 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat You See is What You Get: Visual Pronoun Coreference Resolution in Dialogues
Sep 01, 2019
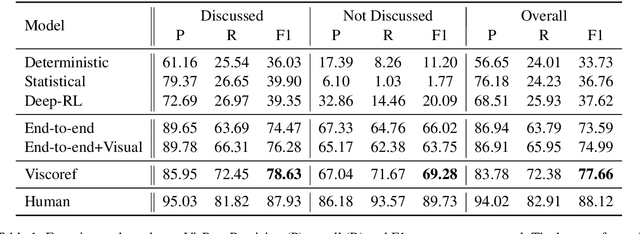
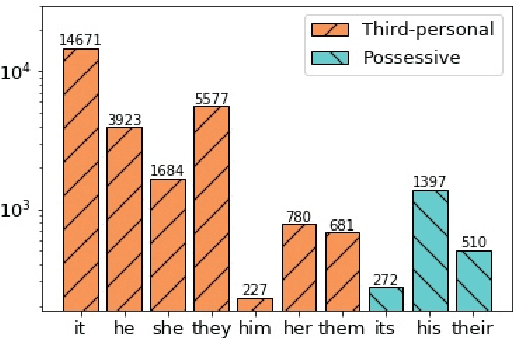
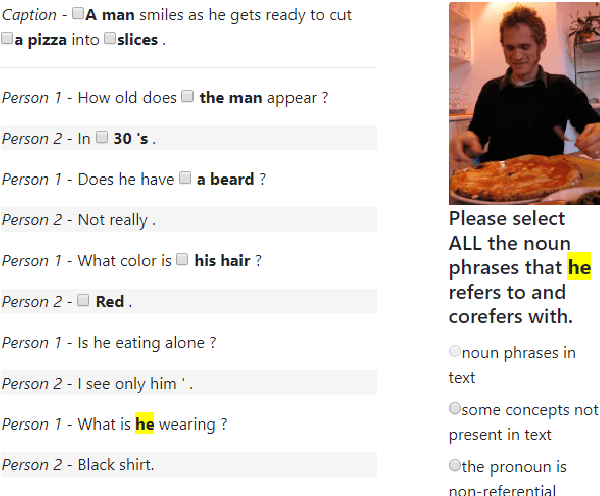
Grounding a pronoun to a visual object it refers to requires complex reasoning from various information sources, especially in conversational scenarios. For example, when people in a conversation talk about something all speakers can see, they often directly use pronouns (e.g., it) to refer to it without previous introduction. This fact brings a huge challenge for modern natural language understanding systems, particularly conventional context-based pronoun coreference models. To tackle this challenge, in this paper, we formally define the task of visual-aware pronoun coreference resolution (PCR) and introduce VisPro, a large-scale dialogue PCR dataset, to investigate whether and how the visual information can help resolve pronouns in dialogues. We then propose a novel visual-aware PCR model, VisCoref, for this task and conduct comprehensive experiments and case studies on our dataset. Results demonstrate the importance of the visual information in this PCR case and show the effectiveness of the proposed model.
Self-reinforcing Unsupervised Matching
Aug 23, 2019


Remarkable gains in deep learning usually rely on tremendous supervised data. Ensuring the modality diversity for one object in training set is critical for the generalization of cutting-edge deep models, but it burdens human with heavy manual labor on data collection and annotation. In addition, some rare or unexpected modalities are new for the current model, causing reduced performance under such emerging modalities. Inspired by the achievements in speech recognition, psychology and behavioristics, we present a practical solution, self-reinforcing unsupervised matching (SUM), to annotate the images with 2D structure-preserving property in an emerging modality by cross-modality matching. This approach requires no any supervision in emerging modality and only one template in seen modality, providing a possible route towards continual learning.
Subspace Attack: Exploiting Promising Subspaces for Query-Efficient Black-box Attacks
Jun 11, 2019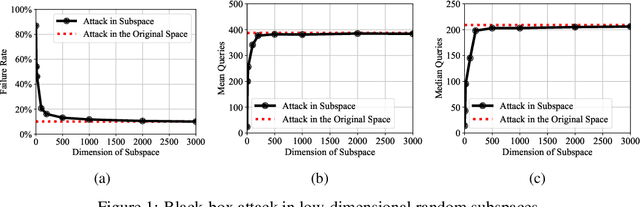
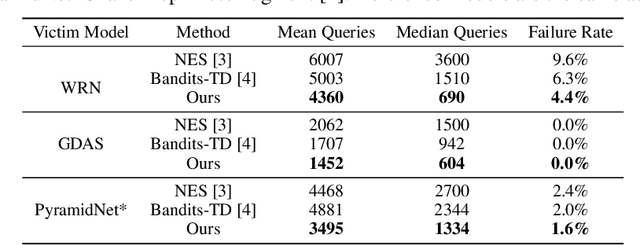
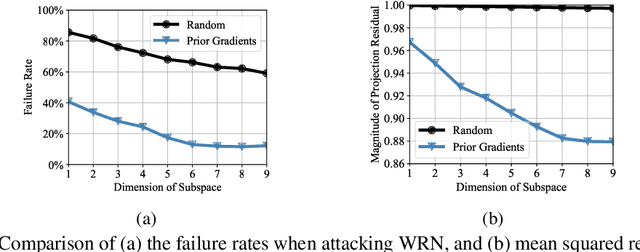

Unlike the white-box counterparts that are widely studied and readily accessible, adversarial examples in black-box settings are generally more Herculean on account of the difficulty of estimating gradients. Many methods achieve the task by issuing numerous queries to target classification systems, which makes the whole procedure costly and suspicious to the systems. In this paper, we aim at reducing the query complexity of black-box attacks in this category. We propose to exploit gradients of a few reference models which arguably span some promising search subspaces. Experimental results show that, in comparison with the state-of-the-arts, our method can gain up to 2x and 4x reductions in the requisite mean and medium numbers of queries with much lower failure rates even if the reference models are trained on a small and inadequate dataset disjoint to the one for training the victim model. Code and models for reproducing our results will be made publicly available.
Deep Likelihood Network for Image Restoration with Multiple Degradations
Apr 19, 2019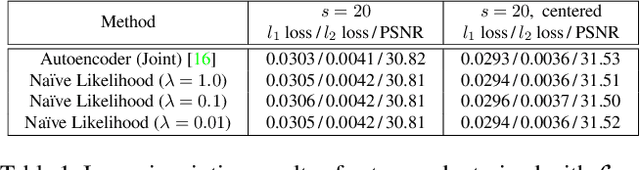
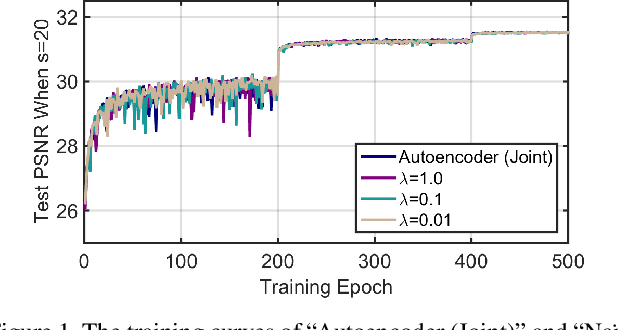
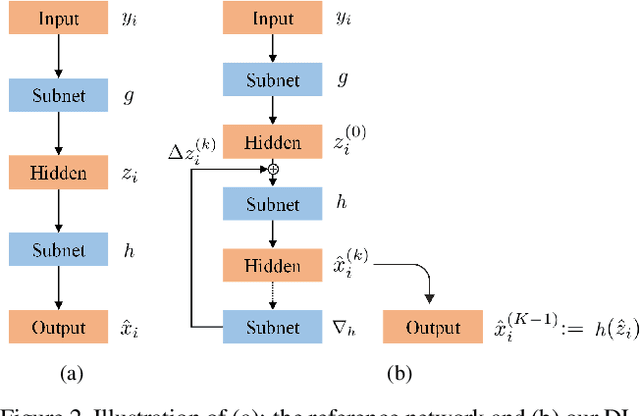

Convolutional neural networks have been proven very effective in a variety of image restoration tasks. Most state-of-the-art solutions, however, are trained using images with a single particular degradation level, and can deteriorate drastically when being applied to some other degradation settings. In this paper, we propose a novel method dubbed deep likelihood network (DL-Net), aiming at generalizing off-the-shelf image restoration networks to succeed over a spectrum of degradation settings while keeping their original learning objectives and core architectures. In particular, we slightly modify the original restoration networks by appending a simple yet effective recursive module, which is derived from a fidelity term for disentangling the effect of degradations. Extensive experimental results on image inpainting, interpolation and super-resolution demonstrate the effectiveness of our DL-Net.
Knowledge Distillation from Few Samples
Dec 05, 2018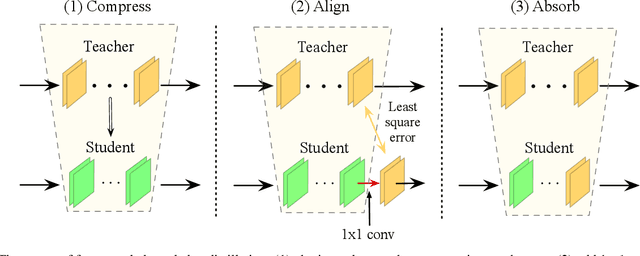
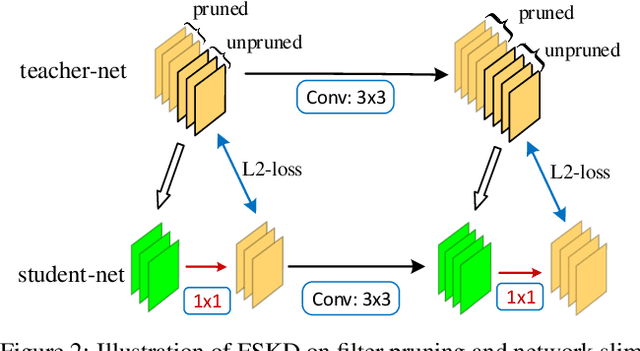
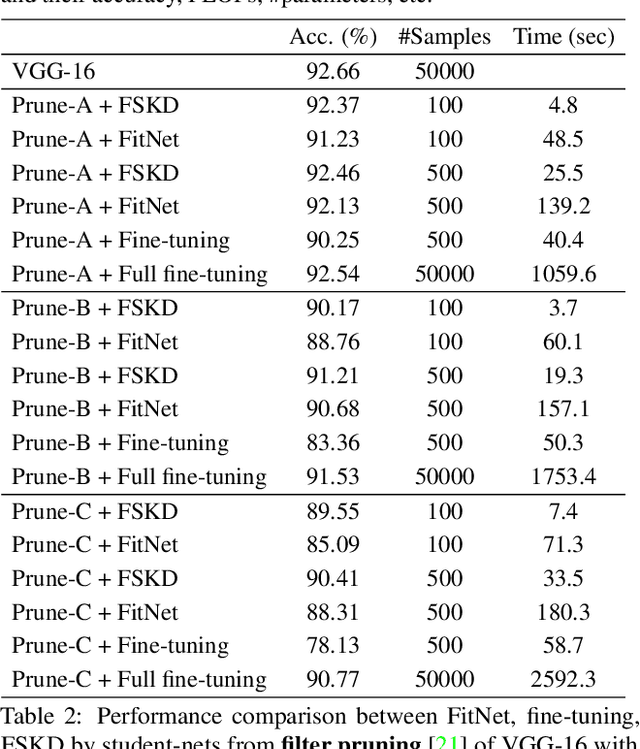
Current knowledge distillation methods require full training data to distill knowledge from a large "teacher" network to a compact "student" network by matching certain statistics between "teacher" and "student" such as softmax outputs and feature responses. This is not only time-consuming but also inconsistent with human cognition in which children can learn knowledge from adults with few examples. This paper proposes a novel and simple method for knowledge distillation from few samples. Taking the assumption that both "teacher" and "student" have the same feature map sizes at each corresponding block, we add a 1x1 conv-layer at the end of each block in the student-net, and align the block-level outputs between "teacher" and "student" by estimating the parameters of the added layer with limited samples. We prove that the added layer can be absorbed/merged into the previous conv-layer to formulate a new conv-layer with the same size of parameters and computation cost as the previous one. Experiments verify that the proposed method is very efficient and effective to distill knowledge from teacher-net to student-net constructing in different ways on various datasets.
Sparse DNNs with Improved Adversarial Robustness
Oct 23, 2018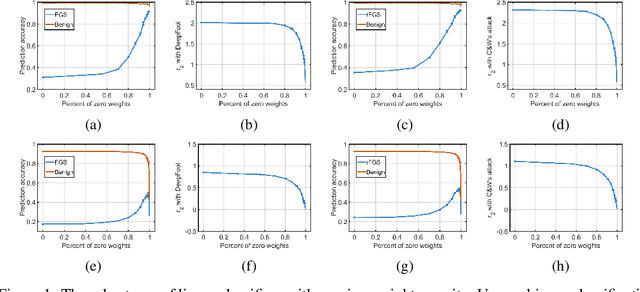
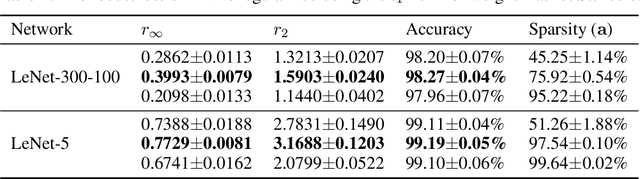
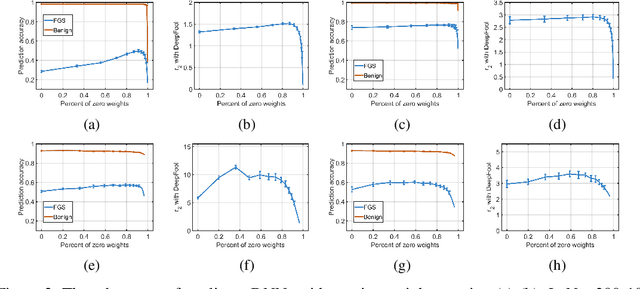
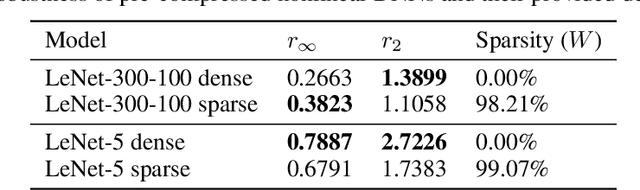
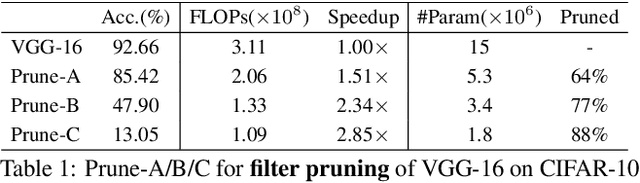
Deep neural networks (DNNs) are computationally/memory-intensive and vulnerable to adversarial attacks, making them prohibitive in some real-world applications. By converting dense models into sparse ones, pruning appears to be a promising solution to reducing the computation/memory cost. This paper studies classification models, especially DNN-based ones, to demonstrate that there exists intrinsic relationships between their sparsity and adversarial robustness. Our analyses reveal, both theoretically and empirically, that nonlinear DNN-based classifiers behave differently under $l_2$ attacks from some linear ones. We further demonstrate that an appropriately higher model sparsity implies better robustness of nonlinear DNNs, whereas over-sparsified models can be more difficult to resist adversarial examples.
Model-Protected Multi-Task Learning
Sep 19, 2018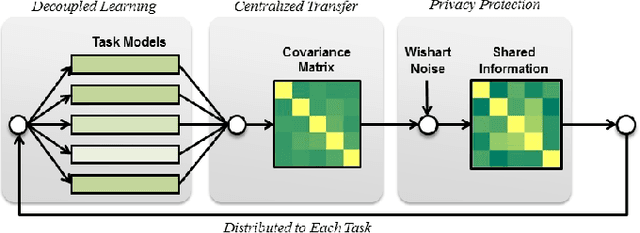

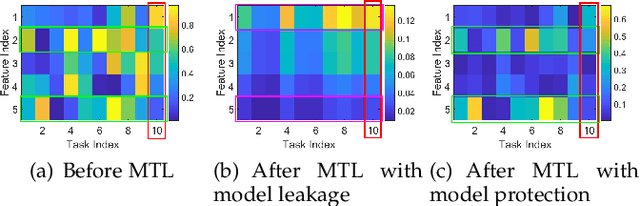
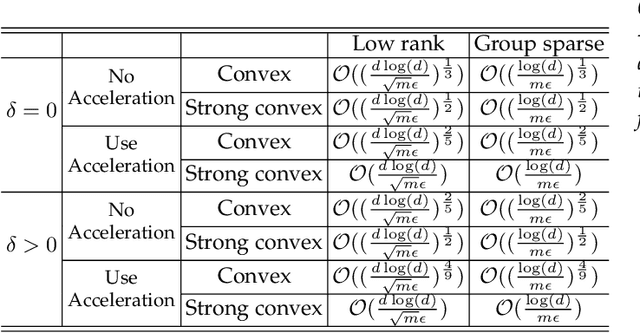
Multi-task learning (MTL) refers to the paradigm of learning multiple related tasks together. By contrast, single-task learning (STL) learns each individual task independently. MTL often leads to better trained models because they can leverage the commonalities among related tasks. However, because MTL algorithms will "transmit" information on different models across different tasks, MTL poses a potential security risk. Specifically, an adversary may participate in the MTL process through a participating task, thereby acquiring the model information for another task. Previously proposed privacy-preserving MTL methods protect data instances rather than models, and some of them may underperform in comparison with STL methods. In this paper, we propose a privacy-preserving MTL framework to prevent the information on each model from leaking to other models based on a perturbation of the covariance matrix of the model matrix, and we study two popular MTL approaches for instantiation, namely, MTL approaches for learning the low-rank and group-sparse patterns of the model matrix. Our methods are built upon tools for differential privacy. Privacy guarantees and utility bounds are provided. Heterogeneous privacy budgets are considered. Our algorithms can be guaranteed not to underperform comparing with STL methods. Experiments demonstrate that our algorithms outperform existing privacy-preserving MTL methods on the proposed model-protection problem.
Deep Defense: Training DNNs with Improved Adversarial Robustness
May 30, 2018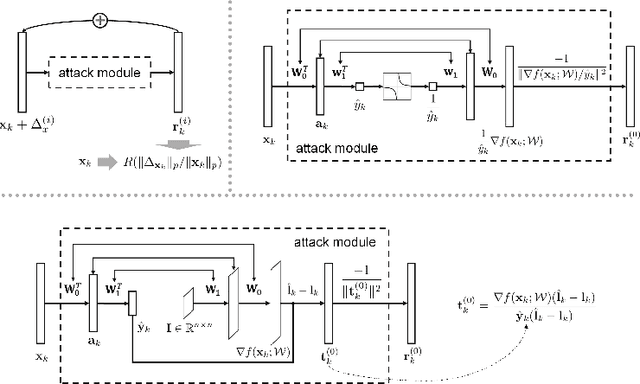
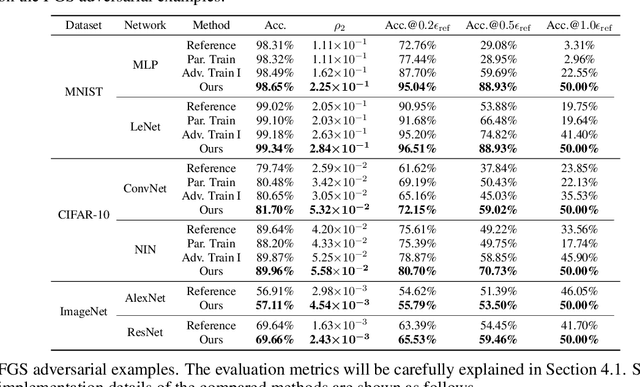
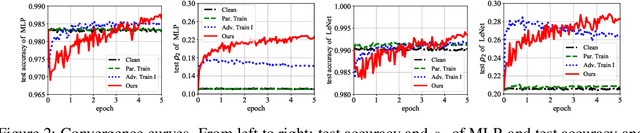
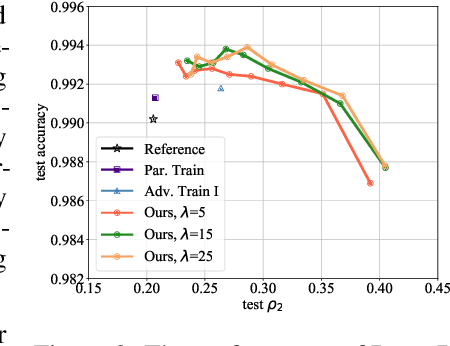
Despite the efficacy on a variety of computer vision tasks, deep neural networks (DNNs) are vulnerable to adversarial attacks, limiting their applications in security-critical systems. Recent works have shown the possibility of generating imperceptibly perturbed image inputs (a.k.a., adversarial examples) to fool well-trained DNN classifiers into making arbitrary predictions. To address this problem, we propose a training recipe named "deep defense". Our core idea is to integrate an adversarial perturbation-based regularizer into the classification objective, such that the obtained models learn to resist potential attacks, directly and precisely. The whole optimization problem is solved just like training a recursive network. Experimental results demonstrate that our method outperforms training with adversarial/Parseval regularizations by large margins on various datasets (including MNIST, CIFAR-10 and ImageNet) and different DNN architectures. Code and models for reproducing our results will be made publicly available.
Optimizing Recurrent Neural Networks Architectures under Time Constraints
Feb 21, 2018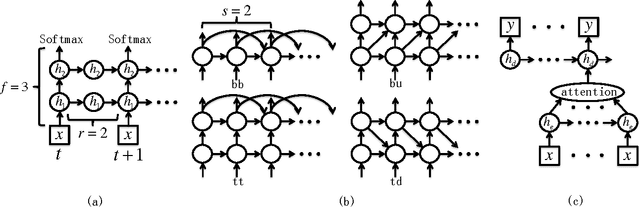
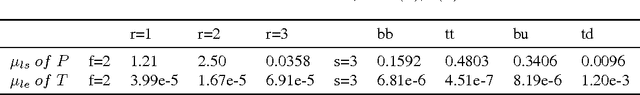
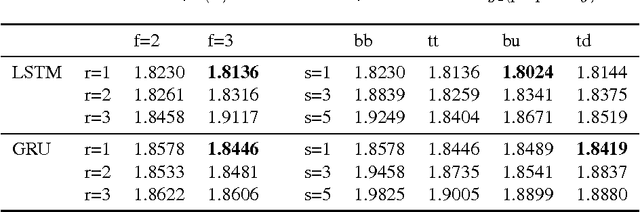
Recurrent neural network (RNN)'s architecture is a key factor influencing its performance. We propose algorithms to optimize hidden sizes under running time constraint. We convert the discrete optimization into a subset selection problem. By novel transformations, the objective function becomes submodular and constraint becomes supermodular. A greedy algorithm with bounds is suggested to solve the transformed problem. And we show how transformations influence the bounds. To speed up optimization, surrogate functions are proposed which balance exploration and exploitation. Experiments show that our algorithms can find more accurate models or faster models than manually tuned state-of-the-art and random search. We also compare popular RNN architectures using our algorithms.
Neural Network Architecture Optimization through Submodularity and Supermodularity
Feb 21, 2018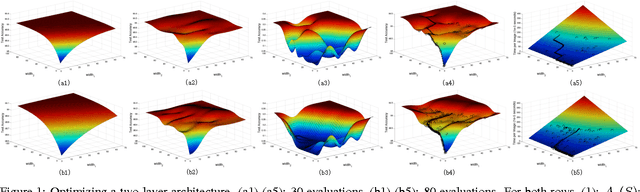
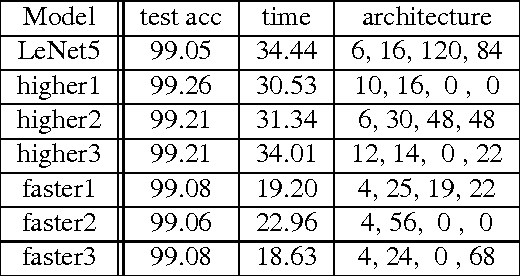
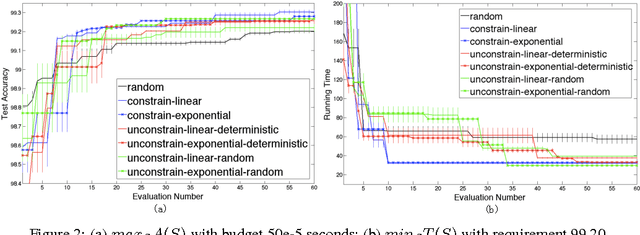
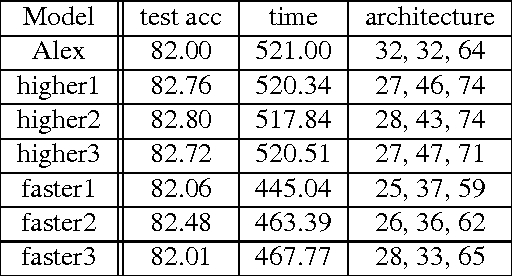
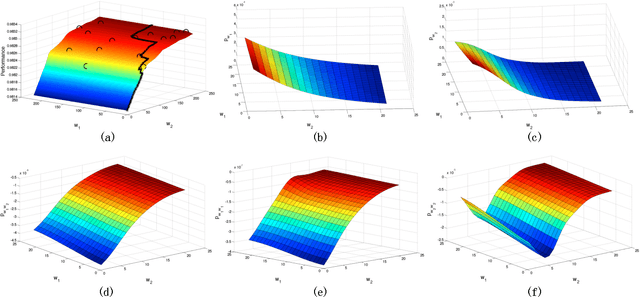
Deep learning models' architectures, including depth and width, are key factors influencing models' performance, such as test accuracy and computation time. This paper solves two problems: given computation time budget, choose an architecture to maximize accuracy, and given accuracy requirement, choose an architecture to minimize computation time. We convert this architecture optimization into a subset selection problem. With accuracy's submodularity and computation time's supermodularity, we propose efficient greedy optimization algorithms. The experiments demonstrate our algorithm's ability to find more accurate models or faster models. By analyzing architecture evolution with growing time budget, we discuss relationships among accuracy, time and architecture, and give suggestions on neural network architecture design.