 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2-Net: Joint Description and Detection of Local Features for Pixel and Point Matching
Mar 01, 2021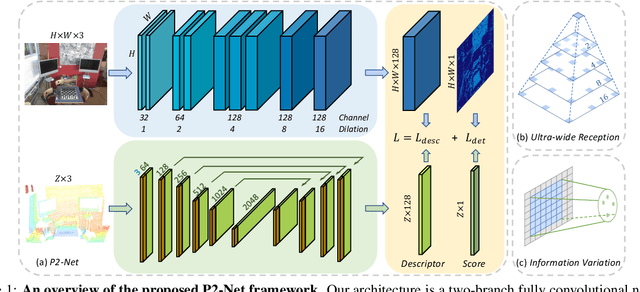
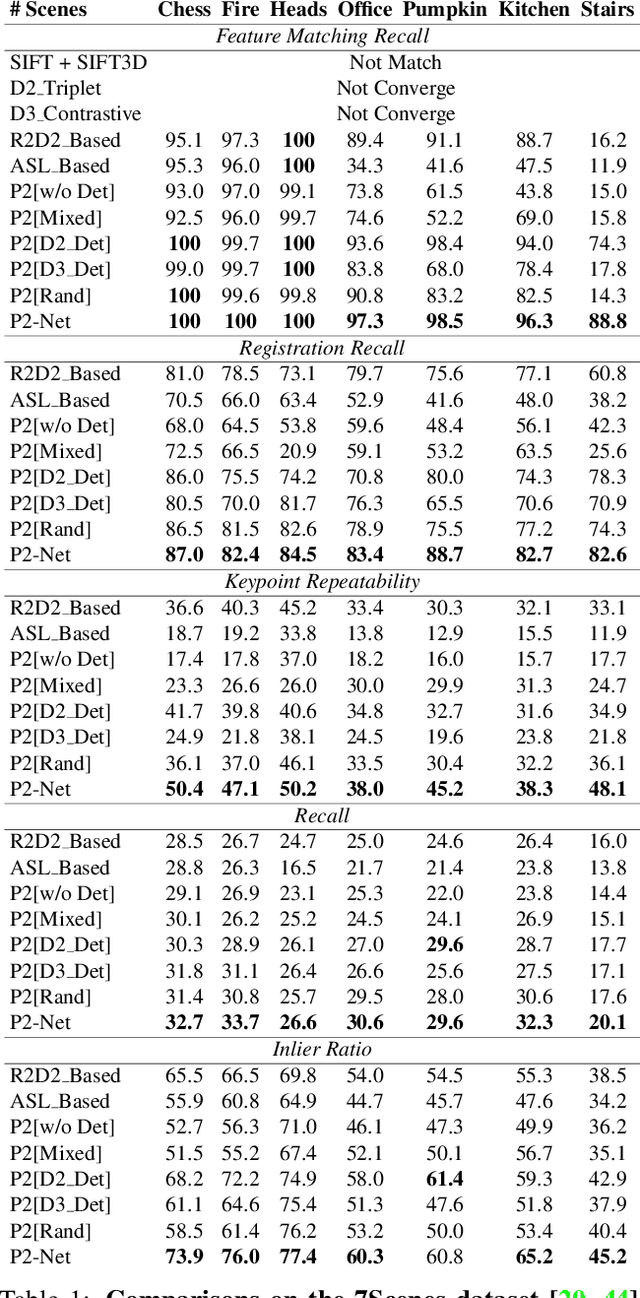
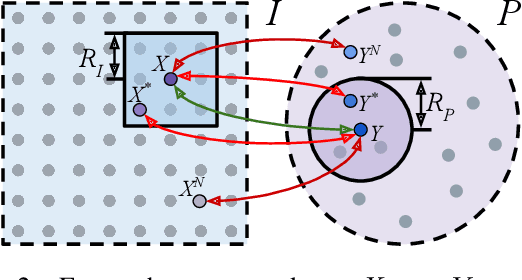
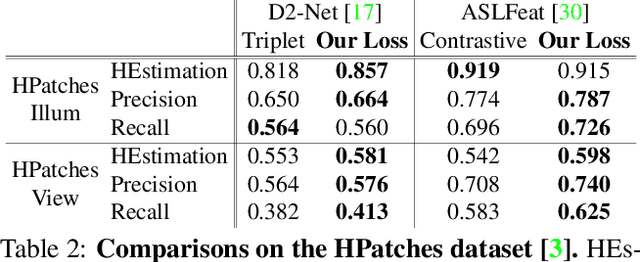
Accurately describing and detecting 2D and 3D keypoints is crucial to establishing correspondences across images and point clouds. Despite a plethora of learning-based 2D or 3D local feature descriptors and detectors having been proposed, the derivation of a shared descriptor and joint keypoint detector that directly matches pixels and points remains under-explored by the community. This work takes the initiative to establish fine-grained correspondences between 2D images and 3D point clouds. In order to directly match pixels and points, a dual fully convolutional framework is presented that maps 2D and 3D inputs into a shared latent representation space to simultaneously describe and detect keypoints. Furthermore, an ultra-wide reception mechanism in combination with a novel loss function are designed to mitigate the intrinsic information variations between pixel and point local regions. Extensive experimental results demonstrate that our framework shows competitive performance in fine-grained matching between images and point clouds and achieves state-of-the-art results for the task of indoor visual localization. Our source code will be available at [no-name-for-blind-review].
A Survey on Deep Learning for Localization and Mapping: Towards the Age of Spatial Machine Intelligence
Jun 29, 2020
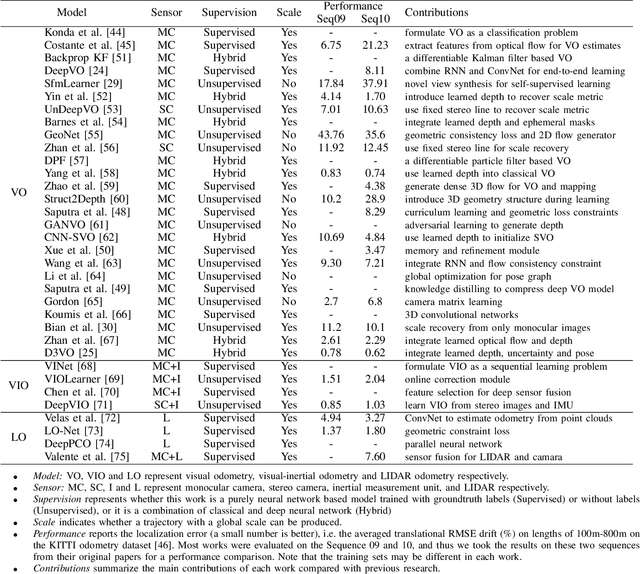
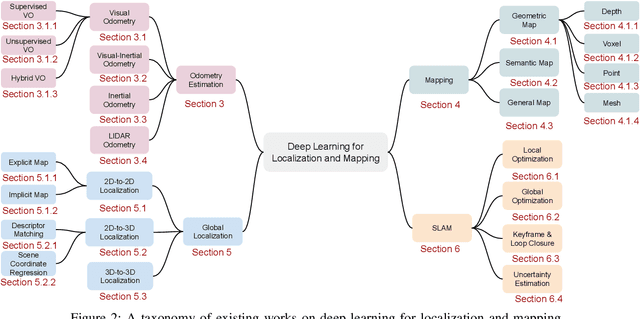

Deep learning based localization and mapping has recently attracted significant attention. Instead of creating hand-designed algorithms through exploitation of physical models or geometric theories, deep learning based solutions provide an alternative to solve the problem in a data-driven way. Benefiting from ever-increasing volumes of data and computational power, these methods are fast evolving into a new area that offers accurate and robust systems to track motion and estimate scenes and their structure for real-world applications. In this work, we provide a comprehensive survey, and propose a new taxonomy for localization and mapping using deep learning. We also discuss the limitations of current models, and indicate possible future directions. A wide range of topics are covered, from learning odometry estimation, mapping, to global localization and simultaneous localization and mapping (SLAM). We revisit the problem of perceiving self-motion and scene understanding with on-board sensors, and show how to solve it by integrating these modules into a prospective spatial machine intelligence system (SMIS). It is our hope that this work can connect emerging works from robotics, computer vision and machine learning communities, and serve as a guide for future researchers to apply deep learning to tackle localization and mapping problems.
milliEgo: mmWave Aided Egomotion Estimation with Deep Sensor Fusion
Jun 03, 2020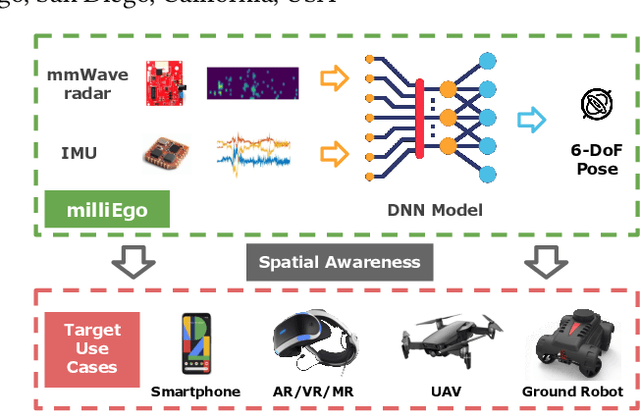
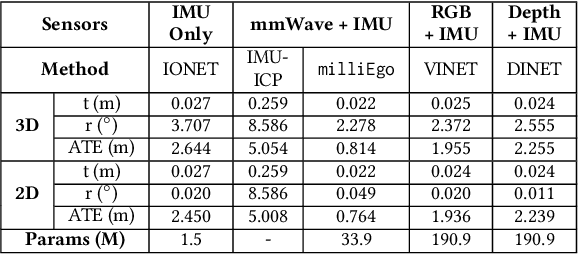
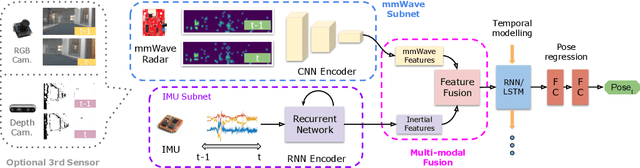
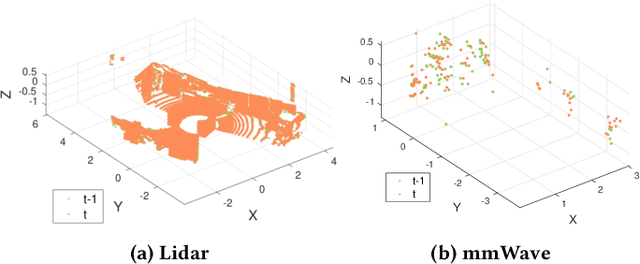
Robust and accurate trajectory estimation of mobile agents such as people and robots is a key requirement for providing spatial awareness to emerging capabilities such as augmented reality or autonomous interaction. Although currently dominated by vision based techniques e.g., visual-inertial odometry, these suffer from challenges with scene illumination or featureless surfaces. As an alternative, we propose \sysname, a novel deep-learning approach to robust egomotion estimation which exploits the capabilities of low-cost mmWave radar. Although mmWave radar has a fundamental advantage over monocular cameras of being metric i.e., providing absolute scale or depth, current single chip solutions have limited and sparse imaging resolution, making existing point-cloud registration techniques brittle. We propose a new architecture that is optimized for solving this underdetermined pose transformation problem. Secondly, to robustly fuse mmWave pose estimates with additional sensors, e.g. inertial or visual sensor we introduce a mixed attention approach to deep fusion. Through extensive experiments, we demonstrate how mmWave radar outperforms existing state-of-the-art odometry techniques. We also show that the neural architecture can be made highly efficient and suitable for real-time embedded applications.
MVLoc: Multimodal Variational Geometry-Aware Learning for Visual Localization
Mar 12, 2020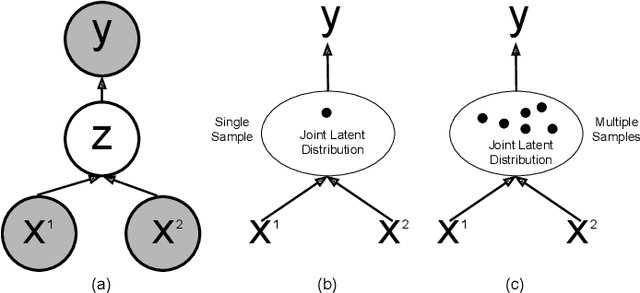
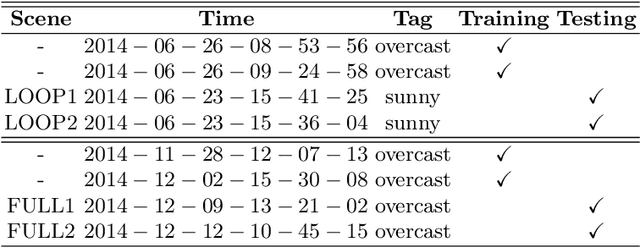
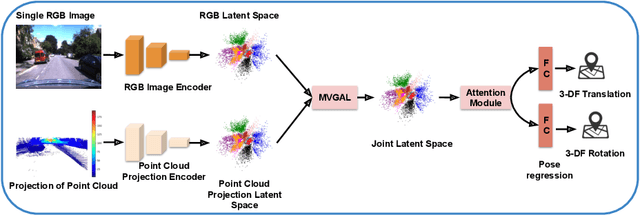
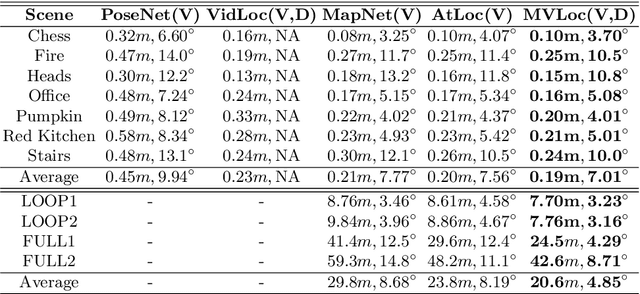
Recent learning-based research has achieved impressive results in the field of single-shot camera relocalization. However, how best to fuse multiple modalities, for example, image and depth, and how to deal with degraded or missing input are less well studied. In particular, we note that previous approaches towards deep fusion do not perform significantly better than models employing a single modality. We conjecture that this is because of the naive approaches to feature space fusion through summation or concatenation which do not take into account the different strengths of each modality, specifically appearance for images and structure for depth. To address this, we propose an end-to-end framework to fuse different sensor inputs through a variational Product-of-Experts (PoE) joint encoder followed by attention-based fusion. Unlike prior work which draws a single sample from the joint encoder, we show how accuracy can be increased through importance sampling and reparameterization of the latent space. Our model is extensively evaluated on RGB-D datasets, outperforming existing baselines by a large margin.
PointLoc: Deep Pose Regressor for LiDAR Point Cloud Localization
Mar 05, 2020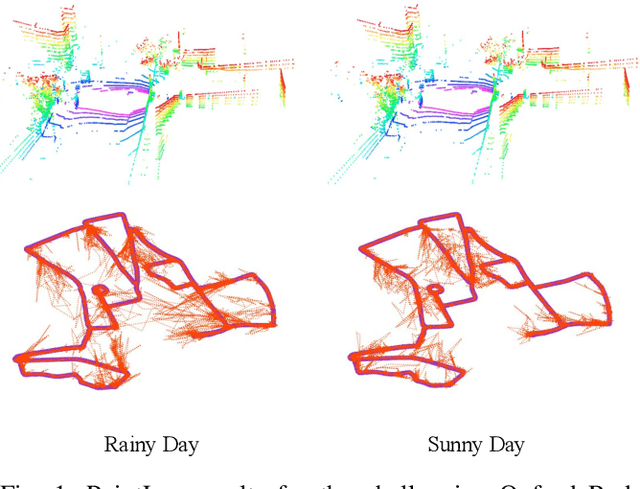
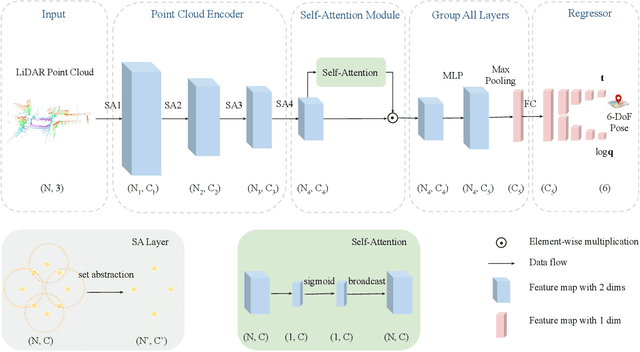
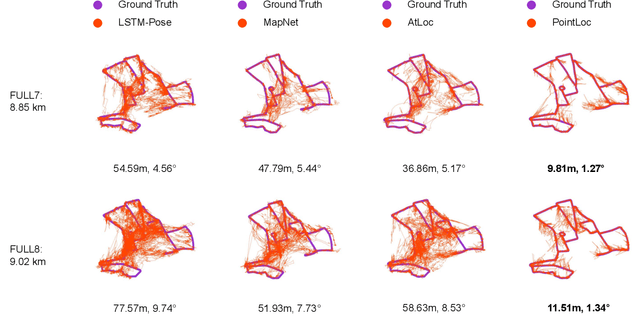
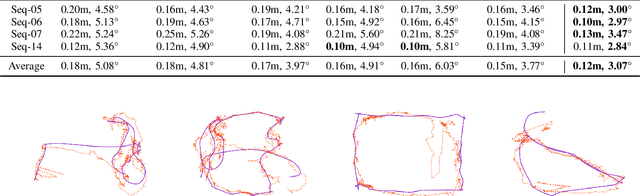
In this paper, we present a novel end-to-end learning-based LiDAR relocalization framework, termed PointLoc, which infers 6-DoF poses directly using only a single point cloud as input, without requiring a pre-built map. Compared to RGB image-based relocalization, LiDAR frames can provide rich and robust geometric information about a scene. However, LiDAR point clouds are sparse and unstructured making it difficult to apply traditional deep learning regression models for this task. We address this issue by proposing a novel PointNet-style architecture with self-attention to efficiently estimate 6-DoF poses from 360{\deg} LiDAR input frames. Extensive experiments on recently released challenging Oxford Radar RobotCar dataset and real-world robot experiments demonstrate that the proposed method can achieve accurate relocalization performance. We show that our approach improves the state-of-the-art MapNet by 69.59% in translation and 75.70% in rotation, and AtLoc by 66.86% in translation and 78.83% in rotation on the challenging outdoor large-scale Oxford Radar RobotCar dataset.
Deep Learning based Pedestrian Inertial Navigation: Methods, Dataset and On-Device Inference
Jan 13, 2020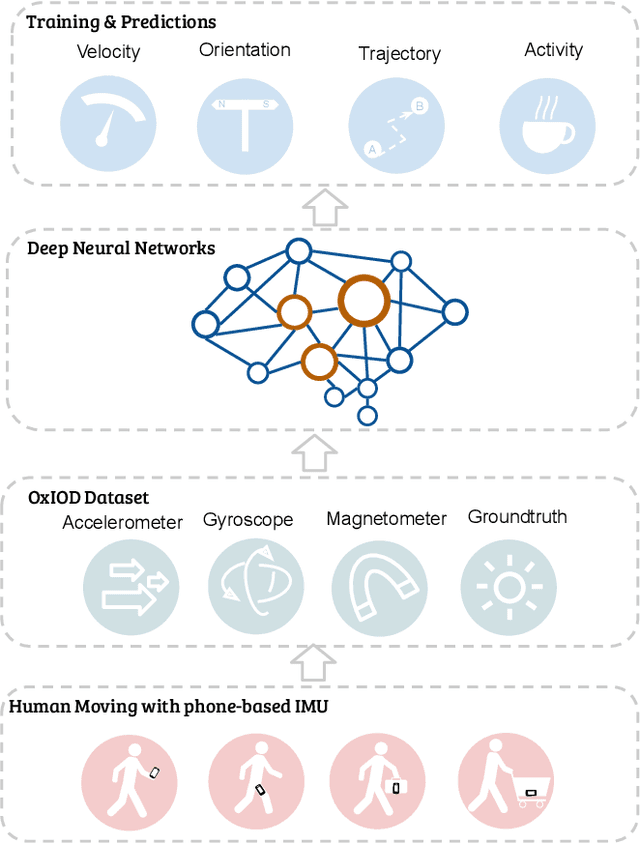
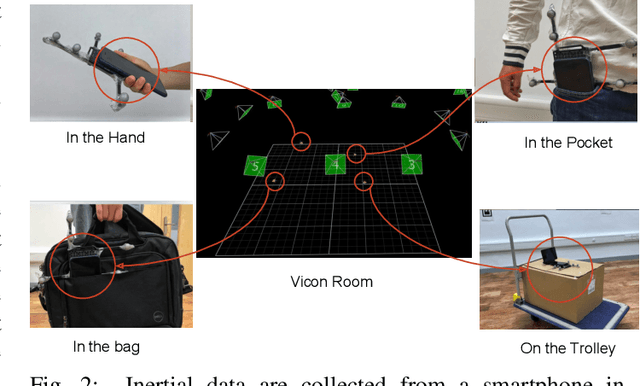
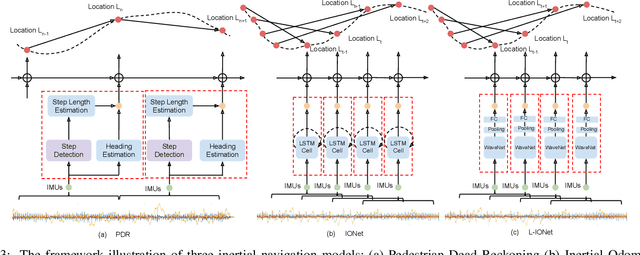
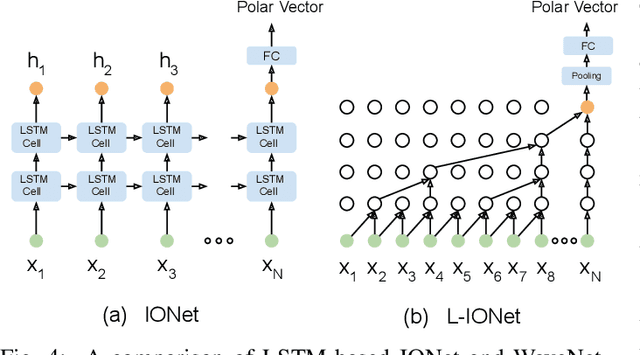
Modern inertial measurements units (IMUs) are small, cheap, energy efficient, and widely employed in smart devices and mobile robots. Exploiting inertial data for accurate and reliable pedestrian navigation supports is a key component for emerging Internet-of-Things applications and services. Recently, there has been a growing interest in applying deep neural networks (DNNs) to motion sensing and location estimation. However, the lack of sufficient labelled data for training and evaluating architecture benchmarks has limited the adoption of DNNs in IMU-based tasks. In this paper, we present and release the Oxford Inertial Odometry Dataset (OxIOD), a first-of-its-kind public dataset for deep learning based inertial navigation research, with fine-grained ground-truth on all sequences. Furthermore, to enable more efficient inference at the edge, we propose a novel lightweight framework to learn and reconstruct pedestrian trajectories from raw IMU data. Extensive experiments show the effectiveness of our dataset and methods in achieving accurate data-driven pedestrian inertial navigation on resource-constrained devices.
SelectFusion: A Generic Framework to Selectively Learn Multisensory Fusion
Dec 30, 2019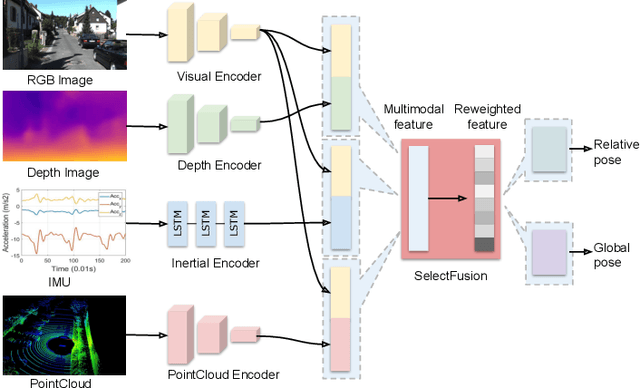

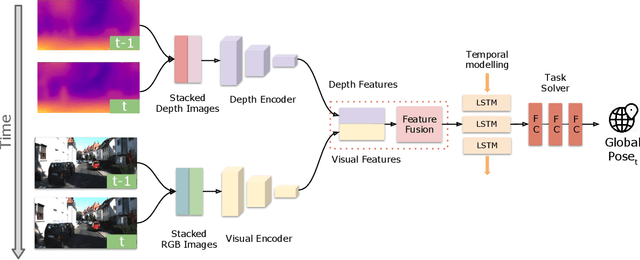
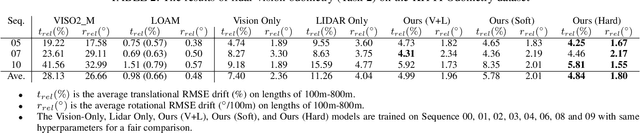
Autonomous vehicles and mobile robotic systems are typically equipped with multiple sensors to provide redundancy. By integrating the observations from different sensors, these mobile agents are able to perceive the environment and estimate system states, e.g. locations and orientations. Although deep learning approaches for multimodal odometry estimation and localization have gained traction, they rarely focus on the issue of robust sensor fusion - a necessary consideration to deal with noisy or incomplete sensor observations in the real world. Moreover, current deep odometry models also suffer from a lack of interpretability. To this extent, we propose SelectFusion, an end-to-end selective sensor fusion module which can be applied to useful pairs of sensor modalities such as monocular images and inertial measurements, depth images and LIDAR point clouds. During prediction, the network is able to assess the reliability of the latent features from different sensor modalities and estimate both trajectory at scale and global pose. In particular, we propose two fusion modules based on different attention strategies: deterministic soft fusion and stochastic hard fusion, and we offer a comprehensive study of the new strategies compared to trivial direct fusion. We evaluate all fusion strategies in both ideal conditions and on progressively degraded datasets that present occlusions, noisy and missing data and time misalignment between sensors, and we investigate the effectiveness of the different fusion strategies in attending the most reliable features, which in itself, provides insights into the operation of the various models.
DeepPCO: End-to-End Point Cloud Odometry through Deep Parallel Neural Network
Oct 13, 2019
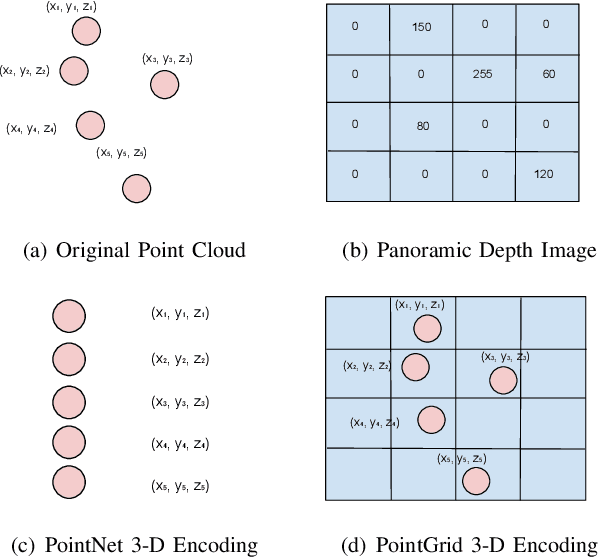
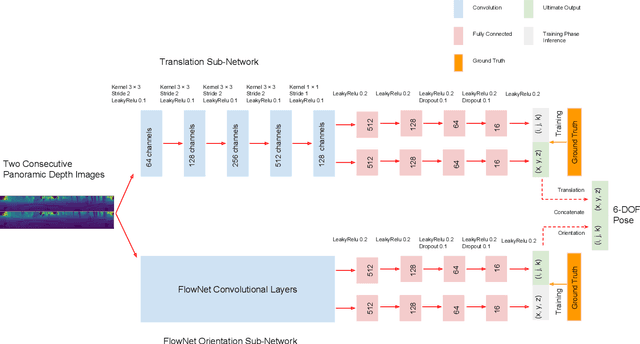
Odometry is of key importance for localization in the absence of a map. There is considerable work in the area of visual odometry (VO), and recent advances in deep learning have brought novel approaches to VO, which directly learn salient features from raw images. These learning-based approaches have led to more accurate and robust VO systems. However, they have not been well applied to point cloud data yet. In this work, we investigate how to exploit deep learning to estimate point cloud odometry (PCO), which may serve as a critical component in point cloud-based downstream tasks or learning-based systems. Specifically, we propose a novel end-to-end deep parallel neural network called DeepPCO, which can estimate the 6-DOF poses using consecutive point clouds. It consists of two parallel sub-networks to estimate 3-D translation and orientation respectively rather than a single neural network. We validate our approach on KITTI Visual Odometry/SLAM benchmark dataset with different baselines. Experiments demonstrate that the proposed approach achieves good performance in terms of pose accuracy.
DeepTIO: A Deep Thermal-Inertial Odometry with Visual Hallucination
Sep 16, 2019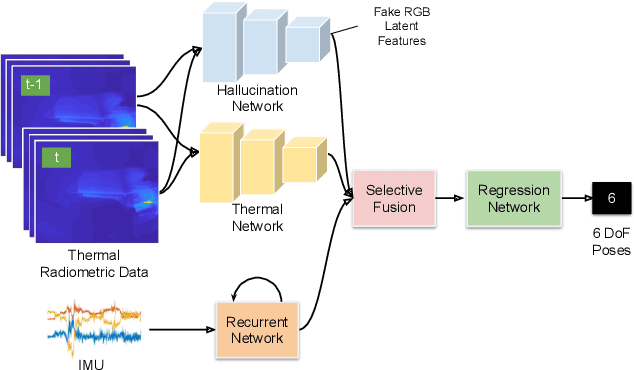
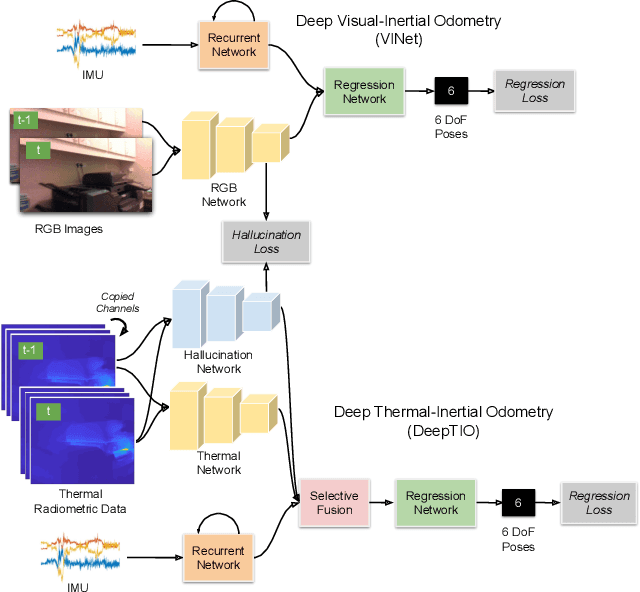
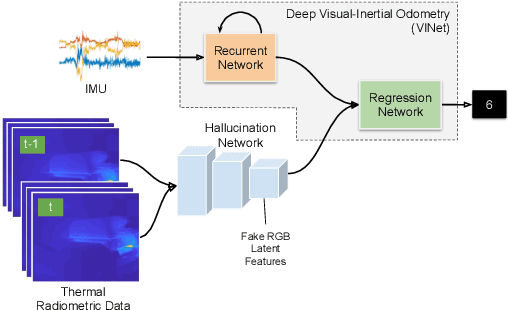
Visual odometry shows excellent performance in a wide range of environments. However, in visually-denied scenarios (e.g. heavy smoke or darkness), pose estimates degrade or even fail. Thermal imaging cameras are commonly used for perception and inspection when the environment has low visibility. However, their use in odometry estimation is hampered by the lack of robust visual features. In part, this is as a result of the sensor measuring the ambient temperature profile rather than scene appearance and geometry. To overcome these issues, we propose a Deep Neural Network model for thermal-inertial odometry (DeepTIO) by incorporating a visual hallucination network to provide the thermal network with complementary information. The hallucination network is taught to predict fake visual features from thermal images by using the robust Huber loss. We also employ selective fusion to attentively fuse the features from three different modalities, i.e thermal, hallucination, and inertial features. Extensive experiments are performed in our large scale hand-held data in benign and smoke-filled environments, showing the efficacy of the proposed model.
AtLoc: Attention Guided Camera Localization
Sep 08, 2019
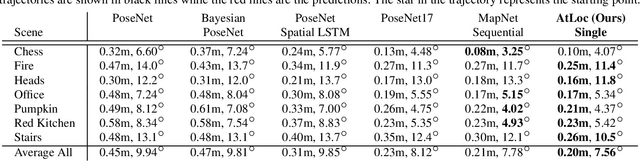
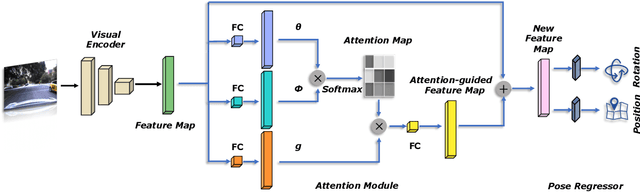
Deep learning has achieved impressive results in camera localization, but current single-image techniques typically suffer from a lack of robustness, leading to large outliers. To some extent, this has been tackled by sequential (multi-images) or geometry constraint approaches, which can learn to reject dynamic objects and illumination conditions to achieve better performance. In this work, we show that attention can be used to force the network to focus on more geometrically robust objects and features, achieving state-of-the-art performance in common benchmark, even if using only a single image as input. Extensive experimental evidence is provided through public indoor and outdoor datasets. Through visualization of the saliency maps, we demonstrate how the network learns to reject dynamic objects, yielding superior global camera pose regression performance. The source code is avaliable at https://github.com/BingCS/AtLoc.