 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeFormer: Transformer-based Shape Completion via Sparse Representation
Jan 25, 2022
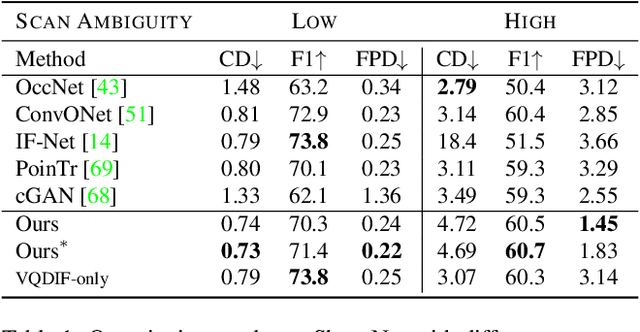
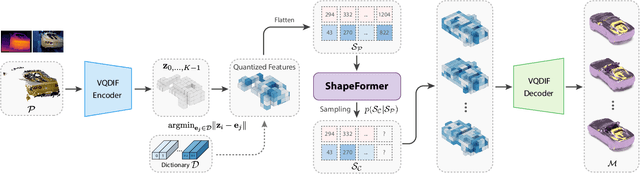
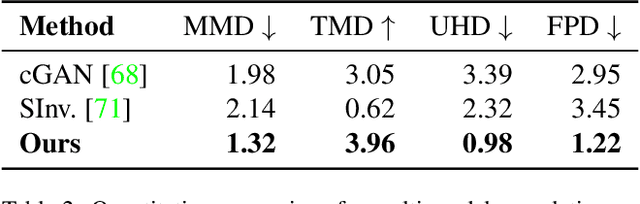
We present ShapeFormer, a transformer-based network that produces a distribution of object completions, conditioned on incomplete, and possibly noisy, point clouds. The resultant distribution can then be sampled to generate likely completions, each exhibiting plausible shape details while being faithful to the input. To facilitate the use of transformers for 3D, we introduce a compact 3D representation, vector quantized deep implicit function, that utilizes spatial sparsity to represent a close approximation of a 3D shape by a short sequence of discrete variables. Experiments demonstrate that ShapeFormer outperforms prior art for shape completion from ambiguous partial inputs in terms of both completion quality and diversity. We also show that our approach effectively handles a variety of shape types, incomplete patterns, and real-world scans.
ShapeConv: Shape-aware Convolutional Layer for Indoor RGB-D Semantic Segmentation
Aug 24, 2021
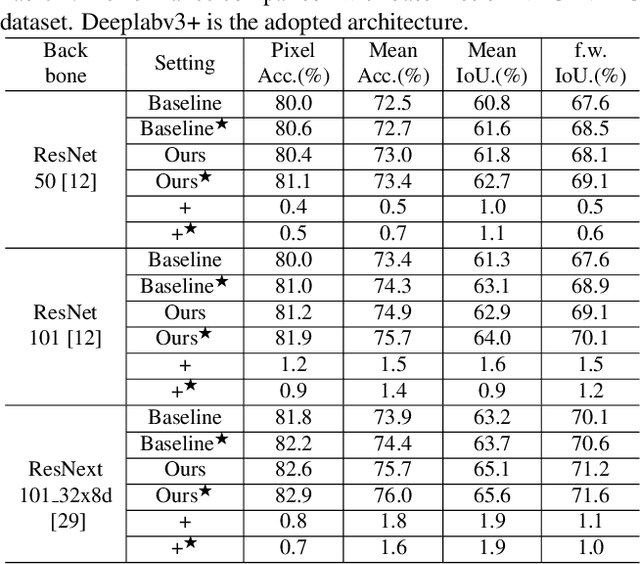
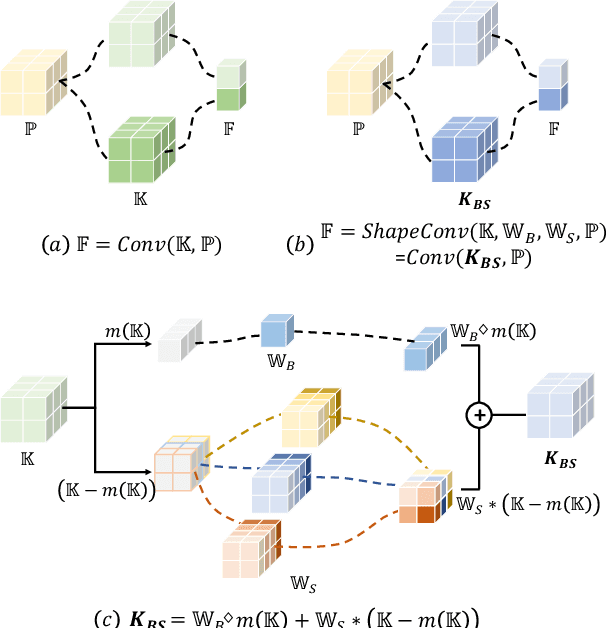
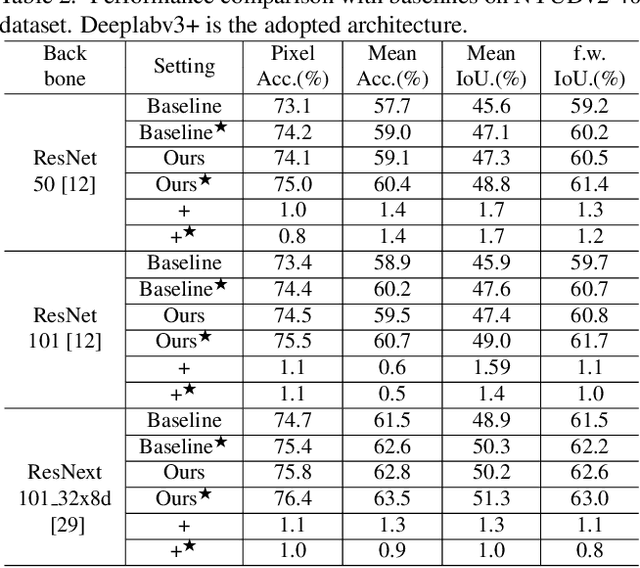
RGB-D semantic segmentation has attracted increasing attention over the past few years. Existing methods mostly employ homogeneous convolution operators to consume the RGB and depth features, ignoring their intrinsic differences. In fact, the RGB values capture the photometric appearance properties in the projected image space, while the depth feature encodes both the shape of a local geometry as well as the base (whereabout) of it in a larger context. Compared with the base, the shape probably is more inherent and has a stronger connection to the semantics, and thus is more critical for segmentation accuracy. Inspired by this observation, we introduce a Shape-aware Convolutional layer (ShapeConv) for processing the depth feature, where the depth feature is firstly decomposed into a shape-component and a base-component, next two learnable weights are introduced to cooperate with them independently, and finally a convolution is applied on the re-weighted combination of these two components. ShapeConv is model-agnostic and can be easily integrated into most CNNs to replace vanilla convolutional layers for semantic segmentation. Extensive experiments on three challenging indoor RGB-D semantic segmentation benchmarks, i.e., NYU-Dv2(-13,-40), SUN RGB-D, and SID, demonstrate the effectiveness of our ShapeConv when employing it over five popular architectures. Moreover, the performance of CNNs with ShapeConv is boosted without introducing any computation and memory increase in the inference phase. The reason is that the learnt weights for balancing the importance between the shape and base components in ShapeConv become constants in the inference phase, and thus can be fused into the following convolution, resulting in a network that is identical to one with vanilla convolutional layers.
Hausdorff Point Convolution with Geometric Priors
Dec 24, 2020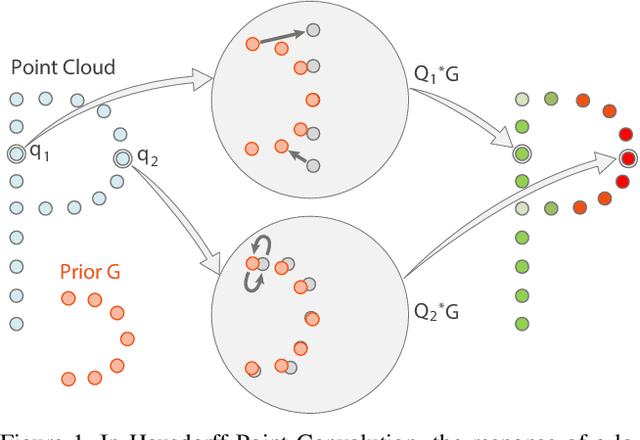
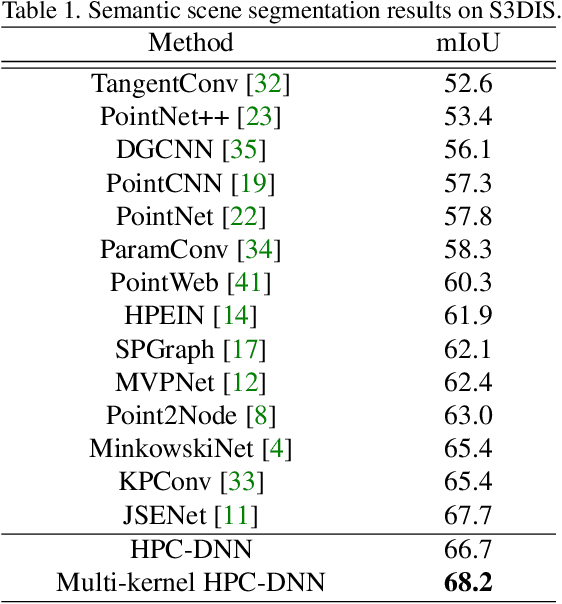
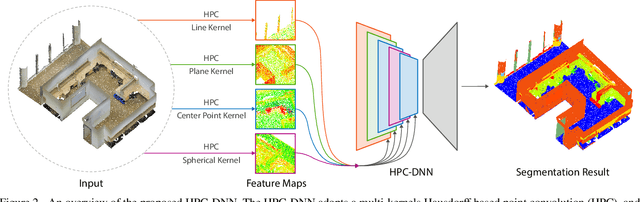
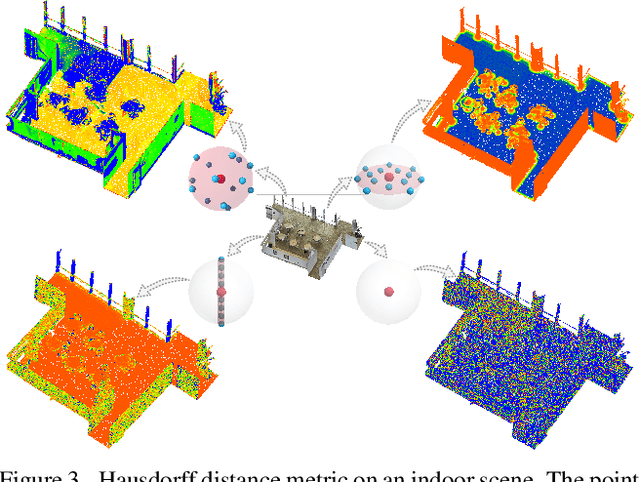
Without a shape-aware response, it is hard to characterize the 3D geometry of a point cloud efficiently with a compact set of kernels. In this paper, we advocate the use of Hausdorff distance as a shape-aware distance measure for calculating point convolutional responses. The technique we present, coined Hausdorff Point Convolution (HPC), is shape-aware. We show that HPC constitutes a powerful point feature learning with a rather compact set of only four types of geometric priors as kernels. We further develop a HPC-based deep neural network (HPC-DNN). Task-specific learning can be achieved by tuning the network weights for combining the shortest distances between input and kernel point sets. We also realize hierarchical feature learning by designing a multi-kernel HPC for multi-scale feature encoding. Extensive experiments demonstrate that HPC-DNN outperforms strong point convolution baselines (e.g., KPConv), achieving 2.8% mIoU performance boost on S3DIS and 1.5% on SemanticKITTI for semantic segmentation task.
Specular-to-Diffuse Translation for Multi-View Reconstruction
Jul 30, 2018
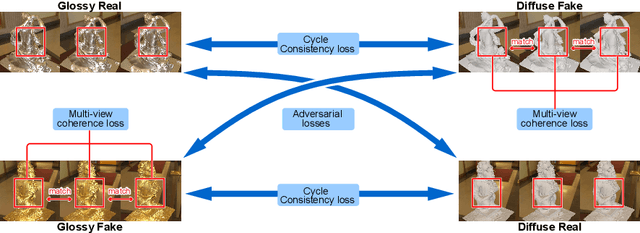


Most multi-view 3D reconstruction algorithms, especially when shape-from-shading cues are used, assume that object appearance is predominantly diffuse. To alleviate this restriction, we introduce S2Dnet, a generative adversarial network for transferring multiple views of objects with specular reflection into diffuse ones, so that multi-view reconstruction methods can be applied more effectively. Our network extends unsupervised image-to-image translation to multi-view "specular to diffuse" translation. To preserve object appearance across multiple views, we introduce a Multi-View Coherence loss (MVC) that evaluates the similarity and faithfulness of local patches after the view-transformation. Our MVC loss ensures that the similarity of local correspondences among multi-view images is preserved under the image-to-image translation. As a result, our network yields significantly better results than several single-view baseline techniques. In addition, we carefully design and generate a large synthetic training data set using physically-based rendering. During testing, our network takes only the raw glossy images as input, without extra information such as segmentation masks or lighting estimation. Results demonstrate that multi-view reconstruction can be significantly improved using the images filtered by our network. We also show promising performance on real world training and testing data.
DiDA: Disentangled Synthesis for Domain Adaptation
May 21, 2018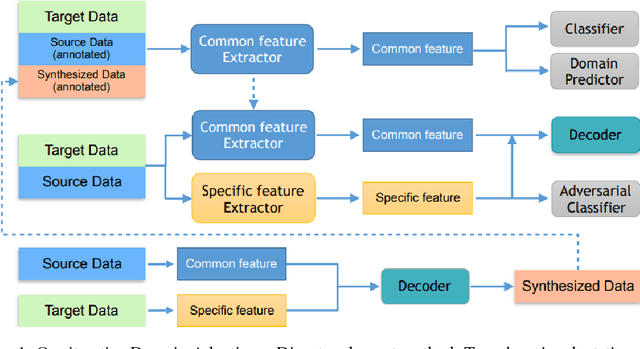



Unsupervised domain adaptation aims at learning a shared model for two related, but not identical, domains by leveraging supervision from a source domain to an unsupervised target domain. A number of effective domain adaptation approaches rely on the ability to extract discriminative, yet domain-invariant, latent factors which are common to both domains. Extracting latent commonality is also useful for disentanglement analysis, enabling separation between the common and the domain-specific features of both domains. In this paper, we present a method for boosting domain adaptation performance by leveraging disentanglement analysis. The key idea is that by learning to separately extract both the common and the domain-specific features, one can synthesize more target domain data with supervision, thereby boosting the domain adaptation performance. Better common feature extraction, in turn, helps further improve the disentanglement analysis and disentangled synthesis. We show that iterating between domain adaptation and disentanglement analysis can consistently improve each other on several unsupervised domain adaptation tasks, for various domain adaptation backbone models.