 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Text Inputs For Training and Adapting RNN Transducer ASR Models
Feb 26, 2022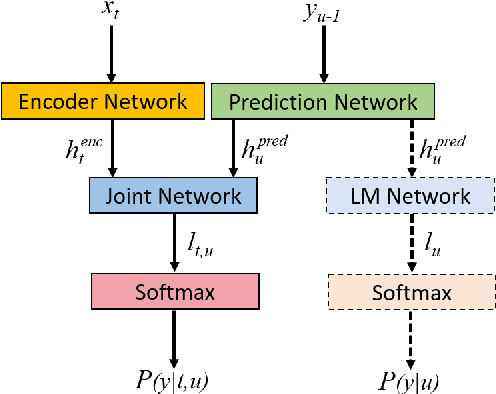
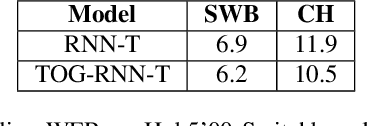
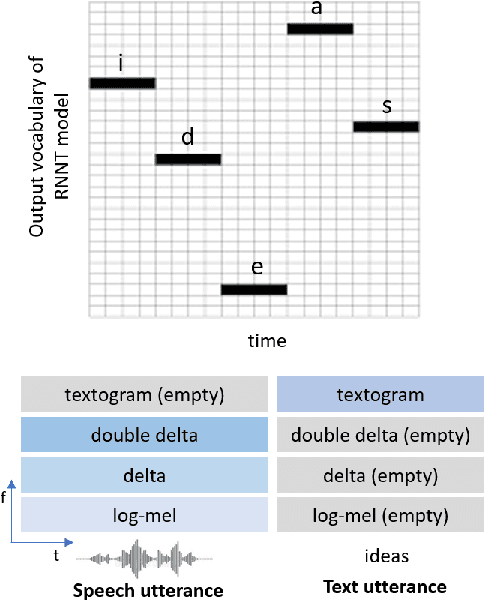
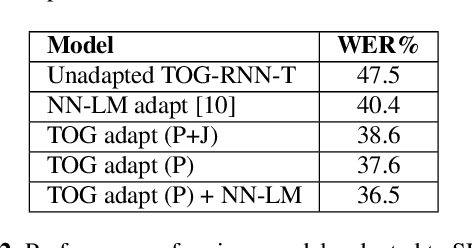
Compared to hybrid automatic speech recognition (ASR) systems that use a modular architecture in which each component can be independently adapted to a new domain, recent end-to-end (E2E) ASR system are harder to customize due to their all-neural monolithic construction. In this paper, we propose a novel text representation and training framework for E2E ASR models. With this approach, we show that a trained RNN Transducer (RNN-T) model's internal LM component can be effectively adapted with text-only data. An RNN-T model trained using both speech and text inputs improves over a baseline model trained on just speech with close to 13% word error rate (WER) reduction on the Switchboard and CallHome test sets of the NIST Hub5 2000 evaluation. The usefulness of the proposed approach is further demonstrated by customizing this general purpose RNN-T model to three separate datasets. We observe 20-45% relative word error rate (WER) reduction in these settings with this novel LM style customization technique using only unpaired text data from the new domains.
A new data augmentation method for intent classification enhancement and its application on spoken conversation datasets
Feb 21, 2022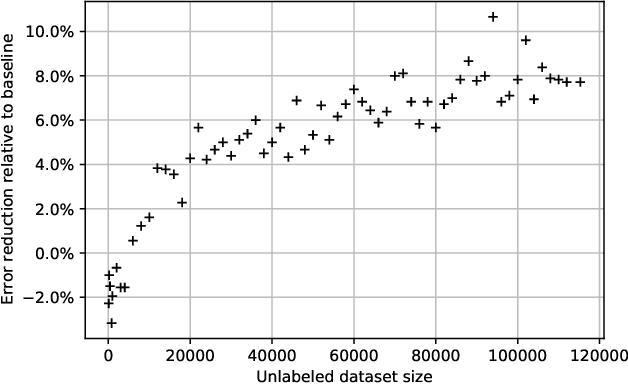
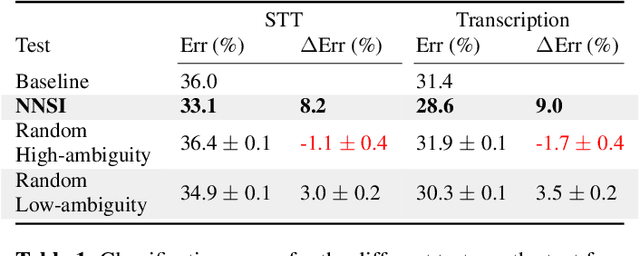
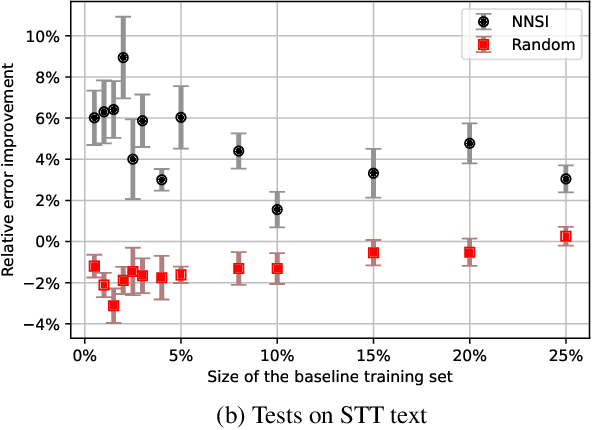
Intent classifiers are vital to the successful operation of virtual agent systems. This is especially so in voice activated systems where the data can be noisy with many ambiguous directions for user intents. Before operation begins, these classifiers are generally lacking in real-world training data. Active learning is a common approach used to help label large amounts of collected user input. However, this approach requires many hours of manual labeling work. We present the Nearest Neighbors Scores Improvement (NNSI) algorithm for automatic data selection and labeling. The NNSI reduces the need for manual labeling by automatically selecting highly-ambiguous samples and labeling them with high accuracy. This is done by integrating the classifier's output from a semantically similar group of text samples. The labeled samples can then be added to the training set to improve the accuracy of the classifier. We demonstrated the use of NNSI on two large-scale, real-life voice conversation systems. Evaluation of our results showed that our method was able to select and label useful samples with high accuracy. Adding these new samples to the training data significantly improved the classifiers and reduced error rates by up to 10%.
Improving End-to-End Models for Set Prediction in Spoken Language Understanding
Jan 28, 2022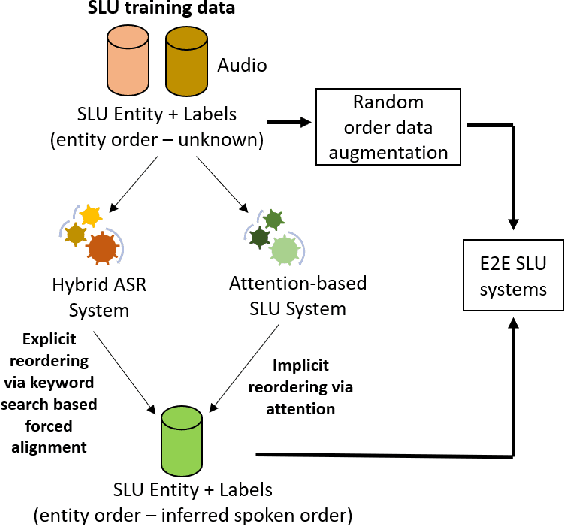

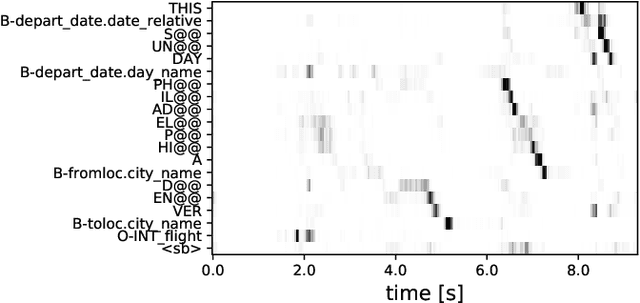
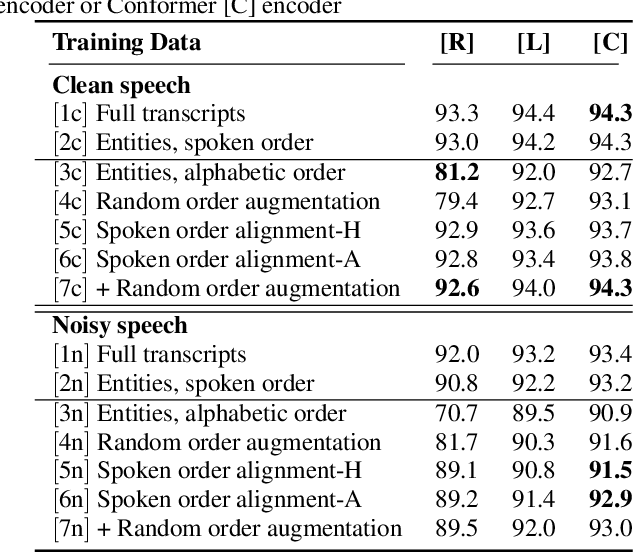
The goal of spoken language understanding (SLU) systems is to determine the meaning of the input speech signal, unlike speech recognition which aims to produce verbatim transcripts. Advances in end-to-end (E2E) speech modeling have made it possible to train solely on semantic entities, which are far cheaper to collect than verbatim transcripts. We focus on this set prediction problem, where entity order is unspecified. Using two classes of E2E models, RNN transducers and attention based encoder-decoders, we show that these models work best when the training entity sequence is arranged in spoken order. To improve E2E SLU models when entity spoken order is unknown, we propose a novel data augmentation technique along with an implicit attention based alignment method to infer the spoken order. F1 scores significantly increased by more than 11% for RNN-T and about 2% for attention based encoder-decoder SLU models, outperforming previously reported results.
Everything at Once -- Multi-modal Fusion Transformer for Video Retrieval
Dec 08, 2021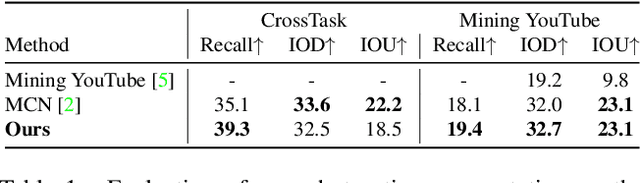

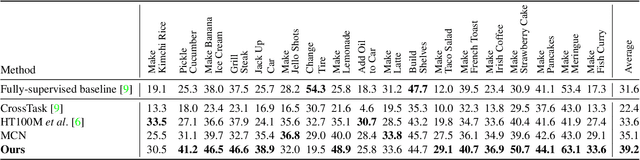
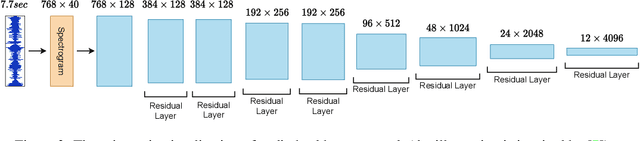
Multi-modal learning from video data has seen increased attention recently as it allows to train semantically meaningful embeddings without human annotation enabling tasks like zero-shot retrieval and classification. In this work, we present a multi-modal, modality agnostic fusion transformer approach that learns to exchange information between multiple modalities, such as video, audio, and text, and integrate them into a joined multi-modal representation to obtain an embedding that aggregates multi-modal temporal information. We propose to train the system with a combinatorial loss on everything at once, single modalities as well as pairs of modalities, explicitly leaving out any add-ons such as position or modality encoding. At test time, the resulting model can process and fuse any number of input modalities. Moreover, the implicit properties of the transformer allow to process inputs of different lengths. To evaluate the proposed approach, we train the model on the large scale HowTo100M dataset and evaluate the resulting embedding space on four challenging benchmark datasets obtaining state-of-the-art results in zero-shot video retrieval and zero-shot video action localization.
Loss Landscape Dependent Self-Adjusting Learning Rates in Decentralized Stochastic Gradient Descent
Dec 02, 2021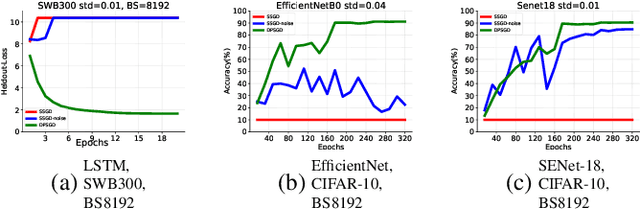
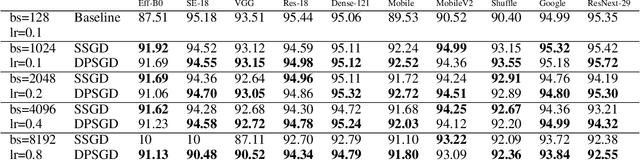
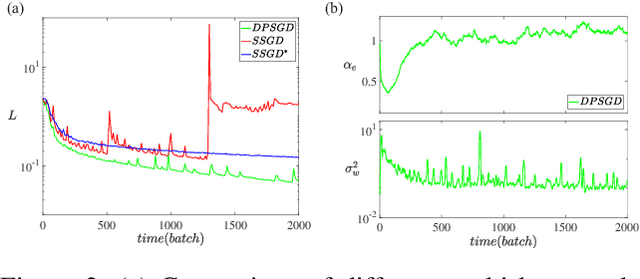
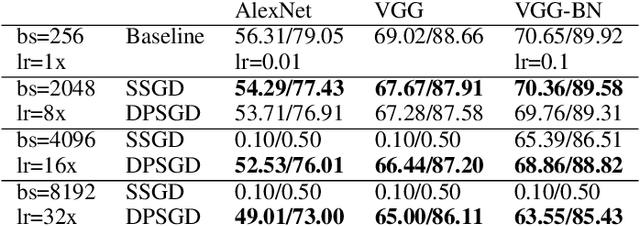
Distributed Deep Learning (DDL) is essential for large-scale Deep Learning (DL) training. Synchronous Stochastic Gradient Descent (SSGD) 1 is the de facto DDL optimization method. Using a sufficiently large batch size is critical to achieving DDL runtime speedup. In a large batch setting, the learning rate must be increased to compensate for the reduced number of parameter updates. However, a large learning rate may harm convergence in SSGD and training could easily diverge. Recently, Decentralized Parallel SGD (DPSGD) has been proposed to improve distributed training speed. In this paper, we find that DPSGD not only has a system-wise run-time benefit but also a significant convergence benefit over SSGD in the large batch setting. Based on a detailed analysis of the DPSGD learning dynamics, we find that DPSGD introduces additional landscape-dependent noise that automatically adjusts the effective learning rate to improve convergence. In addition, we theoretically show that this noise smoothes the loss landscape, hence allowing a larger learning rate. We conduct extensive studies over 18 state-of-the-art DL models/tasks and demonstrate that DPSGD often converges in cases where SSGD diverges for large learning rates in the large batch setting. Our findings are consistent across two different application domains: Computer Vision (CIFAR10 and ImageNet-1K) and Automatic Speech Recognition (SWB300 and SWB2000), and two different types of neural network models: Convolutional Neural Networks and Long Short-Term Memory Recurrent Neural Networks.
Cascaded Multilingual Audio-Visual Learning from Videos
Nov 08, 2021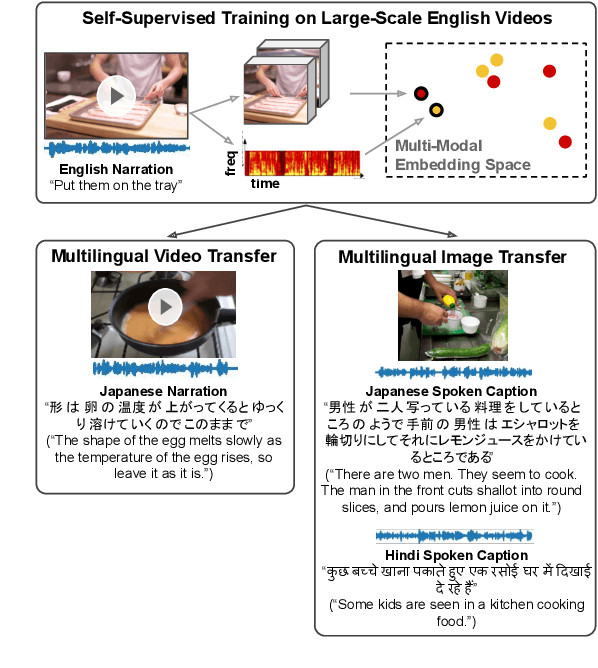
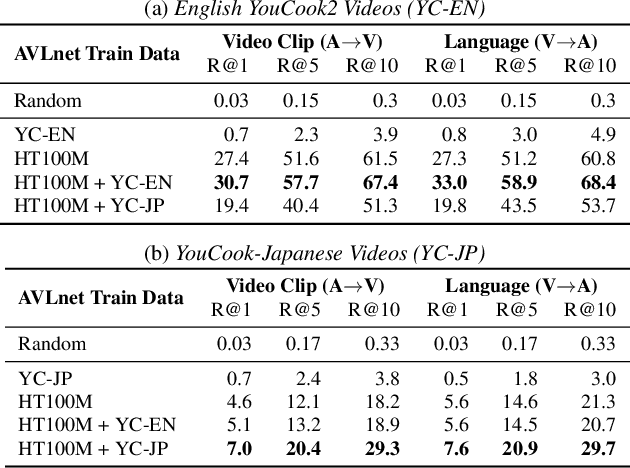

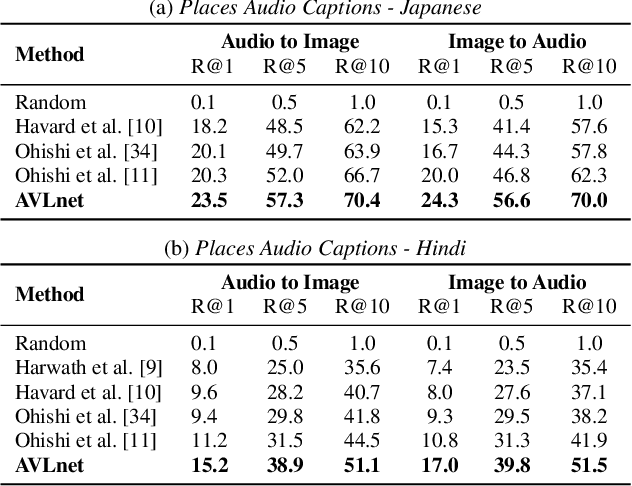
In this paper, we explore self-supervised audio-visual models that learn from instructional videos. Prior work has shown that these models can relate spoken words and sounds to visual content after training on a large-scale dataset of videos, but they were only trained and evaluated on videos in English. To learn multilingual audio-visual representations, we propose a cascaded approach that leverages a model trained on English videos and applies it to audio-visual data in other languages, such as Japanese videos. With our cascaded approach, we show an improvement in retrieval performance of nearly 10x compared to training on the Japanese videos solely. We also apply the model trained on English videos to Japanese and Hindi spoken captions of images, achieving state-of-the-art performance.
Asynchronous Decentralized Distributed Training of Acoustic Models
Oct 21, 2021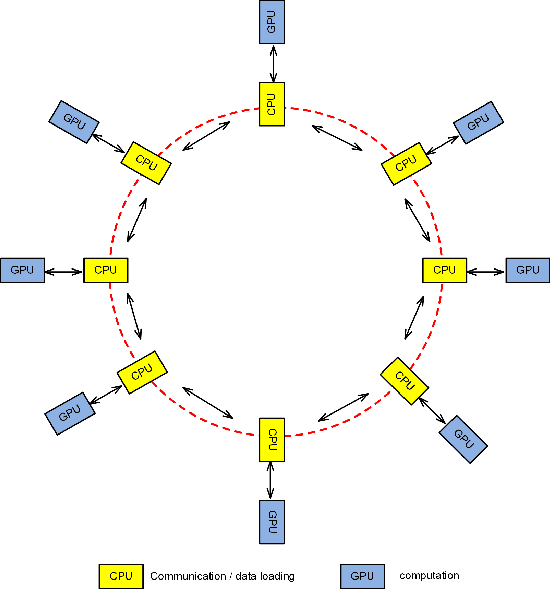
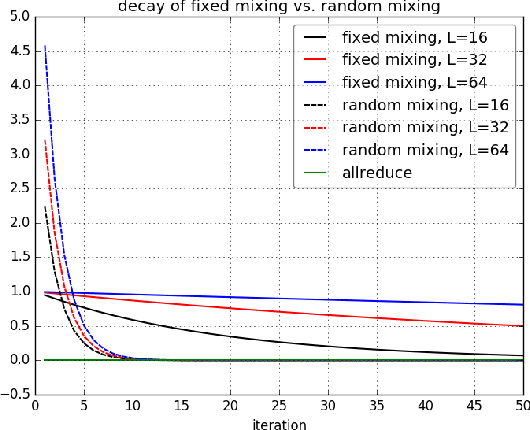
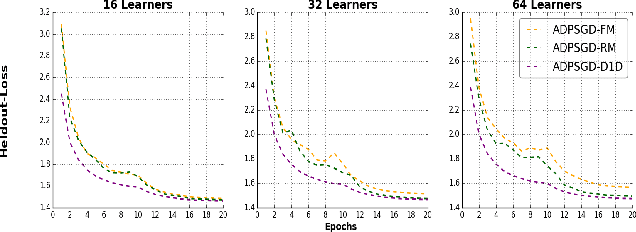
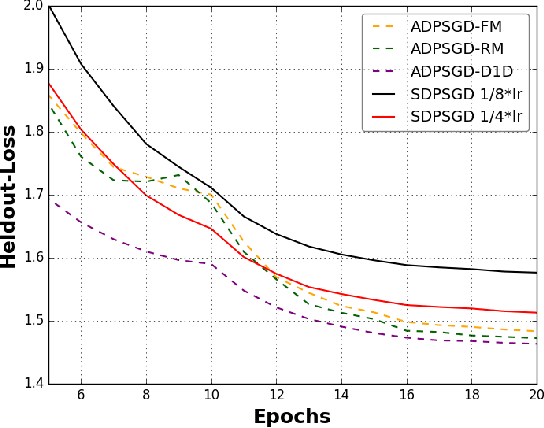
Large-scale distributed training of deep acoustic models plays an important role in today's high-performance automatic speech recognition (ASR). In this paper we investigate a variety of asynchronous decentralized distributed training strategies based on data parallel stochastic gradient descent (SGD) to show their superior performance over the commonly-used synchronous distributed training via allreduce, especially when dealing with large batch sizes. Specifically, we study three variants of asynchronous decentralized parallel SGD (ADPSGD), namely, fixed and randomized communication patterns on a ring as well as a delay-by-one scheme. We introduce a mathematical model of ADPSGD, give its theoretical convergence rate, and compare the empirical convergence behavior and straggler resilience properties of the three variants. Experiments are carried out on an IBM supercomputer for training deep long short-term memory (LSTM) acoustic models on the 2000-hour Switchboard dataset. Recognition and speedup performance of the proposed strategies are evaluated under various training configurations. We show that ADPSGD with fixed and randomized communication patterns cope well with slow learners. When learners are equally fast, ADPSGD with the delay-by-one strategy has the fastest convergence with large batches. In particular, using the delay-by-one strategy, we can train the acoustic model in less than 2 hours using 128 V100 GPUs with competitive word error rates.
4-bit Quantization of LSTM-based Speech Recognition Models
Aug 27, 2021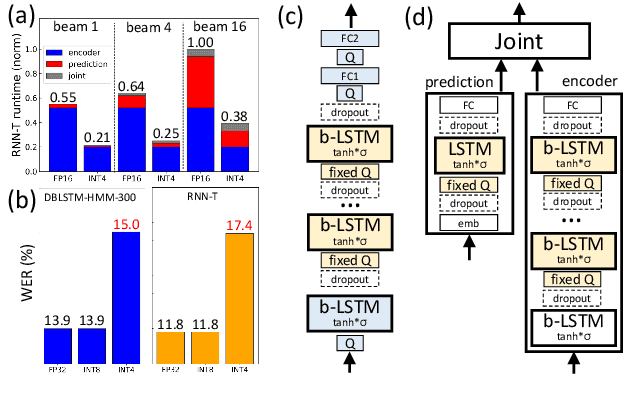
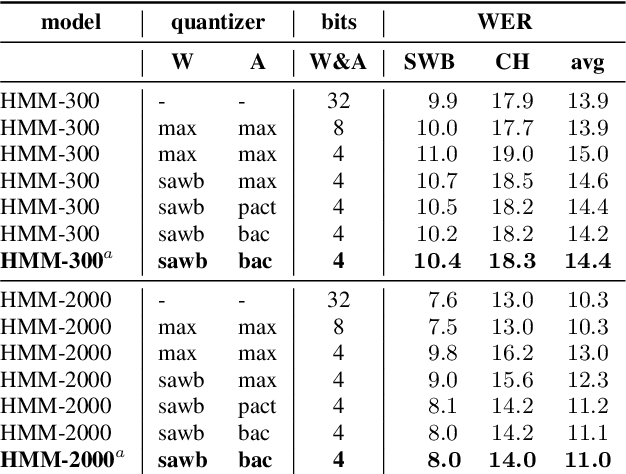
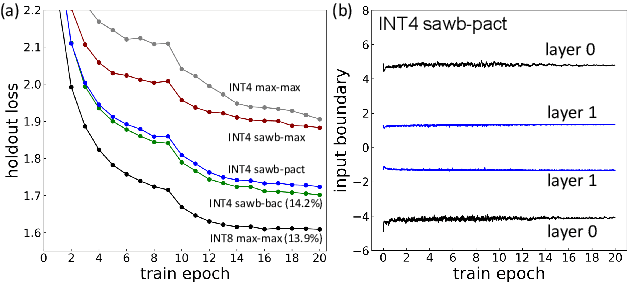
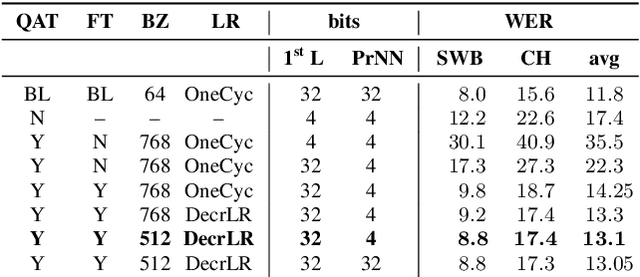
We investigate the impact of aggressive low-precision representations of weights and activations in two families of large LSTM-based architectures for Automatic Speech Recognition (ASR): hybrid Deep Bidirectional LSTM - Hidden Markov Models (DBLSTM-HMMs) and Recurrent Neural Network - Transducers (RNN-Ts). Using a 4-bit integer representation, a na\"ive quantization approach applied to the LSTM portion of these models results in significant Word Error Rate (WER) degradation. On the other hand, we show that minimal accuracy loss is achievable with an appropriate choice of quantizers and initializations. In particular, we customize quantization schemes depending on the local properties of the network, improving recognition performance while limiting computational time. We demonstrate our solution on the Switchboard (SWB) and CallHome (CH) test sets of the NIST Hub5-2000 evaluation. DBLSTM-HMMs trained with 300 or 2000 hours of SWB data achieves $<$0.5% and $<$1% average WER degradation, respectively. On the more challenging RNN-T models, our quantization strategy limits degradation in 4-bit inference to 1.3%.
Reducing Exposure Bias in Training Recurrent Neural Network Transducers
Aug 24, 2021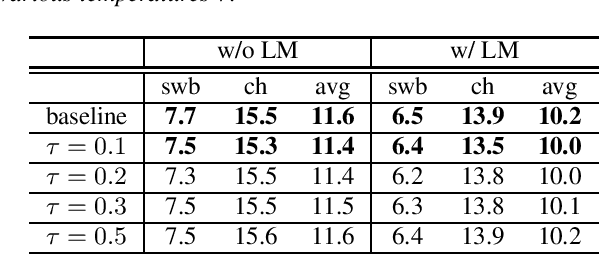
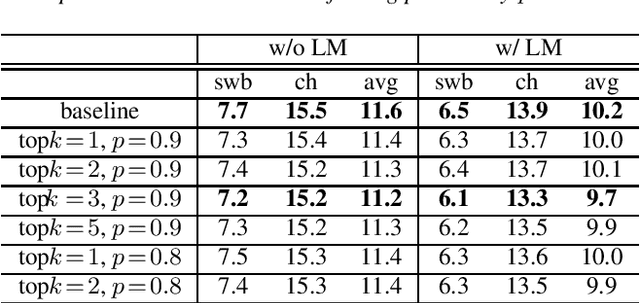
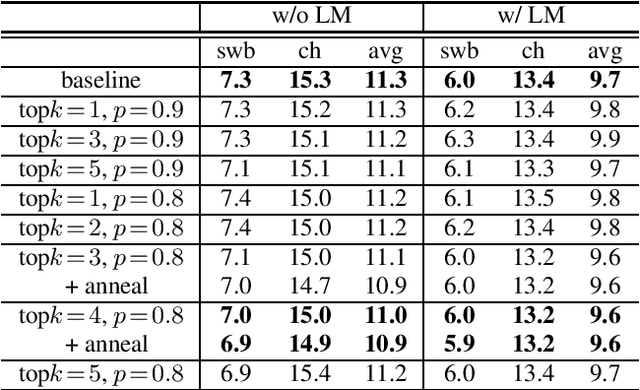
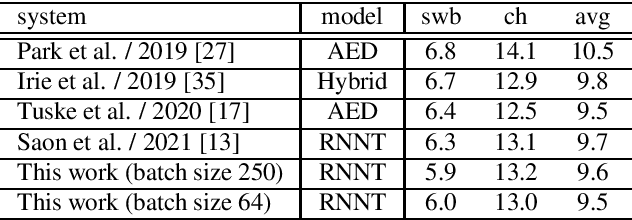
When recurrent neural network transducers (RNNTs) are trained using the typical maximum likelihood criterion, the prediction network is trained only on ground truth label sequences. This leads to a mismatch during inference, known as exposure bias, when the model must deal with label sequences containing errors. In this paper we investigate approaches to reducing exposure bias in training to improve the generalization of RNNT models for automatic speech recognition (ASR). A label-preserving input perturbation to the prediction network is introduced. The input token sequences are perturbed using SwitchOut and scheduled sampling based on an additional token language model. Experiments conducted on the 300-hour Switchboard dataset demonstrate their effectiveness. By reducing the exposure bias, we show that we can further improve the accuracy of a high-performance RNNT ASR model and obtain state-of-the-art results on the 300-hour Switchboard dataset.
Integrating Dialog History into End-to-End Spoken Language Understanding Systems
Aug 18, 2021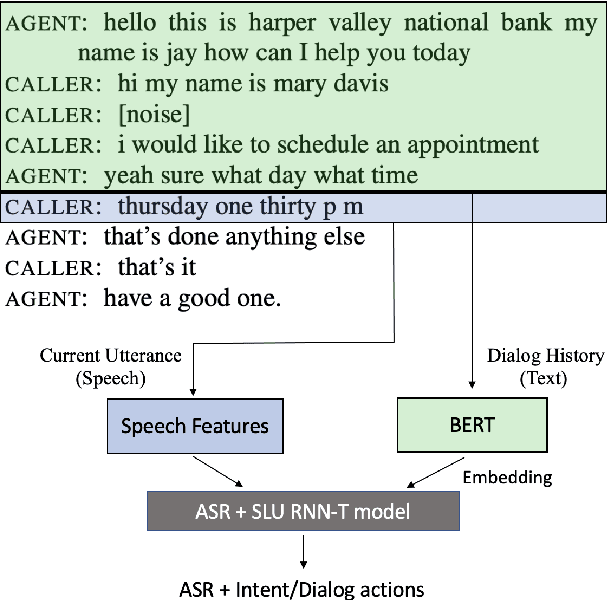

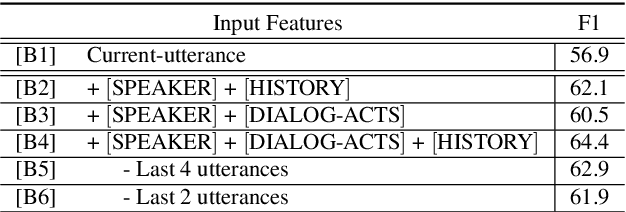
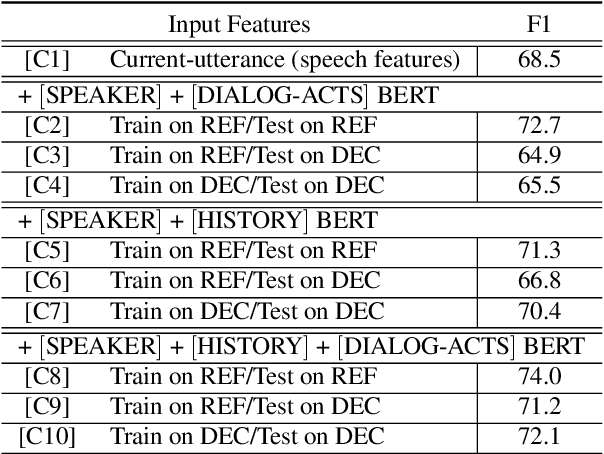
End-to-end spoken language understanding (SLU) systems that process human-human or human-computer interactions are often context independent and process each turn of a conversation independently. Spoken conversations on the other hand, are very much context dependent, and dialog history contains useful information that can improve the processing of each conversational turn. In this paper, we investigate the importance of dialog history and how it can be effectively integrated into end-to-end SLU systems. While processing a spoken utterance, our proposed RNN transducer (RNN-T) based SLU model has access to its dialog history in the form of decoded transcripts and SLU labels of previous turns. We encode the dialog history as BERT embeddings, and use them as an additional input to the SLU model along with the speech features for the current utterance. We evaluate our approach on a recently released spoken dialog data set, the HarperValleyBank corpus. We observe significant improvements: 8% for dialog action and 30% for caller intent recognition tasks, in comparison to a competitive context independent end-to-end baseline system.