 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTpuGraphs: A Performance Prediction Dataset on Large Tensor Computational Graphs
Aug 25, 2023



Precise hardware performance models play a crucial role in code optimizations. They can assist compilers in making heuristic decisions or aid autotuners in identifying the optimal configuration for a given program. For example, the autotuner for XLA, a machine learning compiler, discovered 10-20% speedup on state-of-the-art models serving substantial production traffic at Google. Although there exist a few datasets for program performance prediction, they target small sub-programs such as basic blocks or kernels. This paper introduces TpuGraphs, a performance prediction dataset on full tensor programs, represented as computational graphs, running on Tensor Processing Units (TPUs). Each graph in the dataset represents the main computation of a machine learning workload, e.g., a training epoch or an inference step. Each data sample contains a computational graph, a compilation configuration, and the execution time of the graph when compiled with the configuration. The graphs in the dataset are collected from open-source machine learning programs, featuring popular model architectures, e.g., ResNet, EfficientNet, Mask R-CNN, and Transformer. TpuGraphs provides 25x more graphs than the largest graph property prediction dataset (with comparable graph sizes), and 770x larger graphs on average compared to existing performance prediction datasets on machine learning programs. This graph-level prediction task on large graphs introduces new challenges in learning, ranging from scalability, training efficiency, to model quality.
UGSL: A Unified Framework for Benchmarking Graph Structure Learning
Aug 21, 2023



Graph neural networks (GNNs) demonstrate outstanding performance in a broad range of applications. While the majority of GNN applications assume that a graph structure is given, some recent methods substantially expanded the applicability of GNNs by showing that they may be effective even when no graph structure is explicitly provided. The GNN parameters and a graph structure are jointly learned. Previous studies adopt different experimentation setups, making it difficult to compare their merits. In this paper, we propose a benchmarking strategy for graph structure learning using a unified framework. Our framework, called Unified Graph Structure Learning (UGSL), reformulates existing models into a single model. We implement a wide range of existing models in our framework and conduct extensive analyses of the effectiveness of different components in the framework. Our results provide a clear and concise understanding of the different methods in this area as well as their strengths and weaknesses. The benchmark code is available at https://github.com/google-research/google-research/tree/master/ugsl.
HUGE: Huge Unsupervised Graph Embeddings with TPUs
Jul 26, 2023



Graphs are a representation of structured data that captures the relationships between sets of objects. With the ubiquity of available network data, there is increasing industrial and academic need to quickly analyze graphs with billions of nodes and trillions of edges. A common first step for network understanding is Graph Embedding, the process of creating a continuous representation of nodes in a graph. A continuous representation is often more amenable, especially at scale, for solving downstream machine learning tasks such as classification, link prediction, and clustering. A high-performance graph embedding architecture leveraging Tensor Processing Units (TPUs) with configurable amounts of high-bandwidth memory is presented that simplifies the graph embedding problem and can scale to graphs with billions of nodes and trillions of edges. We verify the embedding space quality on real and synthetic large-scale datasets.
Examining the Effects of Degree Distribution and Homophily in Graph Learning Models
Jul 17, 2023Despite a surge in interest in GNN development, homogeneity in benchmarking datasets still presents a fundamental issue to GNN research. GraphWorld is a recent solution which uses the Stochastic Block Model (SBM) to generate diverse populations of synthetic graphs for benchmarking any GNN task. Despite its success, the SBM imposed fundamental limitations on the kinds of graph structure GraphWorld could create. In this work we examine how two additional synthetic graph generators can improve GraphWorld's evaluation; LFR, a well-established model in the graph clustering literature and CABAM, a recent adaptation of the Barabasi-Albert model tailored for GNN benchmarking. By integrating these generators, we significantly expand the coverage of graph space within the GraphWorld framework while preserving key graph properties observed in real-world networks. To demonstrate their effectiveness, we generate 300,000 graphs to benchmark 11 GNN models on a node classification task. We find GNN performance variations in response to homophily, degree distribution and feature signal. Based on these findings, we classify models by their sensitivity to the new generators under these properties. Additionally, we release the extensions made to GraphWorld on the GitHub repository, offering further evaluation of GNN performance on new graphs.
Explaining and Adapting Graph Conditional Shift
Jun 05, 2023



Graph Neural Networks (GNNs) have shown remarkable performance on graph-structured data. However, recent empirical studies suggest that GNNs are very susceptible to distribution shift. There is still significant ambiguity about why graph-based models seem more vulnerable to these shifts. In this work we provide a thorough theoretical analysis on it by quantifying the magnitude of conditional shift between the input features and the output label. Our findings show that both graph heterophily and model architecture exacerbate conditional shifts, leading to performance degradation. To address this, we propose an approach that involves estimating and minimizing the conditional shift for unsupervised domain adaptation on graphs. In our controlled synthetic experiments, our algorithm demonstrates robustness towards distribution shift, resulting in up to 10% absolute ROC AUC improvement versus the second-best algorithm. Furthermore, comprehensive experiments on both node classification and graph classification show its robust performance under various distribution shifts.
Unsupervised Embedding Quality Evaluation
May 26, 2023



Unsupervised learning has recently significantly gained in popularity, especially with deep learning-based approaches. Despite numerous successes and approaching supervised-level performance on a variety of academic benchmarks, it is still hard to train and evaluate SSL models in practice due to the unsupervised nature of the problem. Even with networks trained in a supervised fashion, it is often unclear whether they will perform well when transferred to another domain. Past works are generally limited to assessing the amount of information contained in embeddings, which is most relevant for self-supervised learning of deep neural networks. This works chooses to follow a different approach: can we quantify how easy it is to linearly separate the data in a stable way? We survey the literature and uncover three methods that could be potentially used for evaluating quality of representations. We also introduce one novel method based on recent advances in understanding the high-dimensional geometric structure self-supervised learning. We conduct extensive experiments and study the properties of these metrics and ones introduced in the previous work. Our results suggest that while there is no free lunch, there are metrics that can robustly estimate embedding quality in an unsupervised way.
Learning Large Graph Property Prediction via Graph Segment Training
May 21, 2023



Learning to predict properties of large graphs is challenging because each prediction requires the knowledge of an entire graph, while the amount of memory available during training is bounded. Here we propose Graph Segment Training (GST), a general framework that utilizes a divide-and-conquer approach to allow learning large graph property prediction with a constant memory footprint. GST first divides a large graph into segments and then backpropagates through only a few segments sampled per training iteration. We refine the GST paradigm by introducing a historical embedding table to efficiently obtain embeddings for segments not sampled for backpropagation. To mitigate the staleness of historical embeddings, we design two novel techniques. First, we finetune the prediction head to fix the input distribution shift. Second, we introduce Stale Embedding Dropout to drop some stale embeddings during training to reduce bias. We evaluate our complete method GST-EFD (with all the techniques together) on two large graph property prediction benchmarks: MalNet and TpuGraphs. Our experiments show that GST-EFD is both memory-efficient and fast, while offering a slight boost on test accuracy over a typical full graph training regime.
On Classification Thresholds for Graph Attention with Edge Features
Oct 18, 2022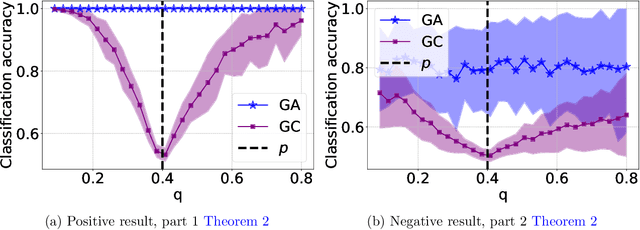
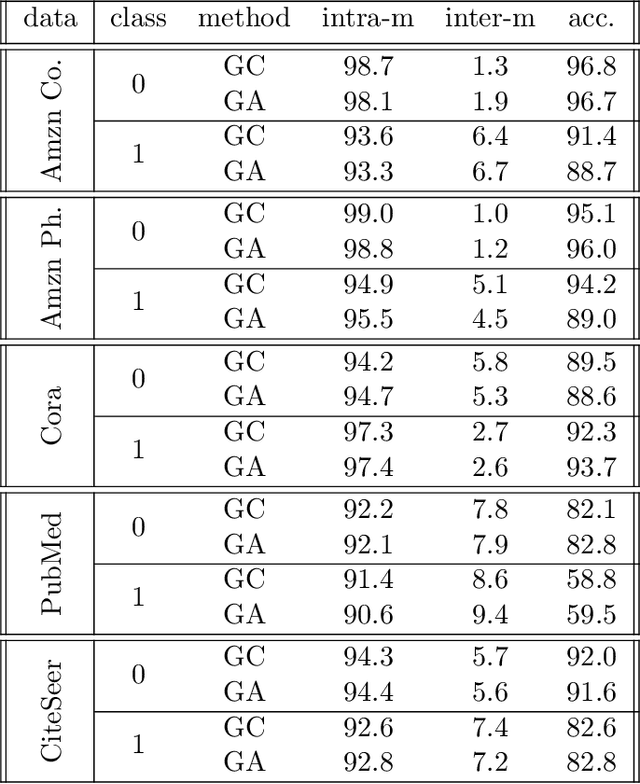
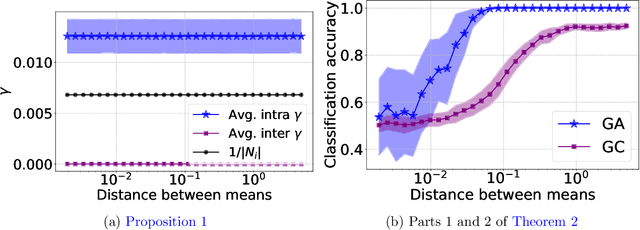
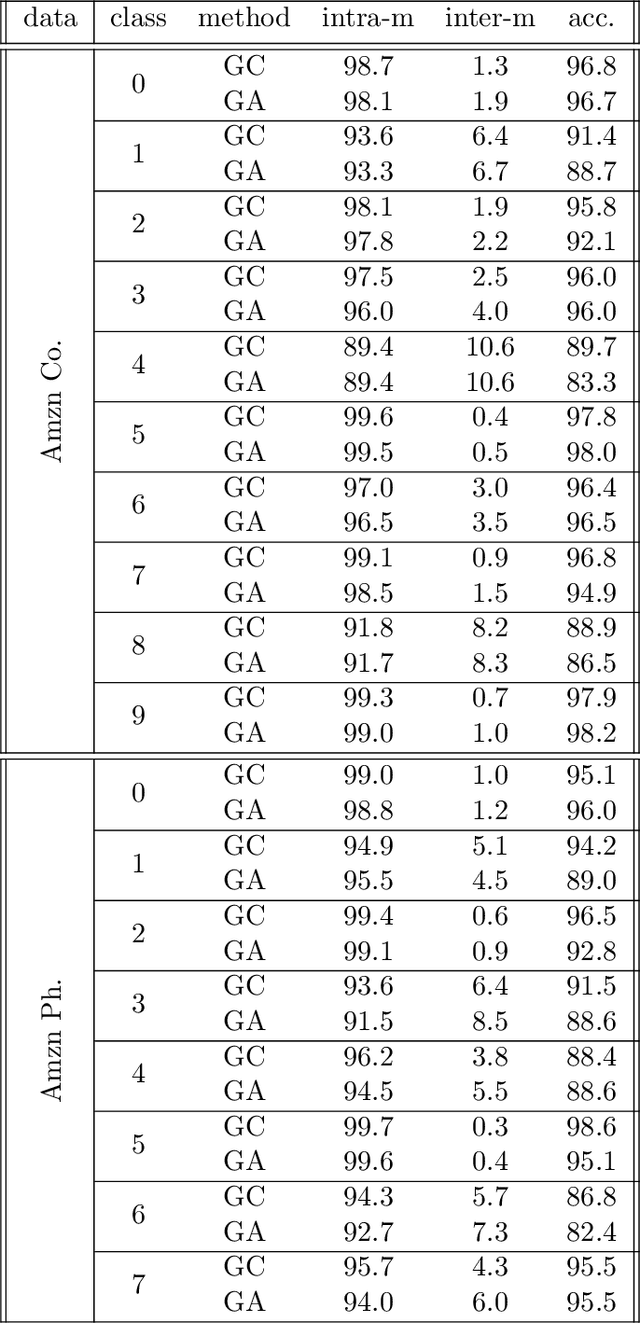
The recent years we have seen the rise of graph neural networks for prediction tasks on graphs. One of the dominant architectures is graph attention due to its ability to make predictions using weighted edge features and not only node features. In this paper we analyze, theoretically and empirically, graph attention networks and their ability of correctly labelling nodes in a classic classification task. More specifically, we study the performance of graph attention on the classic contextual stochastic block model (CSBM). In CSBM the nodes and edge features are obtained from a mixture of Gaussians and the edges from a stochastic block model. We consider a general graph attention mechanism that takes random edge features as input to determine the attention coefficients. We study two cases, in the first one, when the edge features are noisy, we prove that the majority of the attention coefficients are up to a constant uniform. This allows us to prove that graph attention with edge features is not better than simple graph convolution for achieving perfect node classification. Second, we prove that when the edge features are clean graph attention can distinguish intra- from inter-edges and this makes graph attention better than classic graph convolution.
Differentially Private Graph Learning via Sensitivity-Bounded Personalized PageRank
Jul 14, 2022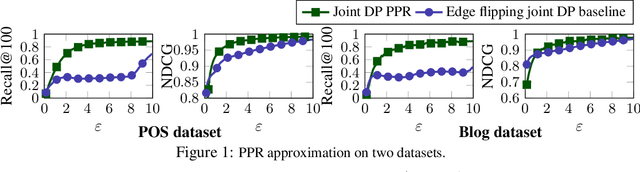
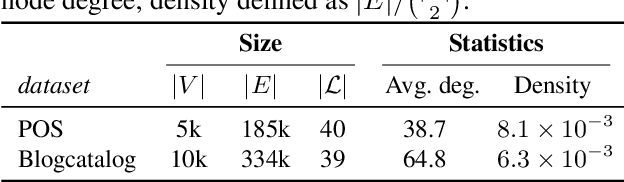
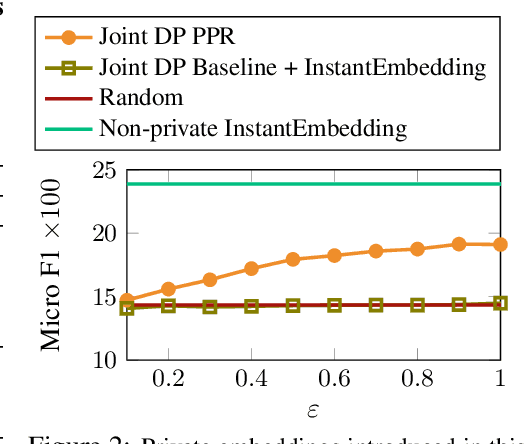
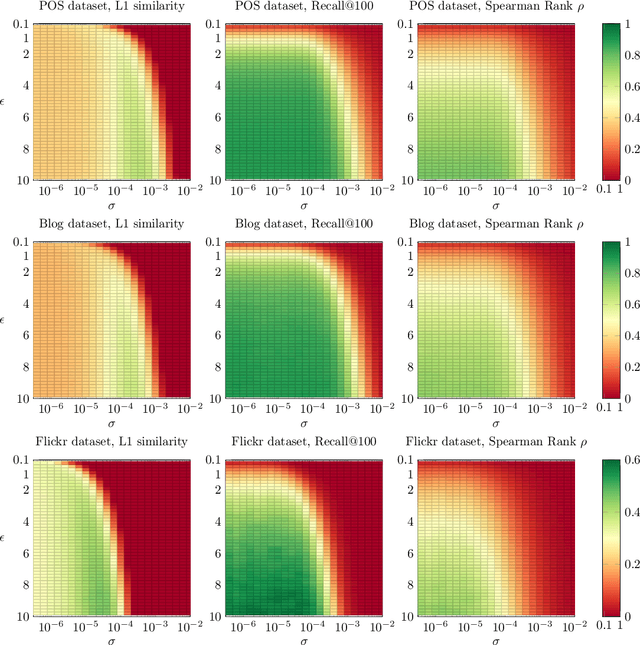
Personalized PageRank (PPR) is a fundamental tool in unsupervised learning of graph representations such as node ranking, labeling, and graph embedding. However, while data privacy is one of the most important recent concerns, existing PPR algorithms are not designed to protect user privacy. PPR is highly sensitive to the input graph edges: the difference of only one edge may cause a big change in the PPR vector, potentially leaking private user data. In this work, we propose an algorithm which outputs an approximate PPR and has provably bounded sensitivity to input edges. In addition, we prove that our algorithm achieves similar accuracy to non-private algorithms when the input graph has large degrees. Our sensitivity-bounded PPR directly implies private algorithms for several tools of graph learning, such as, differentially private (DP) PPR ranking, DP node classification, and DP node embedding. To complement our theoretical analysis, we also empirically verify the practical performances of our algorithms.
Scalable Privacy-enhanced Benchmark Graph Generative Model for Graph Convolutional Networks
Jul 10, 2022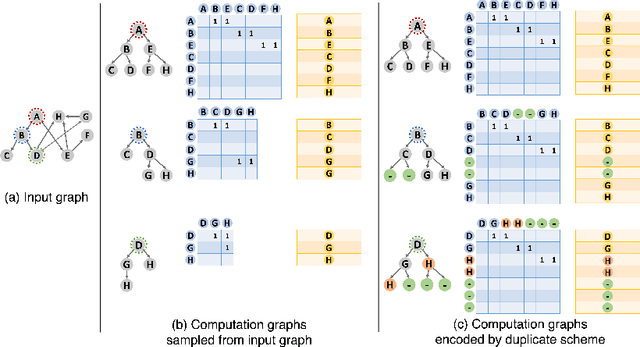
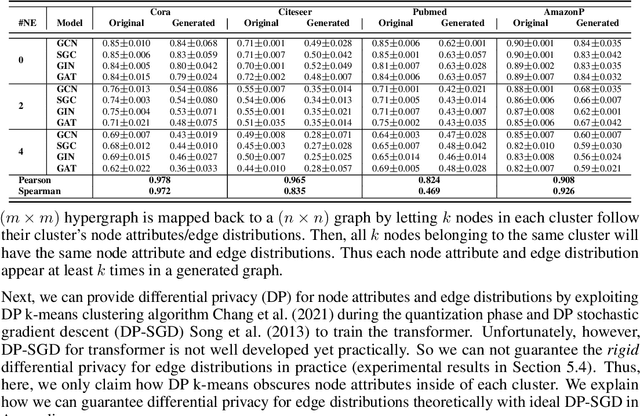
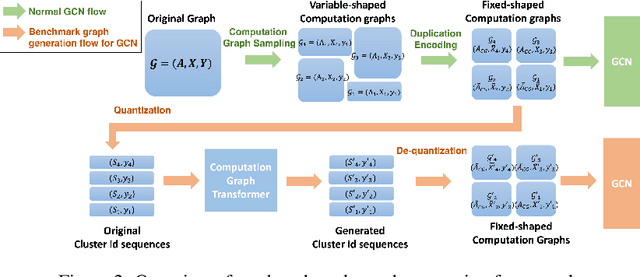
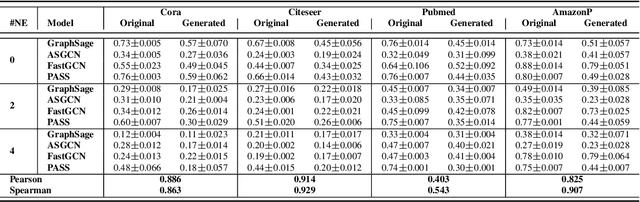
A surge of interest in Graph Convolutional Networks (GCN) has produced thousands of GCN variants, with hundreds introduced every year. In contrast, many GCN models re-use only a handful of benchmark datasets as many graphs of interest, such as social or commercial networks, are proprietary. We propose a new graph generation problem to enable generating a diverse set of benchmark graphs for GCNs following the distribution of a source graph -- possibly proprietary -- with three requirements: 1) benchmark effectiveness as a substitute for the source graph for GCN research, 2) scalability to process large-scale real-world graphs, and 3) a privacy guarantee for end-users. With a novel graph encoding scheme, we reframe large-scale graph generation problem into medium-length sequence generation problem and apply the strong generation power of the Transformer architecture to the graph domain. Extensive experiments across a vast body of graph generative models show that our model can successfully generate benchmark graphs with the realistic graph structure, node attributes, and node labels required to benchmark GCNs on node classification tasks.