 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering Sign Bits of DCT Coefficients in Digital Images as an Optimization Problem
Nov 02, 2022Recovering unknown, missing, damaged, distorted or lost information in DCT coefficients is a common task in multiple applications of digital image processing, including image compression, selective image encryption, and image communications. This paper investigates recovery of a special type of information in DCT coefficients of digital images: sign bits. This problem can be modelled as a mixed integer linear programming (MILP) problem, which is NP-hard in general. To efficiently solve the problem, we propose two approximation methods: 1) a relaxation-based method that convert the MILP problem to a linear programming (LP) problem; 2) a divide-and-conquer method which splits the target image into sufficiently small regions, each of which can be more efficiently solved as an MILP problem, and then conducts a global optimization phase as a smaller MILP problem or an LP problem to maximize smoothness across different regions. To the best of our knowledge, we are the first who considered how to use global optimization to recover sign bits of DCT coefficients. We considered how the proposed methods can be applied to JPEG-encoded images and conducted extensive experiments to validate the performances of our proposed methods. The experimental results showed that the proposed methods worked well, especially when the number of unknown sign bits per DCT block is not too large. Compared with other existing methods, which are all based on simple error-concealment strategies, our proposed methods outperformed them with a substantial margin, both according to objective quality metrics (PSNR and SSIM) and also our subjective evaluation. Our work has a number of profound implications, e.g., more sign bits can be discarded to develop more efficient image compression methods, and image encryption methods based on sign bit encryption can be less secure than we previously understood.
GENHOP: An Image Generation Method Based on Successive Subspace Learning
Oct 07, 2022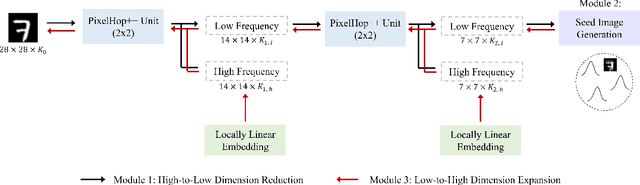
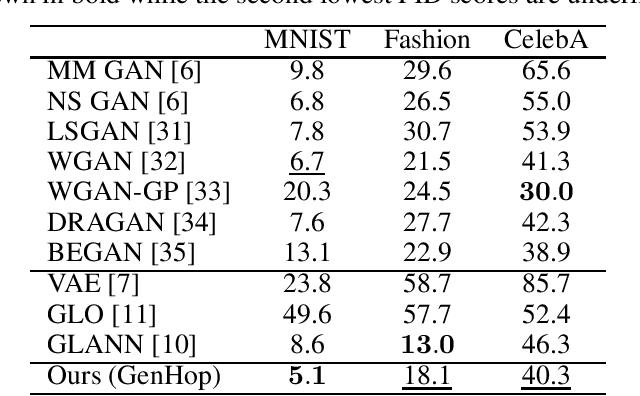
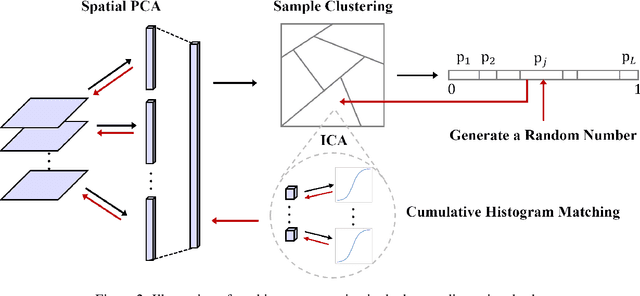
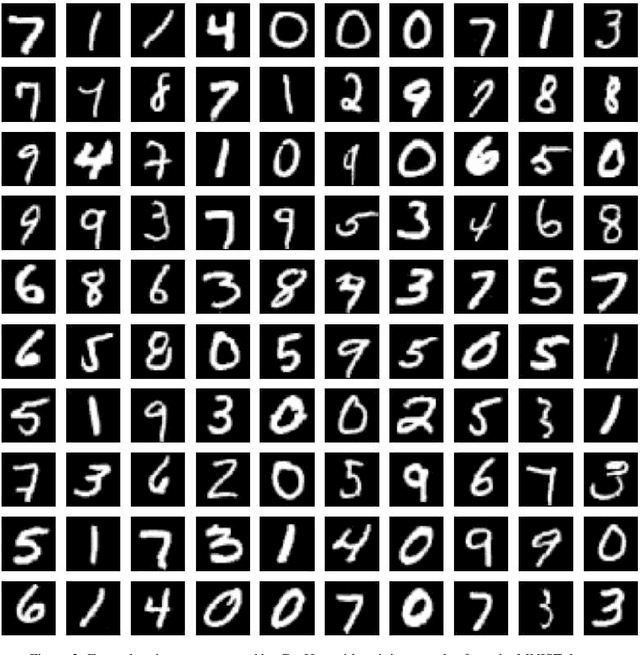
Being different from deep-learning-based (DL-based) image generation methods, a new image generative model built upon successive subspace learning principle is proposed and named GenHop (an acronym of Generative PixelHop) in this work. GenHop consists of three modules: 1) high-to-low dimension reduction, 2) seed image generation, and 3) low-to-high dimension expansion. In the first module, it builds a sequence of high-to-low dimensional subspaces through a sequence of whitening processes, each of which contains samples of joint-spatial-spectral representation. In the second module, it generates samples in the lowest dimensional subspace. In the third module, it finds a proper high-dimensional sample for a seed image by adding details back via locally linear embedding (LLE) and a sequence of coloring processes. Experiments show that GenHop can generate visually pleasant images whose FID scores are comparable or even better than those of DL-based generative models for MNIST, Fashion-MNIST and CelebA datasets.
Green Learning: Introduction, Examples and Outlook
Oct 03, 2022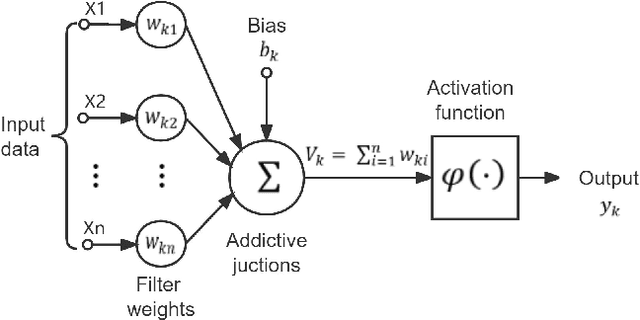
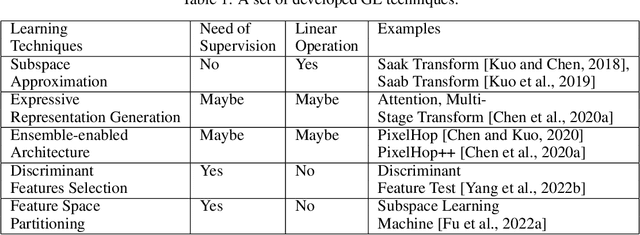

Rapid advances in artificial intelligence (AI) in the last decade have largely been built upon the wide applications of deep learning (DL). However, the high carbon footprint yielded by larger and larger DL networks becomes a concern for sustainability. Furthermore, DL decision mechanism is somewhat obsecure and can only be verified by test data. Green learning (GL) has been proposed as an alternative paradigm to address these concerns. GL is characterized by low carbon footprints, small model sizes, low computational complexity, and logical transparency. It offers energy-effective solutions in cloud centers as well as mobile/edge devices. GL also provides a clear and logical decision-making process to gain people's trust. Several statistical tools have been developed to achieve this goal in recent years. They include subspace approximation, unsupervised and supervised representation learning, supervised discriminant feature selection, and feature space partitioning. We have seen a few successful GL examples with performance comparable with state-of-the-art DL solutions. This paper offers an introduction to GL, its demonstrated applications, and future outlook.
Lightweight Image Codec via Multi-Grid Multi-Block-Size Vector Quantization
Sep 25, 2022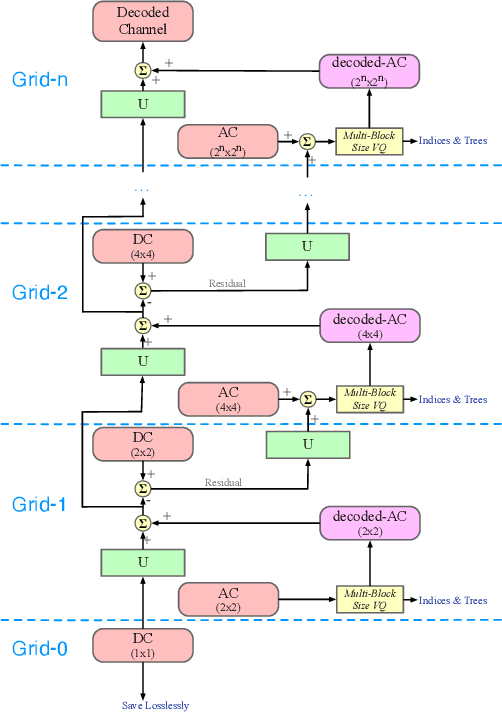
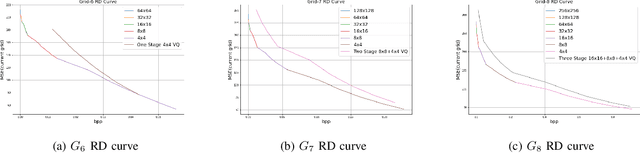


A multi-grid multi-block-size vector quantization (MGBVQ) method is proposed for image coding in this work. The fundamental idea of image coding is to remove correlations among pixels before quantization and entropy coding, e.g., the discrete cosine transform (DCT) and intra predictions, adopted by modern image coding standards. We present a new method to remove pixel correlations. First, by decomposing correlations into long- and short-range correlations, we represent long-range correlations in coarser grids due to their smoothness, thus leading to a multi-grid (MG) coding architecture. Second, we show that short-range correlations can be effectively coded by a suite of vector quantizers (VQs). Along this line, we argue the effectiveness of VQs of very large block sizes and present a convenient way to implement them. It is shown by experimental results that MGBVQ offers excellent rate-distortion (RD) performance, which is comparable with existing image coders, at much lower complexity. Besides, it provides a progressive coded bitstream.
MAGIC: Mask-Guided Image Synthesis by Inverting a Quasi-Robust Classifier
Sep 23, 2022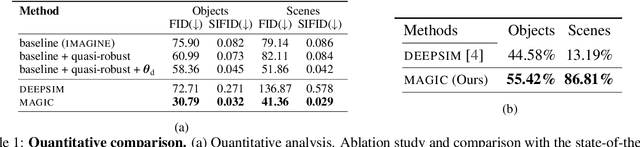
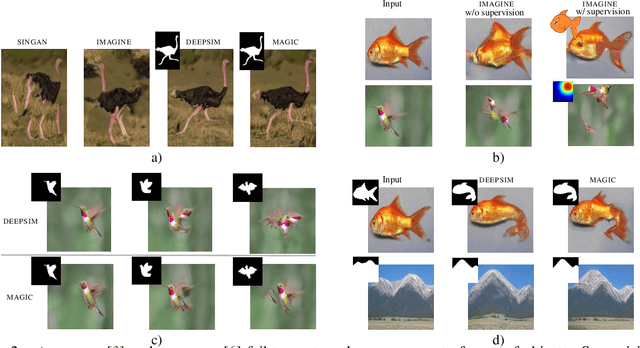
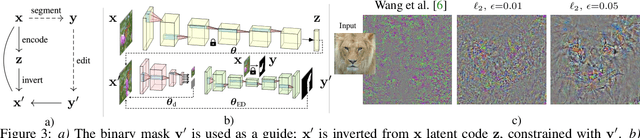
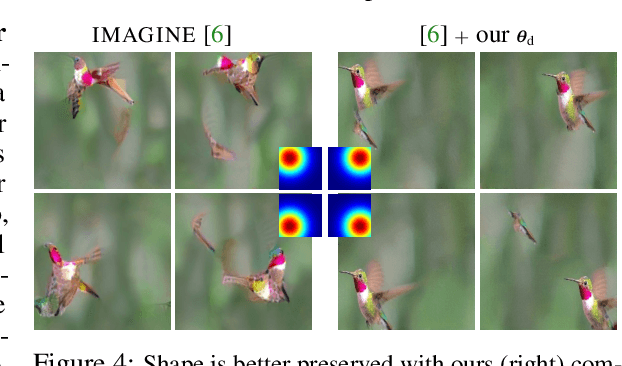
We offer a method for one-shot image synthesis that allows controlling manipulations of a single image by inverting a quasi-robust classifier equipped with strong regularizers. Our proposed method, entitled Magic, samples structured gradients from a pre-trained quasi-robust classifier to better preserve the input semantics while preserving its classification accuracy, thereby guaranteeing credibility in the synthesis. Unlike current methods that use complex primitives to supervise the process or use attention maps as a weak supervisory signal, Magic aggregates gradients over the input, driven by a guide binary mask that enforces a strong, spatial prior. Magic implements a series of manipulations with a single framework achieving shape and location control, intense non-rigid shape deformations, and copy/move operations in the presence of repeating objects and gives users firm control over the synthesis by requiring simply specifying binary guide masks. Our study and findings are supported by various qualitative comparisons with the state-of-the-art on the same images sampled from ImageNet and quantitative analysis using machine perception along with a user survey of 100+ participants that endorse our synthesis quality.
GreenKGC: A Lightweight Knowledge Graph Completion Method
Aug 19, 2022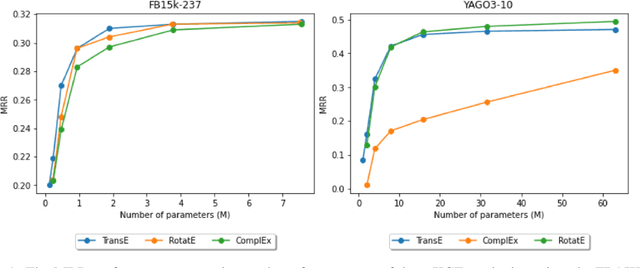
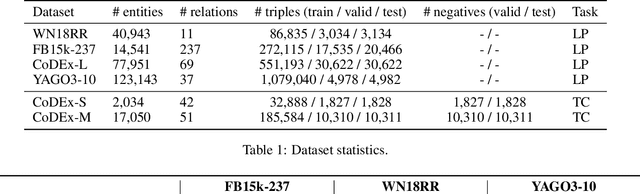
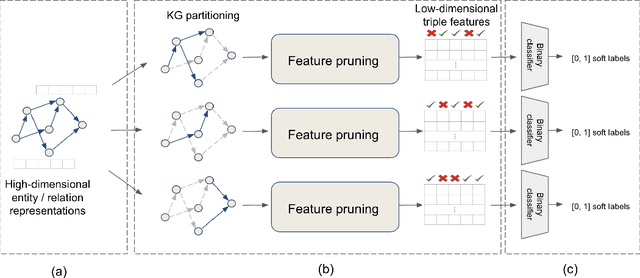
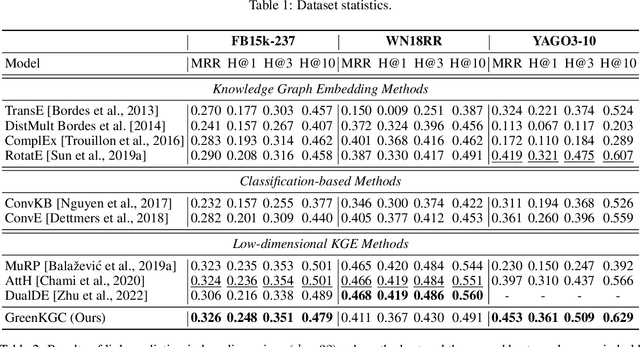
Knowledge graph completion (KGC) aims to discover missing relationships between entities in knowledge graphs (KGs). Most prior KGC work focuses on learning representations for entities and relations. Yet, a higher-dimensional embedding space is usually required for a better reasoning capability, which leads to a larger model size and hinders applicability to real-world problems (e.g., large-scale KGs or mobile/edge computing). A lightweight modularized KGC solution, called GreenKGC, is proposed in this work to address this issue. GreenKGC consists of three modules: 1) representation learning, 2) feature pruning, and 3) decision learning. In Module 1, we leverage existing KG embedding models to learn high-dimensional representations for entities and relations. In Module 2, the KG is partitioned into several relation groups followed by a feature pruning process to find the most discriminant features for each relation group. Finally, a classifier is assigned to each relation group to cope with low-dimensional triple features for KGC tasks in Module 3. We evaluate the performance of GreenKGC on four widely used link prediction datasets and observe that GreenKGC can achieve comparable or even better performance against original high-dimensional embeddings with a much smaller model size. Furthermore, we experiment on two triple classification datasets to demonstrate that the same methodology can generalize to more tasks.
Unsupervised Domain Adaptation for Segmentation with Black-box Source Model
Aug 16, 2022Unsupervised domain adaptation (UDA) has been widely used to transfer knowledge from a labeled source domain to an unlabeled target domain to counter the difficulty of labeling in a new domain. The training of conventional solutions usually relies on the existence of both source and target domain data. However, privacy of the large-scale and well-labeled data in the source domain and trained model parameters can become the major concern of cross center/domain collaborations. In this work, to address this, we propose a practical solution to UDA for segmentation with a black-box segmentation model trained in the source domain only, rather than original source data or a white-box source model. Specifically, we resort to a knowledge distillation scheme with exponential mixup decay (EMD) to gradually learn target-specific representations. In addition, unsupervised entropy minimization is further applied to regularization of the target domain confidence. We evaluated our framework on the BraTS 2018 database, achieving performance on par with white-box source model adaptation approaches.
Subtype-Aware Dynamic Unsupervised Domain Adaptation
Aug 16, 2022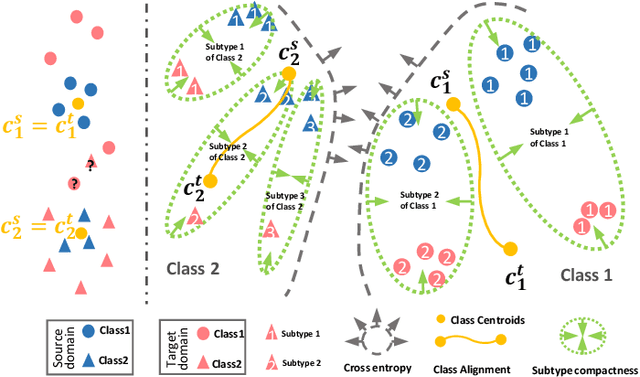
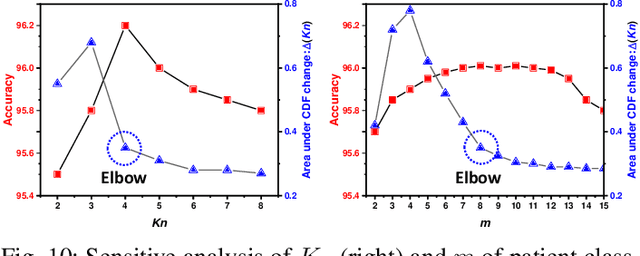
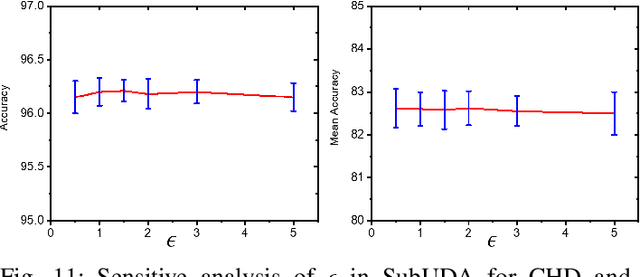
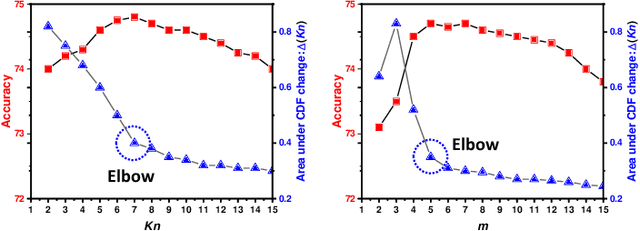
Unsupervised domain adaptation (UDA) has been successfully applied to transfer knowledge from a labeled source domain to target domains without their labels. Recently introduced transferable prototypical networks (TPN) further addresses class-wise conditional alignment. In TPN, while the closeness of class centers between source and target domains is explicitly enforced in a latent space, the underlying fine-grained subtype structure and the cross-domain within-class compactness have not been fully investigated. To counter this, we propose a new approach to adaptively perform a fine-grained subtype-aware alignment to improve performance in the target domain without the subtype label in both domains. The insight of our approach is that the unlabeled subtypes in a class have the local proximity within a subtype, while exhibiting disparate characteristics, because of different conditional and label shifts. Specifically, we propose to simultaneously enforce subtype-wise compactness and class-wise separation, by utilizing intermediate pseudo-labels. In addition, we systematically investigate various scenarios with and without prior knowledge of subtype numbers, and propose to exploit the underlying subtype structure. Furthermore, a dynamic queue framework is developed to evolve the subtype cluster centroids steadily using an alternative processing scheme. Experimental results, carried out with multi-view congenital heart disease data and VisDA and DomainNet, show the effectiveness and validity of our subtype-aware UDA, compared with state-of-the-art UDA methods.
Acceleration of Subspace Learning Machine via Particle Swarm Optimization and Parallel Processing
Aug 15, 2022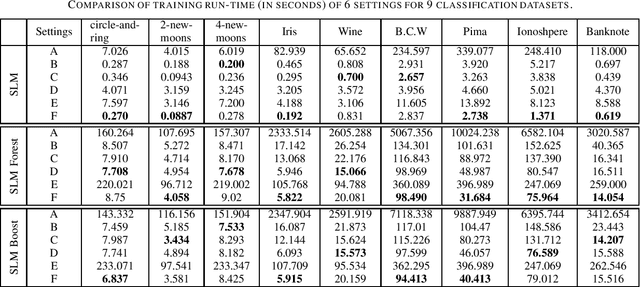
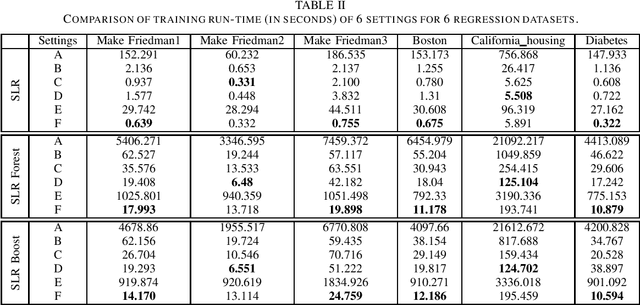


Built upon the decision tree (DT) classification and regression idea, the subspace learning machine (SLM) has been recently proposed to offer higher performance in general classification and regression tasks. Its performance improvement is reached at the expense of higher computational complexity. In this work, we investigate two ways to accelerate SLM. First, we adopt the particle swarm optimization (PSO) algorithm to speed up the search of a discriminant dimension that is expressed as a linear combination of current dimensions. The search of optimal weights in the linear combination is computationally heavy. It is accomplished by probabilistic search in original SLM. The acceleration of SLM by PSO requires 10-20 times fewer iterations. Second, we leverage parallel processing in the SLM implementation. Experimental results show that the accelerated SLM method achieves a speed up factor of 577 in training time while maintaining comparable classification/regression performance of original SLM.
Human Decision Makings on Curriculum Reinforcement Learning with Difficulty Adjustment
Aug 04, 2022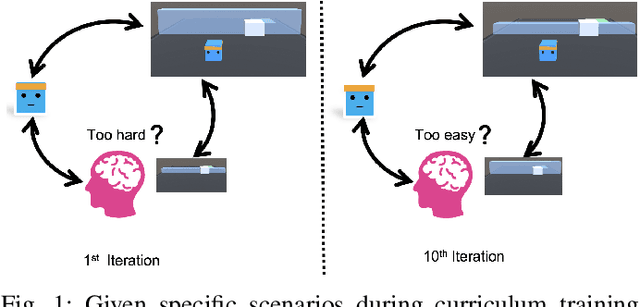
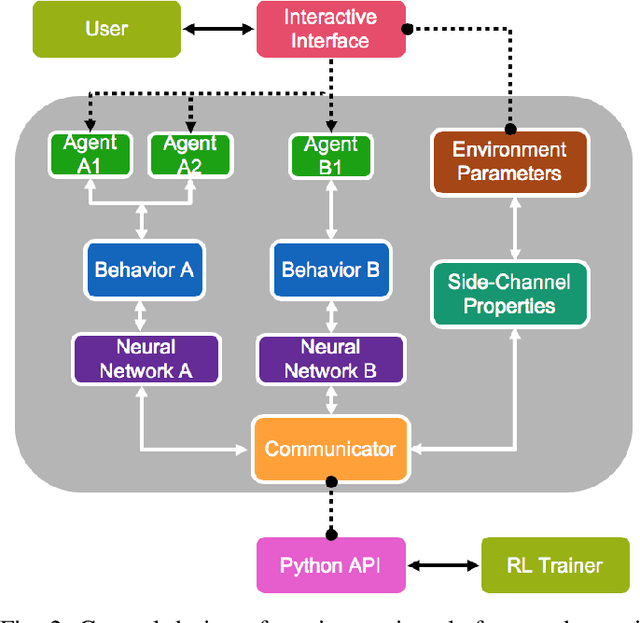
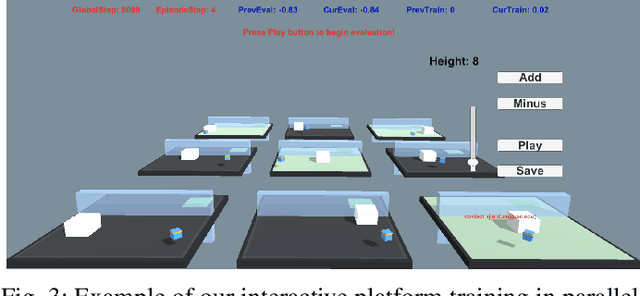
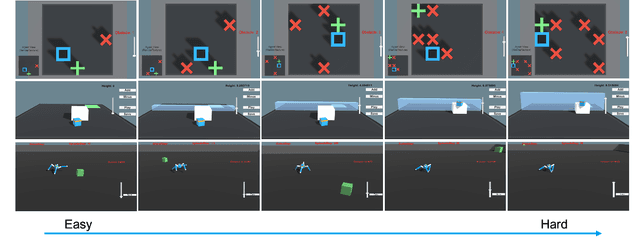
Human-centered AI considers human experiences with AI performance. While abundant research has been helping AI achieve superhuman performance either by fully automatic or weak supervision learning, fewer endeavors are experimenting with how AI can tailor to humans' preferred skill level given fine-grained input. In this work, we guide the curriculum reinforcement learning results towards a preferred performance level that is neither too hard nor too easy via learning from the human decision process. To achieve this, we developed a portable, interactive platform that enables the user to interact with agents online via manipulating the task difficulty, observing performance, and providing curriculum feedback. Our system is highly parallelizable, making it possible for a human to train large-scale reinforcement learning applications that require millions of samples without a server. The result demonstrates the effectiveness of an interactive curriculum for reinforcement learning involving human-in-the-loop. It shows reinforcement learning performance can successfully adjust in sync with the human desired difficulty level. We believe this research will open new doors for achieving flow and personalized adaptive difficulties.