 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sparse and Monotonic Attention for Transformer-based Automatic Speech Recognition
Sep 30, 2022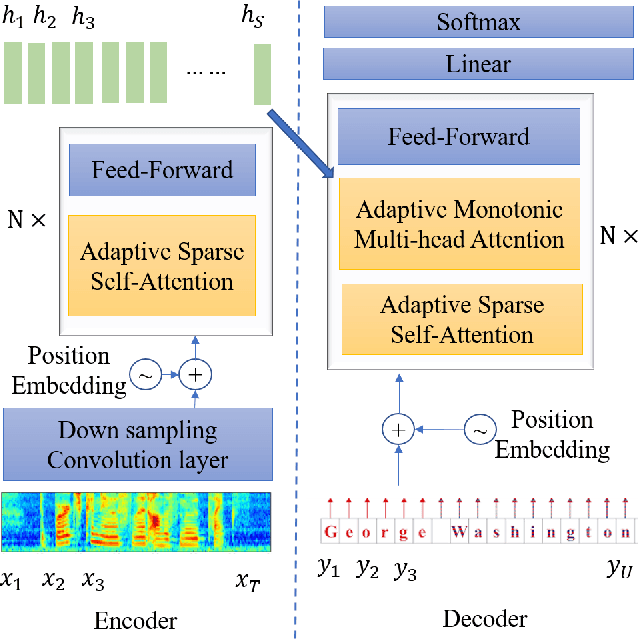
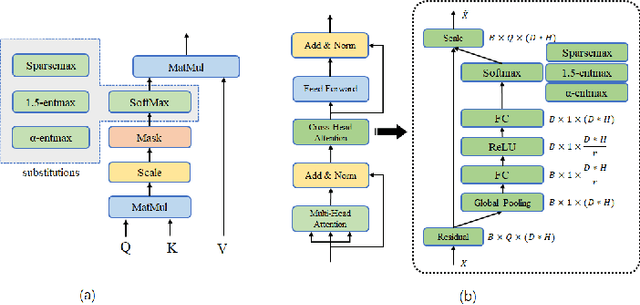
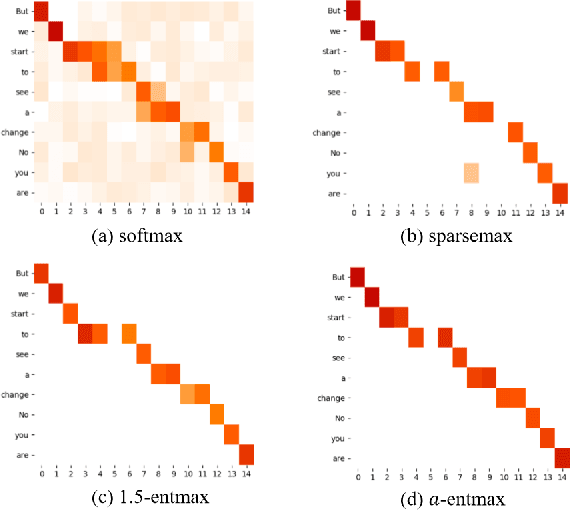
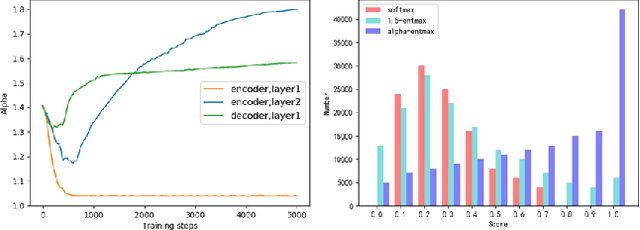
The Transformer architecture model, based on self-attention and multi-head attention, has achieved remarkable success in offline end-to-end Automatic Speech Recognition (ASR). However, self-attention and multi-head attention cannot be easily applied for streaming or online ASR. For self-attention in Transformer ASR, the softmax normalization function-based attention mechanism makes it impossible to highlight important speech information. For multi-head attention in Transformer ASR, it is not easy to model monotonic alignments in different heads. To overcome these two limits, we integrate sparse attention and monotonic attention into Transformer-based ASR. The sparse mechanism introduces a learned sparsity scheme to enable each self-attention structure to fit the corresponding head better. The monotonic attention deploys regularization to prune redundant heads for the multi-head attention structure. The experiments show that our method can effectively improve the attention mechanism on widely used benchmarks of speech recognition.