 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning High-Dimensional Distributions with Latent Neural Fokker-Planck Kernels
May 10, 2021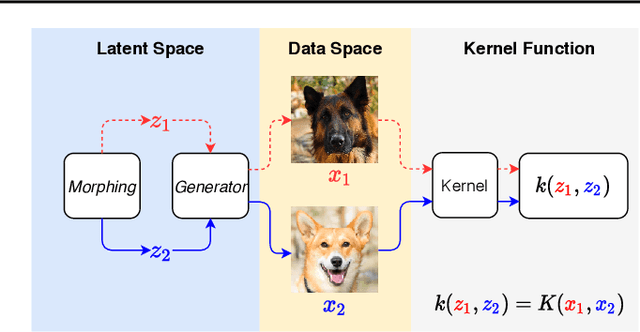


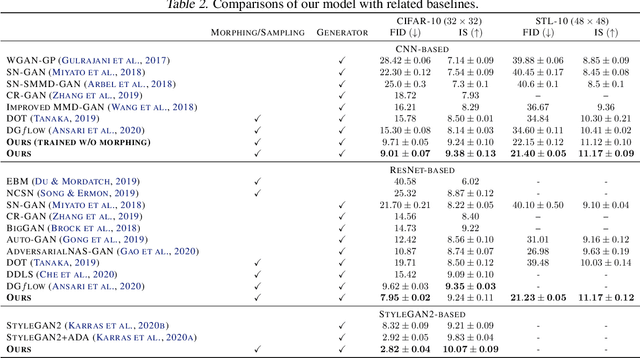
Learning high-dimensional distributions is an important yet challenging problem in machine learning with applications in various domains. In this paper, we introduce new techniques to formulate the problem as solving Fokker-Planck equation in a lower-dimensional latent space, aiming to mitigate challenges in high-dimensional data space. Our proposed model consists of latent-distribution morphing, a generator and a parameterized Fokker-Planck kernel function. One fascinating property of our model is that it can be trained with arbitrary steps of latent distribution morphing or even without morphing, which makes it flexible and as efficient as Generative Adversarial Networks (GANs). Furthermore, this property also makes our latent-distribution morphing an efficient plug-and-play scheme, thus can be used to improve arbitrary GANs, and more interestingly, can effectively correct failure cases of the GAN models. Extensive experiments illustrate the advantages of our proposed method over existing models.
Towards Fair Federated Learning with Zero-Shot Data Augmentation
Apr 27, 2021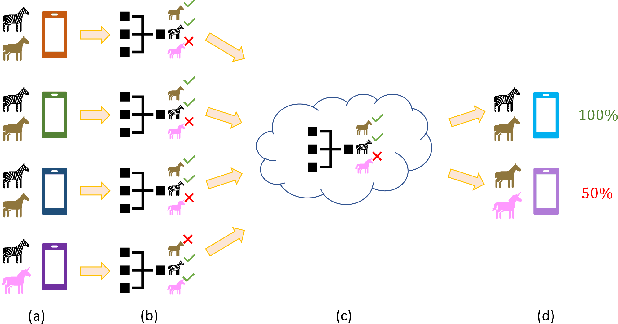
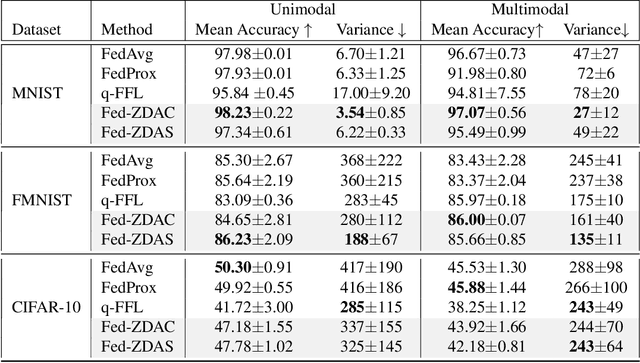
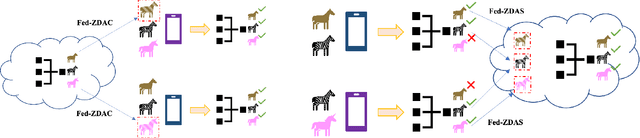
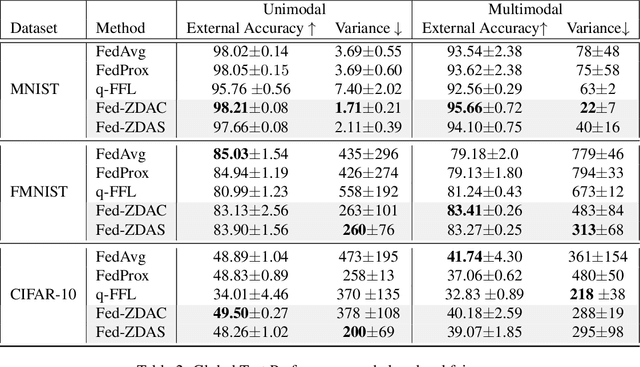
Federated learning has emerged as an important distributed learning paradigm, where a server aggregates a global model from many client-trained models while having no access to the client data. Although it is recognized that statistical heterogeneity of the client local data yields slower global model convergence, it is less commonly recognized that it also yields a biased federated global model with a high variance of accuracy across clients. In this work, we aim to provide federated learning schemes with improved fairness. To tackle this challenge, we propose a novel federated learning system that employs zero-shot data augmentation on under-represented data to mitigate statistical heterogeneity and encourage more uniform accuracy performance across clients in federated networks. We study two variants of this scheme, Fed-ZDAC (federated learning with zero-shot data augmentation at the clients) and Fed-ZDAS (federated learning with zero-shot data augmentation at the server). Empirical results on a suite of datasets demonstrate the effectiveness of our methods on simultaneously improving the test accuracy and fairness.
Meta-Learning with Neural Tangent Kernels
Feb 09, 2021
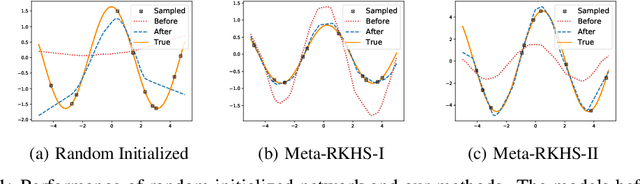
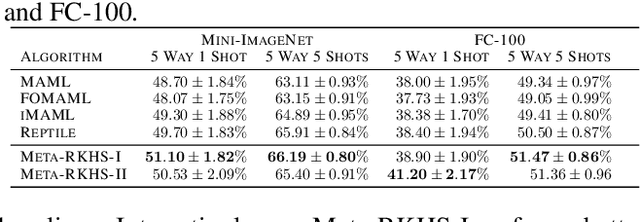
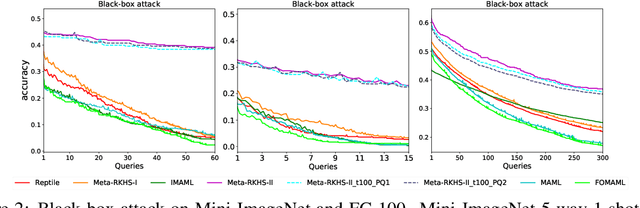
Model Agnostic Meta-Learning (MAML) has emerged as a standard framework for meta-learning, where a meta-model is learned with the ability of fast adapting to new tasks. However, as a double-looped optimization problem, MAML needs to differentiate through the whole inner-loop optimization path for every outer-loop training step, which may lead to both computational inefficiency and sub-optimal solutions. In this paper, we generalize MAML to allow meta-learning to be defined in function spaces, and propose the first meta-learning paradigm in the Reproducing Kernel Hilbert Space (RKHS) induced by the meta-model's Neural Tangent Kernel (NTK). Within this paradigm, we introduce two meta-learning algorithms in the RKHS, which no longer need a sub-optimal iterative inner-loop adaptation as in the MAML framework. We achieve this goal by 1) replacing the adaptation with a fast-adaptive regularizer in the RKHS; and 2) solving the adaptation analytically based on the NTK theory. Extensive experimental studies demonstrate advantages of our paradigm in both efficiency and quality of solutions compared to related meta-learning algorithms. Another interesting feature of our proposed methods is that they are demonstrated to be more robust to adversarial attacks and out-of-distribution adaptation than popular baselines, as demonstrated in our experiments.
Transformer-based Conditional Variational Autoencoder for Controllable Story Generation
Jan 04, 2021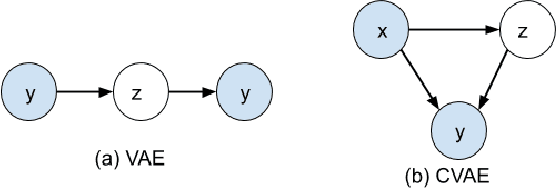

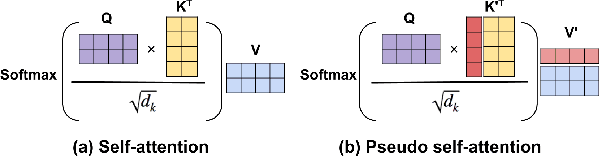

We investigate large-scale latent variable models (LVMs) for neural story generation -- an under-explored application for open-domain long text -- with objectives in two threads: generation effectiveness and controllability. LVMs, especially the variational autoencoder (VAE), have achieved both effective and controllable generation through exploiting flexible distributional latent representations. Recently, Transformers and its variants have achieved remarkable effectiveness without explicit latent representation learning, thus lack satisfying controllability in generation. In this paper, we advocate to revive latent variable modeling, essentially the power of representation learning, in the era of Transformers to enhance controllability without hurting state-of-the-art generation effectiveness. Specifically, we integrate latent representation vectors with a Transformer-based pre-trained architecture to build conditional variational autoencoder (CVAE). Model components such as encoder, decoder and the variational posterior are all built on top of pre-trained language models -- GPT2 specifically in this paper. Experiments demonstrate state-of-the-art conditional generation ability of our model, as well as its excellent representation learning capability and controllability.
Outline to Story: Fine-grained Controllable Story Generation from Cascaded Events
Jan 04, 2021
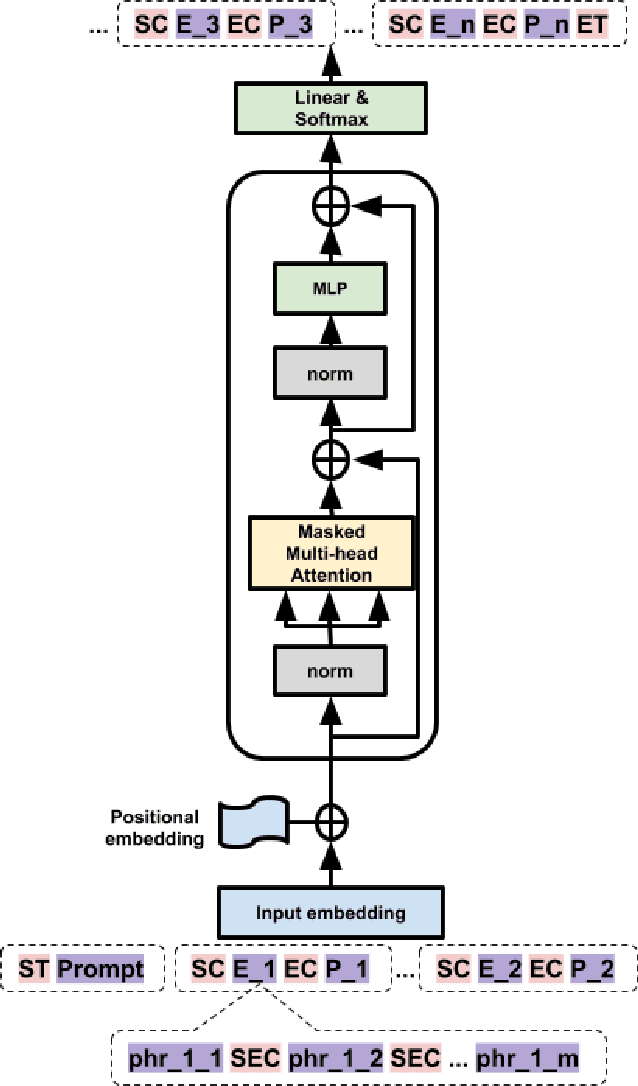


Large-scale pretrained language models have shown thrilling generation capabilities, especially when they generate consistent long text in thousands of words with ease. However, users of these models can only control the prefix of sentences or certain global aspects of generated text. It is challenging to simultaneously achieve fine-grained controllability and preserve the state-of-the-art unconditional text generation capability. In this paper, we first propose a new task named "Outline to Story" (O2S) as a test bed for fine-grained controllable generation of long text, which generates a multi-paragraph story from cascaded events, i.e. a sequence of outline events that guide subsequent paragraph generation. We then create dedicate datasets for future benchmarks, built by state-of-the-art keyword extraction techniques. Finally, we propose an extremely simple yet strong baseline method for the O2S task, which fine tunes pre-trained language models on augmented sequences of outline-story pairs with simple language modeling objective. Our method does not introduce any new parameters or perform any architecture modification, except several special tokens as delimiters to build augmented sequences. Extensive experiments on various datasets demonstrate state-of-the-art conditional story generation performance with our model, achieving better fine-grained controllability and user flexibility. Our paper is among the first ones by our knowledge to propose a model and to create datasets for the task of "outline to story". Our work also instantiates research interest of fine-grained controllable generation of open-domain long text, where controlling inputs are represented by short text.
What all do audio transformer models hear? Probing Acoustic Representations for Language Delivery and its Structure
Jan 02, 2021

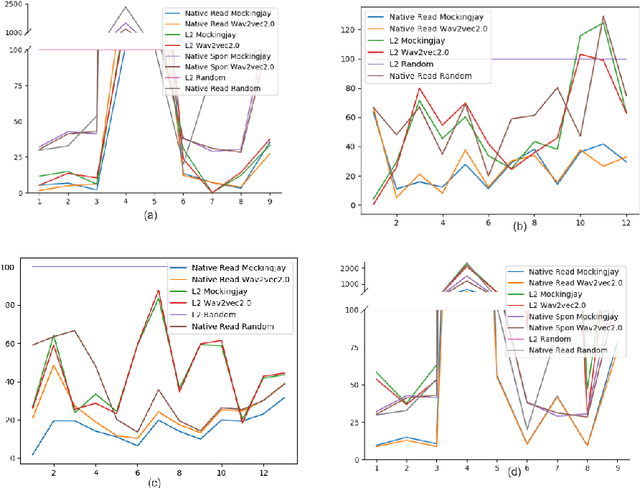

In recent times, BERT based transformer models have become an inseparable part of the 'tech stack' of text processing models. Similar progress is being observed in the speech domain with a multitude of models observing state-of-the-art results by using audio transformer models to encode speech. This begs the question of what are these audio transformer models learning. Moreover, although the standard methodology is to choose the last layer embedding for any downstream task, but is it the optimal choice? We try to answer these questions for the two recent audio transformer models, Mockingjay and wave2vec2.0. We compare them on a comprehensive set of language delivery and structure features including audio, fluency and pronunciation features. Additionally, we probe the audio models' understanding of textual surface, syntax, and semantic features and compare them to BERT. We do this over exhaustive settings for native, non-native, synthetic, read and spontaneous speech datasets
SDA: Improving Text Generation with Self Data Augmentation
Jan 02, 2021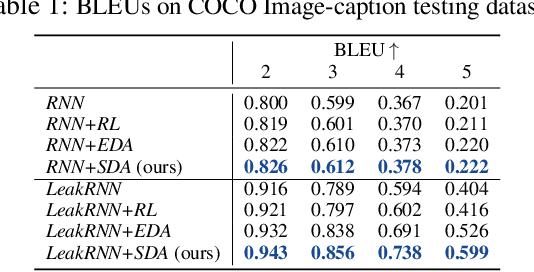
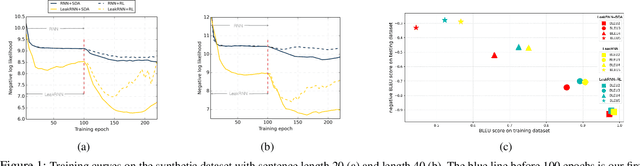
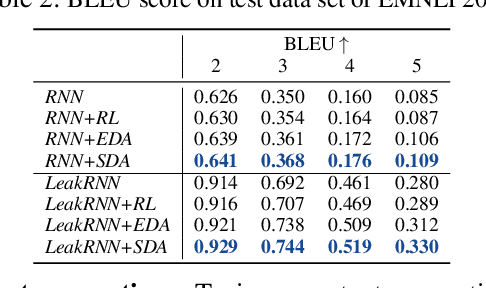

Data augmentation has been widely used to improve deep neural networks in many research fields, such as computer vision. However, less work has been done in the context of text, partially due to its discrete nature and the complexity of natural languages. In this paper, we propose to improve the standard maximum likelihood estimation (MLE) paradigm by incorporating a self-imitation-learning phase for automatic data augmentation. Unlike most existing sentence-level augmentation strategies, which are only applied to specific models, our method is more general and could be easily adapted to any MLE-based training procedure. In addition, our framework allows task-specific evaluation metrics to be designed to flexibly control the generated sentences, for example, in terms of controlling vocabulary usage and avoiding nontrivial repetitions. Extensive experimental results demonstrate the superiority of our method on two synthetic and several standard real datasets, significantly improving related baselines.
My Teacher Thinks The World Is Flat! Interpreting Automatic Essay Scoring Mechanism
Dec 27, 2020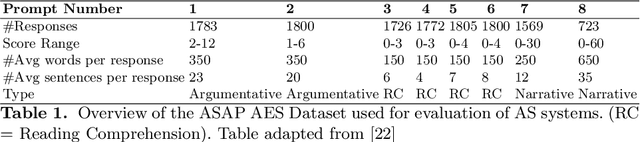
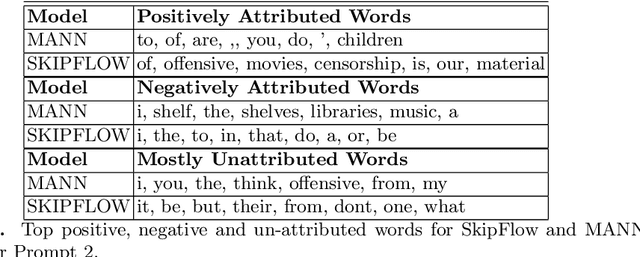
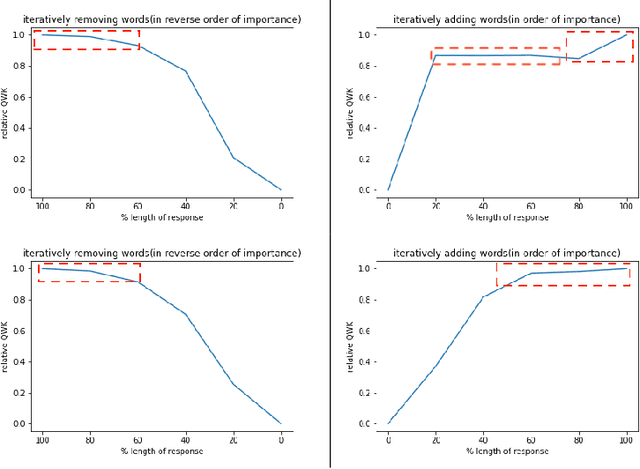
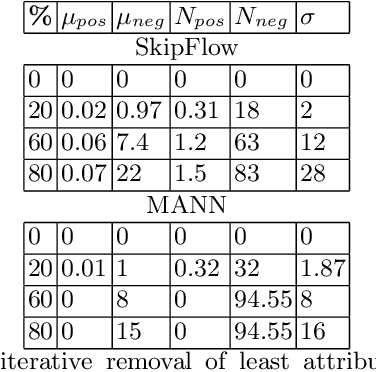
Significant progress has been made in deep-learning based Automatic Essay Scoring (AES) systems in the past two decades. However, little research has been put to understand and interpret the black-box nature of these deep-learning based scoring models. Recent work shows that automated scoring systems are prone to even common-sense adversarial samples. Their lack of natural language understanding capability raises questions on the models being actively used by millions of candidates for life-changing decisions. With scoring being a highly multi-modal task, it becomes imperative for scoring models to be validated and tested on all these modalities. We utilize recent advances in interpretability to find the extent to which features such as coherence, content and relevance are important for automated scoring mechanisms and why they are susceptible to adversarial samples. We find that the systems tested consider essays not as a piece of prose having the characteristics of natural flow of speech and grammatical structure, but as `word-soups' where a few words are much more important than the other words. Removing the context surrounding those few important words causes the prose to lose the flow of speech and grammar, however has little impact on the predicted score. We also find that since the models are not semantically grounded with world-knowledge and common sense, adding false facts such as ``the world is flat'' actually increases the score instead of decreasing it.
ReMP: Rectified Metric Propagation for Few-Shot Learning
Dec 02, 2020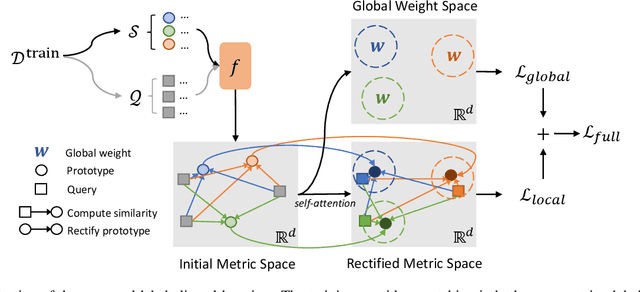
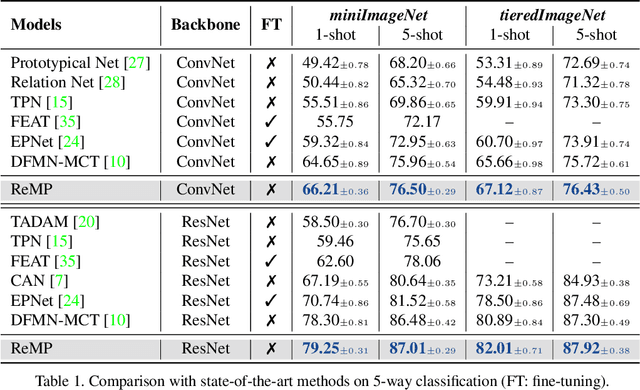
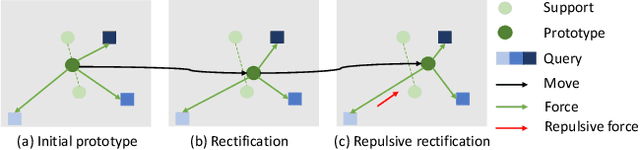

Few-shot learning features the capability of generalizing from a few examples. In this paper, we first identify that a discriminative feature space, namely a rectified metric space, that is learned to maintain the metric consistency from training to testing, is an essential component to the success of metric-based few-shot learning. Numerous analyses indicate that a simple modification of the objective can yield substantial performance gains. The resulting approach, called rectified metric propagation (ReMP), further optimizes an attentive prototype propagation network, and applies a repulsive force to make confident predictions. Extensive experiments demonstrate that the proposed ReMP is effective and efficient, and outperforms the state of the arts on various standard few-shot learning datasets.
Unpaired Image-to-Image Translation via Latent Energy Transport
Dec 01, 2020
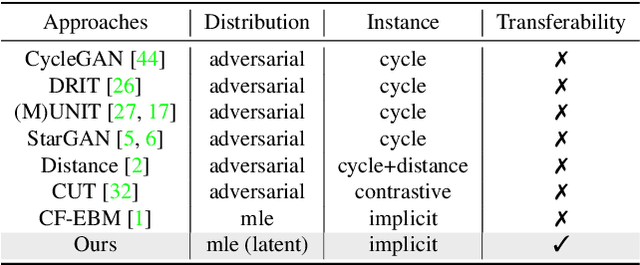
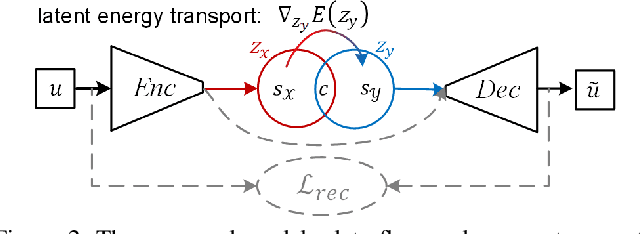

Image-to-image translation aims to preserve source contents while translating to discriminative target styles between two visual domains. Most works apply adversarial learning in the ambient image space, which could be computationally expensive and challenging to train. In this paper, we propose to deploy an energy-based model (EBM) in the latent space of a pretrained autoencoder for this task. The pretrained autoencoder serves as both a latent code extractor and an image reconstruction worker. Our model is based on the assumption that two domains share the same latent space, where latent representation is implicitly decomposed as a content code and a domain-specific style code. Instead of explicitly extracting the two codes and applying adaptive instance normalization to combine them, our latent EBM can implicitly learn to transport the source style code to the target style code while preserving the content code, which is an advantage over existing image translation methods. This simplified solution also brings us far more efficiency in the one-sided unpaired image translation setting. Qualitative and quantitative comparisons demonstrate superior translation quality and faithfulness for content preservation. To the best of our knowledge, our model is the first to be applicable to 1024$\times$1024-resolution unpaired image translation.