 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPR-NeRF: Ownership Verification meets Neural Radiance Field
Jan 23, 2024Neural Radiance Field (NeRF) models have gained significant attention in the computer vision community in the recent past with state-of-the-art visual quality and produced impressive demonstrations. Since then, technopreneurs have sought to leverage NeRF models into a profitable business. Therefore, NeRF models make it worth the risk of plagiarizers illegally copying, re-distributing, or misusing those models. This paper proposes a comprehensive intellectual property (IP) protection framework for the NeRF model in both black-box and white-box settings, namely IPR-NeRF. In the black-box setting, a diffusion-based solution is introduced to embed and extract the watermark via a two-stage optimization process. In the white-box setting, a designated digital signature is embedded into the weights of the NeRF model by adopting the sign loss objective. Our extensive experiments demonstrate that not only does our approach maintain the fidelity (\ie, the rendering quality) of IPR-NeRF models, but it is also robust against both ambiguity and removal attacks compared to prior arts.
InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models
Dec 10, 2023



Large-scale text-to-image (T2I) diffusion models have showcased incredible capabilities in generating coherent images based on textual descriptions, enabling vast applications in content generation. While recent advancements have introduced control over factors such as object localization, posture, and image contours, a crucial gap remains in our ability to control the interactions between objects in the generated content. Well-controlling interactions in generated images could yield meaningful applications, such as creating realistic scenes with interacting characters. In this work, we study the problems of conditioning T2I diffusion models with Human-Object Interaction (HOI) information, consisting of a triplet label (person, action, object) and corresponding bounding boxes. We propose a pluggable interaction control model, called InteractDiffusion that extends existing pre-trained T2I diffusion models to enable them being better conditioned on interactions. Specifically, we tokenize the HOI information and learn their relationships via interaction embeddings. A conditioning self-attention layer is trained to map HOI tokens to visual tokens, thereby conditioning the visual tokens better in existing T2I diffusion models. Our model attains the ability to control the interaction and location on existing T2I diffusion models, which outperforms existing baselines by a large margin in HOI detection score, as well as fidelity in FID and KID. Project page: https://jiuntian.github.io/interactdiffusion.
Everyone Can Attack: Repurpose Lossy Compression as a Natural Backdoor Attack
Sep 03, 2023



The vulnerabilities to backdoor attacks have recently threatened the trustworthiness of machine learning models in practical applications. Conventional wisdom suggests that not everyone can be an attacker since the process of designing the trigger generation algorithm often involves significant effort and extensive experimentation to ensure the attack's stealthiness and effectiveness. Alternatively, this paper shows that there exists a more severe backdoor threat: anyone can exploit an easily-accessible algorithm for silent backdoor attacks. Specifically, this attacker can employ the widely-used lossy image compression from a plethora of compression tools to effortlessly inject a trigger pattern into an image without leaving any noticeable trace; i.e., the generated triggers are natural artifacts. One does not require extensive knowledge to click on the "convert" or "save as" button while using tools for lossy image compression. Via this attack, the adversary does not need to design a trigger generator as seen in prior works and only requires poisoning the data. Empirically, the proposed attack consistently achieves 100% attack success rate in several benchmark datasets such as MNIST, CIFAR-10, GTSRB and CelebA. More significantly, the proposed attack can still achieve almost 100% attack success rate with very small (approximately 10%) poisoning rates in the clean label setting. The generated trigger of the proposed attack using one lossy compression algorithm is also transferable across other related compression algorithms, exacerbating the severity of this backdoor threat. This work takes another crucial step toward understanding the extensive risks of backdoor attacks in practice, urging practitioners to investigate similar attacks and relevant backdoor mitigation methods.
Unsupervised Hashing via Similarity Distribution Calibration
Feb 15, 2023Existing unsupervised hashing methods typically adopt a feature similarity preservation paradigm. As a result, they overlook the intrinsic similarity capacity discrepancy between the continuous feature and discrete hash code spaces. Specifically, since the feature similarity distribution is intrinsically biased (e.g., moderately positive similarity scores on negative pairs), the hash code similarities of positive and negative pairs often become inseparable (i.e., the similarity collapse problem). To solve this problem, in this paper a novel Similarity Distribution Calibration (SDC) method is introduced. Instead of matching individual pairwise similarity scores, SDC aligns the hash code similarity distribution towards a calibration distribution (e.g., beta distribution) with sufficient spread across the entire similarity capacity/range, to alleviate the similarity collapse problem. Extensive experiments show that our SDC outperforms the state-of-the-art alternatives on both coarse category-level and instance-level image retrieval tasks, often by a large margin. Code is available at https://github.com/kamwoh/sdc.
An Embarrassingly Simple Approach for Intellectual Property Rights Protection on Recurrent Neural Networks
Oct 04, 2022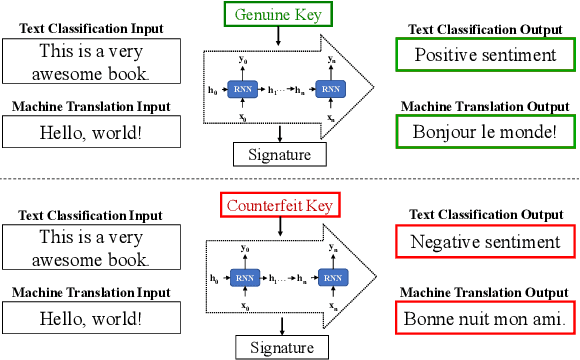
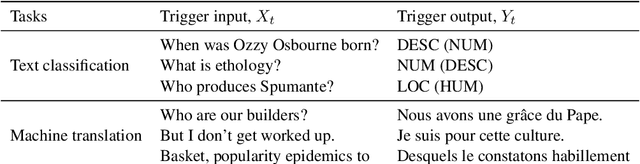
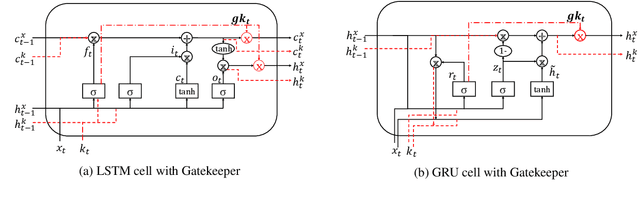
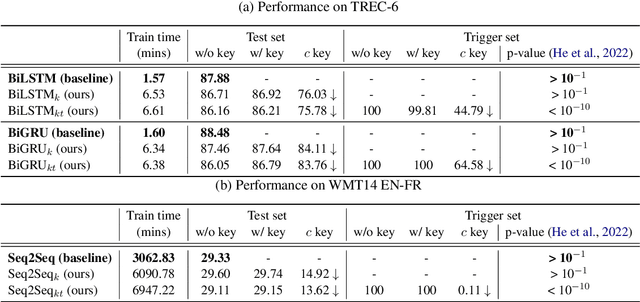
Capitalise on deep learning models, offering Natural Language Processing (NLP) solutions as a part of the Machine Learning as a Service (MLaaS) has generated handsome revenues. At the same time, it is known that the creation of these lucrative deep models is non-trivial. Therefore, protecting these inventions intellectual property rights (IPR) from being abused, stolen and plagiarized is vital. This paper proposes a practical approach for the IPR protection on recurrent neural networks (RNN) without all the bells and whistles of existing IPR solutions. Particularly, we introduce the Gatekeeper concept that resembles the recurrent nature in RNN architecture to embed keys. Also, we design the model training scheme in a way such that the protected RNN model will retain its original performance iff a genuine key is presented. Extensive experiments showed that our protection scheme is robust and effective against ambiguity and removal attacks in both white-box and black-box protection schemes on different RNN variants. Code is available at https://github.com/zhiqin1998/RecurrentIPR
Extremely Low-light Image Enhancement with Scene Text Restoration
Apr 01, 2022
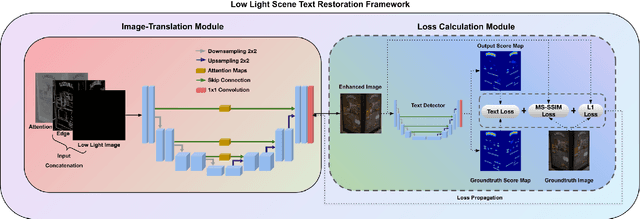


Deep learning-based methods have made impressive progress in enhancing extremely low-light images - the image quality of the reconstructed images has generally improved. However, we found out that most of these methods could not sufficiently recover the image details, for instance, the texts in the scene. In this paper, a novel image enhancement framework is proposed to precisely restore the scene texts, as well as the overall quality of the image simultaneously under extremely low-light images conditions. Mainly, we employed a self-regularised attention map, an edge map, and a novel text detection loss. In addition, leveraging synthetic low-light images is beneficial for image enhancement on the genuine ones in terms of text detection. The quantitative and qualitative experimental results have shown that the proposed model outperforms state-of-the-art methods in image restoration, text detection, and text spotting on See In the Dark and ICDAR15 datasets.
ACORT: A Compact Object Relation Transformer for Parameter Efficient Image Captioning
Feb 11, 2022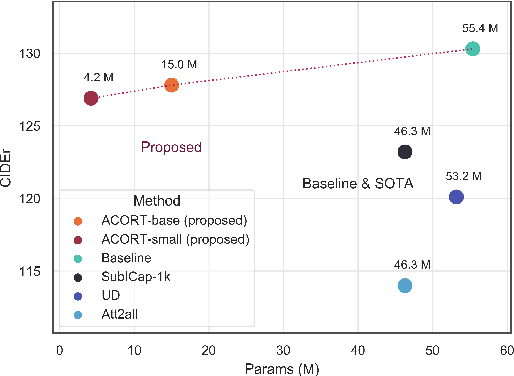
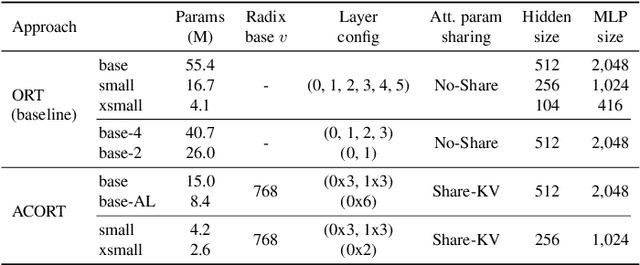
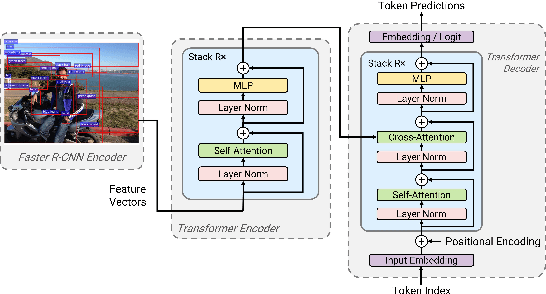
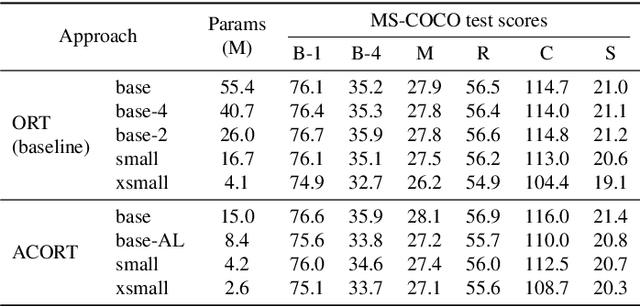
Recent research that applies Transformer-based architectures to image captioning has resulted in state-of-the-art image captioning performance, capitalising on the success of Transformers on natural language tasks. Unfortunately, though these models work well, one major flaw is their large model sizes. To this end, we present three parameter reduction methods for image captioning Transformers: Radix Encoding, cross-layer parameter sharing, and attention parameter sharing. By combining these methods, our proposed ACORT models have 3.7x to 21.6x fewer parameters than the baseline model without compromising test performance. Results on the MS-COCO dataset demonstrate that our ACORT models are competitive against baselines and SOTA approaches, with CIDEr score >=126. Finally, we present qualitative results and ablation studies to demonstrate the efficacy of the proposed changes further. Code and pre-trained models are publicly available at https://github.com/jiahuei/sparse-image-captioning.
End-to-End Supermask Pruning: Learning to Prune Image Captioning Models
Oct 07, 2021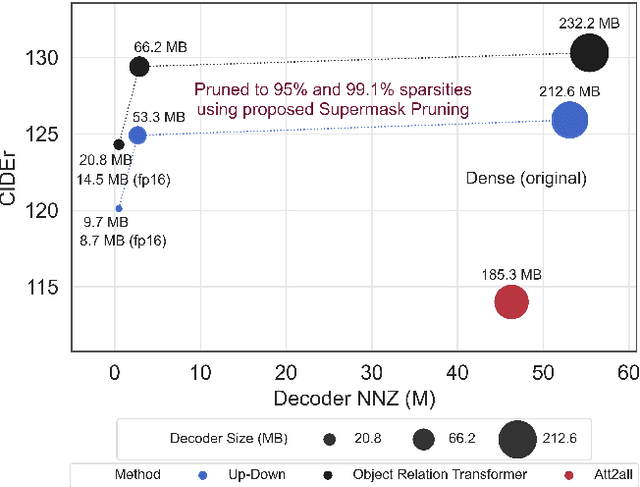
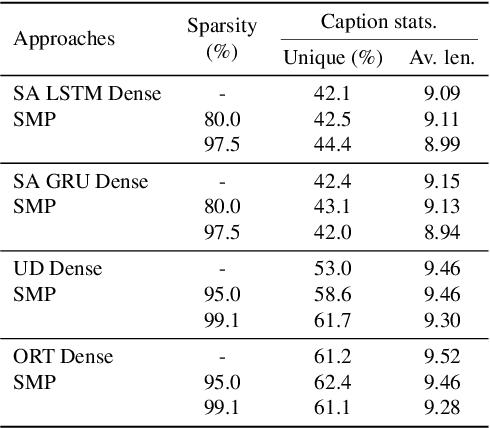
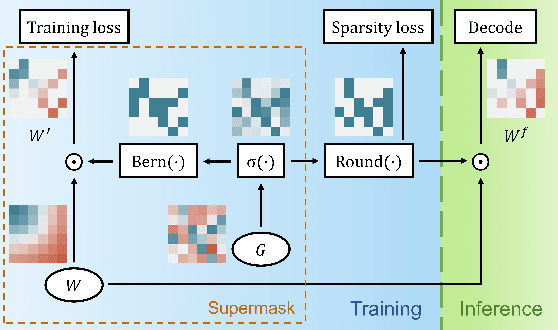
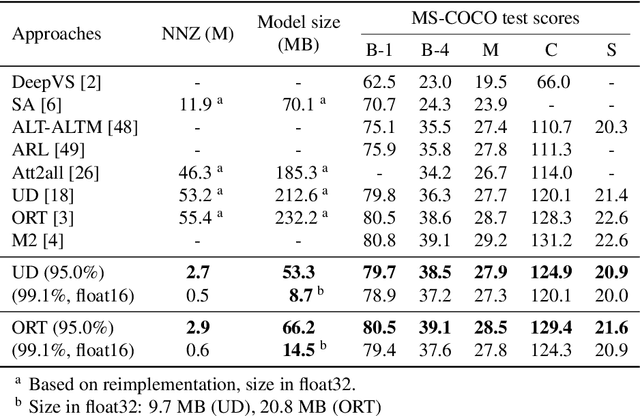
With the advancement of deep models, research work on image captioning has led to a remarkable gain in raw performance over the last decade, along with increasing model complexity and computational cost. However, surprisingly works on compression of deep networks for image captioning task has received little to no attention. For the first time in image captioning research, we provide an extensive comparison of various unstructured weight pruning methods on three different popular image captioning architectures, namely Soft-Attention, Up-Down and Object Relation Transformer. Following this, we propose a novel end-to-end weight pruning method that performs gradual sparsification based on weight sensitivity to the training loss. The pruning schemes are then extended with encoder pruning, where we show that conducting both decoder pruning and training simultaneously prior to the encoder pruning provides good overall performance. Empirically, we show that an 80% to 95% sparse network (up to 75% reduction in model size) can either match or outperform its dense counterpart. The code and pre-trained models for Up-Down and Object Relation Transformer that are capable of achieving CIDEr scores >120 on the MS-COCO dataset but with only 8.7 MB and 14.5 MB in model size (size reduction of 96% and 94% respectively against dense versions) are publicly available at https://github.com/jiahuei/sparse-image-captioning.
One Loss for All: Deep Hashing with a Single Cosine Similarity based Learning Objective
Sep 29, 2021
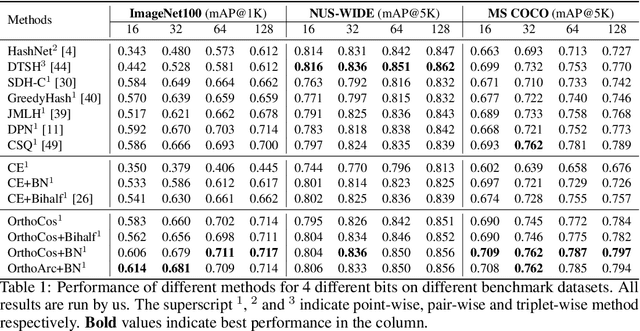
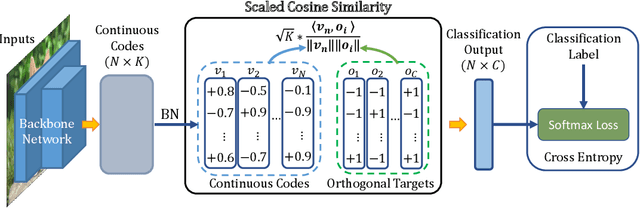
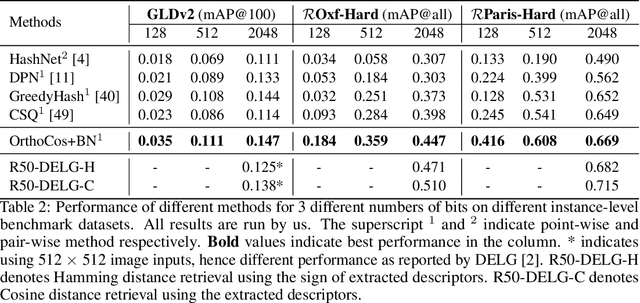
A deep hashing model typically has two main learning objectives: to make the learned binary hash codes discriminative and to minimize a quantization error. With further constraints such as bit balance and code orthogonality, it is not uncommon for existing models to employ a large number (>4) of losses. This leads to difficulties in model training and subsequently impedes their effectiveness. In this work, we propose a novel deep hashing model with only a single learning objective. Specifically, we show that maximizing the cosine similarity between the continuous codes and their corresponding binary orthogonal codes can ensure both hash code discriminativeness and quantization error minimization. Further, with this learning objective, code balancing can be achieved by simply using a Batch Normalization (BN) layer and multi-label classification is also straightforward with label smoothing. The result is an one-loss deep hashing model that removes all the hassles of tuning the weights of various losses. Importantly, extensive experiments show that our model is highly effective, outperforming the state-of-the-art multi-loss hashing models on three large-scale instance retrieval benchmarks, often by significant margins. Code is available at https://github.com/kamwoh/orthohash
ICDAR 2021 Competition on Integrated Circuit Text Spotting and Aesthetic Assessment
Jul 12, 2021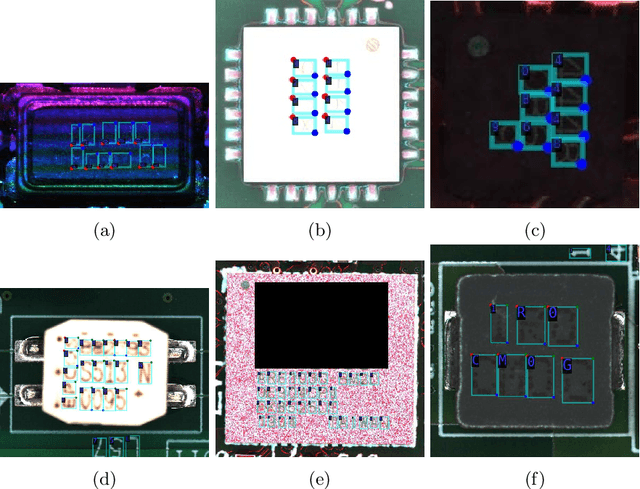


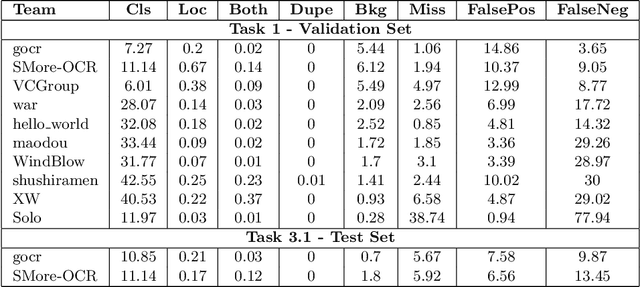
With hundreds of thousands of electronic chip components are being manufactured every day, chip manufacturers have seen an increasing demand in seeking a more efficient and effective way of inspecting the quality of printed texts on chip components. The major problem that deters this area of research is the lacking of realistic text on chips datasets to act as a strong foundation. Hence, a text on chips dataset, ICText is used as the main target for the proposed Robust Reading Challenge on Integrated Circuit Text Spotting and Aesthetic Assessment (RRC-ICText) 2021 to encourage the research on this problem. Throughout the entire competition, we have received a total of 233 submissions from 10 unique teams/individuals. Details of the competition and submission results are presented in this report.
* Technical report of ICDAR 2021 Competition on Integrated Circuit Text Spotting and Aesthetic Assessment