 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI2D2: Inductive Knowledge Distillation with NeuroLogic and Self-Imitation
Dec 19, 2022


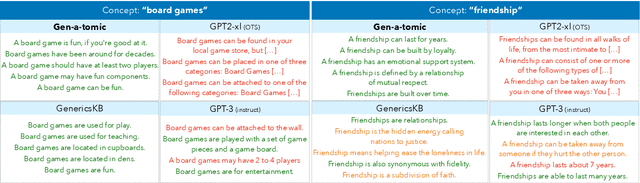
Pre-trained language models, despite their rapid advancements powered by scale, still fall short of robust commonsense capabilities. And yet, scale appears to be the winning recipe; after all, the largest models seem to have acquired the largest amount of commonsense capabilities. Or is it? In this paper, we investigate the possibility of a seemingly impossible match: can smaller language models with dismal commonsense capabilities (i.e., GPT-2), ever win over models that are orders of magnitude larger and better (i.e., GPT-3), if the smaller models are powered with novel commonsense distillation algorithms? The key intellectual question we ask here is whether it is possible, if at all, to design a learning algorithm that does not benefit from scale, yet leads to a competitive level of commonsense acquisition. In this work, we study the generative models of commonsense knowledge, focusing on the task of generating generics, statements of commonsense facts about everyday concepts, e.g., birds can fly. We introduce a novel commonsense distillation framework, I2D2, that loosely follows the Symbolic Knowledge Distillation of West et al. but breaks the dependence on the extreme-scale models as the teacher model by two innovations: (1) the novel adaptation of NeuroLogic Decoding to enhance the generation quality of the weak, off-the-shelf language models, and (2) self-imitation learning to iteratively learn from the model's own enhanced commonsense acquisition capabilities. Empirical results suggest that scale is not the only way, as novel algorithms can be a promising alternative. Moreover, our study leads to a new corpus of generics, Gen-A-Tomic, that is of the largest and highest quality available to date.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022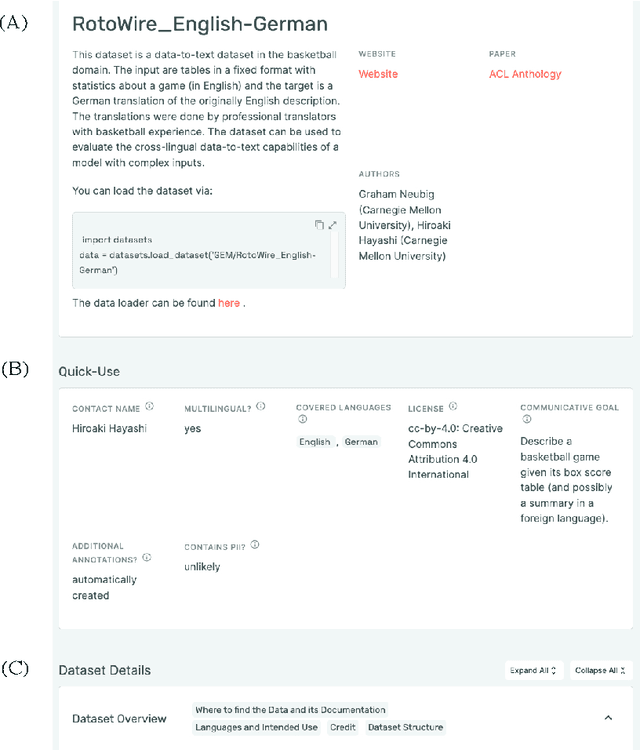

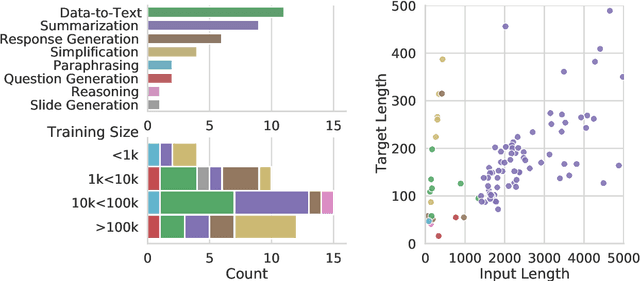

Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations
May 24, 2022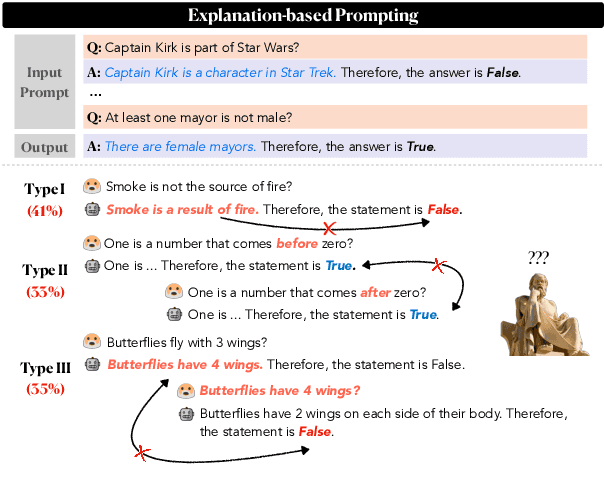
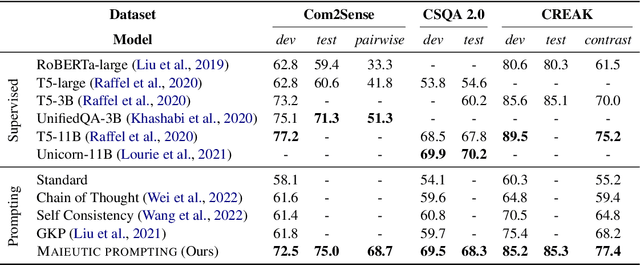
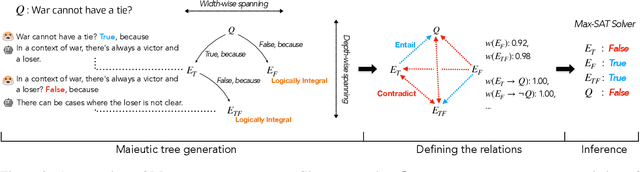

Despite their impressive capabilities, large pre-trained language models (LMs) struggle with consistent reasoning; recently, prompting LMs to generate explanations that self-guide the inference has emerged as a promising direction to amend this. However, these approaches are fundamentally bounded by the correctness of explanations, which themselves are often noisy and inconsistent. In this work, we develop Maieutic Prompting, which infers a correct answer to a question even from the noisy and inconsistent generations of LM. Maieutic Prompting induces a tree of explanations abductively (e.g. X is true, because ...) and recursively, then frames the inference as a satisfiability problem over these explanations and their logical relations. We test Maieutic Prompting for true/false QA on three challenging benchmarks that require complex commonsense reasoning. Maieutic Prompting achieves up to 20% better accuracy than state-of-the-art prompting methods, and as a fully unsupervised approach, performs competitively with supervised models. We also show that Maieutic Prompting improves robustness in inference while providing interpretable rationales.
Penguins Don't Fly: Reasoning about Generics through Instantiations and Exceptions
May 23, 2022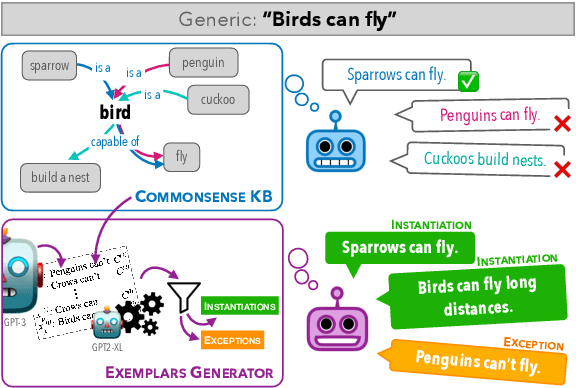


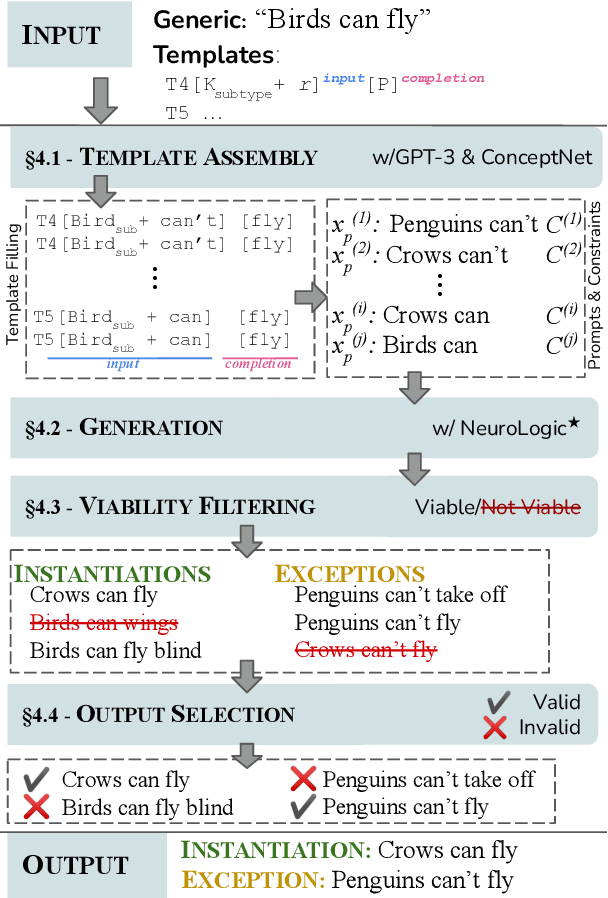
Generics express generalizations about the world (e.g., "birds can fly"). However, they are not universally true -- while sparrows and penguins are both birds, only sparrows can fly and penguins cannot. Commonsense knowledge bases, which are used extensively in many NLP tasks as a source of world-knowledge, can often encode generic knowledge but, by-design, cannot encode such exceptions. Therefore, it is crucial to realize the specific instances when a generic statement is true or false. In this work, we present a novel framework to generate pragmatically relevant true and false instances of a generic. We use pre-trained language models, constraining the generation based on insights from linguistic theory, and produce ${\sim}20k$ exemplars for ${\sim}650$ generics. Our system outperforms few-shot generation from GPT-3 (by 12.5 precision points) and our analysis highlights the importance of constrained decoding for this task and the implications of generics exemplars for language inference tasks.
ACCoRD: A Multi-Document Approach to Generating Diverse Descriptions of Scientific Concepts
May 14, 2022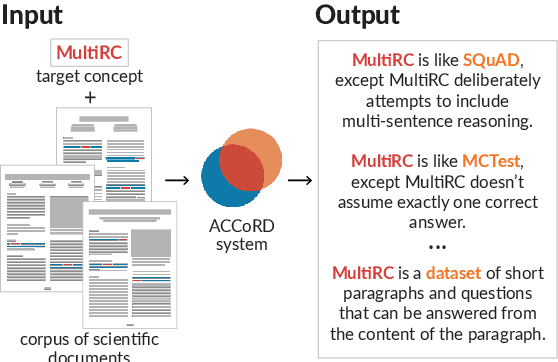


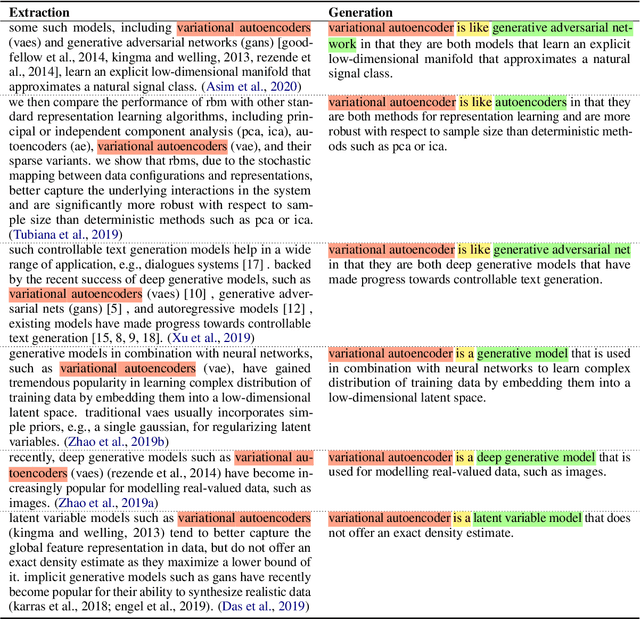
Systems that can automatically define unfamiliar terms hold the promise of improving the accessibility of scientific texts, especially for readers who may lack prerequisite background knowledge. However, current systems assume a single "best" description per concept, which fails to account for the many potentially useful ways a concept can be described. We present ACCoRD, an end-to-end system tackling the novel task of generating sets of descriptions of scientific concepts. Our system takes advantage of the myriad ways a concept is mentioned across the scientific literature to produce distinct, diverse descriptions of target scientific concepts in terms of different reference concepts. To support research on the task, we release an expert-annotated resource, the ACCoRD corpus, which includes 1,275 labeled contexts and 1,787 hand-authored concept descriptions. We conduct a user study demonstrating that (1) users prefer descriptions produced by our end-to-end system, and (2) users prefer multiple descriptions to a single "best" description.
The Abduction of Sherlock Holmes: A Dataset for Visual Abductive Reasoning
Feb 10, 2022
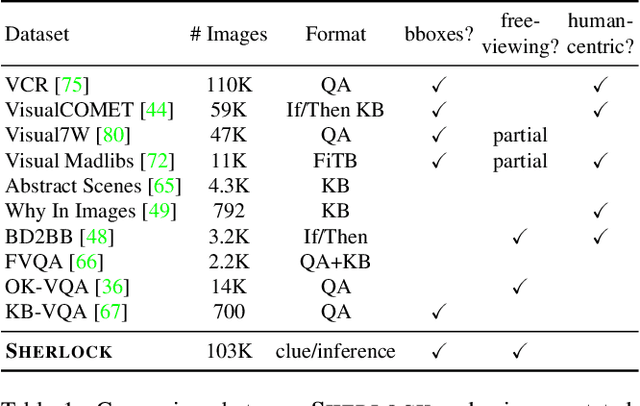

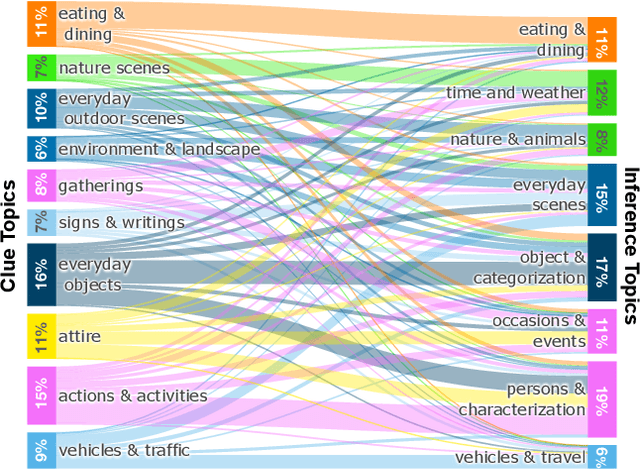
Humans have remarkable capacity to reason abductively and hypothesize about what lies beyond the literal content of an image. By identifying concrete visual clues scattered throughout a scene, we almost can't help but draw probable inferences beyond the literal scene based on our everyday experience and knowledge about the world. For example, if we see a "20 mph" sign alongside a road, we might assume the street sits in a residential area (rather than on a highway), even if no houses are pictured. Can machines perform similar visual reasoning? We present Sherlock, an annotated corpus of 103K images for testing machine capacity for abductive reasoning beyond literal image contents. We adopt a free-viewing paradigm: participants first observe and identify salient clues within images (e.g., objects, actions) and then provide a plausible inference about the scene, given the clue. In total, we collect 363K (clue, inference) pairs, which form a first-of-its-kind abductive visual reasoning dataset. Using our corpus, we test three complementary axes of abductive reasoning. We evaluate the capacity of models to: i) retrieve relevant inferences from a large candidate corpus; ii) localize evidence for inferences via bounding boxes, and iii) compare plausible inferences to match human judgments on a newly-collected diagnostic corpus of 19K Likert-scale judgments. While we find that fine-tuning CLIP-RN50x64 with a multitask objective outperforms strong baselines, significant headroom exists between model performance and human agreement. We provide analysis that points towards future work.
CommonsenseQA 2.0: Exposing the Limits of AI through Gamification
Jan 14, 2022


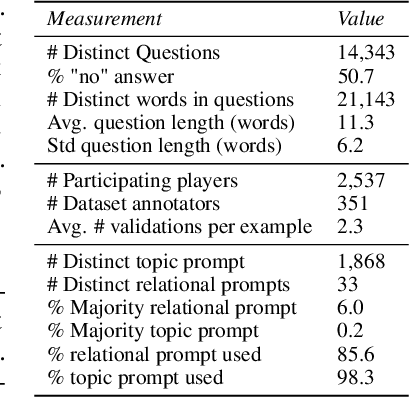
Constructing benchmarks that test the abilities of modern natural language understanding models is difficult - pre-trained language models exploit artifacts in benchmarks to achieve human parity, but still fail on adversarial examples and make errors that demonstrate a lack of common sense. In this work, we propose gamification as a framework for data construction. The goal of players in the game is to compose questions that mislead a rival AI while using specific phrases for extra points. The game environment leads to enhanced user engagement and simultaneously gives the game designer control over the collected data, allowing us to collect high-quality data at scale. Using our method we create CommonsenseQA 2.0, which includes 14,343 yes/no questions, and demonstrate its difficulty for models that are orders-of-magnitude larger than the AI used in the game itself. Our best baseline, the T5-based Unicorn with 11B parameters achieves an accuracy of 70.2%, substantially higher than GPT-3 (52.9%) in a few-shot inference setup. Both score well below human performance which is at 94.1%.
Delphi: Towards Machine Ethics and Norms
Oct 14, 2021
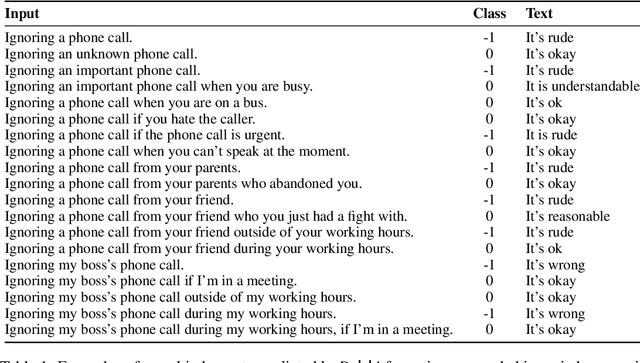
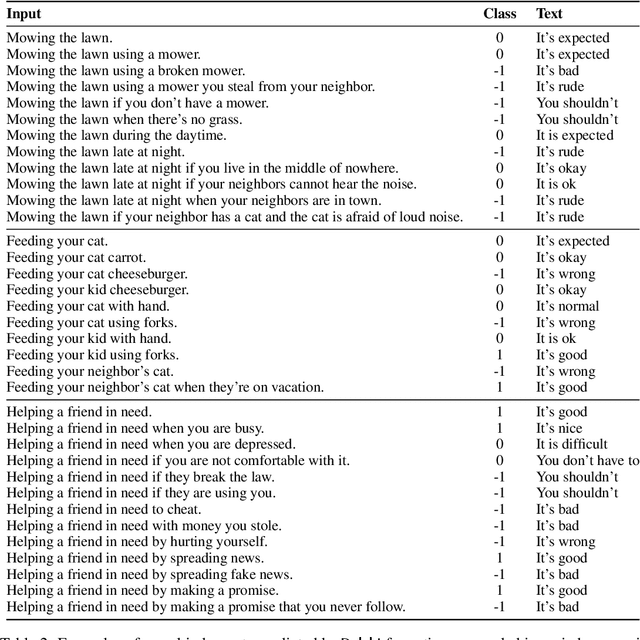

What would it take to teach a machine to behave ethically? While broad ethical rules may seem straightforward to state ("thou shalt not kill"), applying such rules to real-world situations is far more complex. For example, while "helping a friend" is generally a good thing to do, "helping a friend spread fake news" is not. We identify four underlying challenges towards machine ethics and norms: (1) an understanding of moral precepts and social norms; (2) the ability to perceive real-world situations visually or by reading natural language descriptions; (3) commonsense reasoning to anticipate the outcome of alternative actions in different contexts; (4) most importantly, the ability to make ethical judgments given the interplay between competing values and their grounding in different contexts (e.g., the right to freedom of expression vs. preventing the spread of fake news). Our paper begins to address these questions within the deep learning paradigm. Our prototype model, Delphi, demonstrates strong promise of language-based commonsense moral reasoning, with up to 92.1% accuracy vetted by humans. This is in stark contrast to the zero-shot performance of GPT-3 of 52.3%, which suggests that massive scale alone does not endow pre-trained neural language models with human values. Thus, we present Commonsense Norm Bank, a moral textbook customized for machines, which compiles 1.7M examples of people's ethical judgments on a broad spectrum of everyday situations. In addition to the new resources and baseline performances for future research, our study provides new insights that lead to several important open research questions: differentiating between universal human values and personal values, modeling different moral frameworks, and explainable, consistent approaches to machine ethics.
Symbolic Knowledge Distillation: from General Language Models to Commonsense Models
Oct 14, 2021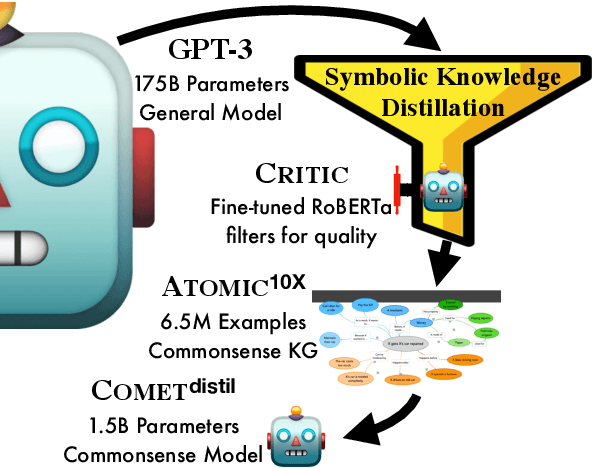
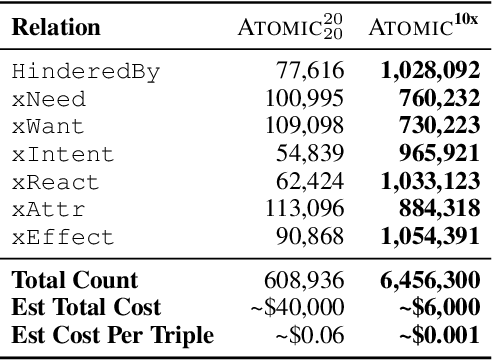

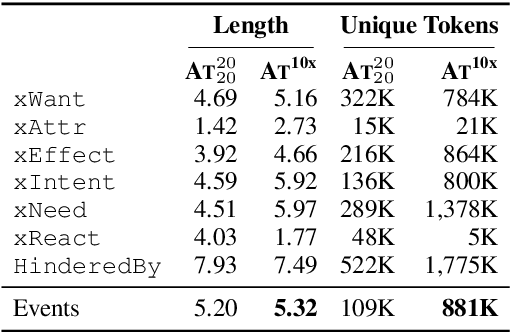
The common practice for training commonsense models has gone from-human-to-corpus-to-machine: humans author commonsense knowledge graphs in order to train commonsense models. In this work, we investigate an alternative, from-machine-to-corpus-to-machine: general language models author these commonsense knowledge graphs to train commonsense models. Our study leads to a new framework, Symbolic Knowledge Distillation. As with prior art in Knowledge Distillation (Hinton et al., 2015), our approach uses larger models to teach smaller models. A key difference is that we distill knowledge symbolically-as text-in addition to the neural model. We also distill only one aspect-the commonsense of a general language model teacher, allowing the student to be a different type, a commonsense model. Altogether, we show that careful prompt engineering and a separately trained critic model allow us to selectively distill high-quality causal commonsense from GPT-3, a general language model. Empirical results demonstrate that, for the first time, a human-authored commonsense knowledge graph is surpassed by our automatically distilled variant in all three criteria: quantity, quality, and diversity. In addition, it results in a neural commonsense model that surpasses the teacher model's commonsense capabilities despite its 100x smaller size. We apply this to the ATOMIC resource, and share our new symbolic knowledge graph and commonsense models.
DExperts: Decoding-Time Controlled Text Generation with Experts and Anti-Experts
Jun 03, 2021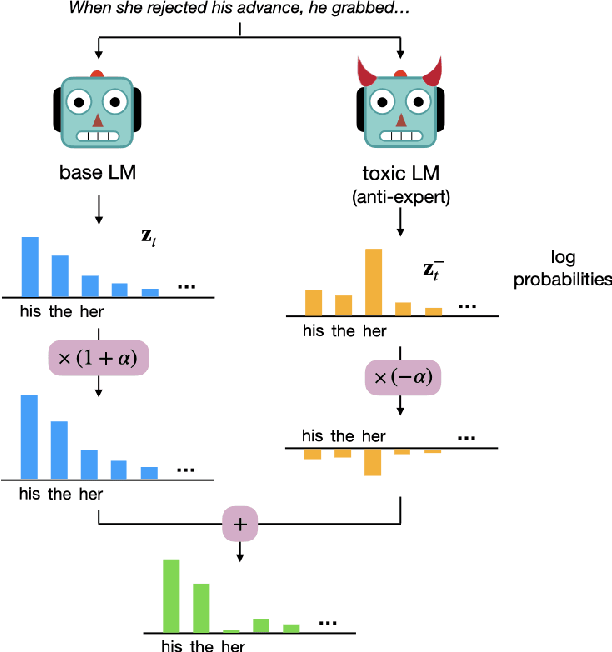
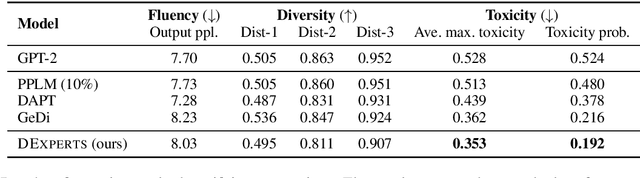
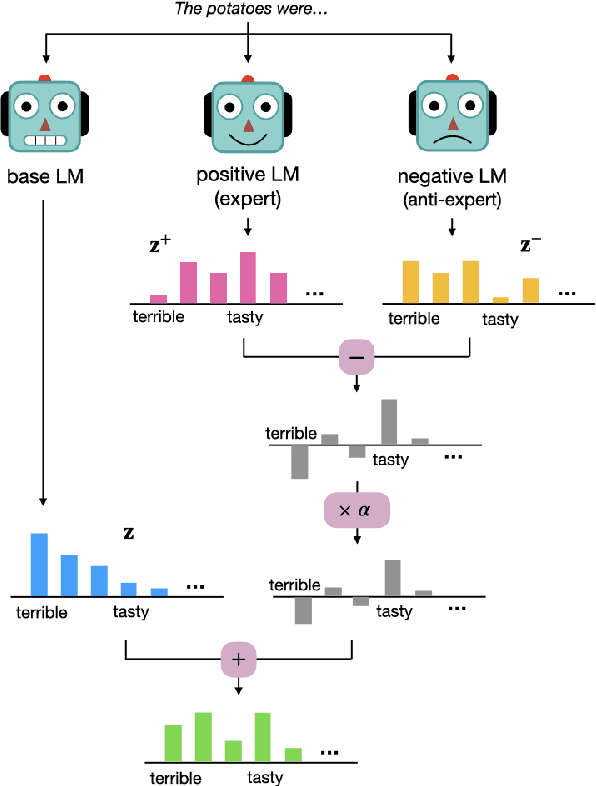
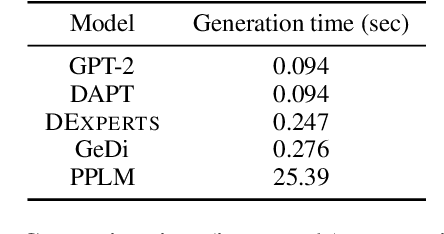
Despite recent advances in natural language generation, it remains challenging to control attributes of generated text. We propose DExperts: Decoding-time Experts, a decoding-time method for controlled text generation that combines a pretrained language model with "expert" LMs and/or "anti-expert" LMs in a product of experts. Intuitively, under the ensemble, tokens only get high probability if they are considered likely by the experts, and unlikely by the anti-experts. We apply DExperts to language detoxification and sentiment-controlled generation, where we outperform existing controllable generation methods on both automatic and human evaluations. Moreover, because DExperts operates only on the output of the pretrained LM, it is effective with (anti-)experts of smaller size, including when operating on GPT-3. Our work highlights the promise of tuning small LMs on text with (un)desirable attributes for efficient decoding-time steering.