 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL4RS: A Real-World Benchmark for Reinforcement Learning based Recommender System
Oct 18, 2021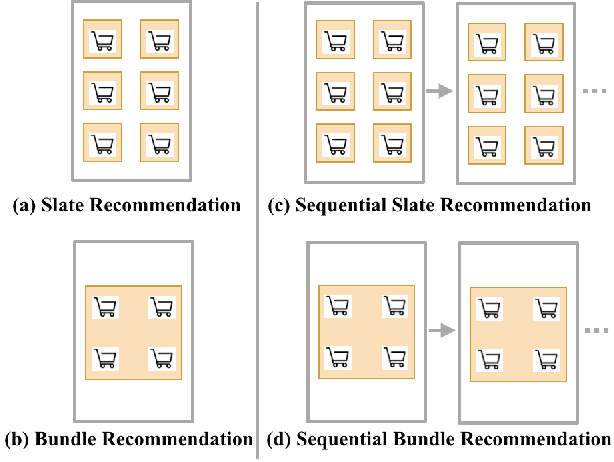
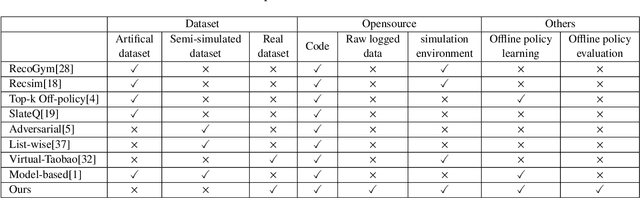
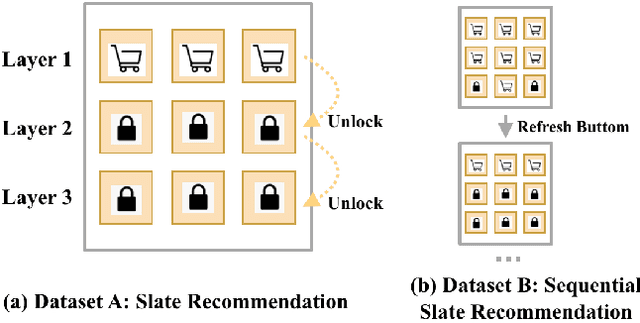
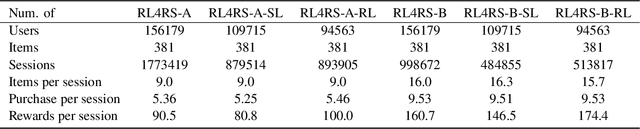
Reinforcement learning based recommender systems (RL-based RS) aims at learning a good policy from a batch of collected data, with casting sequential recommendation to multi-step decision-making tasks. However, current RL-based RS benchmarks commonly have a large reality gap, because they involve artificial RL datasets or semi-simulated RS datasets, and the trained policy is directly evaluated in the simulation environment. In real-world situations, not all recommendation problems are suitable to be transformed into reinforcement learning problems. Unlike previous academic RL researches, RL-based RS suffer from extrapolation error and the difficulties of being well validated before deployment. In this paper, we introduce the RL4RS (Reinforcement Learning for Recommender Systems) benchmark - a new resource fully collected from industrial applications to train and evaluate RL algorithms with special concerns on the above issues. It contains two datasets, tuned simulation environments, related advanced RL baselines, data understanding tools, and counterfactual policy evaluation algorithms. The RL4RS suit can be found at https://github.com/fuxiAIlab/RL4RS. In addition to the RL-based recommender systems, we expect the resource to contribute to research in reinforcement learning and neural combinatorial optimization.
LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation
Aug 30, 2021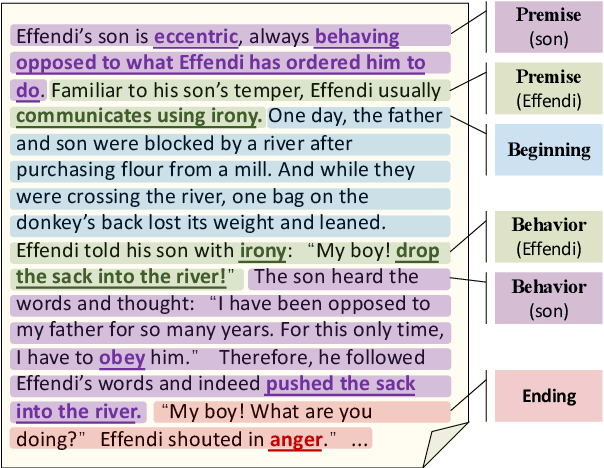

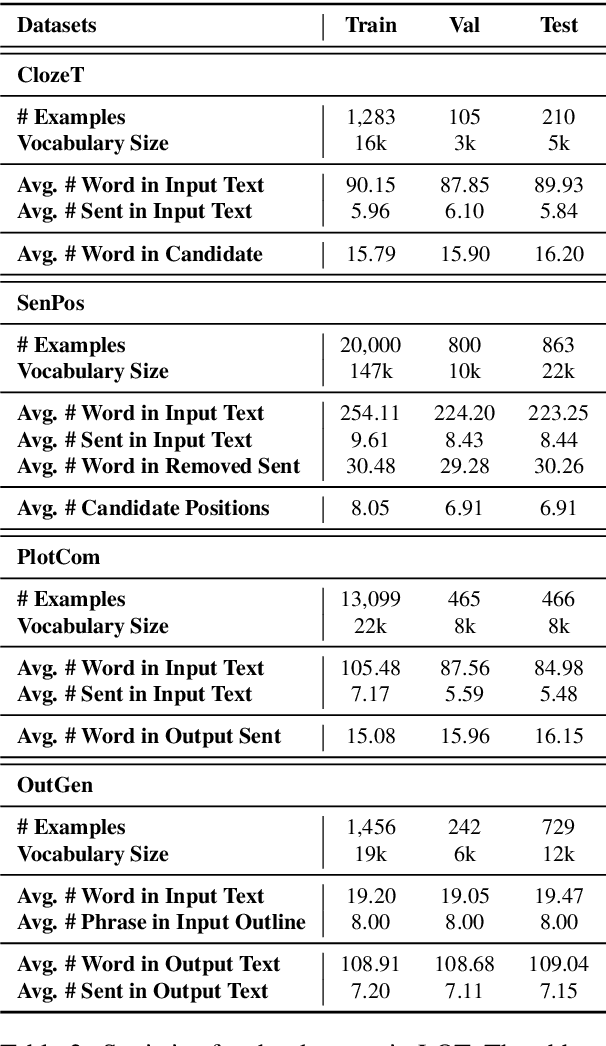

Standard multi-task benchmarks are essential for driving the progress of general pretraining models to generalize to various downstream tasks. However, existing benchmarks such as GLUE and GLGE tend to focus on short text understanding and generation tasks, without considering long text modeling, which requires many distinct capabilities such as modeling long-range commonsense and discourse relations, as well as the coherence and controllability of generation. The lack of standardized benchmarks makes it difficult to fully evaluate these capabilities of a model and fairly compare different models, especially Chinese pretraining models. Therefore, we propose LOT, a benchmark including two understanding and two generation tasks for Chinese long text modeling evaluation. We construct the datasets for the tasks based on various kinds of human-written Chinese stories. Besides, we release an encoder-decoder Chinese long text pretraining model named LongLM with up to 1 billion parameters. We pretrain LongLM on 120G Chinese novels with two generative tasks including text infilling and conditional continuation. Extensive experiments on LOT demonstrate that LongLM matches the performance of similar-sized pretraining models on the understanding tasks and outperforms strong baselines substantially on the generation tasks.
Neural-to-Tree Policy Distillation with Policy Improvement Criterion
Aug 16, 2021
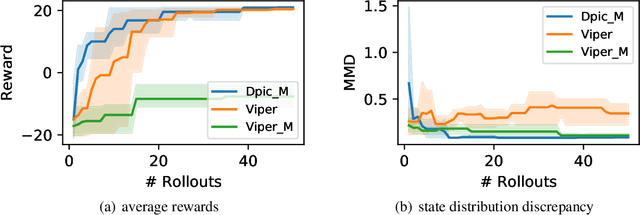
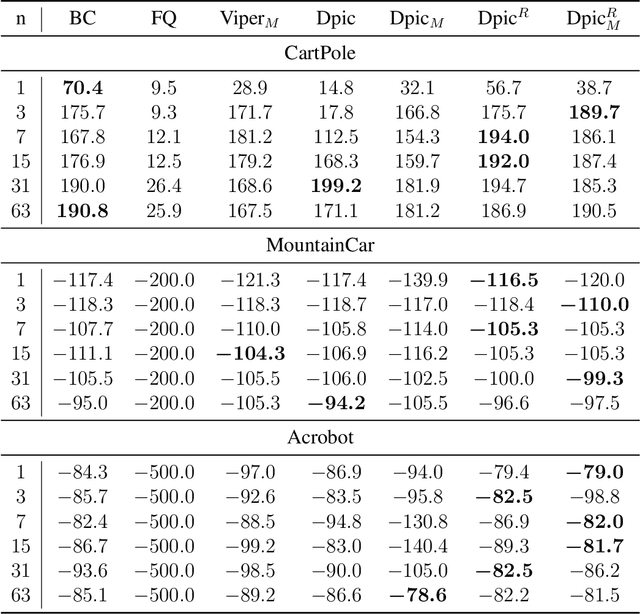
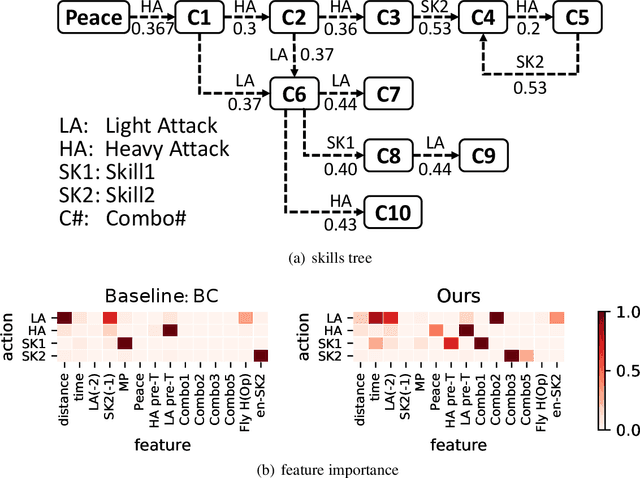
While deep reinforcement learning has achieved promising results in challenging decision-making tasks, the main bones of its success --- deep neural networks are mostly black-boxes. A feasible way to gain insight into a black-box model is to distill it into an interpretable model such as a decision tree, which consists of if-then rules and is easy to grasp and be verified. However, the traditional model distillation is usually a supervised learning task under a stationary data distribution assumption, which is violated in reinforcement learning. Therefore, a typical policy distillation that clones model behaviors with even a small error could bring a data distribution shift, resulting in an unsatisfied distilled policy model with low fidelity or low performance. In this paper, we propose to address this issue by changing the distillation objective from behavior cloning to maximizing an advantage evaluation. The novel distillation objective maximizes an approximated cumulative reward and focuses more on disastrous behaviors in critical states, which controls the data shift effect. We evaluate our method on several Gym tasks, a commercial fight game, and a self-driving car simulator. The empirical results show that the proposed method can preserve a higher cumulative reward than behavior cloning and learn a more consistent policy to the original one. Moreover, by examining the extracted rules from the distilled decision trees, we demonstrate that the proposed method delivers reasonable and robust decisions.
Audio2Head: Audio-driven One-shot Talking-head Generation with Natural Head Motion
Jul 20, 2021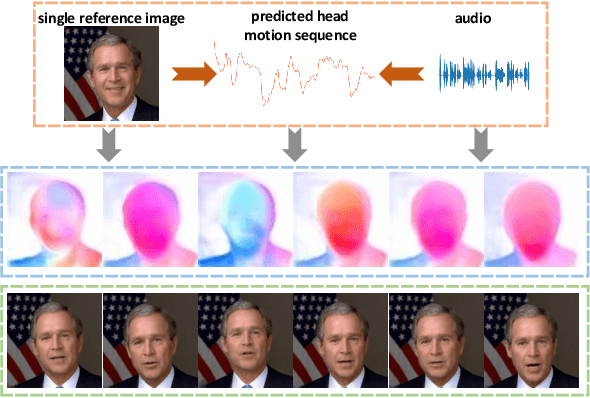
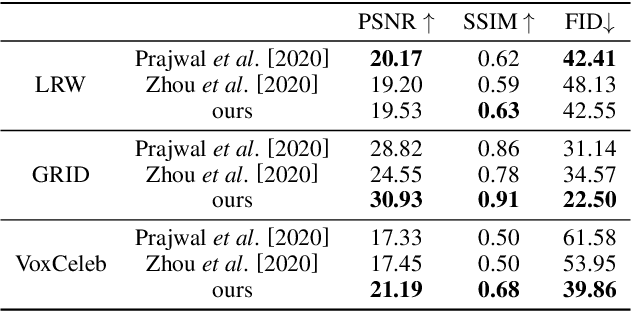
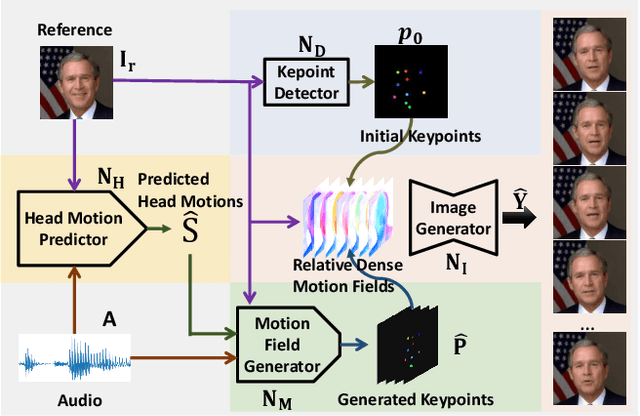

We propose an audio-driven talking-head method to generate photo-realistic talking-head videos from a single reference image. In this work, we tackle two key challenges: (i) producing natural head motions that match speech prosody, and (ii) maintaining the appearance of a speaker in a large head motion while stabilizing the non-face regions. We first design a head pose predictor by modeling rigid 6D head movements with a motion-aware recurrent neural network (RNN). In this way, the predicted head poses act as the low-frequency holistic movements of a talking head, thus allowing our latter network to focus on detailed facial movement generation. To depict the entire image motions arising from audio, we exploit a keypoint based dense motion field representation. Then, we develop a motion field generator to produce the dense motion fields from input audio, head poses, and a reference image. As this keypoint based representation models the motions of facial regions, head, and backgrounds integrally, our method can better constrain the spatial and temporal consistency of the generated videos. Finally, an image generation network is employed to render photo-realistic talking-head videos from the estimated keypoint based motion fields and the input reference image. Extensive experiments demonstrate that our method produces videos with plausible head motions, synchronized facial expressions, and stable backgrounds and outperforms the state-of-the-art.
GLIB: Towards Automated Test Oracle for Graphically-Rich Applications
Jul 15, 2021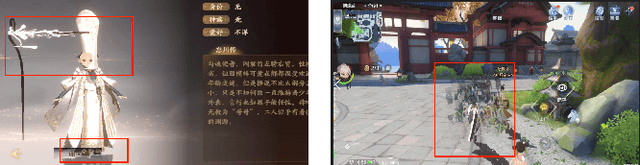
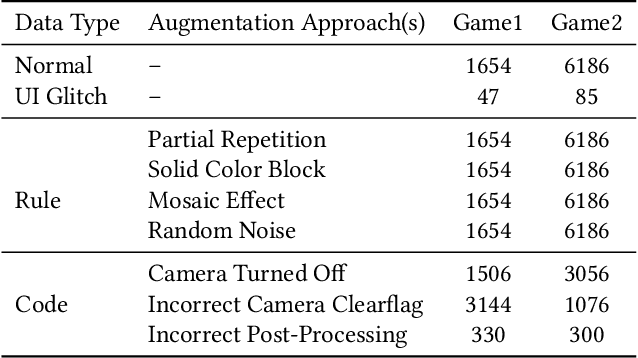
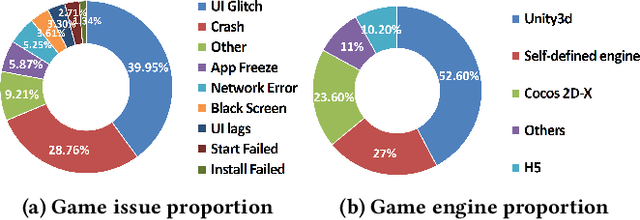
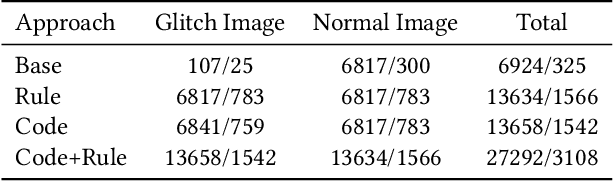
Graphically-rich applications such as games are ubiquitous with attractive visual effects of Graphical User Interface (GUI) that offers a bridge between software applications and end-users. However, various types of graphical glitches may arise from such GUI complexity and have become one of the main component of software compatibility issues. Our study on bug reports from game development teams in NetEase Inc. indicates that graphical glitches frequently occur during the GUI rendering and severely degrade the quality of graphically-rich applications such as video games. Existing automated testing techniques for such applications focus mainly on generating various GUI test sequences and check whether the test sequences can cause crashes. These techniques require constant human attention to captures non-crashing bugs such as bugs causing graphical glitches. In this paper, we present the first step in automating the test oracle for detecting non-crashing bugs in graphically-rich applications. Specifically, we propose \texttt{GLIB} based on a code-based data augmentation technique to detect game GUI glitches. We perform an evaluation of \texttt{GLIB} on 20 real-world game apps (with bug reports available) and the result shows that \texttt{GLIB} can achieve 100\% precision and 99.5\% recall in detecting non-crashing bugs such as game GUI glitches. Practical application of \texttt{GLIB} on another 14 real-world games (without bug reports) further demonstrates that \texttt{GLIB} can effectively uncover GUI glitches, with 48 of 53 bugs reported by \texttt{GLIB} having been confirmed and fixed so far.
Unifying Behavioral and Response Diversity for Open-ended Learning in Zero-sum Games
Jun 10, 2021
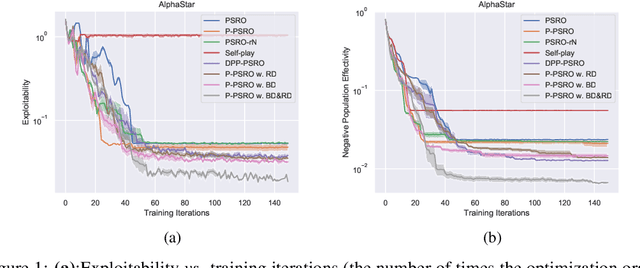
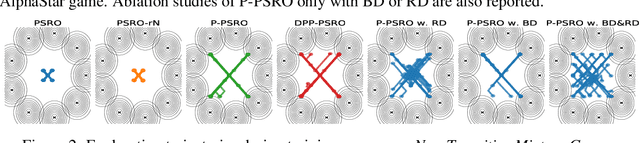
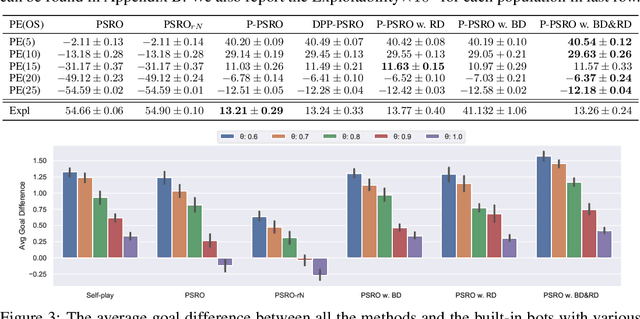
Measuring and promoting policy diversity is critical for solving games with strong non-transitive dynamics where strategic cycles exist, and there is no consistent winner (e.g., Rock-Paper-Scissors). With that in mind, maintaining a pool of diverse policies via open-ended learning is an attractive solution, which can generate auto-curricula to avoid being exploited. However, in conventional open-ended learning algorithms, there are no widely accepted definitions for diversity, making it hard to construct and evaluate the diverse policies. In this work, we summarize previous concepts of diversity and work towards offering a unified measure of diversity in multi-agent open-ended learning to include all elements in Markov games, based on both Behavioral Diversity (BD) and Response Diversity (RD). At the trajectory distribution level, we re-define BD in the state-action space as the discrepancies of occupancy measures. For the reward dynamics, we propose RD to characterize diversity through the responses of policies when encountering different opponents. We also show that many current diversity measures fall in one of the categories of BD or RD but not both. With this unified diversity measure, we design the corresponding diversity-promoting objective and population effectivity when seeking the best responses in open-ended learning. We validate our methods in both relatively simple games like matrix game, non-transitive mixture model, and the complex \textit{Google Research Football} environment. The population found by our methods reveals the lowest exploitability, highest population effectivity in matrix game and non-transitive mixture model, as well as the largest goal difference when interacting with opponents of various levels in \textit{Google Research Football}.
Long Text Generation by Modeling Sentence-Level and Discourse-Level Coherence
May 19, 2021
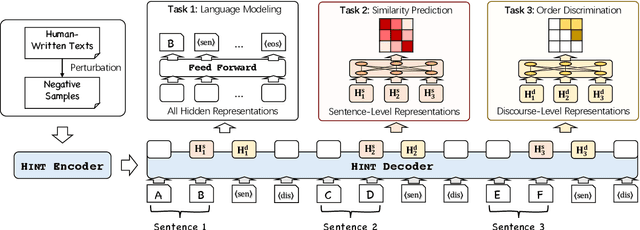
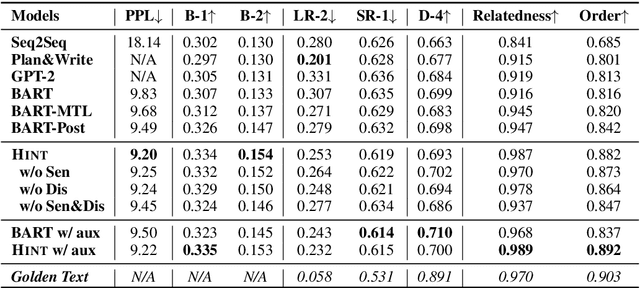
Generating long and coherent text is an important but challenging task, particularly for open-ended language generation tasks such as story generation. Despite the success in modeling intra-sentence coherence, existing generation models (e.g., BART) still struggle to maintain a coherent event sequence throughout the generated text. We conjecture that this is because of the difficulty for the decoder to capture the high-level semantics and discourse structures in the context beyond token-level co-occurrence. In this paper, we propose a long text generation model, which can represent the prefix sentences at sentence level and discourse level in the decoding process. To this end, we propose two pretraining objectives to learn the representations by predicting inter-sentence semantic similarity and distinguishing between normal and shuffled sentence orders. Extensive experiments show that our model can generate more coherent texts than state-of-the-art baselines.
OpenMEVA: A Benchmark for Evaluating Open-ended Story Generation Metrics
May 19, 2021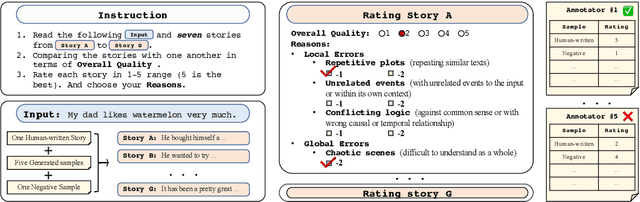
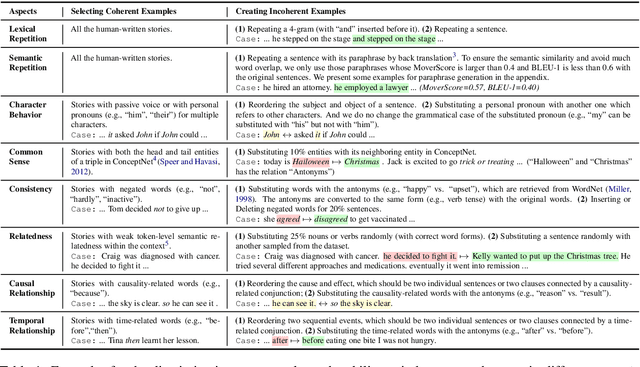
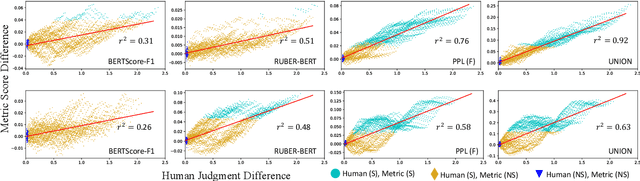
Automatic metrics are essential for developing natural language generation (NLG) models, particularly for open-ended language generation tasks such as story generation. However, existing automatic metrics are observed to correlate poorly with human evaluation. The lack of standardized benchmark datasets makes it difficult to fully evaluate the capabilities of a metric and fairly compare different metrics. Therefore, we propose OpenMEVA, a benchmark for evaluating open-ended story generation metrics. OpenMEVA provides a comprehensive test suite to assess the capabilities of metrics, including (a) the correlation with human judgments, (b) the generalization to different model outputs and datasets, (c) the ability to judge story coherence, and (d) the robustness to perturbations. To this end, OpenMEVA includes both manually annotated stories and auto-constructed test examples. We evaluate existing metrics on OpenMEVA and observe that they have poor correlation with human judgments, fail to recognize discourse-level incoherence, and lack inferential knowledge (e.g., causal order between events), the generalization ability and robustness. Our study presents insights for developing NLG models and metrics in further research.
Write-a-speaker: Text-based Emotional and Rhythmic Talking-head Generation
May 07, 2021
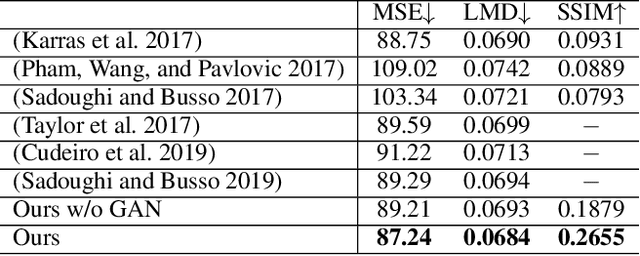
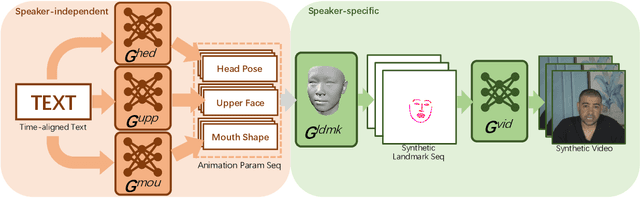
In this paper, we propose a novel text-based talking-head video generation framework that synthesizes high-fidelity facial expressions and head motions in accordance with contextual sentiments as well as speech rhythm and pauses. To be specific, our framework consists of a speaker-independent stage and a speaker-specific stage. In the speaker-independent stage, we design three parallel networks to generate animation parameters of the mouth, upper face, and head from texts, separately. In the speaker-specific stage, we present a 3D face model guided attention network to synthesize videos tailored for different individuals. It takes the animation parameters as input and exploits an attention mask to manipulate facial expression changes for the input individuals. Furthermore, to better establish authentic correspondences between visual motions (i.e., facial expression changes and head movements) and audios, we leverage a high-accuracy motion capture dataset instead of relying on long videos of specific individuals. After attaining the visual and audio correspondences, we can effectively train our network in an end-to-end fashion. Extensive experiments on qualitative and quantitative results demonstrate that our algorithm achieves high-quality photo-realistic talking-head videos including various facial expressions and head motions according to speech rhythms and outperforms the state-of-the-art.
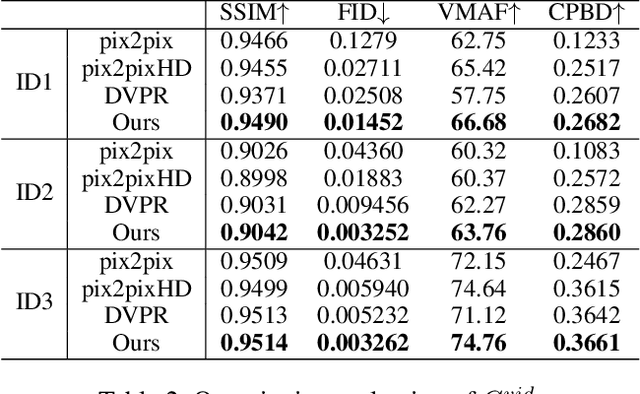
Easy and Efficient Transformer : Scalable Inference Solution For large NLP mode
Apr 26, 2021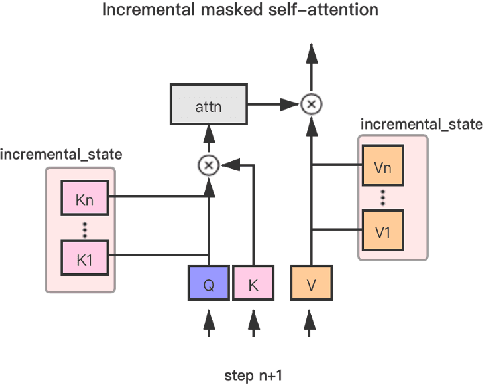
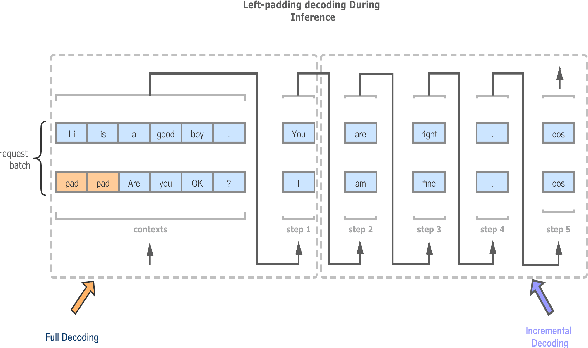

The ultra-large-scale pre-training model can effectively improve the effect of a variety of tasks, and it also brings a heavy computational burden to inference. This paper introduces a series of ultra-large-scale pre-training model optimization methods that combine algorithm characteristics and GPU processor hardware characteristics, and on this basis, propose an inference engine -- Easy and Efficient Transformer (EET), Which has a significant performance improvement over the existing schemes. We firstly introduce a pre-padding decoding mechanism that improves token parallelism for generation tasks. Then we design high optimized kernels to remove sequence masks and achieve cost-free calculation for padding tokens, as well as support long sequence and long embedding sizes. Thirdly a user-friendly inference system with an easy service pipeline was introduced which greatly reduces the difficulty of engineering deployment with high throughput. Compared to Faster Transformer's implementation for GPT-2 on A100, EET achieves a 1.5-15x state-of-art speedup varying with context length.EET is available https://github.com/NetEase-FuXi/EET.