 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating Multi-Suction Item Picking at Scale via Multi-Modal Learning of Pick Success
Jun 12, 2025This work demonstrates how autonomously learning aspects of robotic operation from sparsely-labeled, real-world data of deployed, engineered solutions at industrial scale can provide with solutions that achieve improved performance. Specifically, it focuses on multi-suction robot picking and performs a comprehensive study on the application of multi-modal visual encoders for predicting the success of candidate robotic picks. Picking diverse items from unstructured piles is an important and challenging task for robot manipulation in real-world settings, such as warehouses. Methods for picking from clutter must work for an open set of items while simultaneously meeting latency constraints to achieve high throughput. The demonstrated approach utilizes multiple input modalities, such as RGB, depth and semantic segmentation, to estimate the quality of candidate multi-suction picks. The strategy is trained from real-world item picking data, with a combination of multimodal pretrain and finetune. The manuscript provides comprehensive experimental evaluation performed over a large item-picking dataset, an item-picking dataset targeted to include partial occlusions, and a package-picking dataset, which focuses on containers, such as boxes and envelopes, instead of unpackaged items. The evaluation measures performance for different item configurations, pick scenes, and object types. Ablations help to understand the effects of in-domain pretraining, the impact of different modalities and the importance of finetuning. These ablations reveal both the importance of training over multiple modalities but also the ability of models to learn during pretraining the relationship between modalities so that during finetuning and inference, only a subset of them can be used as input.
ARMBench: An Object-centric Benchmark Dataset for Robotic Manipulation
Mar 29, 2023This paper introduces Amazon Robotic Manipulation Benchmark (ARMBench), a large-scale, object-centric benchmark dataset for robotic manipulation in the context of a warehouse. Automation of operations in modern warehouses requires a robotic manipulator to deal with a wide variety of objects, unstructured storage, and dynamically changing inventory. Such settings pose challenges in perceiving the identity, physical characteristics, and state of objects during manipulation. Existing datasets for robotic manipulation consider a limited set of objects or utilize 3D models to generate synthetic scenes with limitation in capturing the variety of object properties, clutter, and interactions. We present a large-scale dataset collected in an Amazon warehouse using a robotic manipulator performing object singulation from containers with heterogeneous contents. ARMBench contains images, videos, and metadata that corresponds to 235K+ pick-and-place activities on 190K+ unique objects. The data is captured at different stages of manipulation, i.e., pre-pick, during transfer, and after placement. Benchmark tasks are proposed by virtue of high-quality annotations and baseline performance evaluation are presented on three visual perception challenges, namely 1) object segmentation in clutter, 2) object identification, and 3) defect detection. ARMBench can be accessed at http://armbench.com
Online Object Model Reconstruction and Reuse for Lifelong Improvement of Robot Manipulation
Sep 28, 2021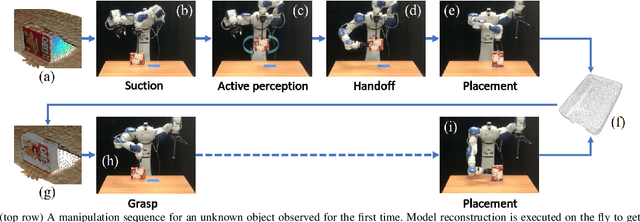
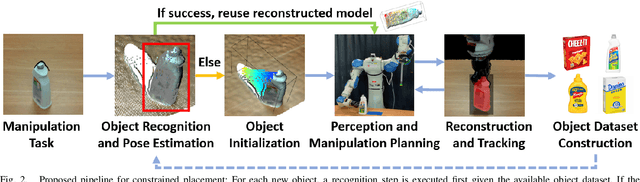
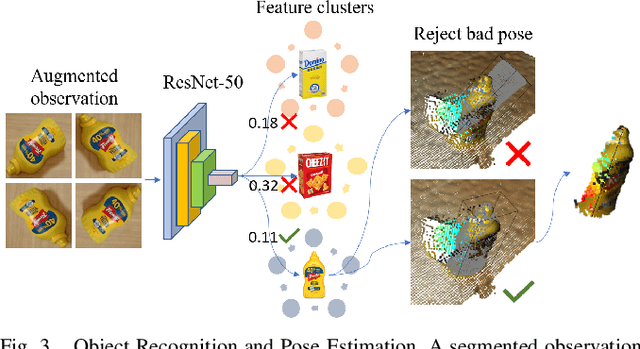
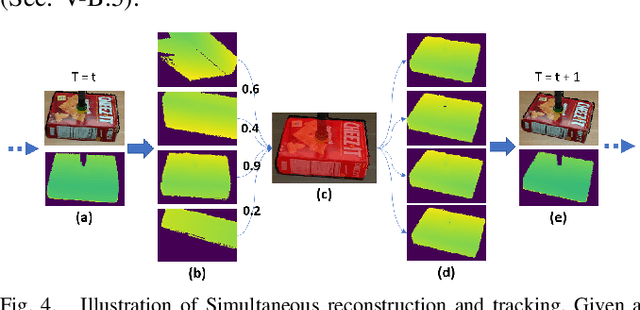
This work proposes a robotic pipeline for picking and constrained placement of objects without geometric shape priors. Compared to recent efforts developed for similar tasks, where every object was assumed to be novel, the proposed system recognizes previously manipulated objects and performs online model reconstruction and reuse. Over a lifelong manipulation process, the system keeps learning features of objects it has interacted with and updates their reconstructed models. Whenever an instance of a previously manipulated object reappears, the system aims to first recognize it and then register its previously reconstructed model given the current observation. This step greatly reduces object shape uncertainty allowing the system to even reason for parts of the objects that are currently not observable. This also results in better manipulation efficiency as it reduces the need for active perception of the target object during manipulation. To get a reusable reconstructed model, the proposed pipeline adopts i) TSDF for object representation, and ii) a variant of the standard particle filter algorithm for pose estimation and tracking of the partial object model. Furthermore, an effective way to construct and maintain a dataset of manipulated objects is presented. A sequence of real-world manipulation experiments is performed to show how future manipulation tasks become more effective and efficient by reusing reconstructed models of previously manipulated objects that were generated on the fly instead of treating objects as novel every time.
Data-driven 6D Pose Tracking by Calibrating Image Residuals in Synthetic Domains
May 29, 2021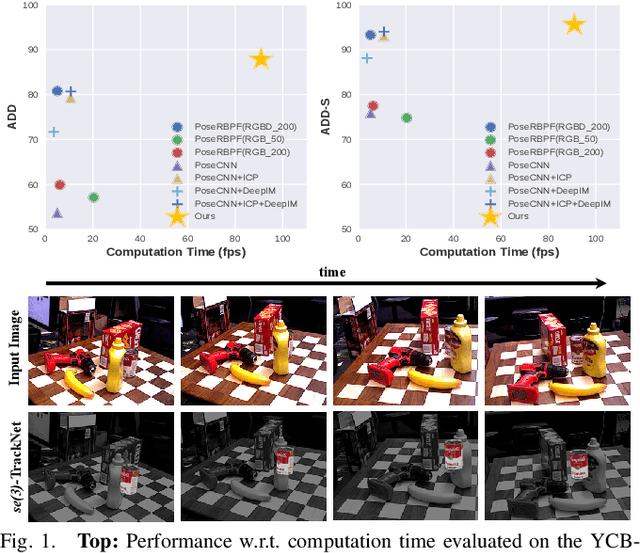
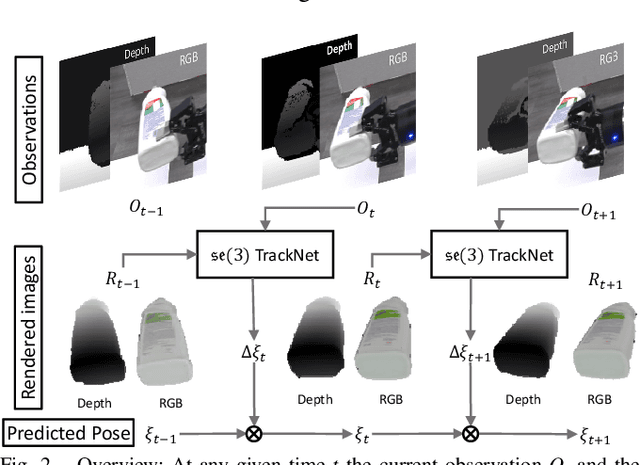
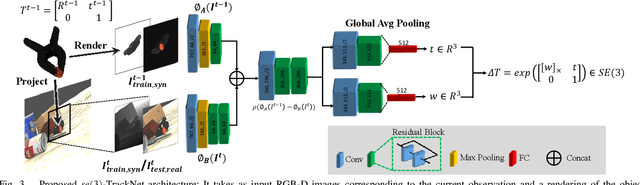

Tracking the 6D pose of objects in video sequences is important for robot manipulation. This work presents se(3)-TrackNet, a data-driven optimization approach for long term, 6D pose tracking. It aims to identify the optimal relative pose given the current RGB-D observation and a synthetic image conditioned on the previous best estimate and the object's model. The key contribution in this context is a novel neural network architecture, which appropriately disentangles the feature encoding to help reduce domain shift, and an effective 3D orientation representation via Lie Algebra. Consequently, even when the network is trained solely with synthetic data can work effectively over real images. Comprehensive experiments over multiple benchmarks show se(3)-TrackNet achieves consistently robust estimates and outperforms alternatives, even though they have been trained with real images. The approach runs in real time at 90.9Hz. Code, data and supplementary video for this project are available at https://github.com/wenbowen123/iros20-6d-pose-tracking
* CVPR 2021 Workshop on 3D Vision and Robotics. arXiv admin note: substantial text overlap with arXiv:2007.13866
Safe and Effective Picking Paths in Clutter given Discrete Distributions of Object Poses
Aug 11, 2020
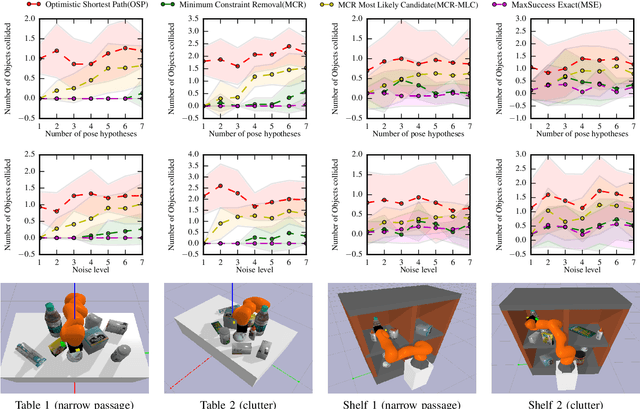
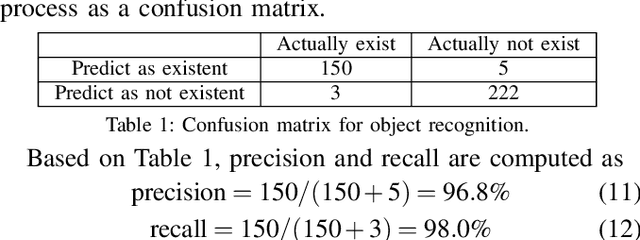
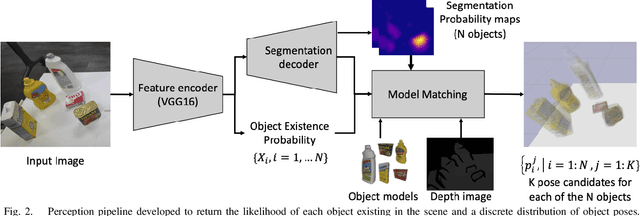
Picking an item in the presence of other objects can be challenging as it involves occlusions and partial views. Given object models, one approach is to perform object pose estimation and use the most likely candidate pose per object to pick the target without collisions. This approach, however, ignores the uncertainty of the perception process both regarding the target's and the surrounding objects' poses. This work proposes first a perception process for 6D pose estimation, which returns a discrete distribution of object poses in a scene. Then, an open-loop planning pipeline is proposed to return safe and effective solutions for moving a robotic arm to pick, which (a) minimizes the probability of collision with the obstructing objects; and (b) maximizes the probability of reaching the target item. The planning framework models the challenge as a stochastic variant of the Minimum Constraint Removal (MCR) problem. The effectiveness of the methodology is verified given both simulated and real data in different scenarios. The experiments demonstrate the importance of considering the uncertainty of the perception process in terms of safe execution. The results also show that the methodology is more effective than conservative MCR approaches, which avoid all possible object poses regardless of the reported uncertainty.
se-TrackNet: Data-driven 6D Pose Tracking by Calibrating Image Residuals in Synthetic Domains
Jul 27, 2020Tracking the 6D pose of objects in video sequences is important for robot manipulation. This task, however, introduces multiple challenges: (i) robot manipulation involves significant occlusions; (ii) data and annotations are troublesome and difficult to collect for 6D poses, which complicates machine learning solutions, and (iii) incremental error drift often accumulates in long term tracking to necessitate re-initialization of the object's pose. This work proposes a data-driven optimization approach for long-term, 6D pose tracking. It aims to identify the optimal relative pose given the current RGB-D observation and a synthetic image conditioned on the previous best estimate and the object's model. The key contribution in this context is a novel neural network architecture, which appropriately disentangles the feature encoding to help reduce domain shift, and an effective 3D orientation representation via Lie Algebra. Consequently, even when the network is trained only with synthetic data can work effectively over real images. Comprehensive experiments over benchmarks - existing ones as well as a new dataset with significant occlusions related to object manipulation - show that the proposed approach achieves consistently robust estimates and outperforms alternatives, even though they have been trained with real images. The approach is also the most computationally efficient among the alternatives and achieves a tracking frequency of 90.9Hz.
Task-driven Perception and Manipulation for Constrained Placement of Unknown Objects
Jun 28, 2020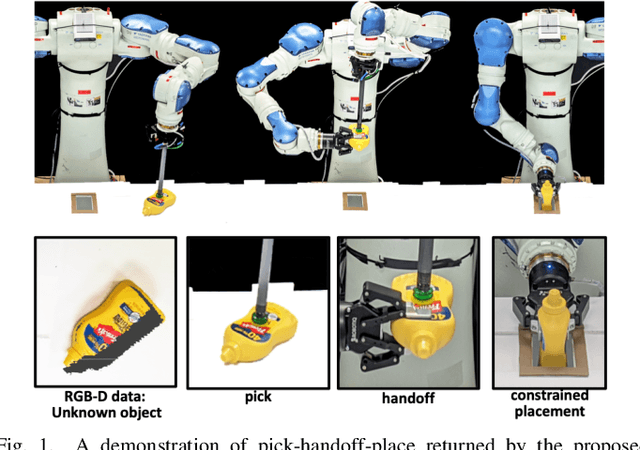
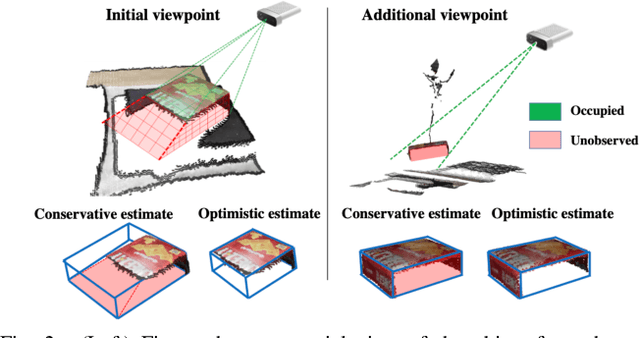
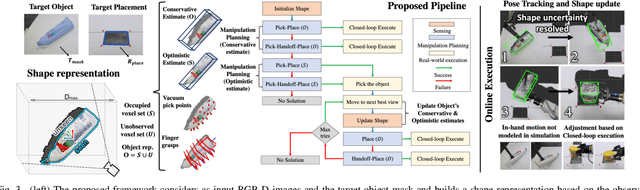
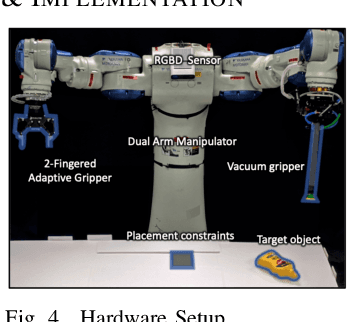
Recent progress in robotic manipulation has dealt with the case of previously unknown objects in the context of relatively simple tasks, such as bin-picking. Existing methods for more constrained problems, however, such as deliberate placement in a tight region, depend more critically on shape information to achieve safe execution. This work deals with pick-and-constrained placement of objects without access to geometric models. The objective is to pick an object and place it safely inside a desired goal region without any collisions, while minimizing the time and the sensing operations required to complete the task. An algorithmic framework is proposed for this purpose, which performs manipulation planning simultaneously over a conservative and an optimistic estimate of the object's volume. The conservative estimate ensures that the manipulation is safe while the optimistic estimate guides the sensor-based manipulation process when no solution can be found for the conservative estimate. To maintain these estimates and dynamically update them during manipulation, objects are represented by a simple volumetric representation, which stores sets of occupied and unseen voxels. The effectiveness of the proposed approach is demonstrated by developing a robotic system that picks a previously unseen object from a table-top and places it in a constrained space. The system comprises of a dual-arm manipulator with heterogeneous end-effectors and leverages hand-offs as a re-grasping strategy. Real-world experiments show that straightforward pick-sense-and-place alternatives frequently fail to solve pick-and-constrained placement problems. The proposed pipeline, however, achieves more than 95% success rate and faster execution times as evaluated over multiple physical experiments.
Robust, Occlusion-aware Pose Estimation for Objects Grasped by Adaptive Hands
Mar 07, 2020
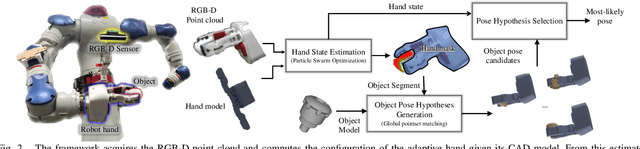
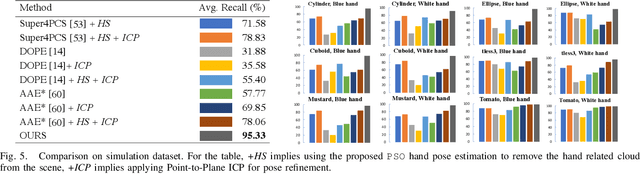

Many manipulation tasks, such as placement or within-hand manipulation, require the object's pose relative to a robot hand. The task is difficult when the hand significantly occludes the object. It is especially hard for adaptive hands, for which it is not easy to detect the finger's configuration. In addition, RGB-only approaches face issues with texture-less objects or when the hand and the object look similar. This paper presents a depth-based framework, which aims for robust pose estimation and short response times. The approach detects the adaptive hand's state via efficient parallel search given the highest overlap between the hand's model and the point cloud. The hand's point cloud is pruned and robust global registration is performed to generate object pose hypotheses, which are clustered. False hypotheses are pruned via physical reasoning. The remaining poses' quality is evaluated given agreement with observed data. Extensive evaluation on synthetic and real data demonstrates the accuracy and computational efficiency of the framework when applied on challenging, highly-occluded scenarios for different object types. An ablation study identifies how the framework's components help in performance. This work also provides a dataset for in-hand 6D object pose estimation. Code and dataset are available at: https://github.com/wenbowen123/icra20-hand-object-pose
That and There: Judging the Intent of Pointing Actions with Robotic Arms
Dec 13, 2019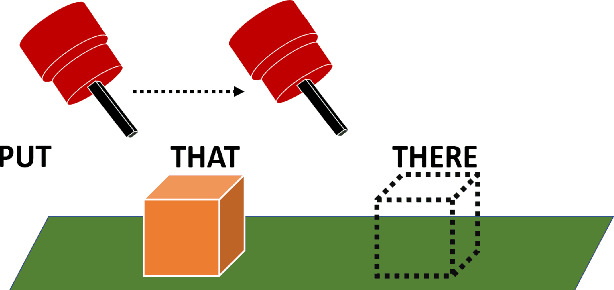
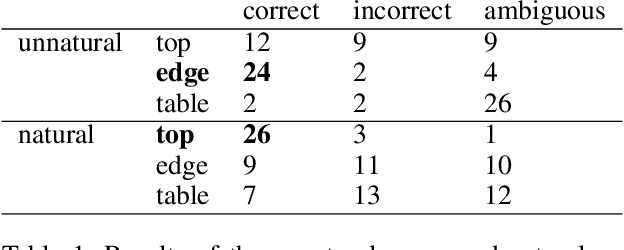
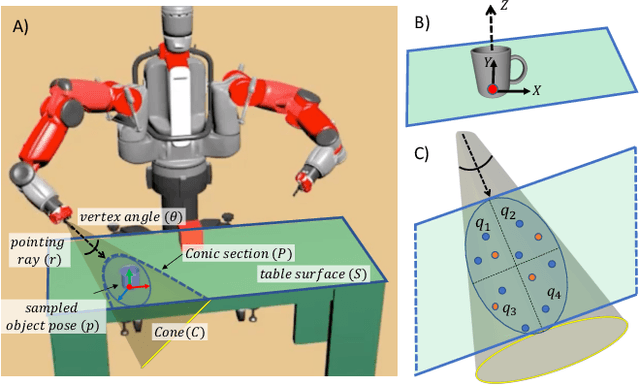
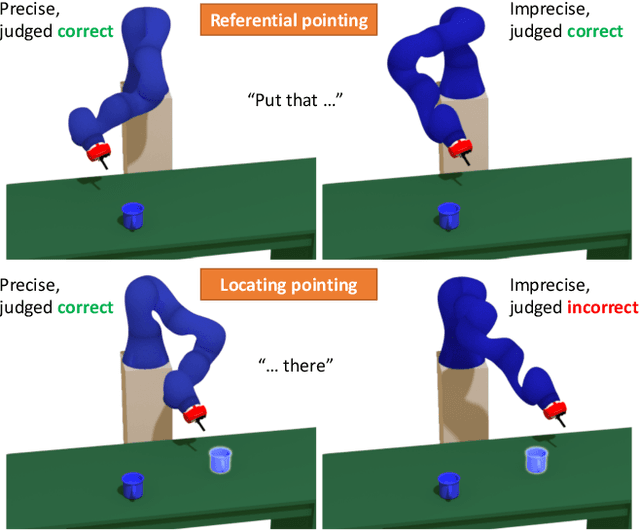
Collaborative robotics requires effective communication between a robot and a human partner. This work proposes a set of interpretive principles for how a robotic arm can use pointing actions to communicate task information to people by extending existing models from the related literature. These principles are evaluated through studies where English-speaking human subjects view animations of simulated robots instructing pick-and-place tasks. The evaluation distinguishes two classes of pointing actions that arise in pick-and-place tasks: referential pointing (identifying objects) and locating pointing (identifying locations). The study indicates that human subjects show greater flexibility in interpreting the intent of referential pointing compared to locating pointing, which needs to be more deliberate. The results also demonstrate the effects of variation in the environment and task context on the interpretation of pointing. Our corpus, experiments and design principles advance models of context, common sense reasoning and communication in embodied communication.
Scene-level Pose Estimation for Multiple Instances of Densely Packed Objects
Oct 11, 2019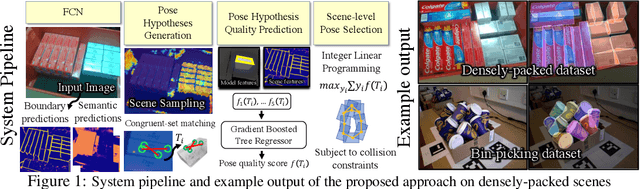

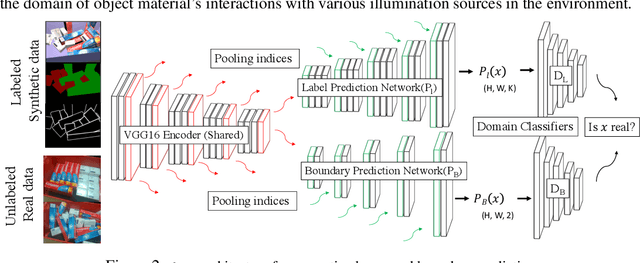

This paper introduces key machine learning operations that allow the realization of robust, joint 6D pose estimation of multiple instances of objects either densely packed or in unstructured piles from RGB-D data. The first objective is to learn semantic and instance-boundary detectors without manual labeling. An adversarial training framework in conjunction with physics-based simulation is used to achieve detectors that behave similarly in synthetic and real data. Given the stochastic output of such detectors, candidates for object poses are sampled. The second objective is to automatically learn a single score for each pose candidate that represents its quality in terms of explaining the entire scene via a gradient boosted tree. The proposed method uses features derived from surface and boundary alignment between the observed scene and the object model placed at hypothesized poses. Scene-level, multi-instance pose estimation is then achieved by an integer linear programming process that selects hypotheses that maximize the sum of the learned individual scores, while respecting constraints, such as avoiding collisions. To evaluate this method, a dataset of densely packed objects with challenging setups for state-of-the-art approaches is collected. Experiments on this dataset and a public one show that the method significantly outperforms alternatives in terms of 6D pose accuracy while trained only with synthetic datasets.