 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrimming and Improving Skip-thought Vectors
Jun 09, 2017

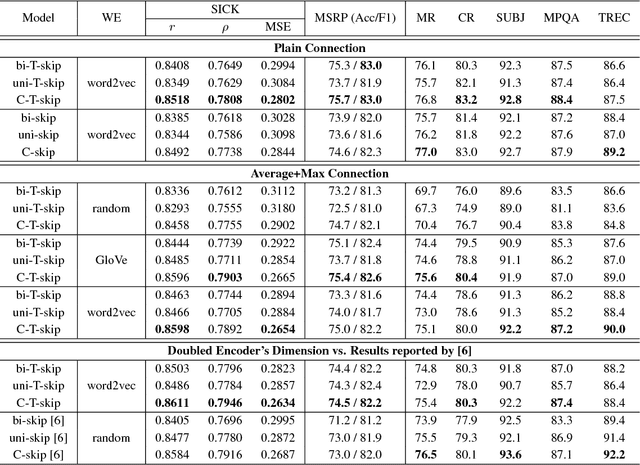
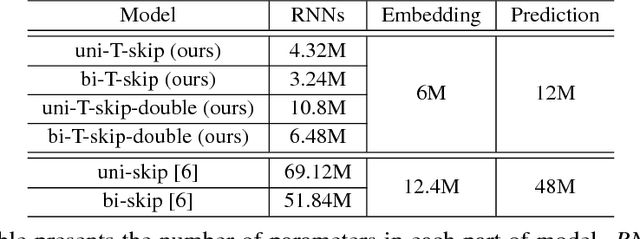
The skip-thought model has been proven to be effective at learning sentence representations and capturing sentence semantics. In this paper, we propose a suite of techniques to trim and improve it. First, we validate a hypothesis that, given a current sentence, inferring the previous and inferring the next sentence provide similar supervision power, therefore only one decoder for predicting the next sentence is preserved in our trimmed skip-thought model. Second, we present a connection layer between encoder and decoder to help the model to generalize better on semantic relatedness tasks. Third, we found that a good word embedding initialization is also essential for learning better sentence representations. We train our model unsupervised on a large corpus with contiguous sentences, and then evaluate the trained model on 7 supervised tasks, which includes semantic relatedness, paraphrase detection, and text classification benchmarks. We empirically show that, our proposed model is a faster, lighter-weight and equally powerful alternative to the original skip-thought model.
Rethinking Skip-thought: A Neighborhood based Approach
Jun 09, 2017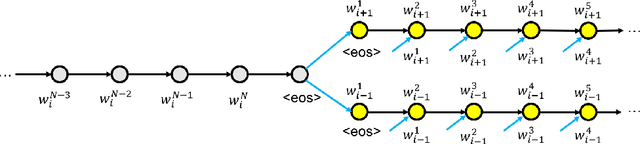
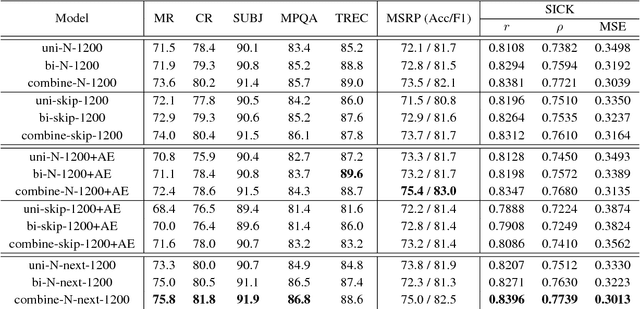
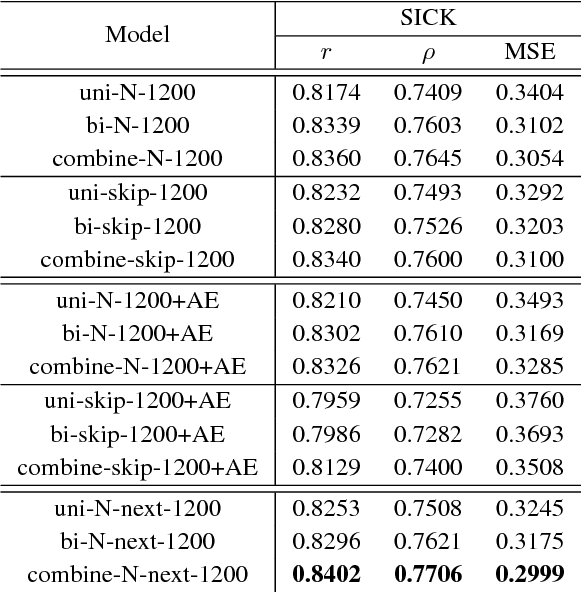

We study the skip-thought model with neighborhood information as weak supervision. More specifically, we propose a skip-thought neighbor model to consider the adjacent sentences as a neighborhood. We train our skip-thought neighbor model on a large corpus with continuous sentences, and then evaluate the trained model on 7 tasks, which include semantic relatedness, paraphrase detection, and classification benchmarks. Both quantitative comparison and qualitative investigation are conducted. We empirically show that, our skip-thought neighbor model performs as well as the skip-thought model on evaluation tasks. In addition, we found that, incorporating an autoencoder path in our model didn't aid our model to perform better, while it hurts the performance of the skip-thought model.
Diversified Texture Synthesis with Feed-forward Networks
Mar 05, 2017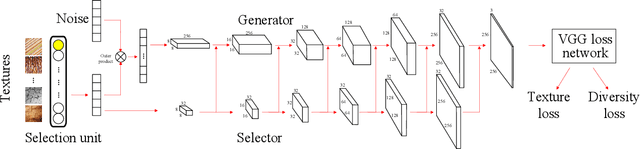


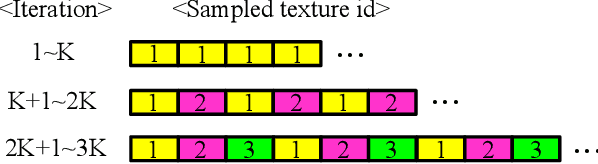
Recent progresses on deep discriminative and generative modeling have shown promising results on texture synthesis. However, existing feed-forward based methods trade off generality for efficiency, which suffer from many issues, such as shortage of generality (i.e., build one network per texture), lack of diversity (i.e., always produce visually identical output) and suboptimality (i.e., generate less satisfying visual effects). In this work, we focus on solving these issues for improved texture synthesis. We propose a deep generative feed-forward network which enables efficient synthesis of multiple textures within one single network and meaningful interpolation between them. Meanwhile, a suite of important techniques are introduced to achieve better convergence and diversity. With extensive experiments, we demonstrate the effectiveness of the proposed model and techniques for synthesizing a large number of textures and show its applications with the stylization.
Scribbler: Controlling Deep Image Synthesis with Sketch and Color
Dec 05, 2016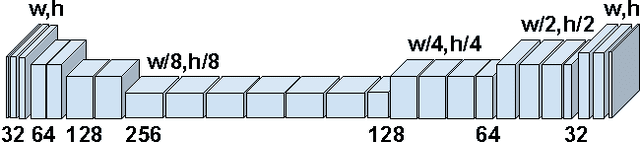



Recently, there have been several promising methods to generate realistic imagery from deep convolutional networks. These methods sidestep the traditional computer graphics rendering pipeline and instead generate imagery at the pixel level by learning from large collections of photos (e.g. faces or bedrooms). However, these methods are of limited utility because it is difficult for a user to control what the network produces. In this paper, we propose a deep adversarial image synthesis architecture that is conditioned on sketched boundaries and sparse color strokes to generate realistic cars, bedrooms, or faces. We demonstrate a sketch based image synthesis system which allows users to 'scribble' over the sketch to indicate preferred color for objects. Our network can then generate convincing images that satisfy both the color and the sketch constraints of user. The network is feed-forward which allows users to see the effect of their edits in real time. We compare to recent work on sketch to image synthesis and show that our approach can generate more realistic, more diverse, and more controllable outputs. The architecture is also effective at user-guided colorization of grayscale images.
Vista: A Visually, Socially, and Temporally-aware Model for Artistic Recommendation
Jul 15, 2016
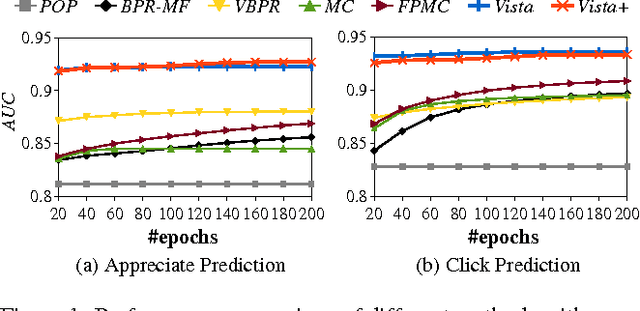


Understanding users' interactions with highly subjective content---like artistic images---is challenging due to the complex semantics that guide our preferences. On the one hand one has to overcome `standard' recommender systems challenges, such as dealing with large, sparse, and long-tailed datasets. On the other, several new challenges present themselves, such as the need to model content in terms of its visual appearance, or even social dynamics, such as a preference toward a particular artist that is independent of the art they create. In this paper we build large-scale recommender systems to model the dynamics of a vibrant digital art community, Behance, consisting of tens of millions of interactions (clicks and `appreciates') of users toward digital art. Methodologically, our main contributions are to model (a) rich content, especially in terms of its visual appearance; (b) temporal dynamics, in terms of how users prefer `visually consistent' content within and across sessions; and (c) social dynamics, in terms of how users exhibit preferences both towards certain art styles, as well as the artists themselves.
Image Captioning with Semantic Attention
Mar 12, 2016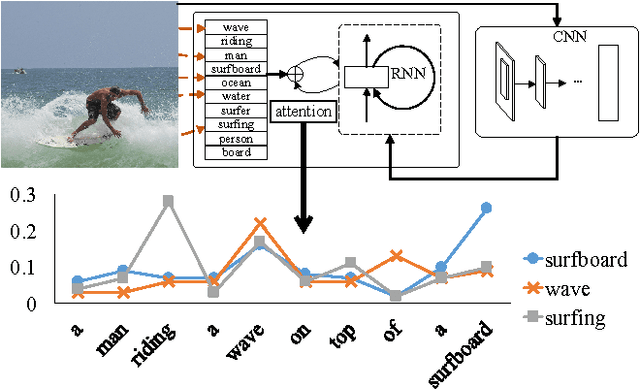
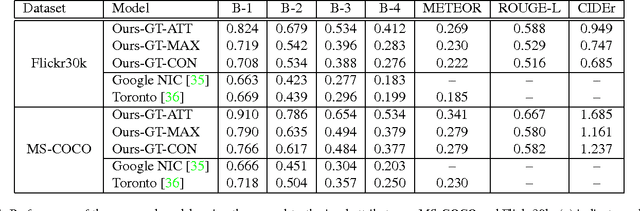
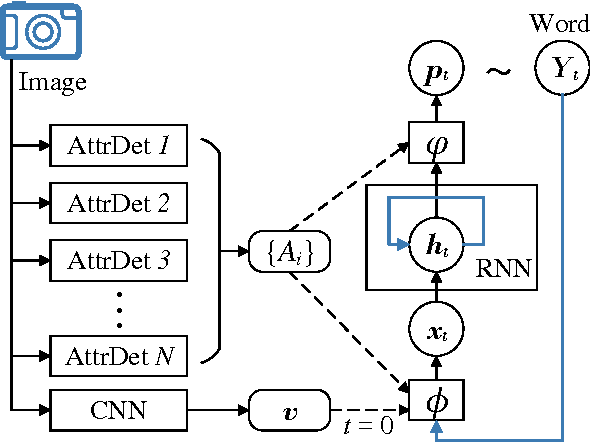
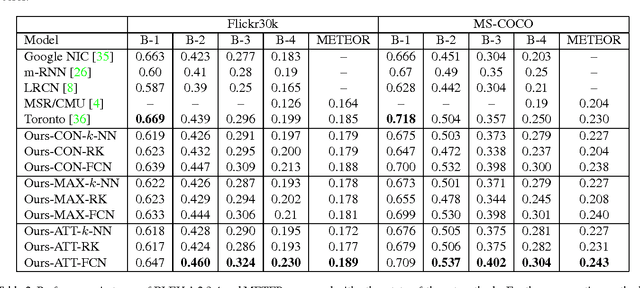
Automatically generating a natural language description of an image has attracted interests recently both because of its importance in practical applications and because it connects two major artificial intelligence fields: computer vision and natural language processing. Existing approaches are either top-down, which start from a gist of an image and convert it into words, or bottom-up, which come up with words describing various aspects of an image and then combine them. In this paper, we propose a new algorithm that combines both approaches through a model of semantic attention. Our algorithm learns to selectively attend to semantic concept proposals and fuse them into hidden states and outputs of recurrent neural networks. The selection and fusion form a feedback connecting the top-down and bottom-up computation. We evaluate our algorithm on two public benchmarks: Microsoft COCO and Flickr30K. Experimental results show that our algorithm significantly outperforms the state-of-the-art approaches consistently across different evaluation metrics.
Multi-Instance Visual-Semantic Embedding
Dec 22, 2015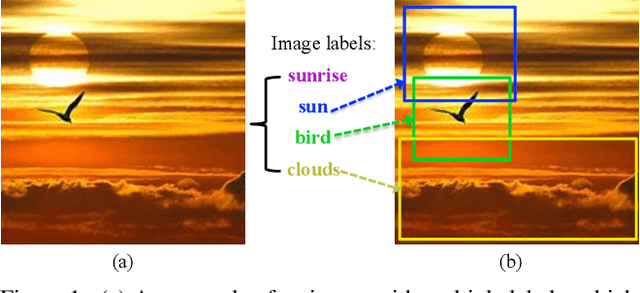
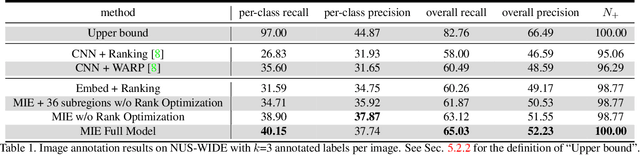
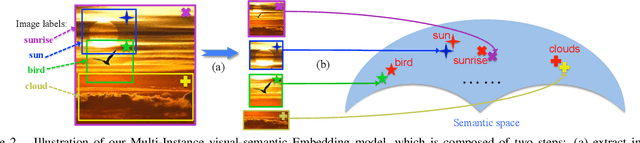
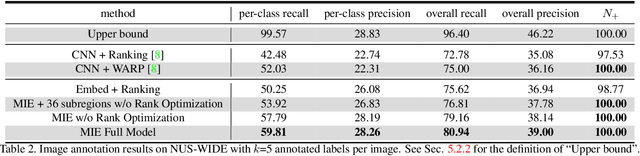
Visual-semantic embedding models have been recently proposed and shown to be effective for image classification and zero-shot learning, by mapping images into a continuous semantic label space. Although several approaches have been proposed for single-label embedding tasks, handling images with multiple labels (which is a more general setting) still remains an open problem, mainly due to the complex underlying corresponding relationship between image and its labels. In this work, we present Multi-Instance visual-semantic Embedding model (MIE) for embedding images associated with either single or multiple labels. Our model discovers and maps semantically-meaningful image subregions to their corresponding labels. And we demonstrate the superiority of our method over the state-of-the-art on two tasks, including multi-label image annotation and zero-shot learning.
Collaborative Feature Learning from Social Media
Apr 09, 2015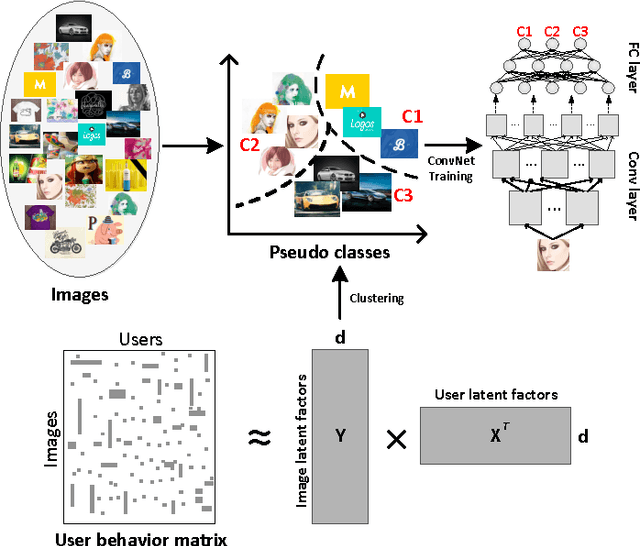
Image feature representation plays an essential role in image recognition and related tasks. The current state-of-the-art feature learning paradigm is supervised learning from labeled data. However, this paradigm requires large-scale category labels, which limits its applicability to domains where labels are hard to obtain. In this paper, we propose a new data-driven feature learning paradigm which does not rely on category labels. Instead, we learn from user behavior data collected on social media. Concretely, we use the image relationship discovered in the latent space from the user behavior data to guide the image feature learning. We collect a large-scale image and user behavior dataset from Behance.net. The dataset consists of 1.9 million images and over 300 million view records from 1.9 million users. We validate our feature learning paradigm on this dataset and find that the learned feature significantly outperforms the state-of-the-art image features in learning better image similarities. We also show that the learned feature performs competitively on various recognition benchmarks.
Multi-Task Metric Learning on Network Data
Nov 10, 2014
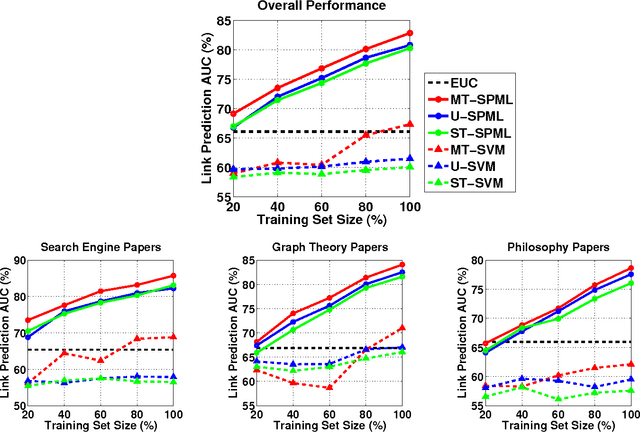
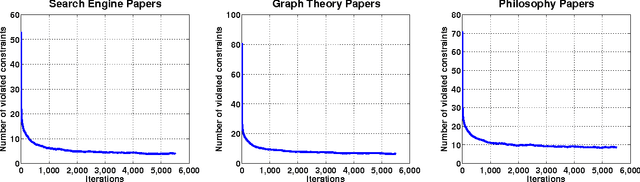
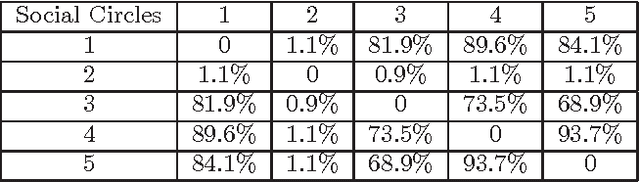
Multi-task learning (MTL) improves prediction performance in different contexts by learning models jointly on multiple different, but related tasks. Network data, which are a priori data with a rich relational structure, provide an important context for applying MTL. In particular, the explicit relational structure implies that network data is not i.i.d. data. Network data also often comes with significant metadata (i.e., attributes) associated with each entity (node). Moreover, due to the diversity and variation in network data (e.g., multi-relational links or multi-category entities), various tasks can be performed and often a rich correlation exists between them. Learning algorithms should exploit all of these additional sources of information for better performance. In this work we take a metric-learning point of view for the MTL problem in the network context. Our approach builds on structure preserving metric learning (SPML). In particular SPML learns a Mahalanobis distance metric for node attributes using network structure as supervision, so that the learned distance function encodes the structure and can be used to predict link patterns from attributes. SPML is described for single-task learning on single network. Herein, we propose a multi-task version of SPML, abbreviated as MT-SPML, which is able to learn across multiple related tasks on multiple networks via shared intermediate parametrization. MT-SPML learns a specific metric for each task and a common metric for all tasks. The task correlation is carried through the common metric and the individual metrics encode task specific information. When combined together, they are structure-preserving with respect to individual tasks. MT-SPML works on general networks, thus is suitable for a wide variety of problems. In experiments, we challenge MT-SPML on two real-word problems, where MT-SPML achieves significant improvement.