 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEEL (Force-Enhanced Egocentric Learning): A Dataset for Physical Action Understanding
Mar 16, 2026We introduce FEEL (Force-Enhanced Egocentric Learning), the first large-scale dataset pairing force measurements gathered from custom piezoresistive gloves with egocentric video. Our gloves enable scalable data collection, and FEEL contains approximately 3 million force-synchronized frames of natural unscripted manipulation in kitchen environments, with 45% of frames involving hand-object contact. Because force is the underlying cause that drives physical interaction, it is a critical primitive for physical action understanding. We demonstrate the utility of force for physical action understanding through application of FEEL to two families of tasks: (1) contact understanding, where we jointly perform temporal contact segmentation and pixel-level contacted object segmentation; and, (2) action representation learning, where force prediction serves as a self-supervised pretraining objective for video backbones. We achieve state-of-the-art temporal contact segmentation results and competitive pixel-level segmentation results without any need for manual contacted object segmentation annotations. Furthermore we demonstrate that action representation learning with FEEL improves transfer performance on action understanding tasks without any manual labels over EPIC-Kitchens, SomethingSomething-V2, EgoExo4D and Meccano.
Monocular Reconstruction of Neural Tactile Fields
Feb 13, 2026Robots operating in the real world must plan through environments that deform, yield, and reconfigure under contact, requiring interaction-aware 3D representations that extend beyond static geometric occupancy. To address this, we introduce neural tactile fields, a novel 3D representation that maps spatial locations to the expected tactile response upon contact. Our model predicts these neural tactile fields from a single monocular RGB image -- the first method to do so. When integrated with off-the-shelf path planners, neural tactile fields enable robots to generate paths that avoid high-resistance objects while deliberately routing through low-resistance regions (e.g. foliage), rather than treating all occupied space as equally impassable. Empirically, our learning framework improves volumetric 3D reconstruction by $85.8\%$ and surface reconstruction by $26.7\%$ compared to state-of-the-art monocular 3D reconstruction methods (LRM and Direct3D).
Extremum Seeking Controlled Wiggling for Tactile Insertion
Oct 03, 2024



When humans perform insertion tasks such as inserting a cup into a cupboard, routing a cable, or key insertion, they wiggle the object and observe the process through tactile and proprioceptive feedback. While recent advances in tactile sensors have resulted in tactile-based approaches, there has not been a generalized formulation based on wiggling similar to human behavior. Thus, we propose an extremum-seeking control law that can insert four keys into four types of locks without control parameter tuning despite significant variation in lock type. The resulting model-free formulation wiggles the end effector pose to maximize insertion depth while minimizing strain as measured by a GelSight Mini tactile sensor that grasps a key. The algorithm achieves a 71\% success rate over 120 randomly initialized trials with uncertainty in both translation and orientation. Over 240 deterministically initialized trials, where only one translation or rotation parameter is perturbed, 84\% of trials succeeded. Given tactile feedback at 13 Hz, the mean insertion time for these groups of trials are 262 and 147 seconds respectively.
AcTExplore: Active Tactile Exploration on Unknown Objects
Oct 18, 2023

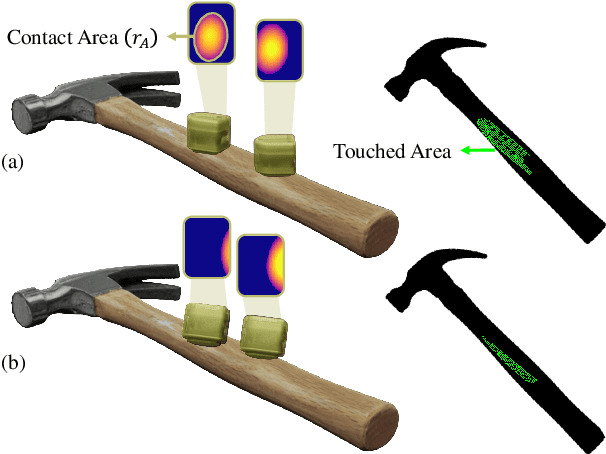

Tactile exploration plays a crucial role in understanding object structures for fundamental robotics tasks such as grasping and manipulation. However, efficiently exploring such objects using tactile sensors is challenging, primarily due to the large-scale unknown environments and limited sensing coverage of these sensors. To this end, we present AcTExplore, an active tactile exploration method driven by reinforcement learning for object reconstruction at scales that automatically explores the object surfaces in a limited number of steps. Through sufficient exploration, our algorithm incrementally collects tactile data and reconstructs 3D shapes of the objects as well, which can serve as a representation for higher-level downstream tasks. Our method achieves an average of 95.97% IoU coverage on unseen YCB objects while just being trained on primitive shapes. Project Webpage: https://prg.cs.umd$.$edu/AcTExplore
GradTac: Spatio-Temporal Gradient Based Tactile Sensing
Mar 14, 2022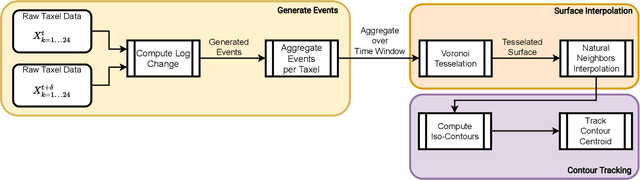
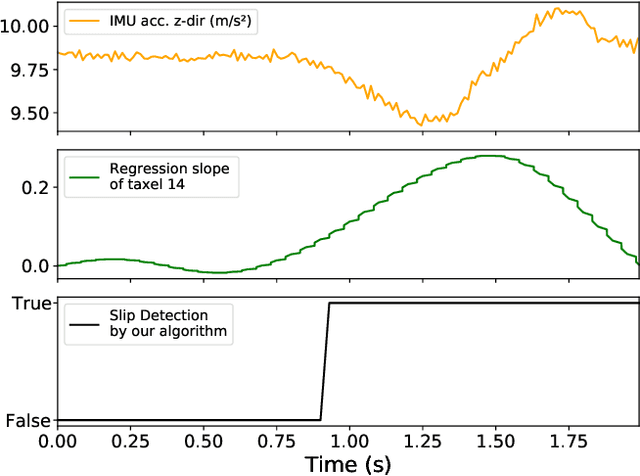

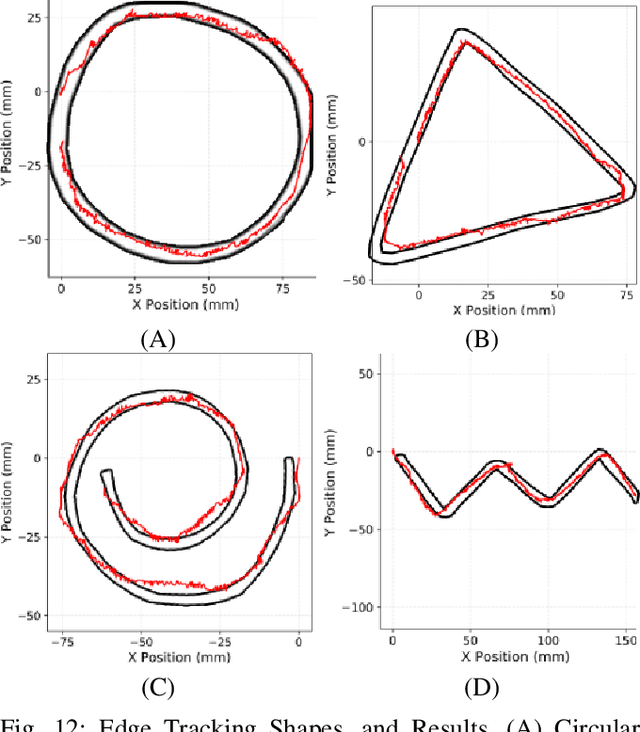
Tactile sensing for robotics is achieved through a variety of mechanisms, including magnetic, optical-tactile, and conductive fluid. Currently, the fluid-based sensors have struck the right balance of anthropomorphic sizes and shapes and accuracy of tactile response measurement. However, this design is plagued by a low Signal to Noise Ratio (SNR) due to the fluid based sensing mechanism "damping" the measurement values that are hard to model. To this end, we present a spatio-temporal gradient representation on the data obtained from fluid-based tactile sensors, which is inspired from neuromorphic principles of event based sensing. We present a novel algorithm (GradTac) that converts discrete data points from spatial tactile sensors into spatio-temporal surfaces and tracks tactile contours across these surfaces. Processing the tactile data using the proposed spatio-temporal domain is robust, makes it less susceptible to the inherent noise from the fluid based sensors, and allows accurate tracking of regions of touch as compared to using the raw data. We successfully evaluate and demonstrate the efficacy of GradTac on many real-world experiments performed using the Shadow Dexterous Hand, equipped with the BioTac SP sensors. Specifically, we use it for tracking tactile input across the sensor's surface, measuring relative forces, detecting linear and rotational slip, and for edge tracking. We also release an accompanying task-agnostic dataset for the BioTac SP, which we hope will provide a resource to compare and quantify various novel approaches, and motivate further research.