 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperFlow: Gradient-Free Emulation of Few-Shot Fine-Tuning
Paper and Code
Apr 21, 2025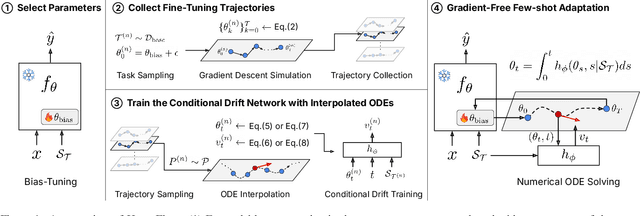



While test-time fine-tuning is beneficial in few-shot learning, the need for multiple backpropagation steps can be prohibitively expensive in real-time or low-resource scenarios. To address this limitation, we propose an approach that emulates gradient descent without computing gradients, enabling efficient test-time adaptation. Specifically, we formulate gradient descent as an Euler discretization of an ordinary differential equation (ODE) and train an auxiliary network to predict the task-conditional drift using only the few-shot support set. The adaptation then reduces to a simple numerical integration (e.g., via the Euler method), which requires only a few forward passes of the auxiliary network -- no gradients or forward passes of the target model are needed. In experiments on cross-domain few-shot classification using the Meta-Dataset and CDFSL benchmarks, our method significantly improves out-of-domain performance over the non-fine-tuned baseline while incurring only 6\% of the memory cost and 0.02\% of the computation time of standard fine-tuning, thus establishing a practical middle ground between direct transfer and fully fine-tuned approaches.