 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Robot Localization in Architectural 3D Plans
Jun 09, 2020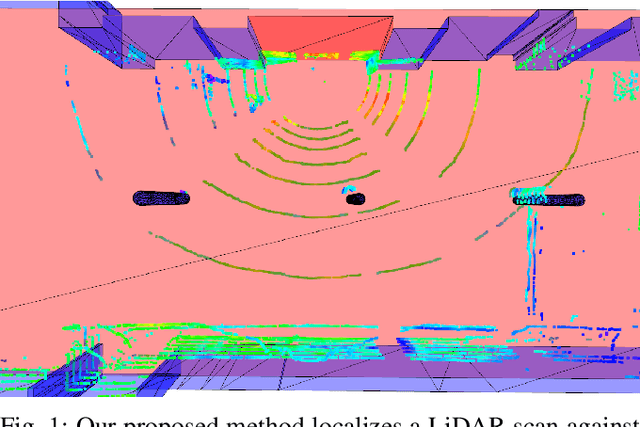

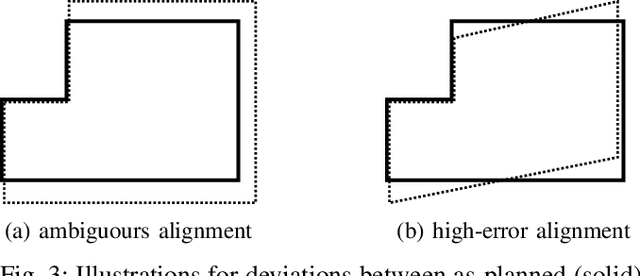

This paper presents a localization system for mobile robots enabling precise localization in inaccurate building models. The approach leverages local referencing to counteract inherent deviations between as-planned and as-built data for locally accurate registration. We further fuse a novel image-based robust outlier detector with LiDAR data to reject a wide range of outlier measurements from clutter, dynamic objects, and sensor failures. We evaluate the proposed approach on a mobile robot in a challenging real world building construction site. It consistently outperforms the traditional ICP-based alingment, reducing localization error by at least 30%.
Learning Camera Miscalibration Detection
May 24, 2020

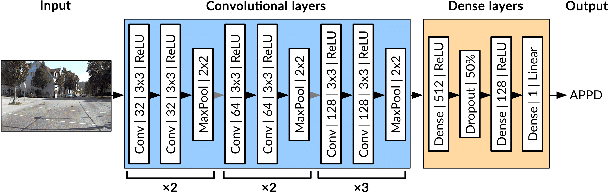
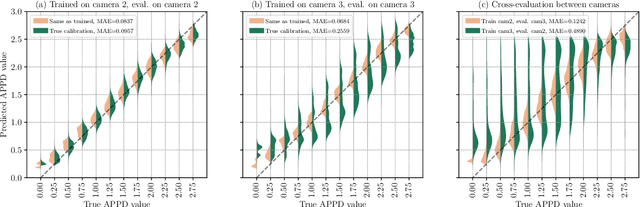
Self-diagnosis and self-repair are some of the key challenges in deploying robotic platforms for long-term real-world applications. One of the issues that can occur to a robot is miscalibration of its sensors due to aging, environmental transients, or external disturbances. Precise calibration lies at the core of a variety of applications, due to the need to accurately perceive the world. However, while a lot of work has focused on calibrating the sensors, not much has been done towards identifying when a sensor needs to be recalibrated. This paper focuses on a data-driven approach to learn the detection of miscalibration in vision sensors, specifically RGB cameras. Our contributions include a proposed miscalibration metric for RGB cameras and a novel semi-synthetic dataset generation pipeline based on this metric. Additionally, by training a deep convolutional neural network, we demonstrate the effectiveness of our pipeline to identify whether a recalibration of the camera's intrinsic parameters is required or not. The code is available at http://github.com/ethz-asl/camera_miscalib_detection.
Voxgraph: Globally Consistent, Volumetric Mapping using Signed Distance Function Submaps
Apr 27, 2020
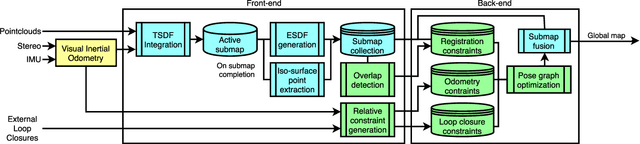
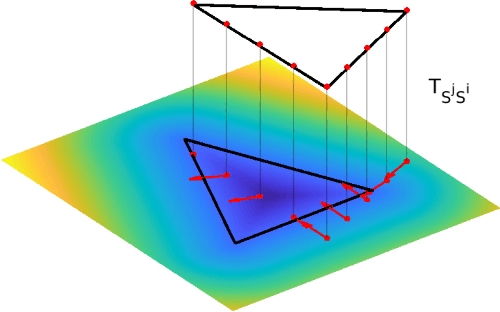
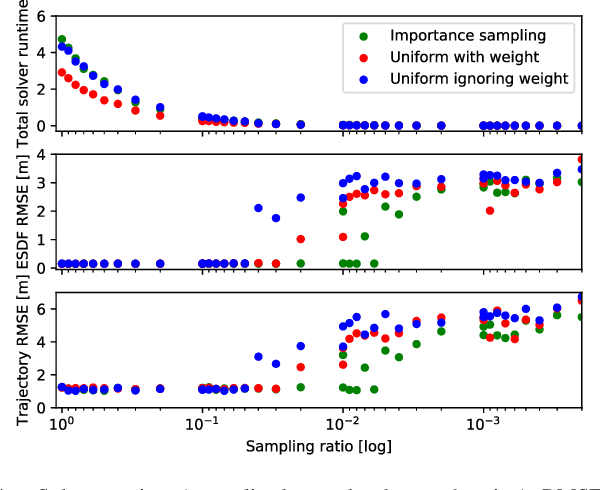
Globally consistent dense maps are a key requirement for long-term robot navigation in complex environments. While previous works have addressed the challenges of dense mapping and global consistency, most require more computational resources than may be available on-board small robots. We propose a framework that creates globally consistent volumetric maps on a CPU and is lightweight enough to run on computationally constrained platforms. Our approach represents the environment as a collection of overlapping Signed Distance Function (SDF) submaps, and maintains global consistency by computing an optimal alignment of the submap collection. By exploiting the underlying SDF representation, we generate correspondence free constraints between submap pairs that are computationally efficient enough to optimize the global problem each time a new submap is added. We deploy the proposed system on a hexacopter Micro Aerial Vehicle (MAV) with an Intel i7-8650U CPU in two realistic scenarios: mapping a large-scale area using a 3D LiDAR, and mapping an industrial space using an RGB-D camera. In the large-scale outdoor experiments, the system optimizes a 120x80m map in less than 4s and produces absolute trajectory RMSEs of less than 1m over 400m trajectories. Our complete system, called voxgraph, is available as open source.
* 8 pages, 9 figures
MOZARD: Multi-Modal Localization for Autonomous Vehicles in Urban Outdoor Environments
Mar 03, 2020
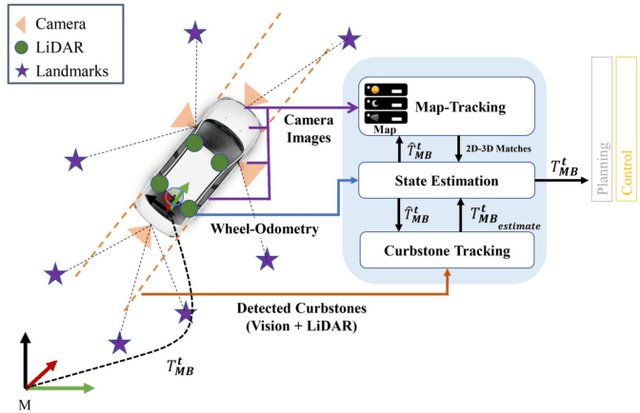


Visually poor scenarios are one of the main sources of failure in visual localization systems in outdoor environments. To address this challenge, we present MOZARD, a multi-modal localization system for urban outdoor environments using vision and LiDAR. By extending our preexisting key-point based visual multi-session local localization approach with the use of semantic data, an improved localization recall can be achieved across vastly different appearance conditions. In particular we focus on the use of curbstone information because of their broad distribution and reliability within urban environments. We present thorough experimental evaluations on several driving kilometers in challenging urban outdoor environments, analyze the recall and accuracy of our localization system and demonstrate in a case study possible failure cases of each subsystem. We demonstrate that MOZARD is able to bridge scenarios where our previous work VIZARD fails, hence yielding an increased recall performance, while a similar localization accuracy of 0.2m is achieved
3D Gated Recurrent Fusion for Semantic Scene Completion
Feb 17, 2020
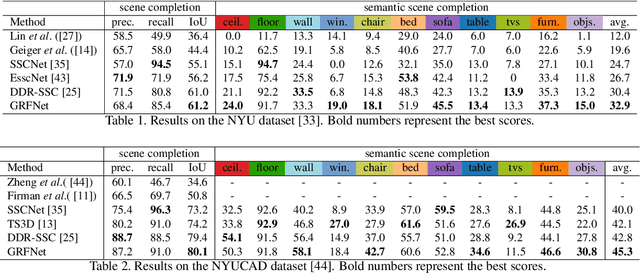
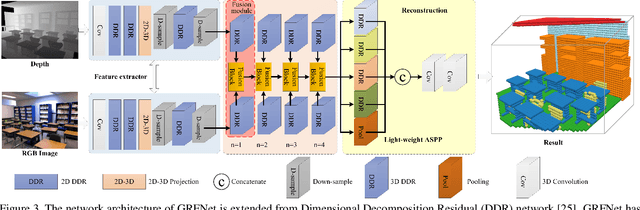
This paper tackles the problem of data fusion in the semantic scene completion (SSC) task, which can simultaneously deal with semantic labeling and scene completion. RGB images contain texture details of the object(s) which are vital for semantic scene understanding. Meanwhile, depth images capture geometric clues of high relevance for shape completion. Using both RGB and depth images can further boost the accuracy of SSC over employing one modality in isolation. We propose a 3D gated recurrent fusion network (GRFNet), which learns to adaptively select and fuse the relevant information from depth and RGB by making use of the gate and memory modules. Based on the single-stage fusion, we further propose a multi-stage fusion strategy, which could model the correlations among different stages within the network. Extensive experiments on two benchmark datasets demonstrate the superior performance and the effectiveness of the proposed GRFNet for data fusion in SSC. Code will be made available.
Depth Based Semantic Scene Completion with Position Importance Aware Loss
Jan 30, 2020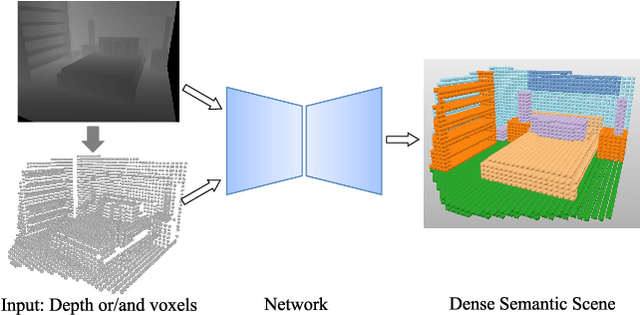
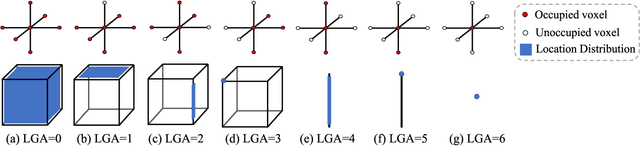
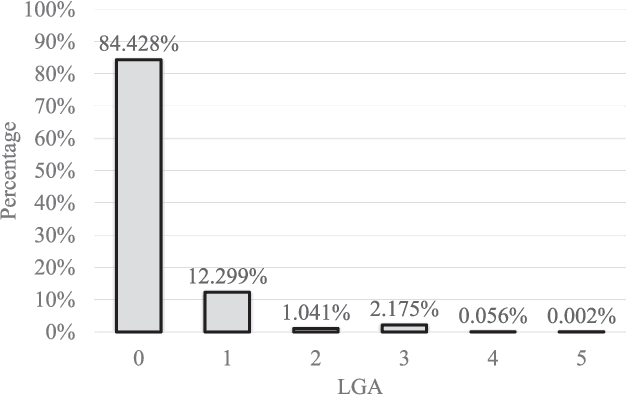
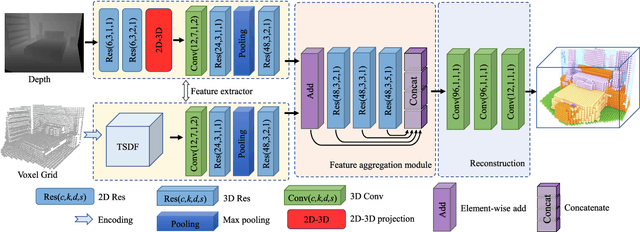
Semantic Scene Completion (SSC) refers to the task of inferring the 3D semantic segmentation of a scene while simultaneously completing the 3D shapes. We propose PALNet, a novel hybrid network for SSC based on single depth. PALNet utilizes a two-stream network to extract both 2D and 3D features from multi-stages using fine-grained depth information to efficiently captures the context, as well as the geometric cues of the scene. Current methods for SSC treat all parts of the scene equally causing unnecessary attention to the interior of objects. To address this problem, we propose Position Aware Loss(PA-Loss) which is position importance aware while training the network. Specifically, PA-Loss considers Local Geometric Anisotropy to determine the importance of different positions within the scene. It is beneficial for recovering key details like the boundaries of objects and the corners of the scene. Comprehensive experiments on two benchmark datasets demonstrate the effectiveness of the proposed method and its superior performance. Models and Video demo can be found at: https://github.com/UniLauX/PALNet.
VersaVIS: An Open Versatile Multi-Camera Visual-Inertial Sensor Suite
Dec 05, 2019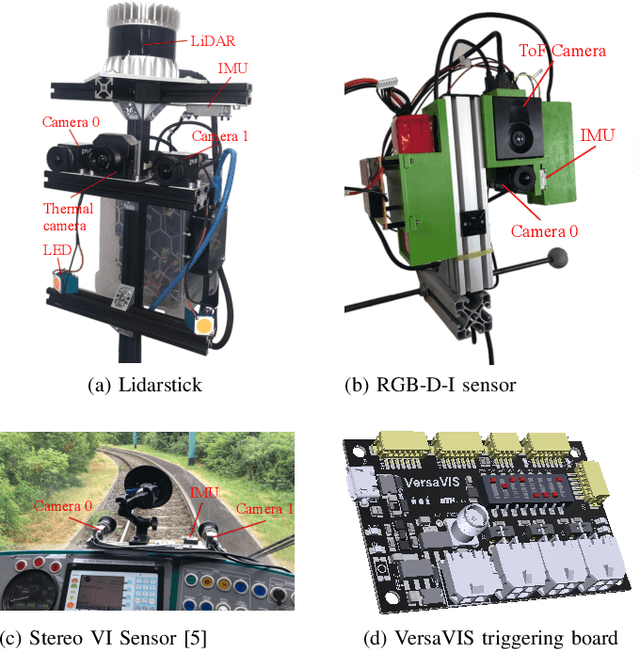
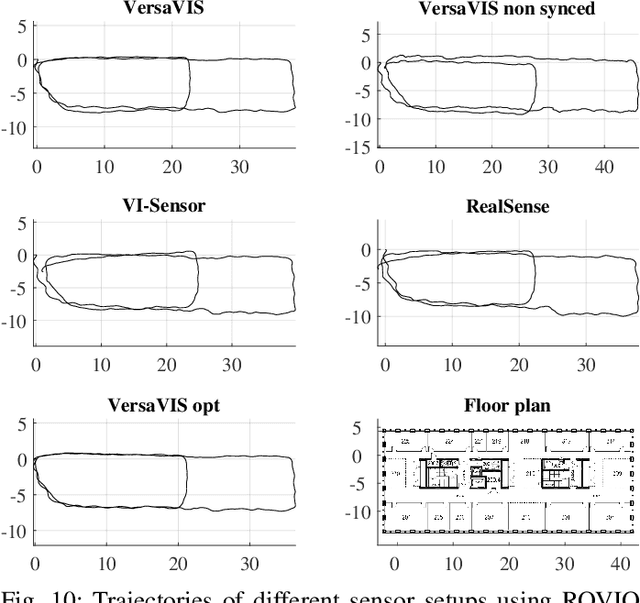
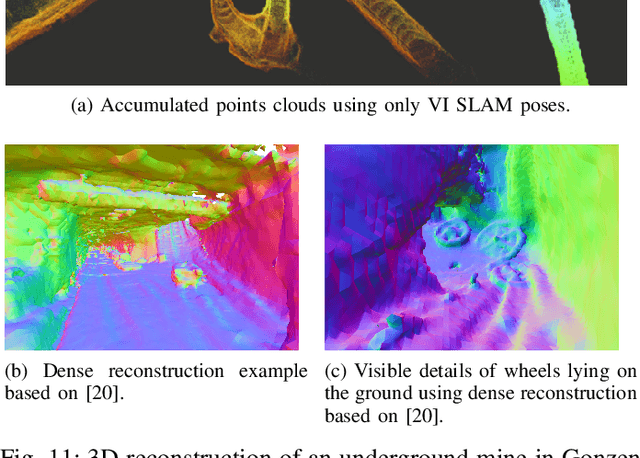
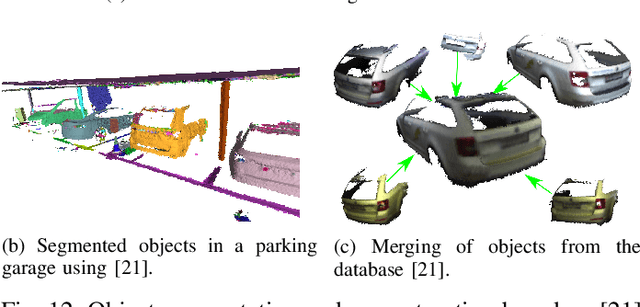
Robust and accurate pose estimation is crucial for many applications in mobile robotics. Extending visual Simultaneous Localization and Mapping (SLAM) with other modalities such as an inertial measurement unit (IMU) can boost robustness and accuracy. However, for a tight sensor fusion, accurate time synchronization of the sensors is often crucial. Changing exposure times, internal sensor filtering, multiple clock sources and unpredictable delays from operation system scheduling and data transfer can make sensor synchronization challenging. In this paper, we present VersaVIS, an Open Versatile Multi-Camera Visual-Inertial Sensor Suite aimed to be an efficient research platform for easy deployment, integration and extension for many mobile robotic applications. VersaVIS provides a complete, open-source hardware, firmware and software bundle to perform time synchronization of multiple cameras with an IMU featuring exposure compensation, host clock translation and independent and stereo camera triggering. The sensor suite supports a wide range of cameras and IMUs to match the requirements of the application. The synchronization accuracy of the framework is evaluated on multiple experiments achieving timing accuracy of less than 1 ms. Furthermore, the applicability and versatility of the sensor suite is demonstrated in multiple applications including visual-inertial SLAM, multi-camera applications, multimodal mapping, reconstruction and object based mapping.
Predicting Unobserved Space For Planning via Depth Map Augmentation
Nov 13, 2019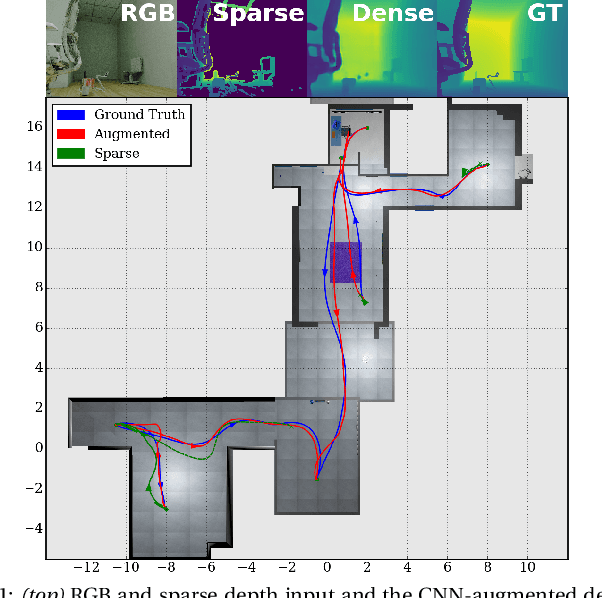
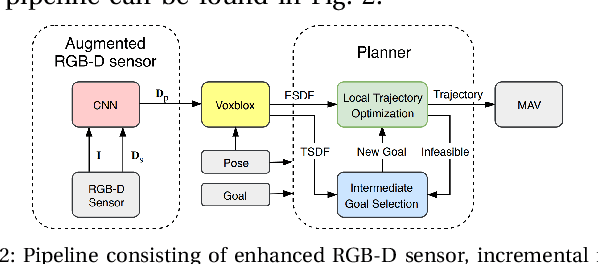

Safe and efficient path planning is crucial for autonomous mobile robots. A prerequisite for path planning is to have a comprehensive understanding of the 3D structure of the robot's environment. On MAVs this is commonly achieved using low-cost sensors, such as stereo or RGB-D cameras. These sensors may fail to provide depth measurements in textureless or IR-absorbing areas and have limited effective range. In path planning, this results in inefficient trajectories or failure to recognize a feasible path to the goal, hence significantly impairing the robot's mobility. Recent advances in deep learning enables us to exploit prior experience about the shape of the world and hence to infer complete depth maps from color images and additional sparse depth measurements. In this work, we present an augmented planning system and investigate the effects of employing state-of-the-art depth completion techniques, specifically trained to augment sparse depth maps originating from RGB-D sensors, semi-dense methods and stereo matchers. We extensively evaluate our approach in online path planning experiments based on simulated data, as well as global path planning experiments based on real world MAV data. We show that our augmented system, provided with only sparse depth perception, can reach on-par performance to ground truth depth input in simulated online planning experiments. On real world MAV data the augmented system demonstrates superior performance compared to a planner based on very dense RGB-D depth maps.
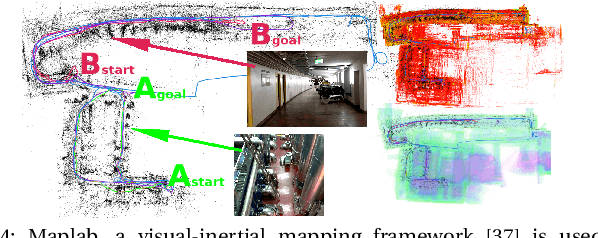
SegMap: Segment-based mapping and localization using data-driven descriptors
Sep 27, 2019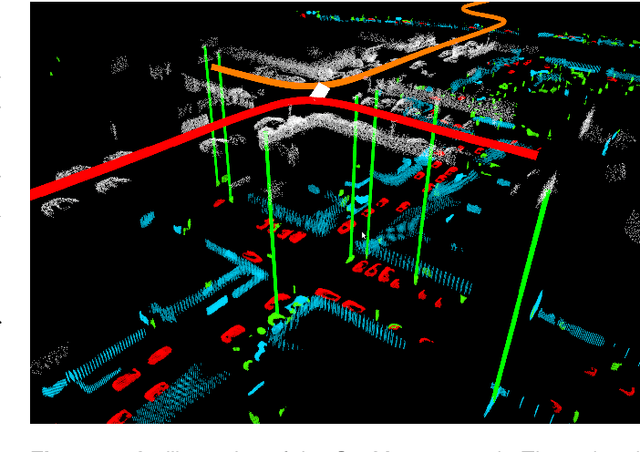
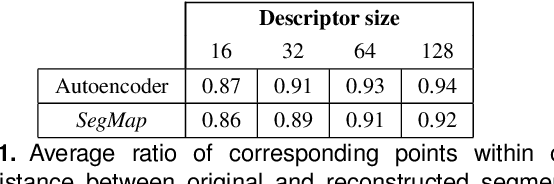

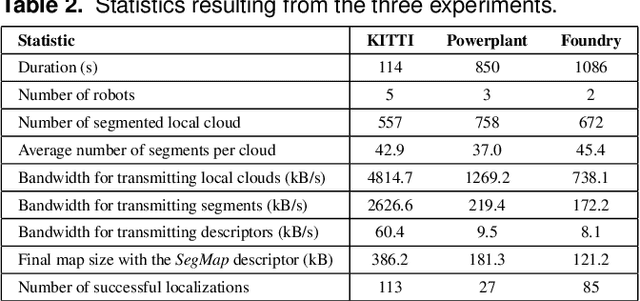
Precisely estimating a robot's pose in a prior, global map is a fundamental capability for mobile robotics, e.g. autonomous driving or exploration in disaster zones. This task, however, remains challenging in unstructured, dynamic environments, where local features are not discriminative enough and global scene descriptors only provide coarse information. We therefore present SegMap: a map representation solution for localization and mapping based on the extraction of segments in 3D point clouds. Working at the level of segments offers increased invariance to view-point and local structural changes, and facilitates real-time processing of large-scale 3D data. SegMap exploits a single compact data-driven descriptor for performing multiple tasks: global localization, 3D dense map reconstruction, and semantic information extraction. The performance of SegMap is evaluated in multiple urban driving and search and rescue experiments. We show that the learned SegMap descriptor has superior segment retrieval capabilities, compared to state-of-the-art handcrafted descriptors. In consequence, we achieve a higher localization accuracy and a 6% increase in recall over state-of-the-art. These segment-based localizations allow us to reduce the open-loop odometry drift by up to 50%. SegMap is open-source available along with easy to run demonstrations.
This is not what I imagined: Error Detection for Semantic Segmentation through Visual Dissimilarity
Sep 02, 2019
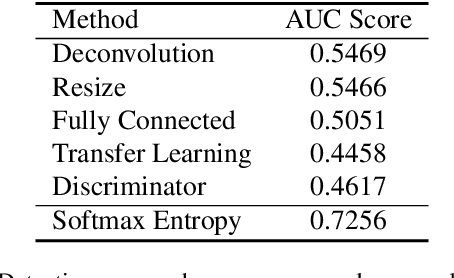
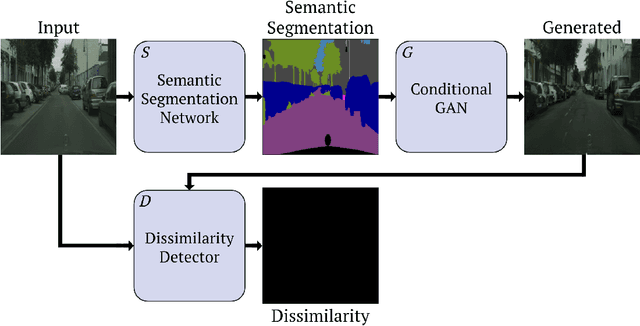
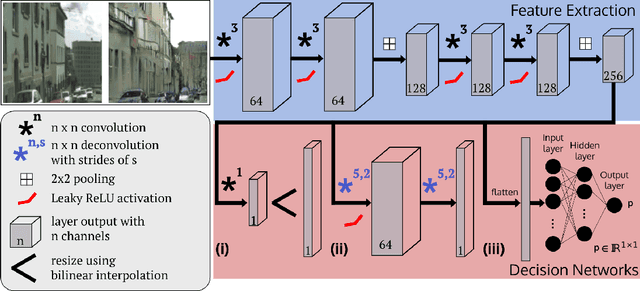
There has been a remarkable progress in the accuracy of semantic segmentation due to the capabilities of deep learning. Unfortunately, these methods are not able to generalize much further than the distribution of their training data and fail to handle out-of-distribution classes appropriately. This limits the applicability to autonomous or safety critical systems. We propose a novel method leveraging generative models to detect wrongly segmented or out-of-distribution instances. Conditioned on the predicted semantic segmentation, an RGB image is generated. We then learn a dissimilarity metric that compares the generated image with the original input and detects inconsistencies introduced by the semantic segmentation. We present test cases for outlier and misclassification detection and evaluate our method qualitatively and quantitatively on multiple datasets.