 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic Segmentation
Apr 14, 2018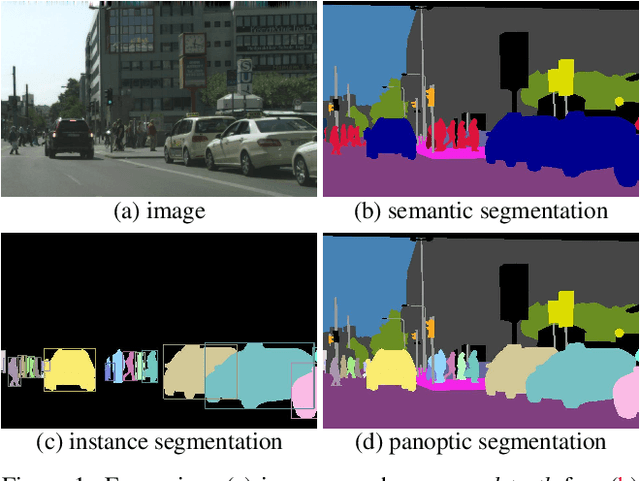
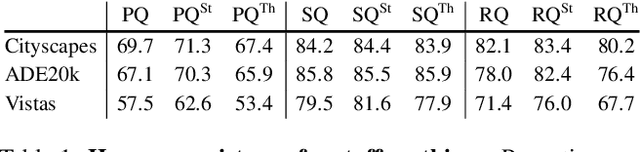
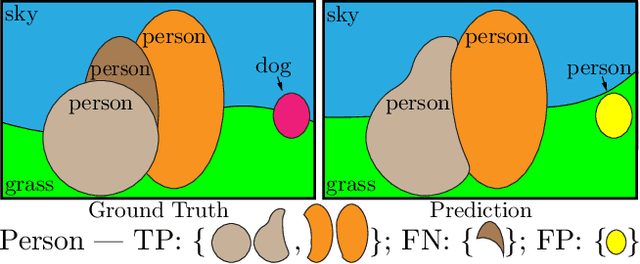

We propose and study a novel panoptic segmentation (PS) task. Panoptic segmentation unifies the typically distinct tasks of semantic segmentation (assign a class label to each pixel) and instance segmentation (detect and segment each object instance). The proposed task requires generating a coherent scene segmentation that is rich and complete, an important step toward real-world vision systems. While early work in computer vision addressed related image/scene parsing tasks, these are not currently popular, possibly due to lack of appropriate metrics or associated recognition challenges. To address this, we first propose a novel panoptic quality (PQ) metric that captures performance for all classes (stuff and things) in an interpretable and unified manner. Using the proposed metric, we perform a rigorous study of both human and machine performance for PS on three existing datasets, revealing interesting insights about the task. Second, we are working to introduce panoptic segmentation tracks at upcoming recognition challenges. The aim of our work is to revive the interest of the community in a more unified view of image segmentation.
Learning Less is More - 6D Camera Localization via 3D Surface Regression
Mar 27, 2018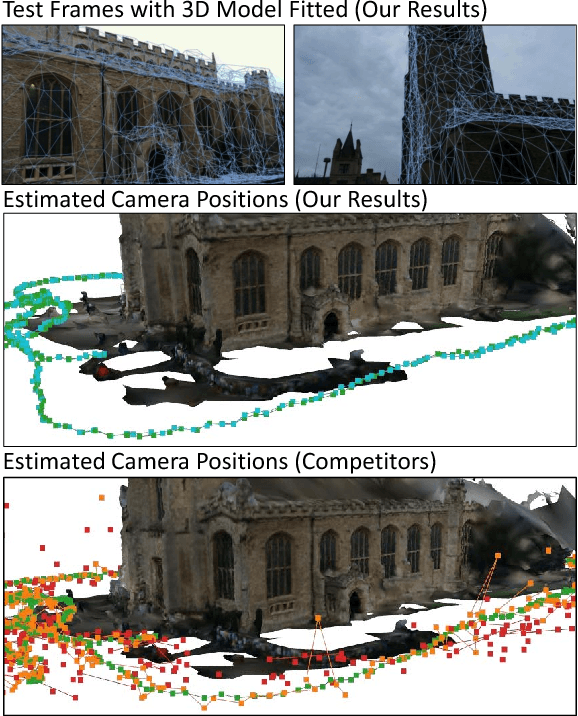
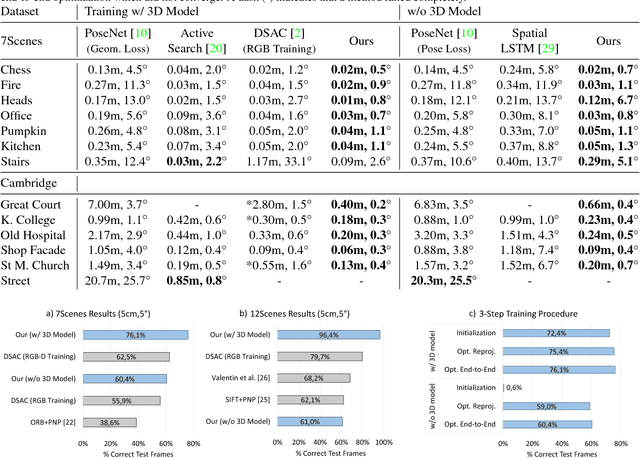
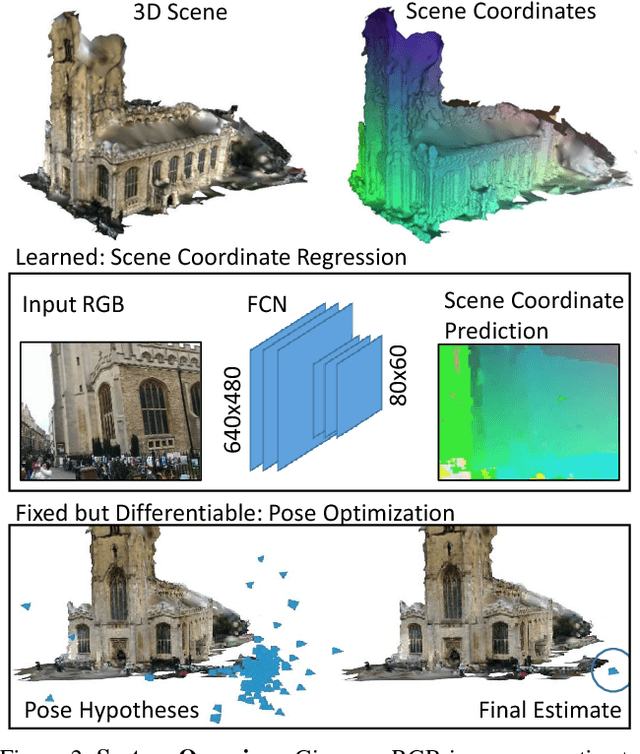

Popular research areas like autonomous driving and augmented reality have renewed the interest in image-based camera localization. In this work, we address the task of predicting the 6D camera pose from a single RGB image in a given 3D environment. With the advent of neural networks, previous works have either learned the entire camera localization process, or multiple components of a camera localization pipeline. Our key contribution is to demonstrate and explain that learning a single component of this pipeline is sufficient. This component is a fully convolutional neural network for densely regressing so-called scene coordinates, defining the correspondence between the input image and the 3D scene space. The neural network is prepended to a new end-to-end trainable pipeline. Our system is efficient, highly accurate, robust in training, and exhibits outstanding generalization capabilities. It exceeds state-of-the-art consistently on indoor and outdoor datasets. Interestingly, our approach surpasses existing techniques even without utilizing a 3D model of the scene during training, since the network is able to discover 3D scene geometry automatically, solely from single-view constraints.
DSAC - Differentiable RANSAC for Camera Localization
Mar 21, 2018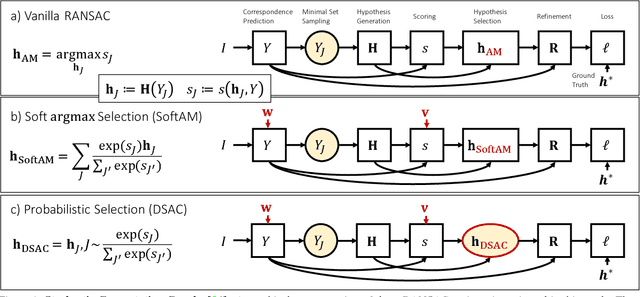
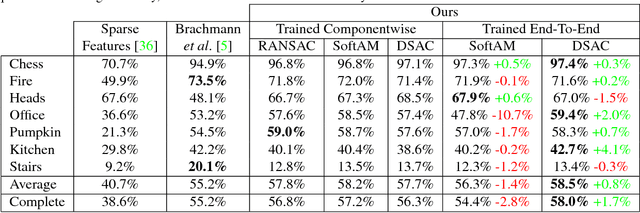

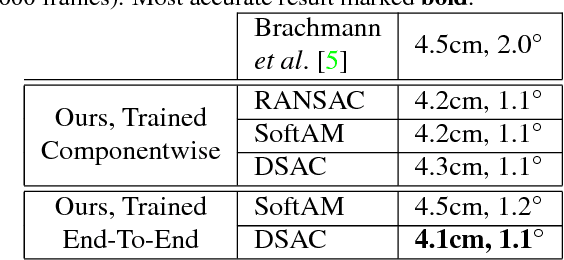
RANSAC is an important algorithm in robust optimization and a central building block for many computer vision applications. In recent years, traditionally hand-crafted pipelines have been replaced by deep learning pipelines, which can be trained in an end-to-end fashion. However, RANSAC has so far not been used as part of such deep learning pipelines, because its hypothesis selection procedure is non-differentiable. In this work, we present two different ways to overcome this limitation. The most promising approach is inspired by reinforcement learning, namely to replace the deterministic hypothesis selection by a probabilistic selection for which we can derive the expected loss w.r.t. to all learnable parameters. We call this approach DSAC, the differentiable counterpart of RANSAC. We apply DSAC to the problem of camera localization, where deep learning has so far failed to improve on traditional approaches. We demonstrate that by directly minimizing the expected loss of the output camera poses, robustly estimated by RANSAC, we achieve an increase in accuracy. In the future, any deep learning pipeline can use DSAC as a robust optimization component.
Augmented Reality Meets Computer Vision : Efficient Data Generation for Urban Driving Scenes
Aug 04, 2017



The success of deep learning in computer vision is based on availability of large annotated datasets. To lower the need for hand labeled images, virtually rendered 3D worlds have recently gained popularity. Creating realistic 3D content is challenging on its own and requires significant human effort. In this work, we propose an alternative paradigm which combines real and synthetic data for learning semantic instance segmentation and object detection models. Exploiting the fact that not all aspects of the scene are equally important for this task, we propose to augment real-world imagery with virtual objects of the target category. Capturing real-world images at large scale is easy and cheap, and directly provides real background appearances without the need for creating complex 3D models of the environment. We present an efficient procedure to augment real images with virtual objects. This allows us to create realistic composite images which exhibit both realistic background appearance and a large number of complex object arrangements. In contrast to modeling complete 3D environments, our augmentation approach requires only a few user interactions in combination with 3D shapes of the target object. Through extensive experimentation, we conclude the right set of parameters to produce augmented data which can maximally enhance the performance of instance segmentation models. Further, we demonstrate the utility of our approach on training standard deep models for semantic instance segmentation and object detection of cars in outdoor driving scenes. We test the models trained on our augmented data on the KITTI 2015 dataset, which we have annotated with pixel-accurate ground truth, and on Cityscapes dataset. Our experiments demonstrate that models trained on augmented imagery generalize better than those trained on synthetic data or models trained on limited amount of annotated real data.
Random Forests versus Neural Networks - What's Best for Camera Localization?
Jul 13, 2017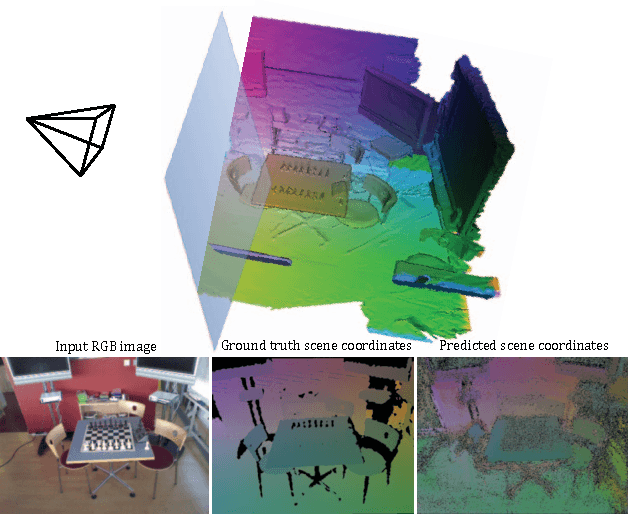
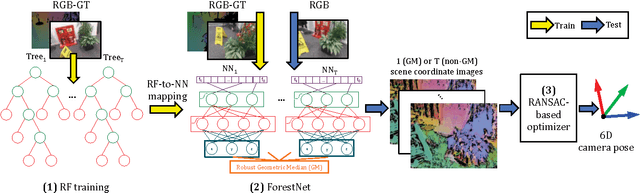
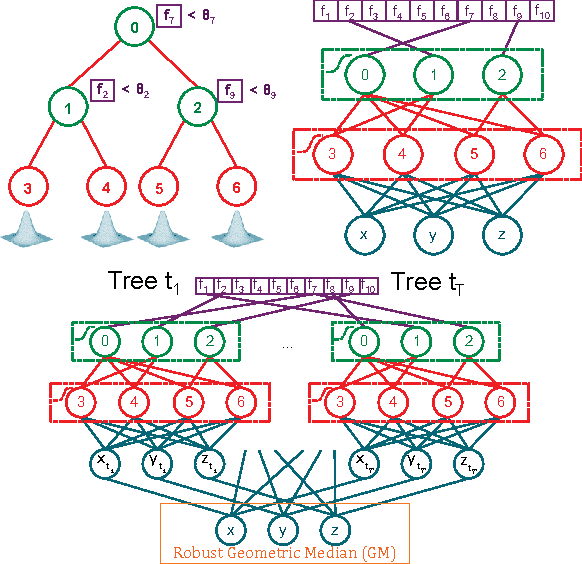
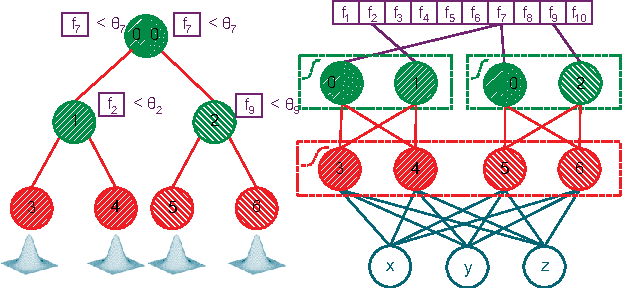
This work addresses the task of camera localization in a known 3D scene given a single input RGB image. State-of-the-art approaches accomplish this in two steps: firstly, regressing for every pixel in the image its 3D scene coordinate and subsequently, using these coordinates to estimate the final 6D camera pose via RANSAC. To solve the first step, Random Forests (RFs) are typically used. On the other hand, Neural Networks (NNs) reign in many dense regression tasks, but are not test-time efficient. We ask the question: which of the two is best for camera localization? To address this, we make two method contributions: (1) a test-time efficient NN architecture which we term a ForestNet that is derived and initialized from a RF, and (2) a new fully-differentiable robust averaging technique for regression ensembles which can be trained end-to-end with a NN. Our experimental findings show that for scene coordinate regression, traditional NN architectures are superior to test-time efficient RFs and ForestNets, however, this does not translate to final 6D camera pose accuracy where RFs and ForestNets perform slightly better. To summarize, our best method, a ForestNet with a robust average, which has an equivalent fast and lightweight RF, improves over the state-of-the-art for camera localization on the 7-Scenes dataset. While this work focuses on scene coordinate regression for camera localization, our innovations may also be applied to other continuous regression tasks.
PoseAgent: Budget-Constrained 6D Object Pose Estimation via Reinforcement Learning
Apr 11, 2017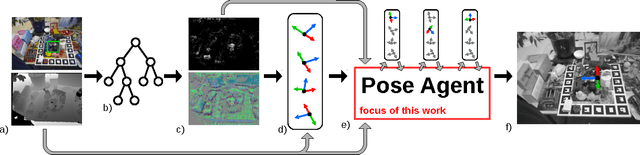
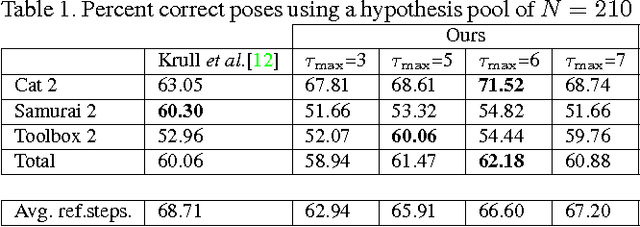
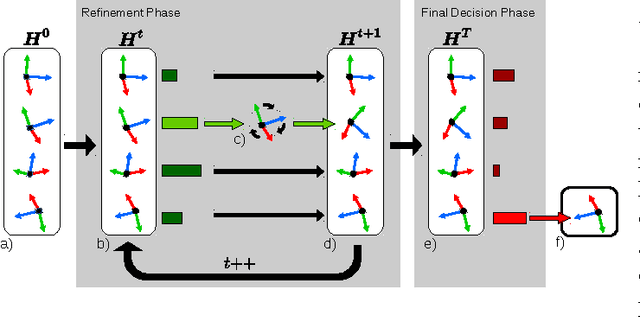
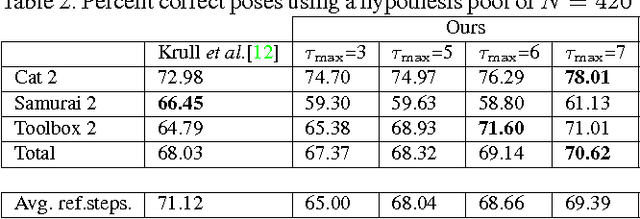
State-of-the-art computer vision algorithms often achieve efficiency by making discrete choices about which hypotheses to explore next. This allows allocation of computational resources to promising candidates, however, such decisions are non-differentiable. As a result, these algorithms are hard to train in an end-to-end fashion. In this work we propose to learn an efficient algorithm for the task of 6D object pose estimation. Our system optimizes the parameters of an existing state-of-the art pose estimation system using reinforcement learning, where the pose estimation system now becomes the stochastic policy, parametrized by a CNN. Additionally, we present an efficient training algorithm that dramatically reduces computation time. We show empirically that our learned pose estimation procedure makes better use of limited resources and improves upon the state-of-the-art on a challenging dataset. Our approach enables differentiable end-to-end training of complex algorithmic pipelines and learns to make optimal use of a given computational budget.
Analyzing Modular CNN Architectures for Joint Depth Prediction and Semantic Segmentation
Feb 26, 2017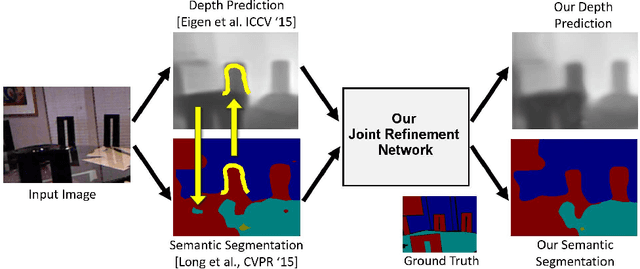
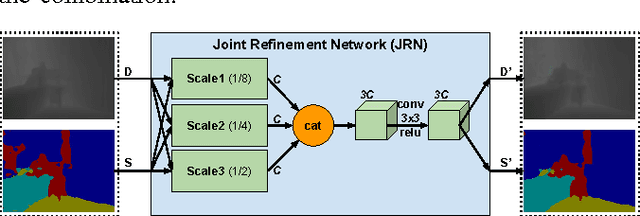
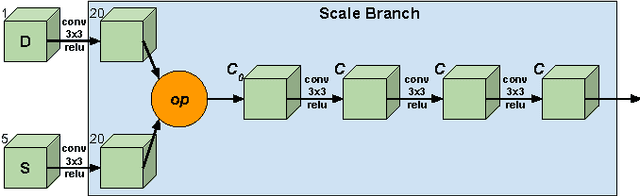
This paper addresses the task of designing a modular neural network architecture that jointly solves different tasks. As an example we use the tasks of depth estimation and semantic segmentation given a single RGB image. The main focus of this work is to analyze the cross-modality influence between depth and semantic prediction maps on their joint refinement. While most previous works solely focus on measuring improvements in accuracy, we propose a way to quantify the cross-modality influence. We show that there is a relationship between final accuracy and cross-modality influence, although not a simple linear one. Hence a larger cross-modality influence does not necessarily translate into an improved accuracy. We find that a beneficial balance between the cross-modality influences can be achieved by network architecture and conjecture that this relationship can be utilized to understand different network design choices. Towards this end we propose a Convolutional Neural Network (CNN) architecture that fuses the state of the state-of-the-art results for depth estimation and semantic labeling. By balancing the cross-modality influences between depth and semantic prediction, we achieve improved results for both tasks using the NYU-Depth v2 benchmark.
Crowd Sourcing Image Segmentation with iaSTAPLE
Feb 21, 2017
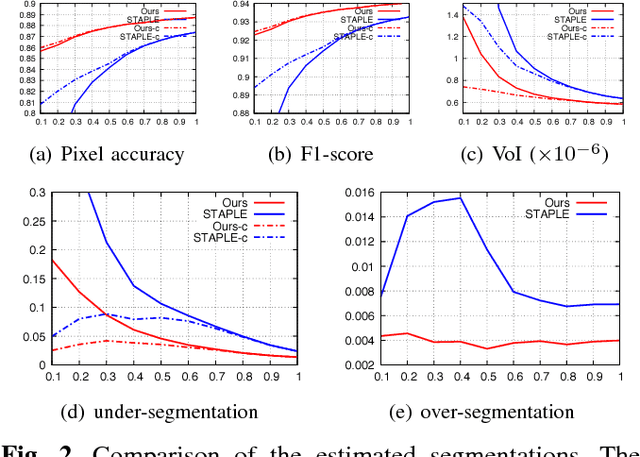

We propose a novel label fusion technique as well as a crowdsourcing protocol to efficiently obtain accurate epithelial cell segmentations from non-expert crowd workers. Our label fusion technique simultaneously estimates the true segmentation, the performance levels of individual crowd workers, and an image segmentation model in the form of a pairwise Markov random field. We term our approach image-aware STAPLE (iaSTAPLE) since our image segmentation model seamlessly integrates into the well-known and widely used STAPLE approach. In an evaluation on a light microscopy dataset containing more than 5000 membrane labeled epithelial cells of a fly wing, we show that iaSTAPLE outperforms STAPLE in terms of segmentation accuracy as well as in terms of the accuracy of estimated crowd worker performance levels, and is able to correctly segment 99% of all cells when compared to expert segmentations. These results show that iaSTAPLE is a highly useful tool for crowd sourcing image segmentation.
Joint Graph Decomposition and Node Labeling: Problem, Algorithms, Applications
Feb 21, 2017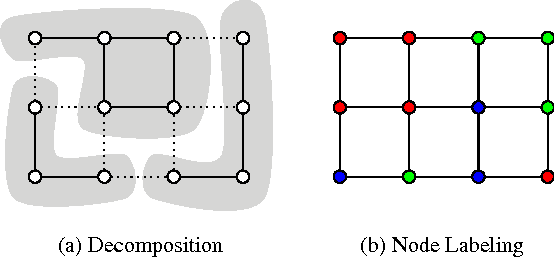
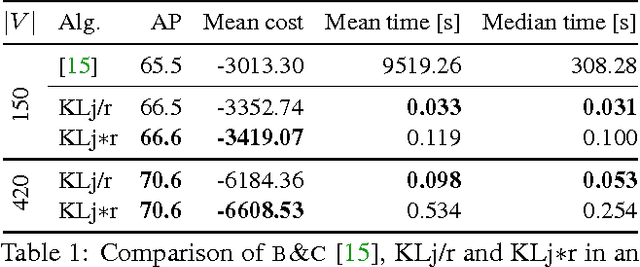
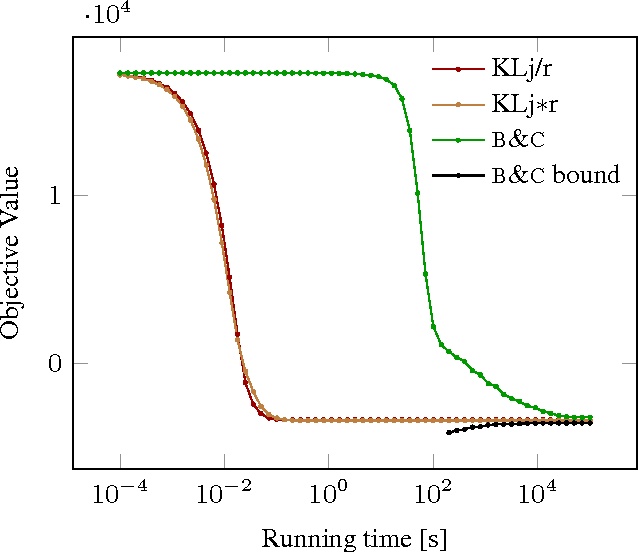
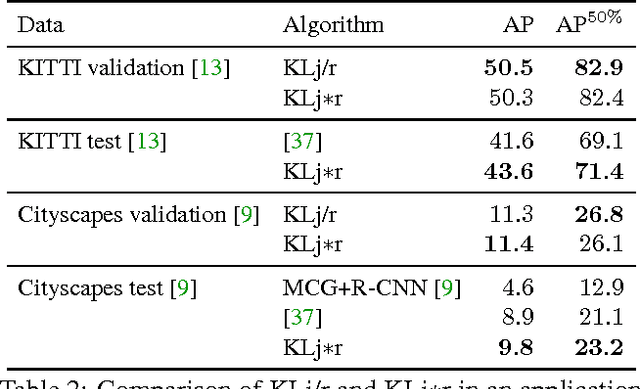
We state a combinatorial optimization problem whose feasible solutions define both a decomposition and a node labeling of a given graph. This problem offers a common mathematical abstraction of seemingly unrelated computer vision tasks, including instance-separating semantic segmentation, articulated human body pose estimation and multiple object tracking. Conceptually, the problem we state generalizes the unconstrained integer quadratic program and the minimum cost lifted multicut problem, both of which are NP-hard. In order to find feasible solutions efficiently, we define two local search algorithms that converge monotonously to a local optimum, offering a feasible solution at any time. To demonstrate their effectiveness in tackling computer vision tasks, we apply these algorithms to instances of the problem that we construct from published data, using published algorithms. We report state-of-the-art application-specific accuracy for the three above-mentioned applications.
A Study of Lagrangean Decompositions and Dual Ascent Solvers for Graph Matching
Jan 12, 2017
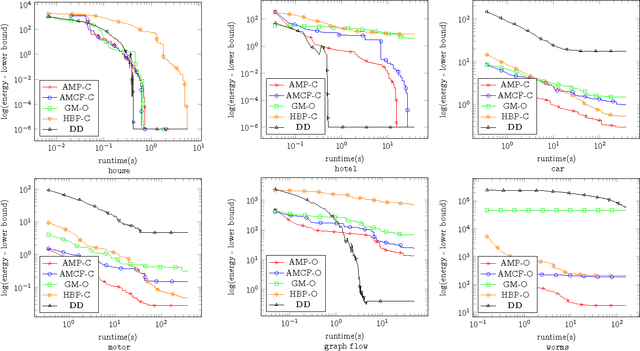
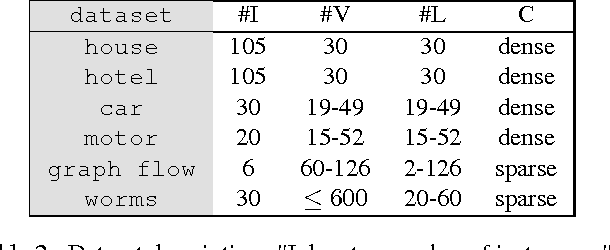
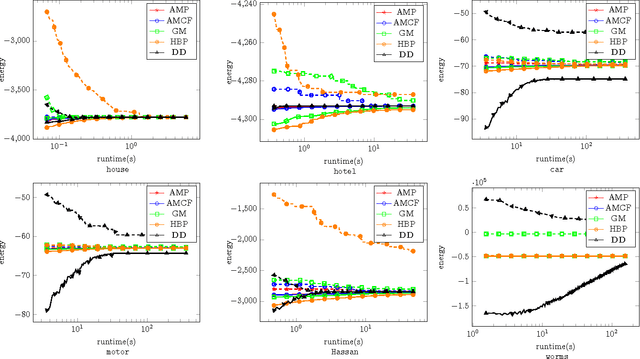
We study the quadratic assignment problem, in computer vision also known as graph matching. Two leading solvers for this problem optimize the Lagrange decomposition duals with sub-gradient and dual ascent (also known as message passing) updates. We explore s direction further and propose several additional Lagrangean relaxations of the graph matching problem along with corresponding algorithms, which are all based on a common dual ascent framework. Our extensive empirical evaluation gives several theoretical insights and suggests a new state-of-the-art any-time solver for the considered problem. Our improvement over state-of-the-art is particularly visible on a new dataset with large-scale sparse problem instances containing more than 500 graph nodes each.