 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity of Classical Acceleration for $\ell_1$-Regularized PageRank
Feb 24, 2026We study the degree-weighted work required to compute $\ell_1$-regularized PageRank using the standard one-gradient-per-iteration accelerated proximal-gradient method (FISTA). For non-accelerated local methods, the best known worst-case work scales as $\widetilde{O} ((αρ)^{-1})$, where $α$ is the teleportation parameter and $ρ$ is the $\ell_1$-regularization parameter. A natural question is whether FISTA can improve the dependence on $α$ from $1/α$ to $1/\sqrtα$ while preserving the $1/ρ$ locality scaling. The challenge is that acceleration can break locality by transiently activating nodes that are zero at optimality, thereby increasing the cost of gradient evaluations. We analyze FISTA on a slightly over-regularized objective and show that, under a checkable confinement condition, all spurious activations remain inside a boundary set $\mathcal{B}$. This yields a bound consisting of an accelerated $(ρ\sqrtα)^{-1}\log(α/\varepsilon)$ term plus a boundary overhead $\sqrt{vol(\mathcal{B})}/(ρα^{3/2})$. We provide graph-structural conditions that imply such confinement. Experiments on synthetic and real graphs show the resulting speedup and slowdown regimes under the degree-weighted work model.
Learning to Execute Graph Algorithms Exactly with Graph Neural Networks
Jan 30, 2026Understanding what graph neural networks can learn, especially their ability to learn to execute algorithms, remains a central theoretical challenge. In this work, we prove exact learnability results for graph algorithms under bounded-degree and finite-precision constraints. Our approach follows a two-step process. First, we train an ensemble of multi-layer perceptrons (MLPs) to execute the local instructions of a single node. Second, during inference, we use the trained MLP ensemble as the update function within a graph neural network (GNN). Leveraging Neural Tangent Kernel (NTK) theory, we show that local instructions can be learned from a small training set, enabling the complete graph algorithm to be executed during inference without error and with high probability. To illustrate the learning power of our setting, we establish a rigorous learnability result for the LOCAL model of distributed computation. We further demonstrate positive learnability results for widely studied algorithms such as message flooding, breadth-first and depth-first search, and Bellman-Ford.
Exact Learning of Permutations for Nonzero Binary Inputs with Logarithmic Training Size and Quadratic Ensemble Complexity
Feb 24, 2025The ability of an architecture to realize permutations is quite fundamental. For example, Large Language Models need to be able to correctly copy (and perhaps rearrange) parts of the input prompt into the output. Classical universal approximation theorems guarantee the existence of parameter configurations that solve this task but offer no insights into whether gradient-based algorithms can find them. In this paper, we address this gap by focusing on two-layer fully connected feed-forward neural networks and the task of learning permutations on nonzero binary inputs. We show that in the infinite width Neural Tangent Kernel (NTK) regime, an ensemble of such networks independently trained with gradient descent on only the $k$ standard basis vectors out of $2^k - 1$ possible inputs successfully learns any fixed permutation of length $k$ with arbitrarily high probability. By analyzing the exact training dynamics, we prove that the network's output converges to a Gaussian process whose mean captures the ground truth permutation via sign-based features. We then demonstrate how averaging these runs (an "ensemble" method) and applying a simple rounding step yields an arbitrarily accurate prediction on any possible input unseen during training. Notably, the number of models needed to achieve exact learning with high probability (which we refer to as ensemble complexity) exhibits a linearithmic dependence on the input size $k$ for a single test input and a quadratic dependence when considering all test inputs simultaneously.
LVLM-COUNT: Enhancing the Counting Ability of Large Vision-Language Models
Dec 01, 2024



Counting is a fundamental skill for various visual tasks in real-life applications, requiring both object recognition and robust counting capabilities. Despite their advanced visual perception, large vision-language models (LVLMs) struggle with counting tasks, especially when the number of objects exceeds those commonly encountered during training. We enhance LVLMs' counting abilities using a divide-and-conquer approach, breaking counting problems into sub-counting tasks. Unlike prior methods, which do not generalize well to counting datasets on which they have not been trained, our method performs well on new datasets without any additional training or fine-tuning. We demonstrate that our approach enhances counting capabilities across various datasets and benchmarks.
Positional Attention: Out-of-Distribution Generalization and Expressivity for Neural Algorithmic Reasoning
Oct 02, 2024There has been a growing interest in the ability of neural networks to solve algorithmic tasks, such as arithmetic, summary statistics, and sorting. While state-of-the-art models like Transformers have demonstrated good generalization performance on in-distribution tasks, their out-of-distribution (OOD) performance is poor when trained end-to-end. In this paper, we focus on value generalization, a common instance of OOD generalization where the test distribution has the same input sequence length as the training distribution, but the value ranges in the training and test distributions do not necessarily overlap. To address this issue, we propose that using fixed positional encodings to determine attention weights-referred to as positional attention-enhances empirical OOD performance while maintaining expressivity. We support our claim about expressivity by proving that Transformers with positional attention can effectively simulate parallel algorithms.
Analysis of Corrected Graph Convolutions
May 22, 2024Machine learning for node classification on graphs is a prominent area driven by applications such as recommendation systems. State-of-the-art models often use multiple graph convolutions on the data, as empirical evidence suggests they can enhance performance. However, it has been shown empirically and theoretically, that too many graph convolutions can degrade performance significantly, a phenomenon known as oversmoothing. In this paper, we provide a rigorous theoretical analysis, based on the contextual stochastic block model (CSBM), of the performance of vanilla graph convolution from which we remove the principal eigenvector to avoid oversmoothing. We perform a spectral analysis for $k$ rounds of corrected graph convolutions, and we provide results for partial and exact classification. For partial classification, we show that each round of convolution can reduce the misclassification error exponentially up to a saturation level, after which performance does not worsen. For exact classification, we show that the separability threshold can be improved exponentially up to $O({\log{n}}/{\log\log{n}})$ corrected convolutions.
Simulation of Graph Algorithms with Looped Transformers
Feb 02, 2024


The execution of graph algorithms using neural networks has recently attracted significant interest due to promising empirical progress. This motivates further understanding of how neural networks can replicate reasoning steps with relational data. In this work, we study the ability of transformer networks to simulate algorithms on graphs from a theoretical perspective. The architecture that we utilize is a looped transformer with extra attention heads that interact with the graph. We prove by construction that this architecture can simulate algorithms such as Dijkstra's shortest path algorithm, Breadth- and Depth-First Search, and Kosaraju's strongly connected components algorithm. The width of the network does not increase with the size of the input graph, which implies that the network can simulate the above algorithms for any graph. Despite this property, we show that there is a limit to simulation in our solution due to finite precision. Finally, we show a Turing Completeness result with constant width when the extra attention heads are utilized.
Local Graph Clustering with Noisy Labels
Oct 12, 2023



The growing interest in machine learning problems over graphs with additional node information such as texts, images, or labels has popularized methods that require the costly operation of processing the entire graph. Yet, little effort has been made to the development of fast local methods (i.e. without accessing the entire graph) that extract useful information from such data. To that end, we propose a study of local graph clustering using noisy node labels as a proxy for additional node information. In this setting, nodes receive initial binary labels based on cluster affiliation: 1 if they belong to the target cluster and 0 otherwise. Subsequently, a fraction of these labels is flipped. We investigate the benefits of incorporating noisy labels for local graph clustering. By constructing a weighted graph with such labels, we study the performance of graph diffusion-based local clustering method on both the original and the weighted graphs. From a theoretical perspective, we consider recovering an unknown target cluster with a single seed node in a random graph with independent noisy node labels. We provide sufficient conditions on the label noise under which, with high probability, using diffusion in the weighted graph yields a more accurate recovery of the target cluster. This approach proves more effective than using the given labels alone or using diffusion in the label-free original graph. Empirically, we show that reliable node labels can be obtained with just a few samples from an attributed graph. Moreover, utilizing these labels via diffusion in the weighted graph leads to significantly better local clustering performance across several real-world datasets, improving F1 scores by up to 13%.
Optimality of Message-Passing Architectures for Sparse Graphs
May 17, 2023We study the node classification problem on feature-decorated graphs in the sparse setting, i.e., when the expected degree of a node is $O(1)$ in the number of nodes. Such graphs are typically known to be locally tree-like. We introduce a notion of Bayes optimality for node classification tasks, called asymptotic local Bayes optimality, and compute the optimal classifier according to this criterion for a fairly general statistical data model with arbitrary distributions of the node features and edge connectivity. The optimal classifier is implementable using a message-passing graph neural network architecture. We then compute the generalization error of this classifier and compare its performance against existing learning methods theoretically on a well-studied statistical model with naturally identifiable signal-to-noise ratios (SNRs) in the data. We find that the optimal message-passing architecture interpolates between a standard MLP in the regime of low graph signal and a typical convolution in the regime of high graph signal. Furthermore, we prove a corresponding non-asymptotic result.
On Classification Thresholds for Graph Attention with Edge Features
Oct 18, 2022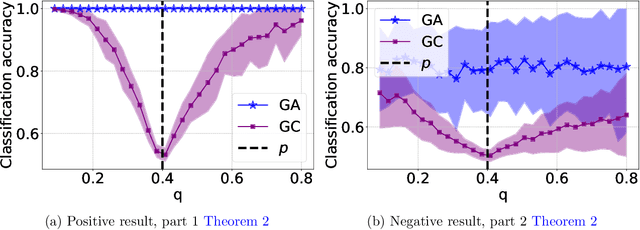
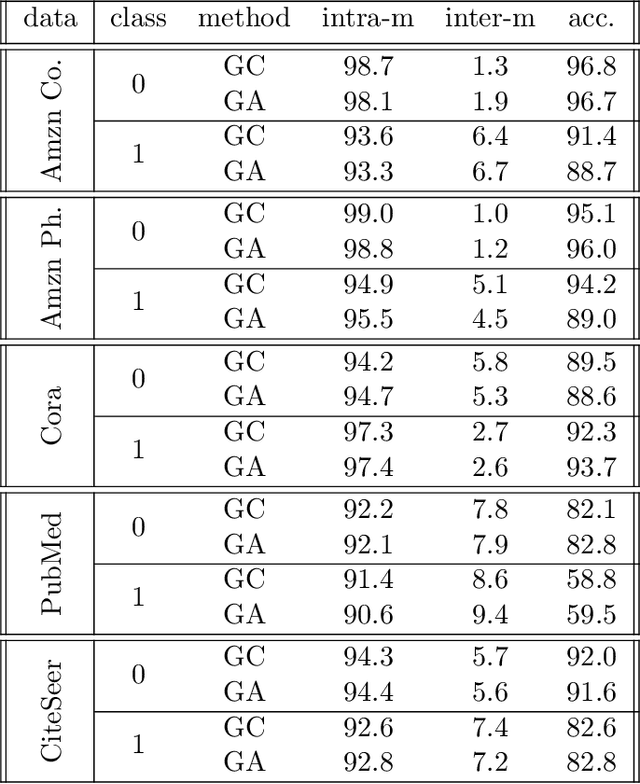
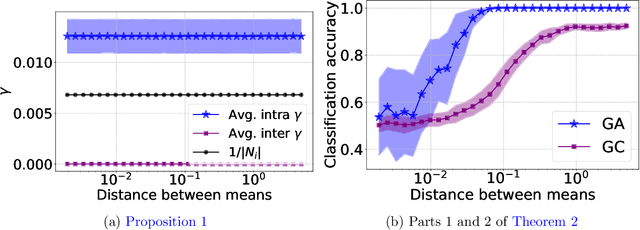
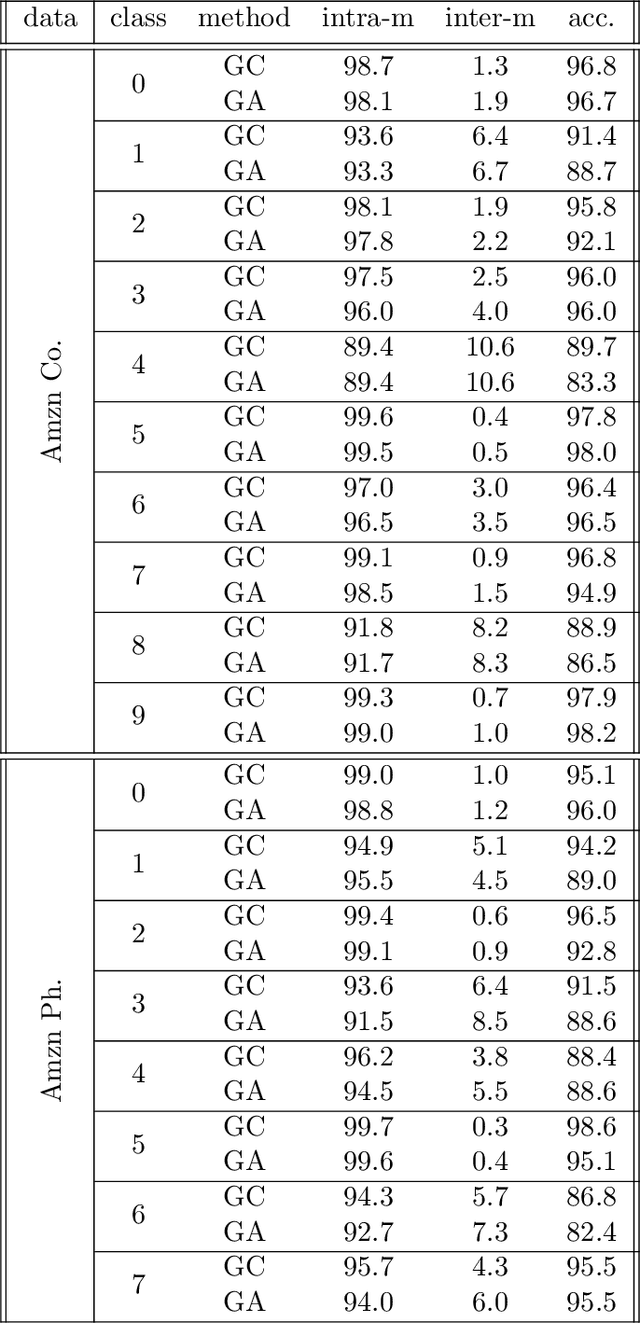
The recent years we have seen the rise of graph neural networks for prediction tasks on graphs. One of the dominant architectures is graph attention due to its ability to make predictions using weighted edge features and not only node features. In this paper we analyze, theoretically and empirically, graph attention networks and their ability of correctly labelling nodes in a classic classification task. More specifically, we study the performance of graph attention on the classic contextual stochastic block model (CSBM). In CSBM the nodes and edge features are obtained from a mixture of Gaussians and the edges from a stochastic block model. We consider a general graph attention mechanism that takes random edge features as input to determine the attention coefficients. We study two cases, in the first one, when the edge features are noisy, we prove that the majority of the attention coefficients are up to a constant uniform. This allows us to prove that graph attention with edge features is not better than simple graph convolution for achieving perfect node classification. Second, we prove that when the edge features are clean graph attention can distinguish intra- from inter-edges and this makes graph attention better than classic graph convolution.