 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurCADRecon: Neural Representation for Reconstructing CAD Surfaces by Enforcing Zero Gaussian Curvature
Apr 20, 2024



Despite recent advances in reconstructing an organic model with the neural signed distance function (SDF), the high-fidelity reconstruction of a CAD model directly from low-quality unoriented point clouds remains a significant challenge. In this paper, we address this challenge based on the prior observation that the surface of a CAD model is generally composed of piecewise surface patches, each approximately developable even around the feature line. Our approach, named NeurCADRecon, is self-supervised, and its loss includes a developability term to encourage the Gaussian curvature toward 0 while ensuring fidelity to the input points. Noticing that the Gaussian curvature is non-zero at tip points, we introduce a double-trough curve to tolerate the existence of these tip points. Furthermore, we develop a dynamic sampling strategy to deal with situations where the given points are incomplete or too sparse. Since our resulting neural SDFs can clearly manifest sharp feature points/lines, one can easily extract the feature-aligned triangle mesh from the SDF and then decompose it into smooth surface patches, greatly reducing the difficulty of recovering the parametric CAD design. A comprehensive comparison with existing state-of-the-art methods shows the significant advantage of our approach in reconstructing faithful CAD shapes.
OAAFormer: Robust and Efficient Point Cloud Registration Through Overlapping-Aware Attention in Transformer
Oct 15, 2023



In the domain of point cloud registration, the coarse-to-fine feature matching paradigm has received substantial attention owing to its impressive performance. This paradigm involves a two-step process: first, the extraction of multi-level features, and subsequently, the propagation of correspondences from coarse to fine levels. Nonetheless, this paradigm exhibits two notable limitations.Firstly, the utilization of the Dual Softmax operation has the potential to promote one-to-one correspondences between superpoints, inadvertently excluding valuable correspondences. This propensity arises from the fact that a source superpoint typically maintains associations with multiple target superpoints. Secondly, it is imperative to closely examine the overlapping areas between point clouds, as only correspondences within these regions decisively determine the actual transformation. Based on these considerations, we propose {\em OAAFormer} to enhance correspondence quality. On one hand, we introduce a soft matching mechanism, facilitating the propagation of potentially valuable correspondences from coarse to fine levels. Additionally, we integrate an overlapping region detection module to minimize mismatches to the greatest extent possible. Furthermore, we introduce a region-wise attention module with linear complexity during the fine-level matching phase, designed to enhance the discriminative capabilities of the extracted features. Tests on the challenging 3DLoMatch benchmark demonstrate that our approach leads to a substantial increase of about 7\% in the inlier ratio, as well as an enhancement of 2-4\% in registration recall. =
For A More Comprehensive Evaluation of 6DoF Object Pose Tracking
Sep 15, 2023



Previous evaluations on 6DoF object pose tracking have presented obvious limitations along with the development of this area. In particular, the evaluation protocols are not unified for different methods, the widely-used YCBV dataset contains significant annotation error, and the error metrics also may be biased. As a result, it is hard to fairly compare the methods, which has became a big obstacle for developing new algorithms. In this paper we contribute a unified benchmark to address the above problems. For more accurate annotation of YCBV, we propose a multi-view multi-object global pose refinement method, which can jointly refine the poses of all objects and view cameras, resulting in sub-pixel sub-millimeter alignment errors. The limitations of previous scoring methods and error metrics are analyzed, based on which we introduce our improved evaluation methods. The unified benchmark takes both YCBV and BCOT as base datasets, which are shown to be complementary in scene categories. In experiments, we validate the precision and reliability of the proposed global pose refinement method with a realistic semi-synthesized dataset particularly for YCBV, and then present the benchmark results unifying learning&non-learning and RGB&RGBD methods, with some finds not discovered in previous studies.
Neural-Singular-Hessian: Implicit Neural Representation of Unoriented Point Clouds by Enforcing Singular Hessian
Sep 06, 2023Neural implicit representation is a promising approach for reconstructing surfaces from point clouds. Existing methods combine various regularization terms, such as the Eikonal and Laplacian energy terms, to enforce the learned neural function to possess the properties of a Signed Distance Function (SDF). However, inferring the actual topology and geometry of the underlying surface from poor-quality unoriented point clouds remains challenging. In accordance with Differential Geometry, the Hessian of the SDF is singular for points within the differential thin-shell space surrounding the surface. Our approach enforces the Hessian of the neural implicit function to have a zero determinant for points near the surface. This technique aligns the gradients for a near-surface point and its on-surface projection point, producing a rough but faithful shape within just a few iterations. By annealing the weight of the singular-Hessian term, our approach ultimately produces a high-fidelity reconstruction result. Extensive experimental results demonstrate that our approach effectively suppresses ghost geometry and recovers details from unoriented point clouds with better expressiveness than existing fitting-based methods.
Guided Linear Upsampling
Jul 13, 2023



Guided upsampling is an effective approach for accelerating high-resolution image processing. In this paper, we propose a simple yet effective guided upsampling method. Each pixel in the high-resolution image is represented as a linear interpolation of two low-resolution pixels, whose indices and weights are optimized to minimize the upsampling error. The downsampling can be jointly optimized in order to prevent missing small isolated regions. Our method can be derived from the color line model and local color transformations. Compared to previous methods, our method can better preserve detail effects while suppressing artifacts such as bleeding and blurring. It is efficient, easy to implement, and free of sensitive parameters. We evaluate the proposed method with a wide range of image operators, and show its advantages through quantitative and qualitative analysis. We demonstrate the advantages of our method for both interactive image editing and real-time high-resolution video processing. In particular, for interactive editing, the joint optimization can be precomputed, thus allowing for instant feedback without hardware acceleration.
Mesh-MLP: An all-MLP Architecture for Mesh Classification and Semantic Segmentation
Jun 08, 2023



With the rapid development of geometric deep learning techniques, many mesh-based convolutional operators have been proposed to bridge irregular mesh structures and popular backbone networks. In this paper, we show that while convolutions are helpful, a simple architecture based exclusively on multi-layer perceptrons (MLPs) is competent enough to deal with mesh classification and semantic segmentation. Our new network architecture, named Mesh-MLP, takes mesh vertices equipped with the heat kernel signature (HKS) and dihedral angles as the input, replaces the convolution module of a ResNet with Multi-layer Perceptron (MLP), and utilizes layer normalization (LN) to perform the normalization of the layers. The all-MLP architecture operates in an end-to-end fashion and does not include a pooling module. Extensive experimental results on the mesh classification/segmentation tasks validate the effectiveness of the all-MLP architecture.
Neural-IMLS: Learning Implicit Moving Least-Squares for Surface Reconstruction from Unoriented Point clouds
Sep 09, 2021
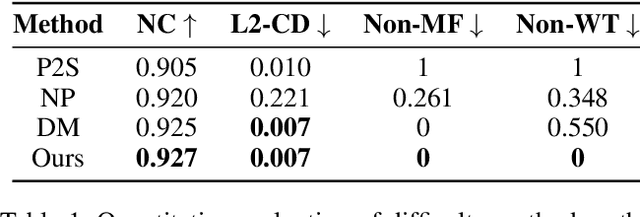

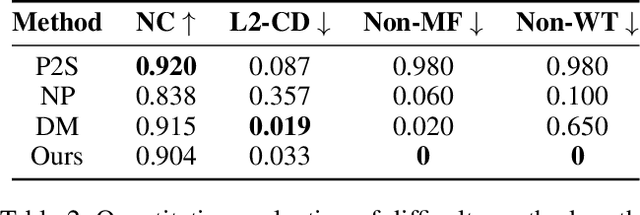
Surface reconstruction from noisy, non-uniformly, and unoriented point clouds is a fascinating yet difficult problem in computer vision and computer graphics. In this paper, we propose Neural-IMLS, a novel approach that learning noise-resistant signed distance function (SDF) for reconstruction. Instead of explicitly learning priors with the ground-truth signed distance values, our method learns the SDF from raw point clouds directly in a self-supervised fashion by minimizing the loss between the couple of SDFs, one obtained by the implicit moving least-square function (IMLS) and the other by our network. Finally, a watertight and smooth 2-manifold triangle mesh is yielded by running Marching Cubes. We conduct extensive experiments on various benchmarks to demonstrate the performance of Neural-IMLS, especially for point clouds with noise.
ShapeConv: Shape-aware Convolutional Layer for Indoor RGB-D Semantic Segmentation
Aug 24, 2021
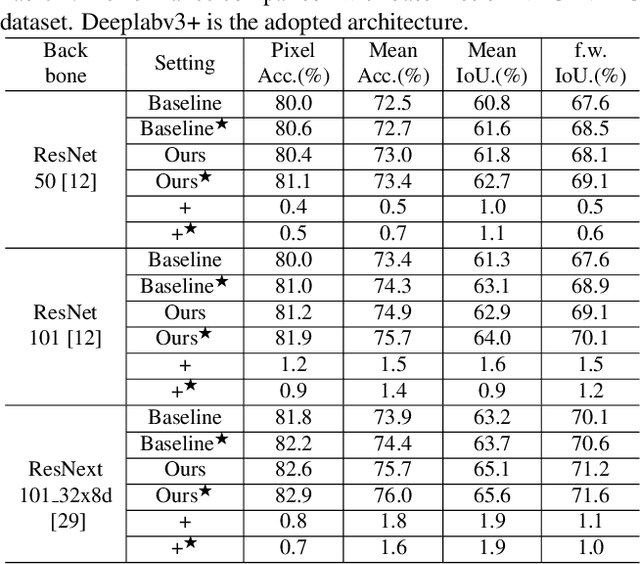
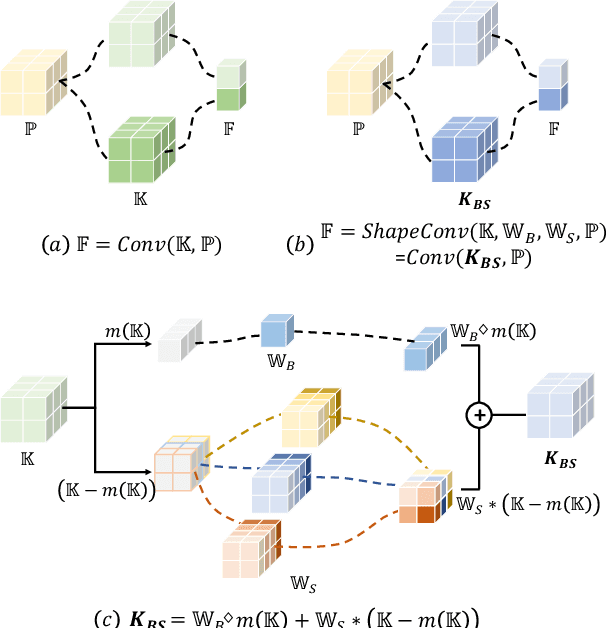
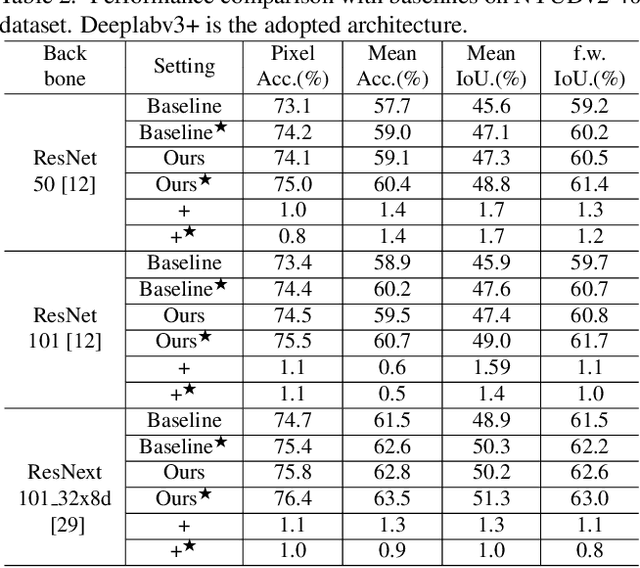
RGB-D semantic segmentation has attracted increasing attention over the past few years. Existing methods mostly employ homogeneous convolution operators to consume the RGB and depth features, ignoring their intrinsic differences. In fact, the RGB values capture the photometric appearance properties in the projected image space, while the depth feature encodes both the shape of a local geometry as well as the base (whereabout) of it in a larger context. Compared with the base, the shape probably is more inherent and has a stronger connection to the semantics, and thus is more critical for segmentation accuracy. Inspired by this observation, we introduce a Shape-aware Convolutional layer (ShapeConv) for processing the depth feature, where the depth feature is firstly decomposed into a shape-component and a base-component, next two learnable weights are introduced to cooperate with them independently, and finally a convolution is applied on the re-weighted combination of these two components. ShapeConv is model-agnostic and can be easily integrated into most CNNs to replace vanilla convolutional layers for semantic segmentation. Extensive experiments on three challenging indoor RGB-D semantic segmentation benchmarks, i.e., NYU-Dv2(-13,-40), SUN RGB-D, and SID, demonstrate the effectiveness of our ShapeConv when employing it over five popular architectures. Moreover, the performance of CNNs with ShapeConv is boosted without introducing any computation and memory increase in the inference phase. The reason is that the learnt weights for balancing the importance between the shape and base components in ShapeConv become constants in the inference phase, and thus can be fused into the following convolution, resulting in a network that is identical to one with vanilla convolutional layers.
Planning of Power Grasps Using Infinite Program Under Complementary Constraints
Jul 31, 2021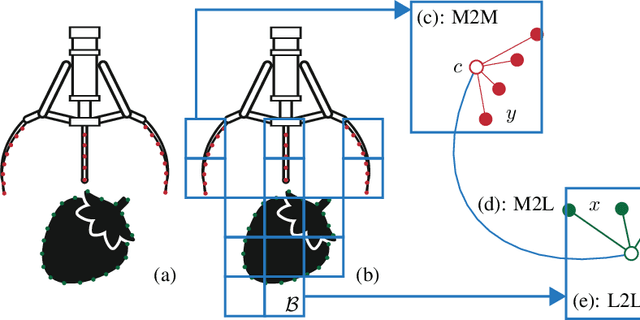

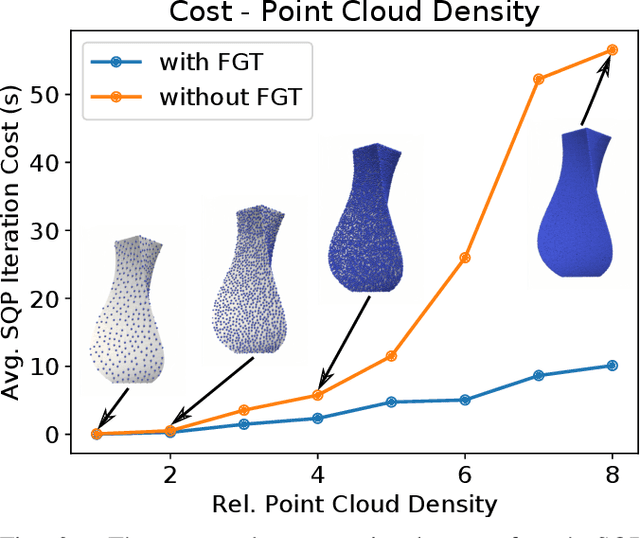
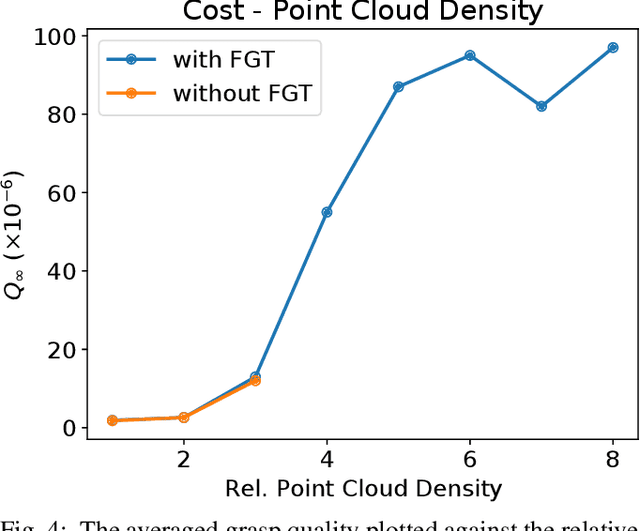
We propose an optimization-based approach to plan power grasps. Central to our method is a reformulation of grasp planning as an infinite program under complementary constraints (IPCC), which allows contacts to happen between arbitrary pairs of points on the object and the robot gripper. We show that IPCC can be reduced to a conventional finite-dimensional nonlinear program (NLP) using a kernel-integral relaxation. Moreover, the values and Jacobian matrices of the kernel-integral can be evaluated efficiently using a modified Fast Multipole Method (FMM). We further guarantee that the planned grasps are collision-free using primal barrier penalties. We demonstrate the effectiveness, robustness, and efficiency of our grasp planner on a row of challenging 3D objects and high-DOF grippers, such as Barrett Hand and Shadow Hand, where our method achieves superior grasp qualities over competitors.
Scribble-Supervised Semantic Segmentation by Uncertainty Reduction on Neural Representation and Self-Supervision on Neural Eigenspace
Feb 19, 2021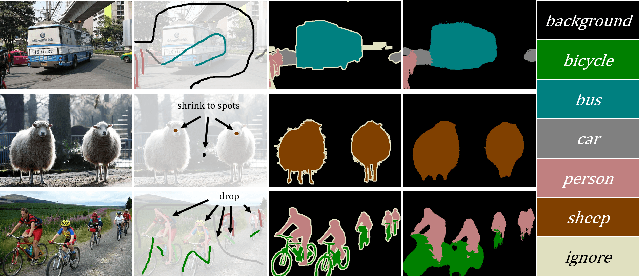
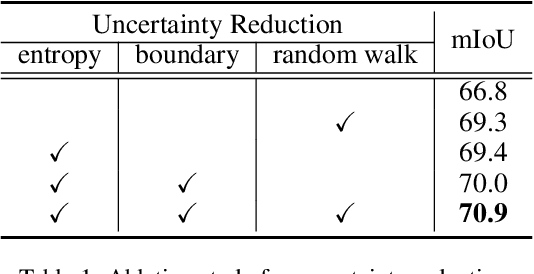
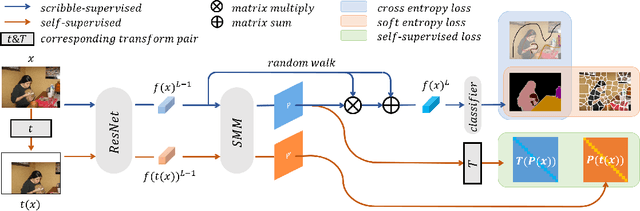
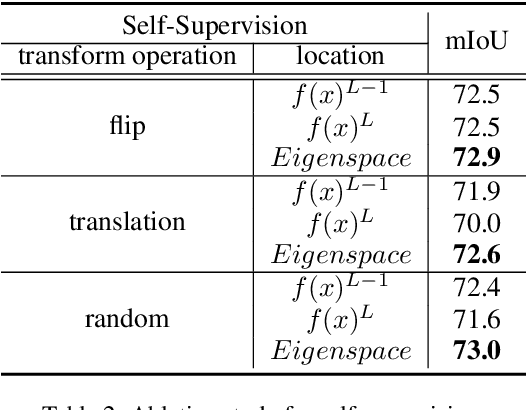
Scribble-supervised semantic segmentation has gained much attention recently for its promising performance without high-quality annotations. Due to the lack of supervision, confident and consistent predictions are usually hard to obtain. Typically, people handle these problems to either adopt an auxiliary task with the well-labeled dataset or incorporate the graphical model with additional requirements on scribble annotations. Instead, this work aims to achieve semantic segmentation by scribble annotations directly without extra information and other limitations. Specifically, we propose holistic operations, including minimizing entropy and a network embedded random walk on neural representation to reduce uncertainty. Given the probabilistic transition matrix of a random walk, we further train the network with self-supervision on its neural eigenspace to impose consistency on predictions between related images. Comprehensive experiments and ablation studies verify the proposed approach, which demonstrates superiority over others; it is even comparable to some full-label supervised ones and works well when scribbles are randomly shrunk or dropped.