 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Robot Mapping using Spectral Graph Analysis
Mar 01, 2022
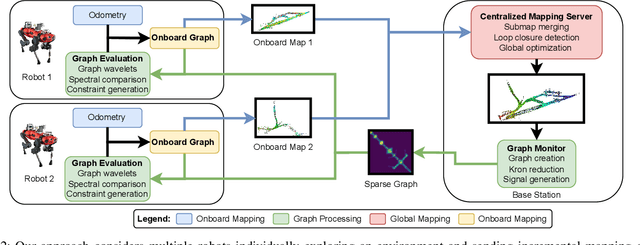
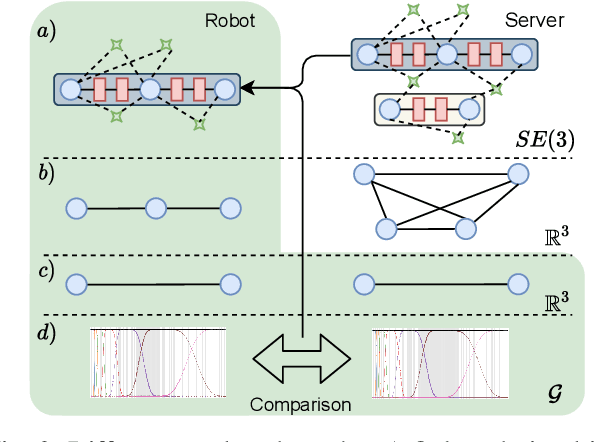
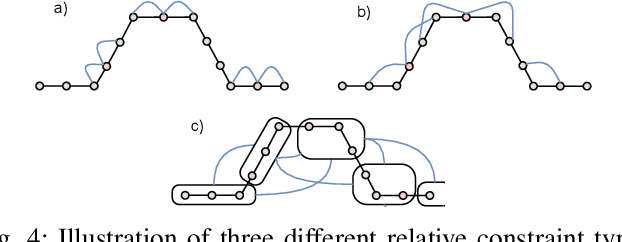
In this paper, we deal with the problem of creating globally consistent pose graphs in a centralized multi-robot SLAM framework. For each robot to act autonomously, individual onboard pose estimates and maps are maintained, which are then communicated to a central server to build an optimized global map. However, inconsistencies between onboard and server estimates can occur due to onboard odometry drift or failure. Furthermore, robots do not benefit from the collaborative map if the server provides no feedback in a computationally tractable and bandwidth-efficient manner. Motivated by this challenge, this paper proposes a novel collaborative mapping framework to enable accurate global mapping among robots and server. In particular, structural differences between robot and server graphs are exploited at different spatial scales using graph spectral analysis to generate necessary constraints for the individual robot pose graphs. The proposed approach is thoroughly analyzed and validated using several real-world multi-robot field deployments where we show improvements of the onboard system up to 90%.
Continual Learning of Semantic Segmentation using Complementary 2D-3D Data Representations
Nov 03, 2021
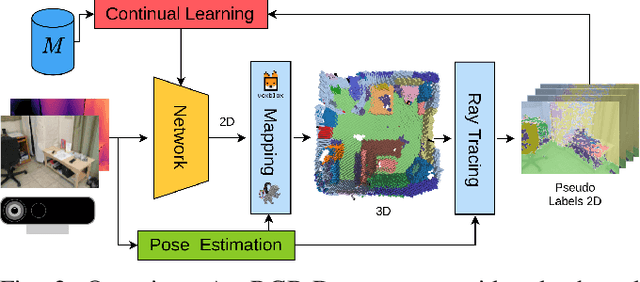
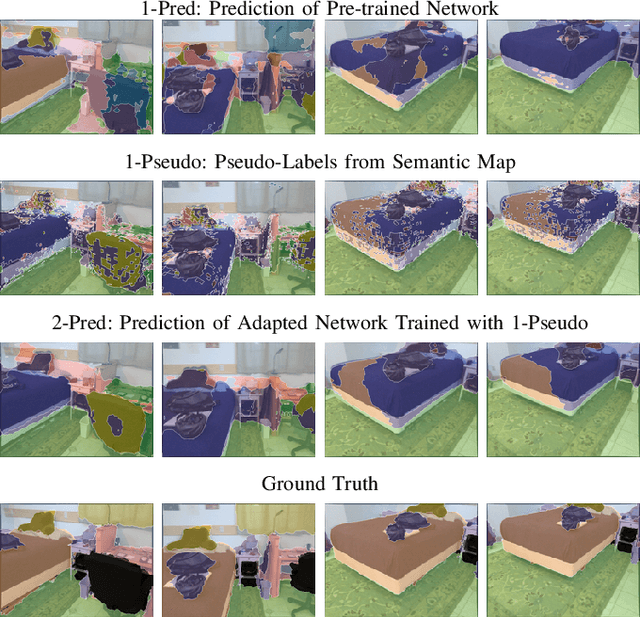

Semantic segmentation networks are usually pre-trained and not updated during deployment. As a consequence, misclassifications commonly occur if the distribution of the training data deviates from the one encountered during the robot's operation. We propose to mitigate this problem by adapting the neural network to the robot's environment during deployment, without any need for external supervision. Leveraging complementary data representations, we generate a supervision signal, by probabilistically accumulating consecutive 2D semantic predictions in a volumetric 3D map. We then retrain the network on renderings of the accumulated semantic map, effectively resolving ambiguities and enforcing multi-view consistency through the 3D representation. To preserve the previously-learned knowledge while performing network adaptation, we employ a continual learning strategy based on experience replay. Through extensive experimental evaluation, we show successful adaptation to real-world indoor scenes both on the ScanNet dataset and on in-house data recorded with an RGB-D sensor. Our method increases the segmentation performance on average by 11.8% compared to the fixed pre-trained neural network, while effectively retaining knowledge from the pre-training dataset.
NeuralBlox: Real-Time Neural Representation Fusion for Robust Volumetric Mapping
Oct 18, 2021
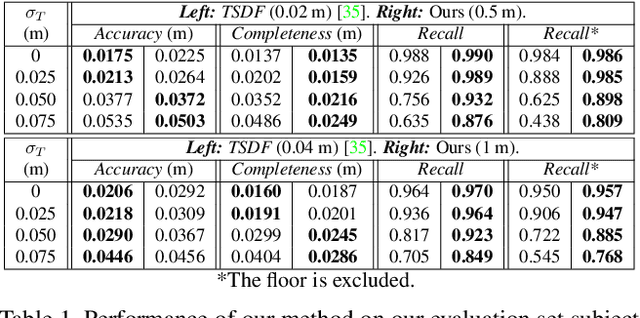
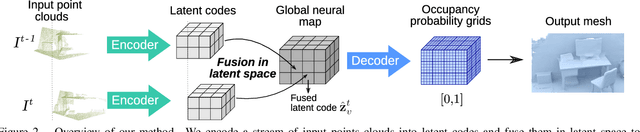

We present a novel 3D mapping method leveraging the recent progress in neural implicit representation for 3D reconstruction. Most existing state-of-the-art neural implicit representation methods are limited to object-level reconstructions and can not incrementally perform updates given new data. In this work, we propose a fusion strategy and training pipeline to incrementally build and update neural implicit representations that enable the reconstruction of large scenes from sequential partial observations. By representing an arbitrarily sized scene as a grid of latent codes and performing updates directly in latent space, we show that incrementally built occupancy maps can be obtained in real-time even on a CPU. Compared to traditional approaches such as Truncated Signed Distance Fields (TSDFs), our map representation is significantly more robust in yielding a better scene completeness given noisy inputs. We demonstrate the performance of our approach in thorough experimental validation on real-world datasets with varying degrees of added pose noise.
See Yourself in Others: Attending Multiple Tasks for Own Failure Detection
Oct 06, 2021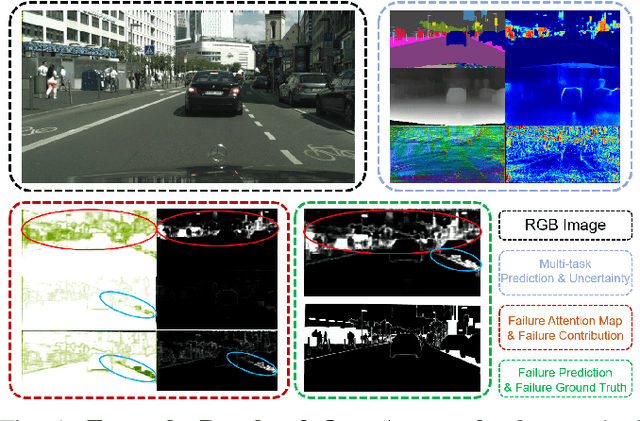
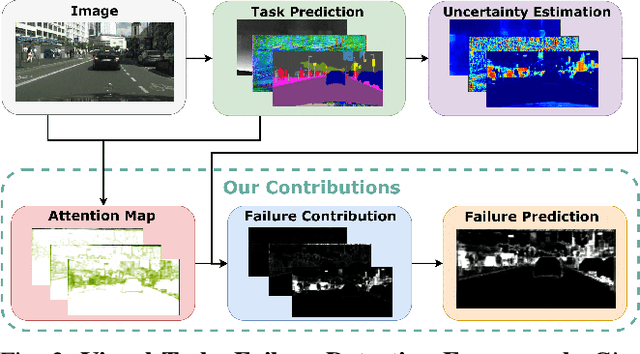
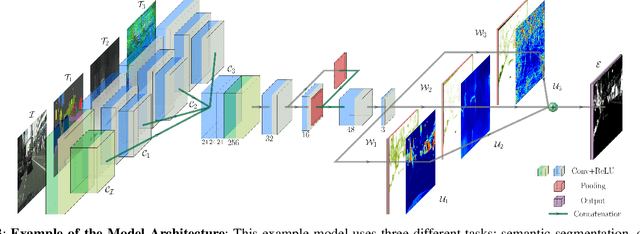
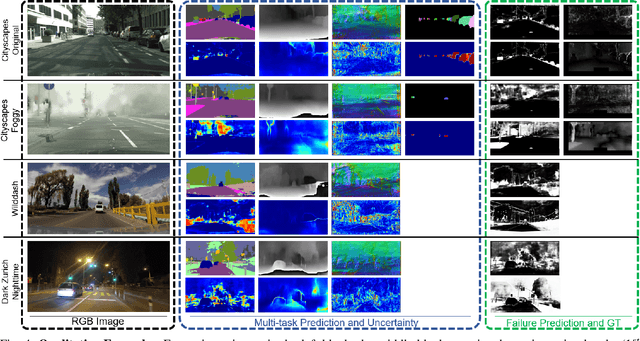
Autonomous robots deal with unexpected scenarios in real environments. Given input images, various visual perception tasks can be performed, e.g., semantic segmentation, depth estimation and normal estimation. These different tasks provide rich information for the whole robotic perception system. All tasks have their own characteristics while sharing some latent correlations. However, some of the task predictions may suffer from the unreliability dealing with complex scenes and anomalies. We propose an attention-based failure detection approach by exploiting the correlations among multiple tasks. The proposed framework infers task failures by evaluating the individual prediction, across multiple visual perception tasks for different regions in an image. The formulation of the evaluations is based on an attention network supervised by multi-task uncertainty estimation and their corresponding prediction errors. Our proposed framework generates more accurate estimations of the prediction error for the different task's predictions.
Panoptic Multi-TSDFs: a Flexible Representation for Online Multi-resolution Volumetric Mapping and Long-term Dynamic Scene Consistency
Sep 21, 2021

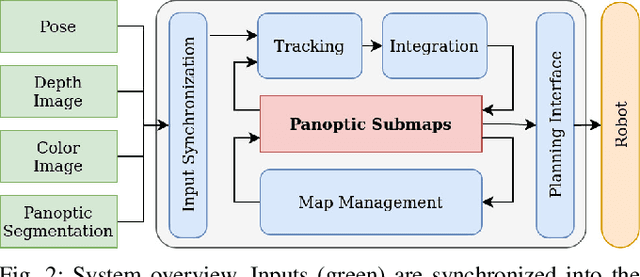
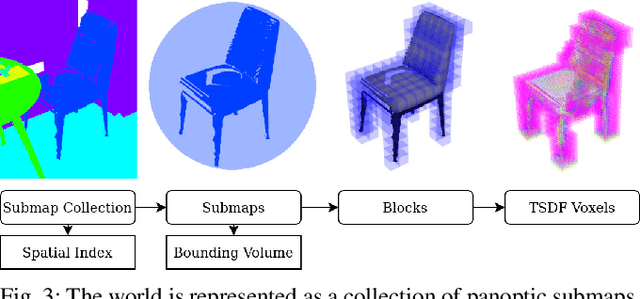
For robotic interaction in an environment shared with multiple agents, accessing a volumetric and semantic map of the scene is crucial. However, such environments are inevitably subject to long-term changes, which the map representation needs to account for.To this end, we propose panoptic multi-TSDFs, a novel representation for multi-resolution volumetric mapping over long periods of time. By leveraging high-level information for 3D reconstruction, our proposed system allocates high resolution only where needed. In addition, through reasoning on the object level, semantic consistency over time is achieved. This enables to maintain up-to-date reconstructions with high accuracy while improving coverage by incorporating and fusing previous data. We show in thorough experimental validations that our map representation can be efficiently constructed, maintained, and queried during online operation, and that the presented approach can operate robustly on real depth sensors using non-optimized panoptic segmentation as input.
Superquadric Object Representation for Optimization-based Semantic SLAM
Sep 20, 2021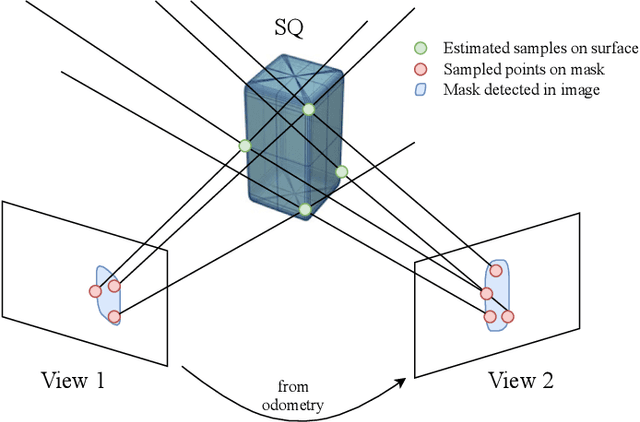
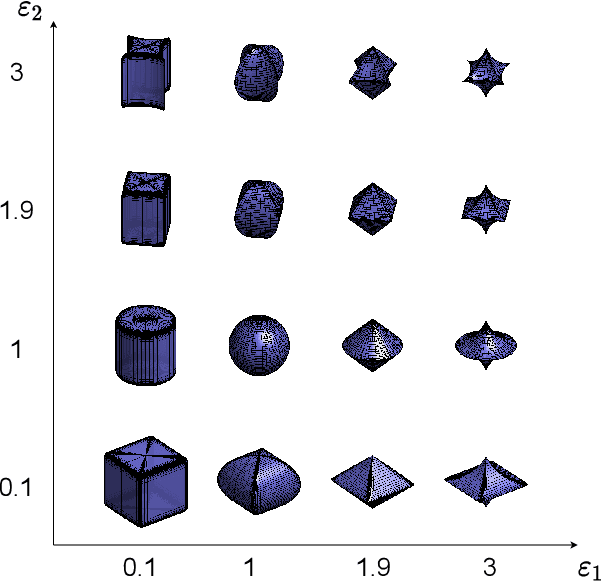
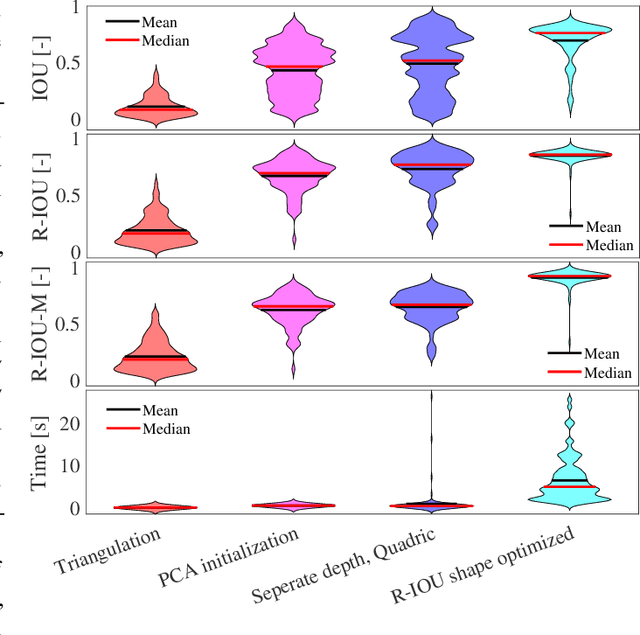
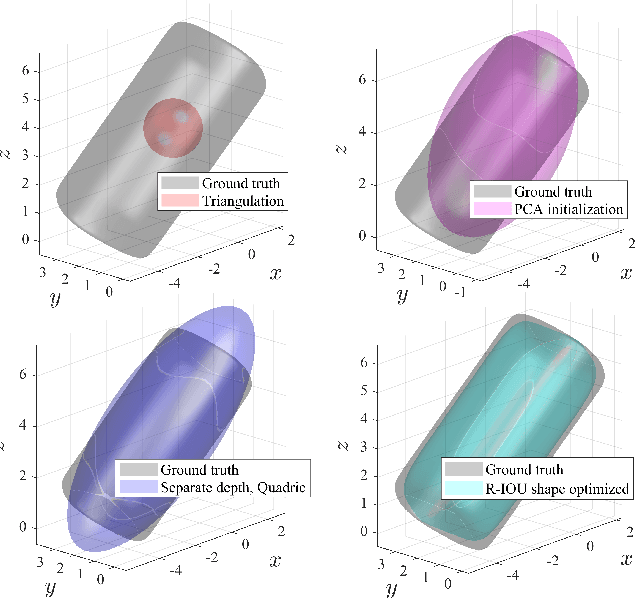
Introducing semantically meaningful objects to visual Simultaneous Localization And Mapping (SLAM) has the potential to improve both the accuracy and reliability of pose estimates, especially in challenging scenarios with significant view-point and appearance changes. However, how semantic objects should be represented for an efficient inclusion in optimization-based SLAM frameworks is still an open question. Superquadrics(SQs) are an efficient and compact object representation, able to represent most common object types to a high degree, and typically retrieved from 3D point-cloud data. However, accurate 3D point-cloud data might not be available in all applications. Recent advancements in machine learning enabled robust object recognition and semantic mask measurements from camera images under many different appearance conditions. We propose a pipeline to leverage such semantic mask measurements to fit SQ parameters to multi-view camera observations using a multi-stage initialization and optimization procedure. We demonstrate the system's ability to retrieve randomly generated SQ parameters from multi-view mask observations in preliminary simulation experiments and evaluate different initialization stages and cost functions.
Self-Improving Semantic Perception on a Construction Robot
May 04, 2021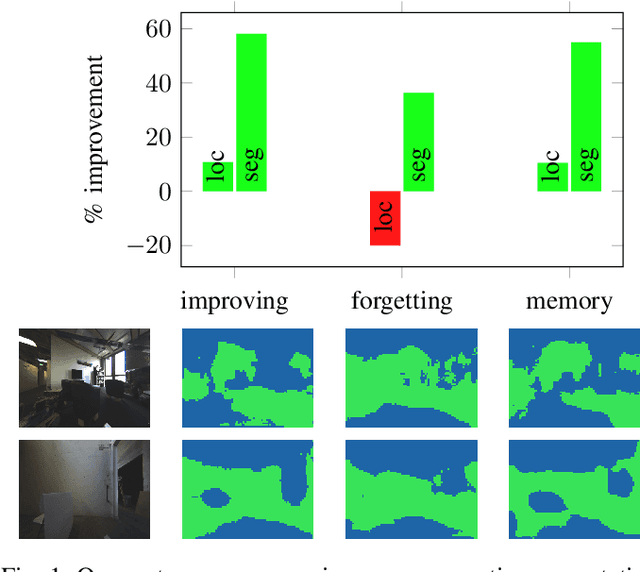
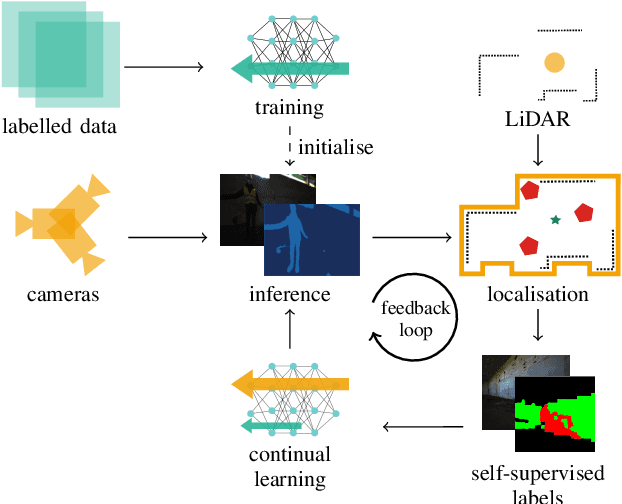
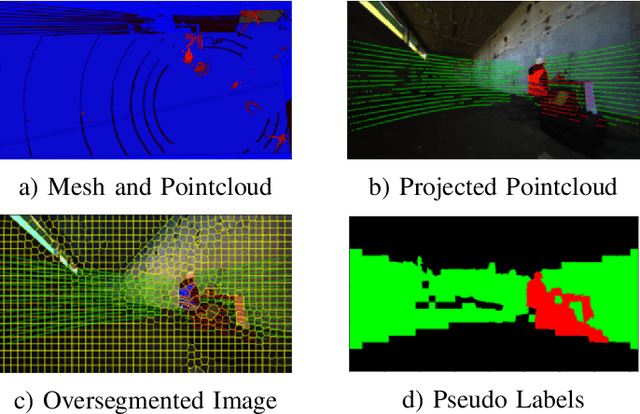

We propose a novel robotic system that can improve its semantic perception during deployment. Contrary to the established approach of learning semantics from large datasets and deploying fixed models, we propose a framework in which semantic models are continuously updated on the robot to adapt to the deployment environments. Our system therefore tightly couples multi-sensor perception and localisation to continuously learn from self-supervised pseudo labels. We study this system in the context of a construction robot registering LiDAR scans of cluttered environments against building models. Our experiments show how the robot's semantic perception improves during deployment and how this translates into improved 3D localisation by filtering the clutter out of the LiDAR scan, even across drastically different environments. We further study the risk of catastrophic forgetting that such a continuous learning setting poses. We find memory replay an effective measure to reduce forgetting and show how the robotic system can improve even when switching between different environments. On average, our system improves by 60% in segmentation and 10% in localisation compared to deployment of a fixed model, and it keeps this improvement up while adapting to further environments.
Spherical Multi-Modal Place Recognition for Heterogeneous Sensor Systems
Apr 17, 2021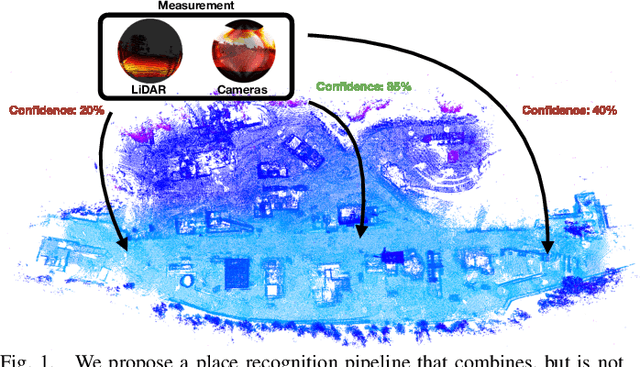
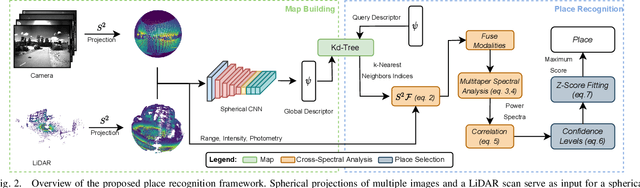
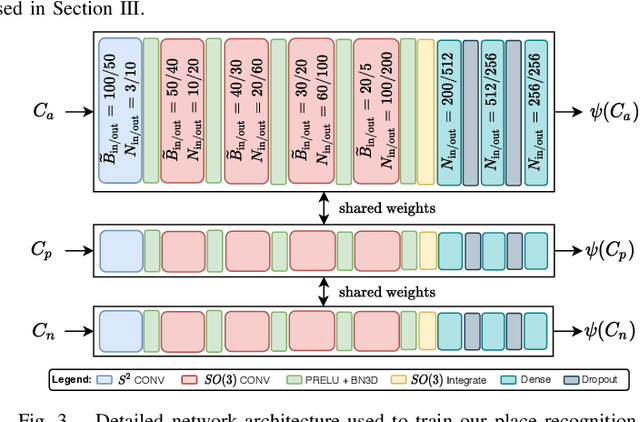
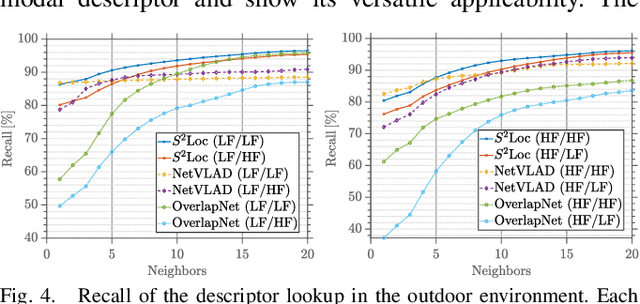
In this paper, we propose a robust end-to-end multi-modal pipeline for place recognition where the sensor systems can differ from the map building to the query. Our approach operates directly on images and LiDAR scans without requiring any local feature extraction modules. By projecting the sensor data onto the unit sphere, we learn a multi-modal descriptor of partially overlapping scenes using a spherical convolutional neural network. The employed spherical projection model enables the support of arbitrary LiDAR and camera systems readily without losing information. Loop closure candidates are found using a nearest-neighbor lookup in the embedding space. We tackle the problem of correctly identifying the closest place by correlating the candidates' power spectra, obtaining a confidence value per prospect. Our estimate for the correct place corresponds then to the candidate with the highest confidence. We evaluate our proposal w.r.t. state-of-the-art approaches in place recognition using real-world data acquired using different sensors. Our approach can achieve a recall that is up to 10% and 5% higher than for a LiDAR- and vision-based system, respectively, when the sensor setup differs between model training and deployment. Additionally, our place selection can correctly identify up to 95% matches from the candidate set.
CalQNet -- Detection of Calibration Quality for Life-Long Stereo Camera Setups
Apr 10, 2021
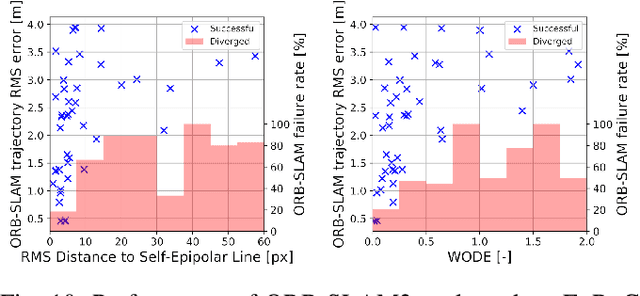

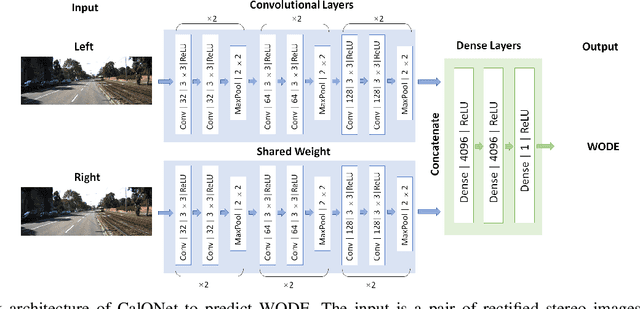
Many mobile robotic platforms rely on an accurate knowledge of the extrinsic calibration parameters, especially systems performing visual stereo matching. Although a number of accurate stereo camera calibration methods have been developed, which provide good initial "factory" calibrations, the determined parameters can lose their validity over time as the sensors are exposed to environmental conditions and external effects. Thus, on autonomous platforms on-board diagnostic methods for an early detection of the need to repeat calibration procedures have the potential to prevent critical failures of crucial systems, such as state estimation or obstacle detection. In this work, we present a novel data-driven method to estimate the calibration quality and detect discrepancies between the original calibration and the current system state for stereo camera systems. The framework consists of a novel dataset generation pipeline to train CalQNet, a deep convolutional neural network. CalQNet can estimate the calibration quality using a new metric that approximates the degree of miscalibration in stereo setups. We show the framework's ability to predict from a single stereo frame if a state-of-the-art stereo-visual odometry system will diverge due to a degraded calibration in two real-world experiments.
Pixel-wise Anomaly Detection in Complex Driving Scenes
Mar 09, 2021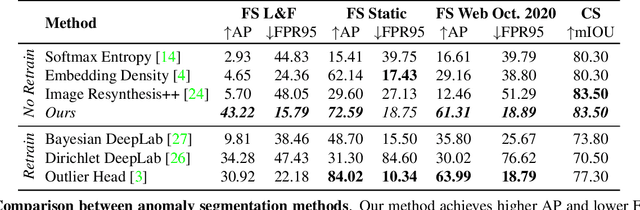
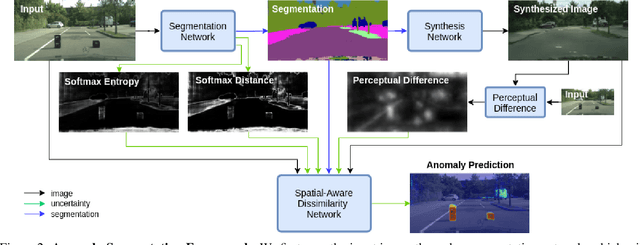
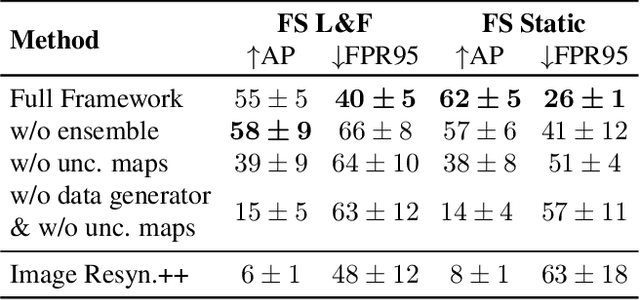
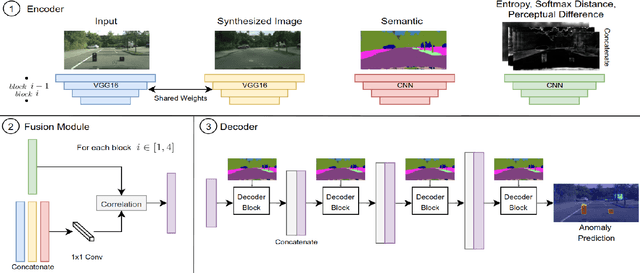
The inability of state-of-the-art semantic segmentation methods to detect anomaly instances hinders them from being deployed in safety-critical and complex applications, such as autonomous driving. Recent approaches have focused on either leveraging segmentation uncertainty to identify anomalous areas or re-synthesizing the image from the semantic label map to find dissimilarities with the input image. In this work, we demonstrate that these two methodologies contain complementary information and can be combined to produce robust predictions for anomaly segmentation. We present a pixel-wise anomaly detection framework that uses uncertainty maps to improve over existing re-synthesis methods in finding dissimilarities between the input and generated images. Our approach works as a general framework around already trained segmentation networks, which ensures anomaly detection without compromising segmentation accuracy, while significantly outperforming all similar methods. Top-2 performance across a range of different anomaly datasets shows the robustness of our approach to handling different anomaly instances.