficient Teachers
Jul 26, 2022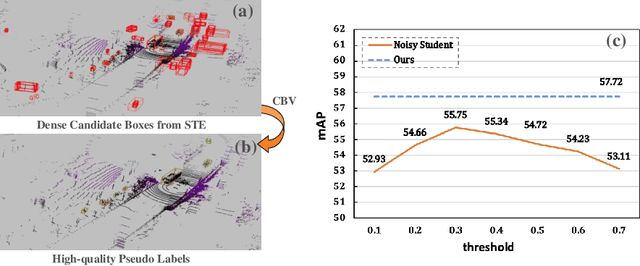

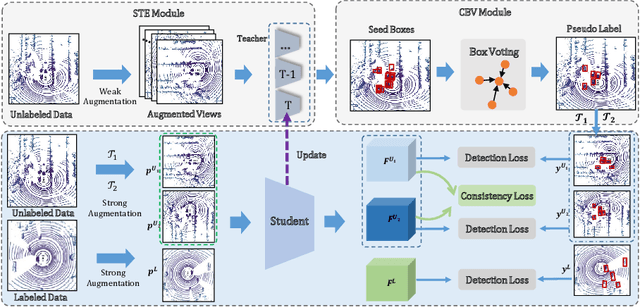

Dominated point cloud-based 3D object detectors in autonomous driving scenarios rely heavily on the huge amount of accurately labeled samples, however, 3D annotation in the point cloud is extremely tedious, expensive and time-consuming. To reduce the dependence on large supervision, semi-supervised learning (SSL) based approaches have been proposed. The Pseudo-Labeling methodology is commonly used for SSL frameworks, however, the low-quality predictions from the teacher model have seriously limited its performance. In this work, we propose a new Pseudo-Labeling framework for semi-supervised 3D object detection, by enhancing the teacher model to a proficient one with several necessary designs. First, to improve the recall of pseudo labels, a Spatialtemporal Ensemble (STE) module is proposed to generate sufficient seed boxes. Second, to improve the precision of recalled boxes, a Clusteringbased Box Voting (CBV) module is designed to get aggregated votes from the clustered seed boxes. This also eliminates the necessity of sophisticated thresholds to select pseudo labels. Furthermore, to reduce the negative influence of wrongly pseudo-labeled samples during the training, a soft supervision signal is proposed by considering Box-wise Contrastive Learning (BCL). The effectiveness of our model is verified on both ONCE and Waymo datasets. For example, on ONCE, our approach significantly improves the baseline by 9.51 mAP. Moreover, with half annotations, our model outperforms the oracle model with full annotations on Waymo.
ProposalContrast: Unsupervised Pre-training for LiDAR-based 3D Object Detection
Jul 26, 2022
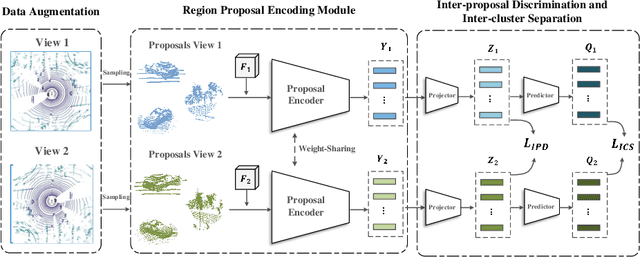
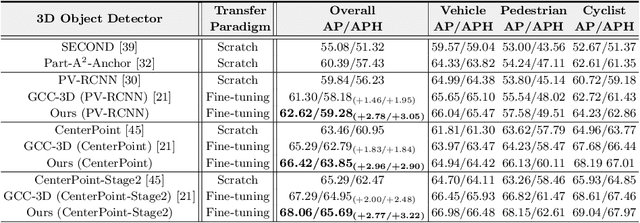
Existing approaches for unsupervised point cloud pre-training are constrained to either scene-level or point/voxel-level instance discrimination. Scene-level methods tend to lose local details that are crucial for recognizing the road objects, while point/voxel-level methods inherently suffer from limited receptive field that is incapable of perceiving large objects or context environments. Considering region-level representations are more suitable for 3D object detection, we devise a new unsupervised point cloud pre-training framework, called ProposalContrast, that learns robust 3D representations by contrasting region proposals. Specifically, with an exhaustive set of region proposals sampled from each point cloud, geometric point relations within each proposal are modeled for creating expressive proposal representations. To better accommodate 3D detection properties, ProposalContrast optimizes with both inter-cluster and inter-proposal separation, i.e., sharpening the discriminativeness of proposal representations across semantic classes and object instances. The generalizability and transferability of ProposalContrast are verified on various 3D detectors (i.e., PV-RCNN, CenterPoint, PointPillars and PointRCNN) and datasets (i.e., KITTI, Waymo and ONCE).
Fine-tuning Pre-trained Language Models with Noise Stability Regularization
Jun 12, 2022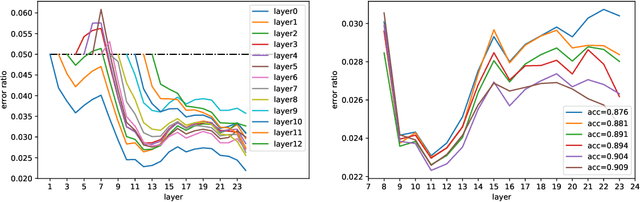
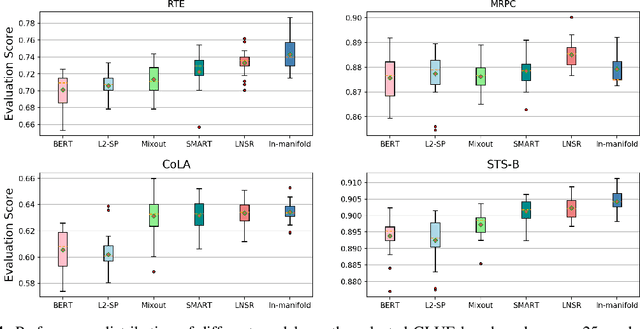
The advent of large-scale pre-trained language models has contributed greatly to the recent progress in natural language processing. Many state-of-the-art language models are first trained on a large text corpus and then fine-tuned on downstream tasks. Despite its recent success and wide adoption, fine-tuning a pre-trained language model often suffers from overfitting, which leads to poor generalizability due to the extremely high complexity of the model and the limited training samples from downstream tasks. To address this problem, we propose a novel and effective fine-tuning framework, named Layerwise Noise Stability Regularization (LNSR). Specifically, we propose to inject the standard Gaussian noise or In-manifold noise and regularize hidden representations of the fine-tuned model. We first provide theoretical analyses to support the efficacy of our method. We then demonstrate the advantages of the proposed method over other state-of-the-art algorithms including L2-SP, Mixout and SMART. While these previous works only verify the effectiveness of their methods on relatively simple text classification tasks, we also verify the effectiveness of our method on question answering tasks, where the target problem is much more difficult and more training examples are available. Furthermore, extensive experimental results indicate that the proposed algorithm can not only enhance the in-domain performance of the language models but also improve the domain generalization performance on out-of-domain data.
Unsupervised Visible-light Images Guided Cross-Spectrum Depth Estimation from Dual-Modality Cameras
Apr 30, 2022
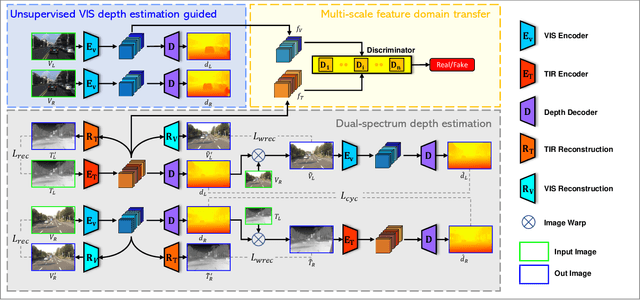


Cross-spectrum depth estimation aims to provide a depth map in all illumination conditions with a pair of dual-spectrum images. It is valuable for autonomous vehicle applications when the vehicle is equipped with two cameras of different modalities. However, images captured by different-modality cameras can be photometrically quite different. Therefore, cross-spectrum depth estimation is a very challenging problem. Moreover, the shortage of large-scale open-source datasets also retards further research in this field. In this paper, we propose an unsupervised visible-light image guided cross-spectrum (i.e., thermal and visible-light, TIR-VIS in short) depth estimation framework given a pair of RGB and thermal images captured from a visible-light camera and a thermal one. We first adopt a base depth estimation network using RGB-image pairs. Then we propose a multi-scale feature transfer network to transfer features from the TIR-VIS domain to the VIS domain at the feature level to fit the trained depth estimation network. At last, we propose a cross-spectrum depth cycle consistency to improve the depth result of dual-spectrum image pairs. Meanwhile, we release a large dual-spectrum depth estimation dataset with visible-light and far-infrared stereo images captured in different scenes to the society. The experiment result shows that our method achieves better performance than the compared existing methods. Our datasets is available at https://github.com/whitecrow1027/VIS-TIR-Datasets.
FedDC: Federated Learning with Non-IID Data via Local Drift Decoupling and Correction
Mar 22, 2022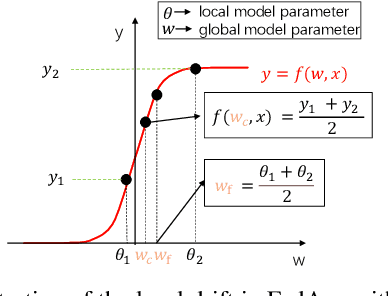
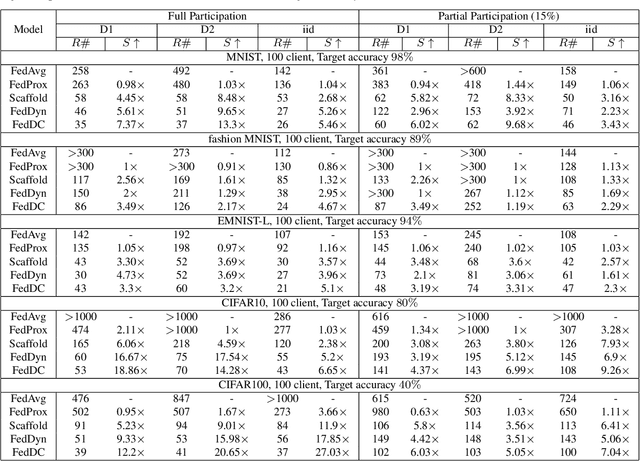
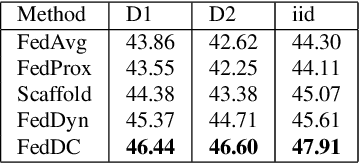
Federated learning (FL) allows multiple clients to collectively train a high-performance global model without sharing their private data. However, the key challenge in federated learning is that the clients have significant statistical heterogeneity among their local data distributions, which would cause inconsistent optimized local models on the client-side. To address this fundamental dilemma, we propose a novel federated learning algorithm with local drift decoupling and correction (FedDC). Our FedDC only introduces lightweight modifications in the local training phase, in which each client utilizes an auxiliary local drift variable to track the gap between the local model parameter and the global model parameters. The key idea of FedDC is to utilize this learned local drift variable to bridge the gap, i.e., conducting consistency in parameter-level. The experiment results and analysis demonstrate that FedDC yields expediting convergence and better performance on various image classification tasks, robust in partial participation settings, non-iid data, and heterogeneous clients.
Grounding Commands for Autonomous Vehicles via Layer Fusion with Region-specific Dynamic Layer Attention
Mar 14, 2022
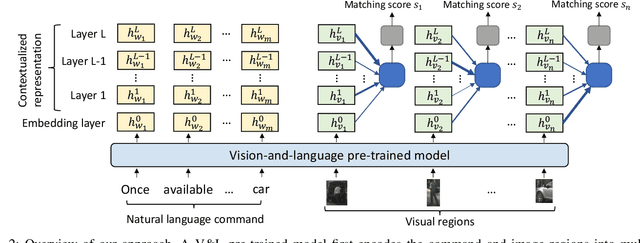
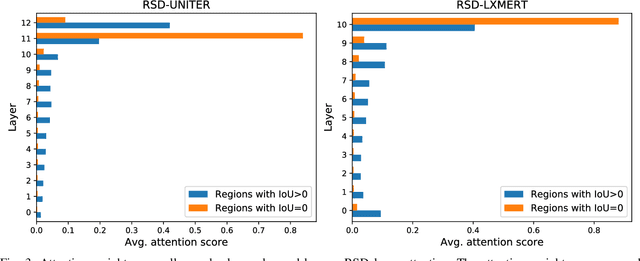
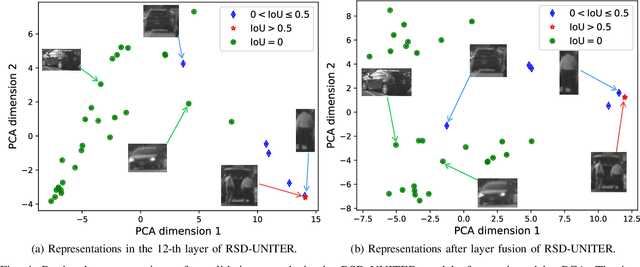
Grounding a command to the visual environment is an essential ingredient for interactions between autonomous vehicles and humans. In this work, we study the problem of language grounding for autonomous vehicles, which aims to localize a region in a visual scene according to a natural language command from a passenger. Prior work only employs the top layer representations of a vision-and-language pre-trained model to predict the region referred to by the command. However, such a method omits the useful features encoded in other layers, and thus results in inadequate understanding of the input scene and command. To tackle this limitation, we present the first layer fusion approach for this task. Since different visual regions may require distinct types of features to disambiguate them from each other, we further propose the region-specific dynamic (RSD) layer attention to adaptively fuse the multimodal information across layers for each region. Extensive experiments on the Talk2Car benchmark demonstrate that our approach helps predict more accurate regions and outperforms state-of-the-art methods.