 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation from Few Samples
Paper and Code
Dec 05, 2018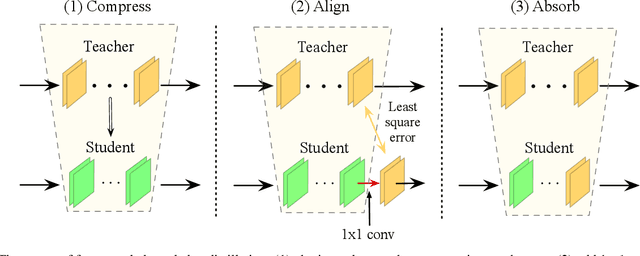
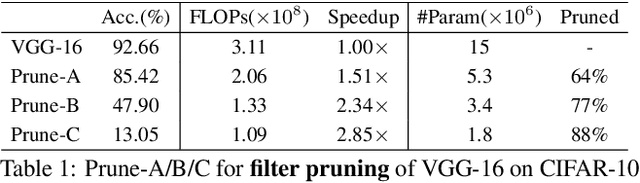
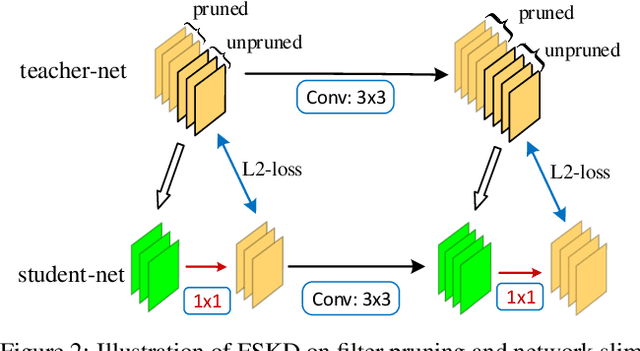
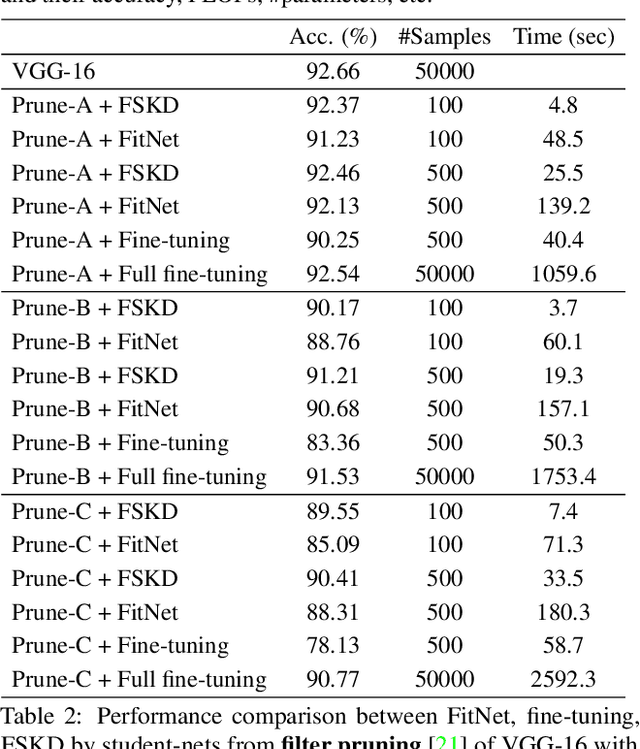
Current knowledge distillation methods require full training data to distill knowledge from a large "teacher" network to a compact "student" network by matching certain statistics between "teacher" and "student" such as softmax outputs and feature responses. This is not only time-consuming but also inconsistent with human cognition in which children can learn knowledge from adults with few examples. This paper proposes a novel and simple method for knowledge distillation from few samples. Taking the assumption that both "teacher" and "student" have the same feature map sizes at each corresponding block, we add a 1x1 conv-layer at the end of each block in the student-net, and align the block-level outputs between "teacher" and "student" by estimating the parameters of the added layer with limited samples. We prove that the added layer can be absorbed/merged into the previous conv-layer to formulate a new conv-layer with the same size of parameters and computation cost as the previous one. Experiments verify that the proposed method is very efficient and effective to distill knowledge from teacher-net to student-net constructing in different ways on various datasets.