 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake the Pertinent Salient: Task-Relevant Reconstruction for Visual Control with Distractions
Oct 13, 2024



Recent advancements in Model-Based Reinforcement Learning (MBRL) have made it a powerful tool for visual control tasks. Despite improved data efficiency, it remains challenging to train MBRL agents with generalizable perception. Training in the presence of visual distractions is particularly difficult due to the high variation they introduce to representation learning. Building on DREAMER, a popular MBRL method, we propose a simple yet effective auxiliary task to facilitate representation learning in distracting environments. Under the assumption that task-relevant components of image observations are straightforward to identify with prior knowledge in a given task, we use a segmentation mask on image observations to only reconstruct task-relevant components. In doing so, we greatly reduce the complexity of representation learning by removing the need to encode task-irrelevant objects in the latent representation. Our method, Segmentation Dreamer (SD), can be used either with ground-truth masks easily accessible in simulation or by leveraging potentially imperfect segmentation foundation models. The latter is further improved by selectively applying the reconstruction loss to avoid providing misleading learning signals due to mask prediction errors. In modified DeepMind Control suite (DMC) and Meta-World tasks with added visual distractions, SD achieves significantly better sample efficiency and greater final performance than prior work. We find that SD is especially helpful in sparse reward tasks otherwise unsolvable by prior work, enabling the training of visually robust agents without the need for extensive reward engineering.
CriSp: Leveraging Tread Depth Maps for Enhanced Crime-Scene Shoeprint Matching
Apr 25, 2024



Shoeprints are a common type of evidence found at crime scenes and are used regularly in forensic investigations. However, existing methods cannot effectively employ deep learning techniques to match noisy and occluded crime-scene shoeprints to a shoe database due to a lack of training data. Moreover, all existing methods match crime-scene shoeprints to clean reference prints, yet our analysis shows matching to more informative tread depth maps yields better retrieval results. The matching task is further complicated by the necessity to identify similarities only in corresponding regions (heels, toes, etc) of prints and shoe treads. To overcome these challenges, we leverage shoe tread images from online retailers and utilize an off-the-shelf predictor to estimate depth maps and clean prints. Our method, named CriSp, matches crime-scene shoeprints to tread depth maps by training on this data. CriSp incorporates data augmentation to simulate crime-scene shoeprints, an encoder to learn spatially-aware features, and a masking module to ensure only visible regions of crime-scene prints affect retrieval results. To validate our approach, we introduce two validation sets by reprocessing existing datasets of crime-scene shoeprints and establish a benchmarking protocol for comparison. On this benchmark, CriSp significantly outperforms state-of-the-art methods in both automated shoeprint matching and image retrieval tailored to this task.
Instance Tracking in 3D Scenes from Egocentric Videos
Dec 07, 2023



Egocentric sensors such as AR/VR devices capture human-object interactions and offer the potential to provide task-assistance by recalling 3D locations of objects of interest in the surrounding environment. This capability requires instance tracking in real-world 3D scenes from egocentric videos (IT3DEgo). We explore this problem by first introducing a new benchmark dataset, consisting of RGB and depth videos, per-frame camera pose, and instance-level annotations in both 2D camera and 3D world coordinates. We present an evaluation protocol which evaluates tracking performance in 3D coordinates with two settings for enrolling instances to track: (1) single-view online enrollment where an instance is specified on-the-fly based on the human wearer's interactions. and (2) multi-view pre-enrollment where images of an instance to be tracked are stored in memory ahead of time. To address IT3DEgo, we first re-purpose methods from relevant areas, e.g., single object tracking (SOT) -- running SOT methods to track instances in 2D frames and lifting them to 3D using camera pose and depth. We also present a simple method that leverages pretrained segmentation and detection models to generate proposals from RGB frames and match proposals with enrolled instance images. Perhaps surprisingly, our extensive experiments show that our method (with no finetuning) significantly outperforms SOT-based approaches. We conclude by arguing that the problem of egocentric instance tracking is made easier by leveraging camera pose and using a 3D allocentric (world) coordinate representation.
Introspective Cross-Attention Probing for Lightweight Transfer of Pre-trained Models
Mar 07, 2023



We propose InCA, a lightweight method for transfer learning that cross-attends to any activation layer of a pre-trained model. During training, InCA uses a single forward pass to extract multiple activations, which are passed to external cross-attention adapters, trained anew and combined or selected for downstream tasks. We show that, even when selecting a single top-scoring adapter, InCA achieves performance comparable to full fine-tuning, at a cost comparable to fine-tuning just the last layer. For example, with a cross-attention probe 1.3% the size of a pre-trained ViT-L/16 model, we achieve performance within 0.2% of the full fine-tuning paragon at 51% training cost of the baseline, on average across 11 downstream classification tasks. Unlike other forms of efficient adaptation, InCA does not require backpropagating through the pre-trained model, thus leaving its execution unaltered at both training and inference. The versatility of InCA is best illustrated in fine-grained tasks, which may require accessing information absent in the last layer but accessible in intermediate layer activations. Since the backbone is fixed, InCA allows parallel ensembling as well as parallel execution of multiple tasks. InCA achieves state-of-the-art performance in the ImageNet-to-Sketch multi-task benchmark.
The Best of Both Worlds: Combining Model-based and Nonparametric Approaches for 3D Human Body Estimation
May 01, 2022

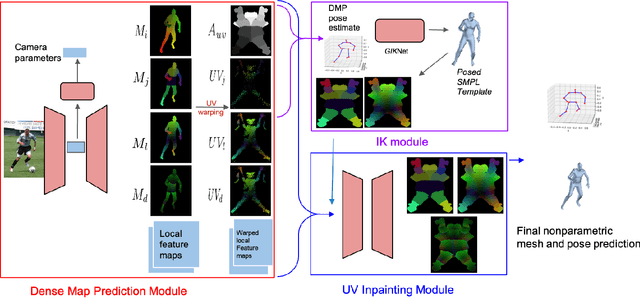
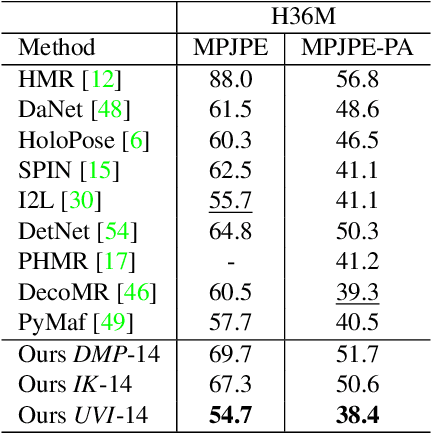
Nonparametric based methods have recently shown promising results in reconstructing human bodies from monocular images while model-based methods can help correct these estimates and improve prediction. However, estimating model parameters from global image features may lead to noticeable misalignment between the estimated meshes and image evidence. To address this issue and leverage the best of both worlds, we propose a framework of three consecutive modules. A dense map prediction module explicitly establishes the dense UV correspondence between the image evidence and each part of the body model. The inverse kinematics module refines the key point prediction and generates a posed template mesh. Finally, a UV inpainting module relies on the corresponding feature, prediction and the posed template, and completes the predictions of occluded body shape. Our framework leverages the best of non-parametric and model-based methods and is also robust to partial occlusion. Experiments demonstrate that our framework outperforms existing 3D human estimation methods on multiple public benchmarks.
Task Adaptive Parameter Sharing for Multi-Task Learning
Mar 30, 2022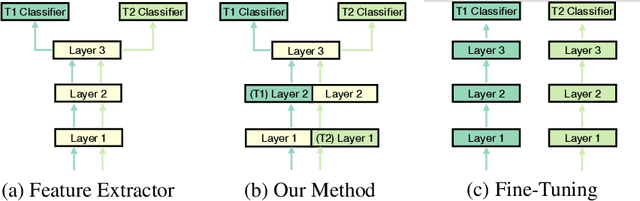
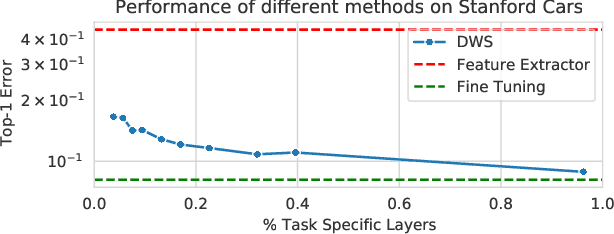
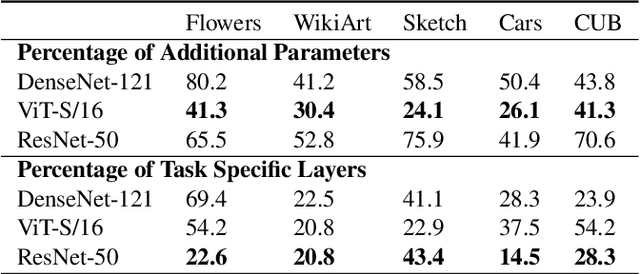
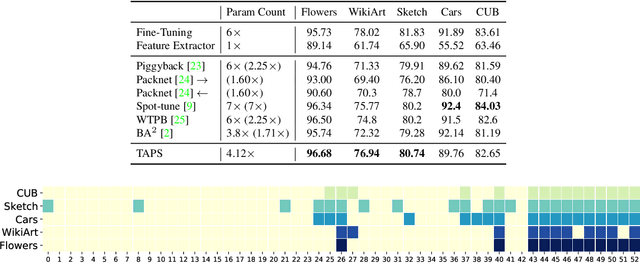
Adapting pre-trained models with broad capabilities has become standard practice for learning a wide range of downstream tasks. The typical approach of fine-tuning different models for each task is performant, but incurs a substantial memory cost. To efficiently learn multiple downstream tasks we introduce Task Adaptive Parameter Sharing (TAPS), a general method for tuning a base model to a new task by adaptively modifying a small, task-specific subset of layers. This enables multi-task learning while minimizing resources used and competition between tasks. TAPS solves a joint optimization problem which determines which layers to share with the base model and the value of the task-specific weights. Further, a sparsity penalty on the number of active layers encourages weight sharing with the base model. Compared to other methods, TAPS retains high accuracy on downstream tasks while introducing few task-specific parameters. Moreover, TAPS is agnostic to the model architecture and requires only minor changes to the training scheme. We evaluate our method on a suite of fine-tuning tasks and architectures (ResNet, DenseNet, ViT) and show that it achieves state-of-the-art performance while being simple to implement.
GeoFill: Reference-Based Image Inpainting of Scenes with Complex Geometry
Jan 20, 2022

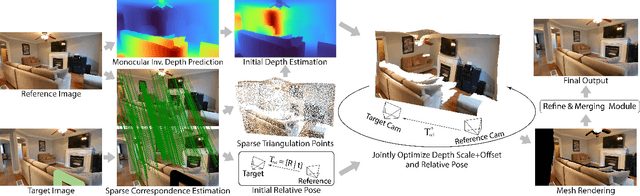
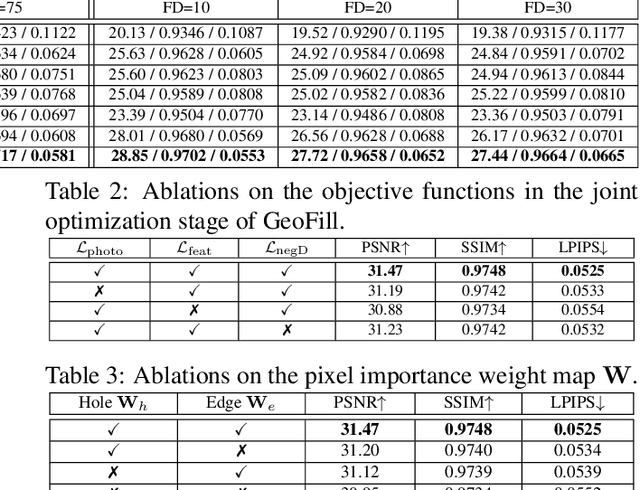
Reference-guided image inpainting restores image pixels by leveraging the content from another reference image. The previous state-of-the-art, TransFill, warps the source image with multiple homographies, and fuses them together for hole filling. Inspired by structure from motion pipelines and recent progress in monocular depth estimation, we propose a more principled approach that does not require heuristic planar assumptions. We leverage a monocular depth estimate and predict relative pose between cameras, then align the reference image to the target by a differentiable 3D reprojection and a joint optimization of relative pose and depth map scale and offset. Our approach achieves state-of-the-art performance on both RealEstate10K and MannequinChallenge dataset with large baselines, complex geometry and extreme camera motions. We experimentally verify our approach is also better at handling large holes.
Representation Consolidation for Training Expert Students
Jul 16, 2021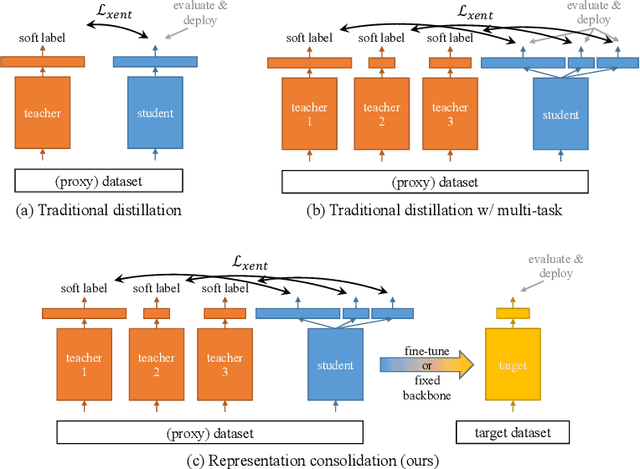

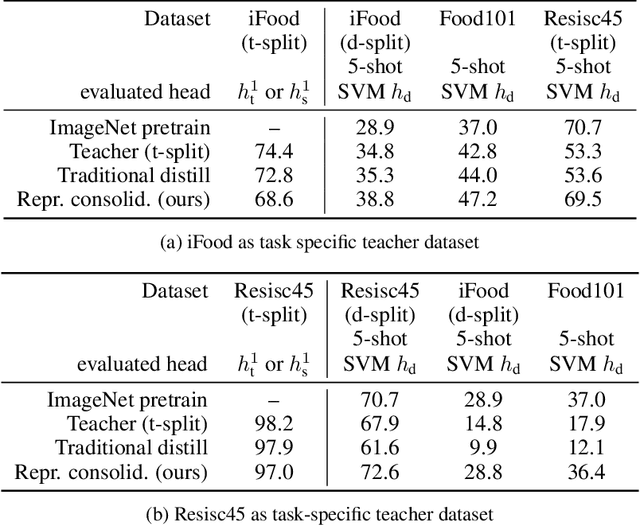

Traditionally, distillation has been used to train a student model to emulate the input/output functionality of a teacher. A more useful goal than emulation, yet under-explored, is for the student to learn feature representations that transfer well to future tasks. However, we observe that standard distillation of task-specific teachers actually *reduces* the transferability of student representations to downstream tasks. We show that a multi-head, multi-task distillation method using an unlabeled proxy dataset and a generalist teacher is sufficient to consolidate representations from task-specific teacher(s) and improve downstream performance, outperforming the teacher(s) and the strong baseline of ImageNet pretrained features. Our method can also combine the representational knowledge of multiple teachers trained on one or multiple domains into a single model, whose representation is improved on all teachers' domain(s).
Unsupervised Action Segmentation with Self-supervised Feature Learning and Co-occurrence Parsing
Jun 02, 2021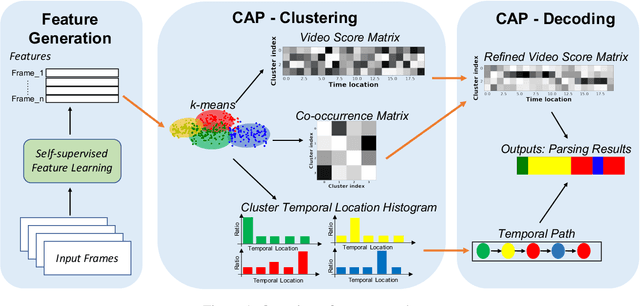
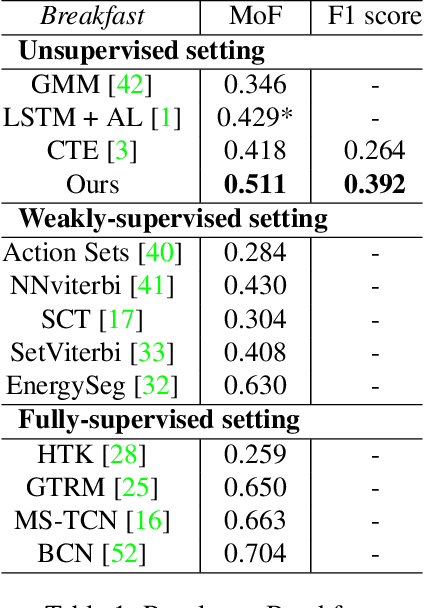
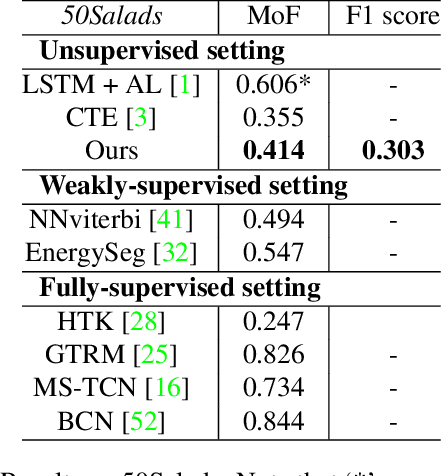
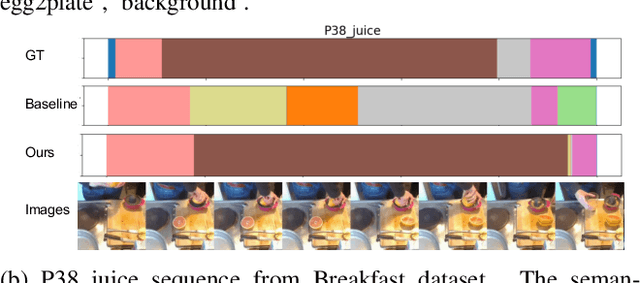
Temporal action segmentation is a task to classify each frame in the video with an action label. However, it is quite expensive to annotate every frame in a large corpus of videos to construct a comprehensive supervised training dataset. Thus in this work we explore a self-supervised method that operates on a corpus of unlabeled videos and predicts a likely set of temporal segments across the videos. To do this we leverage self-supervised video classification approaches to perform unsupervised feature extraction. On top of these features we develop CAP, a novel co-occurrence action parsing algorithm that can not only capture the correlation among sub-actions underlying the structure of activities, but also estimate the temporal trajectory of the sub-actions in an accurate and general way. We evaluate on both classic datasets (Breakfast, 50Salads) and emerging fine-grained action datasets (FineGym) with more complex activity structures and similar sub-actions. Results show that our method achieves state-of-the-art performance on all three datasets with up to 22\% improvement, and can even outperform some weakly-supervised approaches, demonstrating its effectiveness and generalizability.
A linearized framework and a new benchmark for model selection for fine-tuning
Jan 29, 2021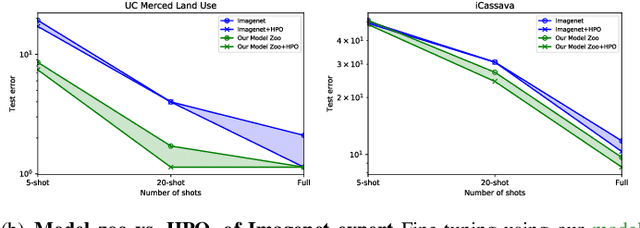

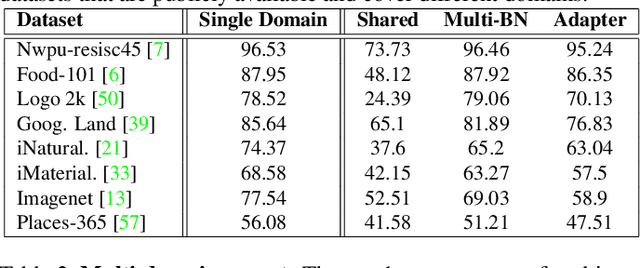
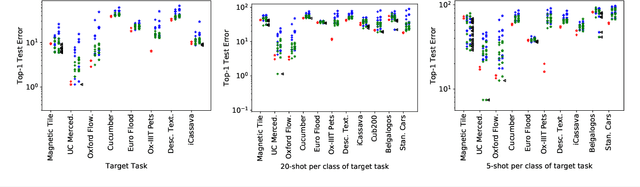
Fine-tuning from a collection of models pre-trained on different domains (a "model zoo") is emerging as a technique to improve test accuracy in the low-data regime. However, model selection, i.e. how to pre-select the right model to fine-tune from a model zoo without performing any training, remains an open topic. We use a linearized framework to approximate fine-tuning, and introduce two new baselines for model selection -- Label-Gradient and Label-Feature Correlation. Since all model selection algorithms in the literature have been tested on different use-cases and never compared directly, we introduce a new comprehensive benchmark for model selection comprising of: i) A model zoo of single and multi-domain models, and ii) Many target tasks. Our benchmark highlights accuracy gain with model zoo compared to fine-tuning Imagenet models. We show our model selection baseline can select optimal models to fine-tune in few selections and has the highest ranking correlation to fine-tuning accuracy compared to existing algorithms.