 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Sequential Conformal Probing for Reliable OOD Rejection in LLM Services
Jun 19, 2026Rejecting inputs outside the defined in-distribution (IND) service scope is critical for large language model (LLM) services, where unsupported requests should be filtered before full generation. Existing out-of-distribution (OOD) detectors often rely on final outputs or final-layer representations, leaving unclear where service-boundary signals are most clearly encoded inside the model; they also lack a theoretical guarantee for held-out inputs. In this paper, we introduce SCOPE (Sequential Conformal OOD Probing and Evaluation), a framework that selects a readable hidden layer, constructs a conformal gate with IND calibration, and uses a supermartingale e-process to certify persistent service-boundary evidence. Experiments across multiple LLM backbones and six carefully designed boundary conditions show that SCOPE improves gate-level rejection over standard final-layer detectors, while revealing how different OOD boundaries take different geometric forms in hidden space.
ReverseEOL: Improving Training-free Text Embeddings via Text Reversal in Decoder-only LLMs
Jun 04, 2026Recent advances in Large Language Models (LLMs) have opened new avenues for generating training-free text embeddings. However, the causal attention in decoder-only LLMs prevents earlier tokens from attending to future context, leading to biased contextualized representations. In this work, we propose Reverse prompting with Explicit One-word Limitation (ReverseEOL), a simple yet effective method for enhancing the representational capability of frozen LLMs. ReverseEOL augments the standard forward embedding with an additional reversed embedding derived from the reversed input text. Since reversing the input exposes each token to context inaccessible in the original order, the resulting reversed embedding effectively provides complementary information to the original one. As a result, combining the forward and reversed embeddings yields a richer final representation. Comprehensive experiments on STS and MTEB benchmarks demonstrate that ReverseEOL significantly improves the performance of existing training-free baselines across a broad range of LLMs with diverse architectures and scales. Extensive ablations and analyses further confirm the necessity of our reversal mechanism.
Dive into Ambiguity: A*-Inspired Multi-Agents Commonsense Obfuscation Attack on LLM Prompts
May 31, 2026Large language models (LLMs) excel in reasoning and knowledge-intensive tasks but remain vulnerable to prompt-level adversarial attacks that preserve intent while triggering commonsense hallucinations. This vulnerability is urgent, as LLMs are rapidly integrated into safety-critical domains where factual reliability is non-negotiable. Existing attack methods either lack efficiency or fail to capture the adaptive strategies of real-world adversaries. We propose an A*-inspired Factual Error Induction Framework, a framework for generating semantically aligned yet obfuscated prompts. At its core is a Hierarchical Rewrite Strategy guided by a dynamic semantic dispersion coefficient $γ$ that balances conservative edits early with aggressive obfuscations later, following a reverse simulated annealing schedule. To enhance interpretability, we further introduce Agentic Mechanism Labeling, which discovers and refines adversarial mechanisms, offering interpretable reverse optimization. Theoretically, we prove that prompt rewriting follows a contractive recurrence, leading to semantic collapse as $γ$ decreases. Empirically, across diverse LLMs, our method achieves higher attack success rates than exhaustive exploration while requiring fewer attempts, demonstrating both efficiency and effectiveness.
Safety-Constrained Reinforcement Learning with Post-Training Reachability Verification for Robot Navigation
May 13, 2026Safe navigation for mobile robots demands policies that remain reliable under the high-consequence perception uncertainty of cluttered environments. Yet most existing safe reinforcement learning (RL) methods assess safety through average cumulative cost. Such metrics can mask dangerous tail-risk behaviors. To address this, we propose a framework that trains risk-sensitive policies through Conditional Value-at-Risk (CVaR) constrained optimization on an off-policy TD3 backbone and evaluates their safety margins post-training through neural network reachability verification. During training, the policy is optimized under CVaR constraints on cumulative costs, promoting sensitivity to high-cost tail outcomes rather than average behavior alone. After training, we compute action reachable sets under bounded observation uncertainty using Taylor Model analysis, yielding a safety rate metric that quantifies the proportion of evaluated states at which the policy's reachable action set remains within prescribed safety margins. A key finding is that policies trained with CVaR constraints maintain larger safety margins from obstacles across evaluated states. This makes them significantly more amenable to formal reachability verification. Experiments across ten navigation scenarios and six baselines show that our method achieves a 98.3\% success rate, the highest safety verification rate among all compared methods, while revealing that average cost rankings and reachability-based safety rankings can diverge. This indicates that reachability verification captures risks which are missed by empirical cost metrics alone. We further validate our approach on a physical Clearpath Jackal robot, demonstrating successful sim-to-real transfer.
Rethinking Multi-Agent Intelligence Through the Lens of Small-World Networks
Dec 19, 2025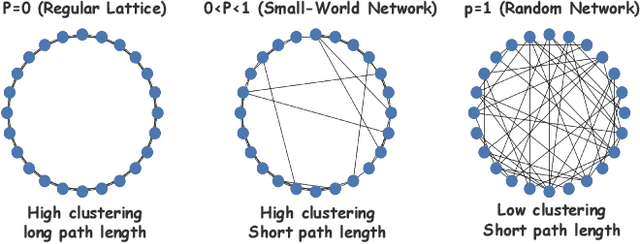



Large language models (LLMs) have enabled multi-agent systems (MAS) in which multiple agents argue, critique, and coordinate to solve complex tasks, making communication topology a first-class design choice. Yet most existing LLM-based MAS either adopt fully connected graphs, simple sparse rings, or ad-hoc dynamic selection, with little structural guidance. In this work, we revisit classic theory on small-world (SW) networks and ask: what changes if we treat SW connectivity as a design prior for MAS? We first bridge insights from neuroscience and complex networks to MAS, highlighting how SW structures balance local clustering and long-range integration. Using multi-agent debate (MAD) as a controlled testbed, experiment results show that SW connectivity yields nearly the same accuracy and token cost, while substantially stabilizing consensus trajectories. Building on this, we introduce an uncertainty-guided rewiring scheme for scaling MAS, where long-range shortcuts are added between epistemically divergent agents using LLM-oriented uncertainty signals (e.g., semantic entropy). This yields controllable SW structures that adapt to task difficulty and agent heterogeneity. Finally, we discuss broader implications of SW priors for MAS design, framing them as stabilizers of reasoning, enhancers of robustness, scalable coordinators, and inductive biases for emergent cognitive roles.
Chasing Consistency: Quantifying and Optimizing Human-Model Alignment in Chain-of-Thought Reasoning
Nov 09, 2025This paper presents a framework for evaluating and optimizing reasoning consistency in Large Language Models (LLMs) via a new metric, the Alignment Score, which quantifies the semantic alignment between model-generated reasoning chains and human-written reference chains in Chain-of-Thought (CoT) reasoning. Empirically, we find that 2-hop reasoning chains achieve the highest Alignment Score. To explain this phenomenon, we define four key error types: logical disconnection, thematic shift, redundant reasoning, and causal reversal, and show how each contributes to the degradation of the Alignment Score. Building on this analysis, we further propose Semantic Consistency Optimization Sampling (SCOS), a method that samples and favors chains with minimal alignment errors, significantly improving Alignment Scores by an average of 29.84% with longer reasoning chains, such as in 3-hop tasks.
Position: Towards a Responsible LLM-empowered Multi-Agent Systems
Feb 03, 2025



The rise of Agent AI and Large Language Model-powered Multi-Agent Systems (LLM-MAS) has underscored the need for responsible and dependable system operation. Tools like LangChain and Retrieval-Augmented Generation have expanded LLM capabilities, enabling deeper integration into MAS through enhanced knowledge retrieval and reasoning. However, these advancements introduce critical challenges: LLM agents exhibit inherent unpredictability, and uncertainties in their outputs can compound across interactions, threatening system stability. To address these risks, a human-centered design approach with active dynamic moderation is essential. Such an approach enhances traditional passive oversight by facilitating coherent inter-agent communication and effective system governance, allowing MAS to achieve desired outcomes more efficiently.
Preserving Earlier Knowledge in Continual Learning with the Help of All Previous Feature Extractors
Apr 28, 2021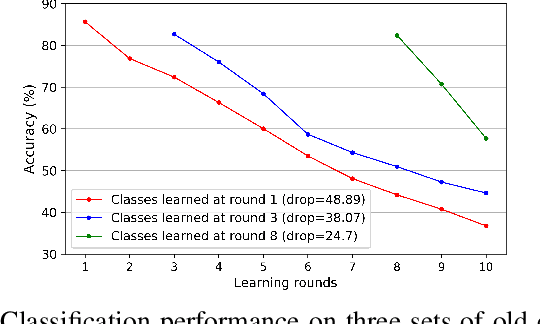
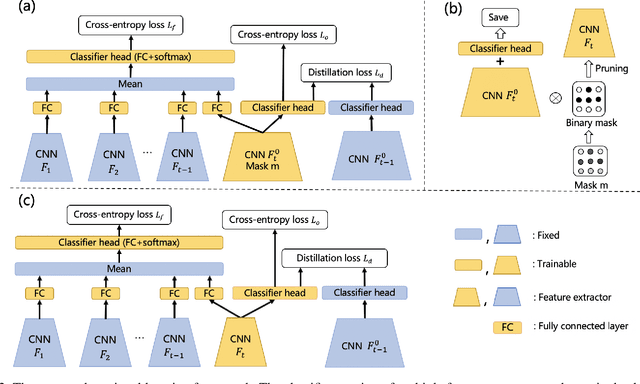
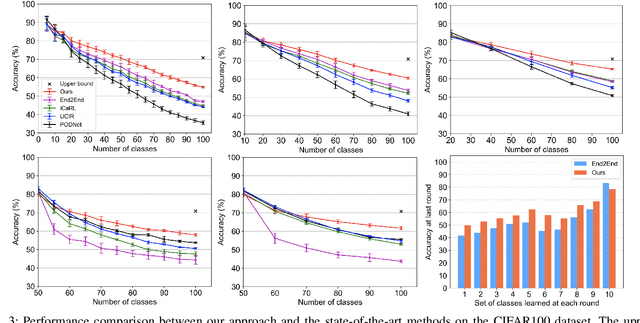
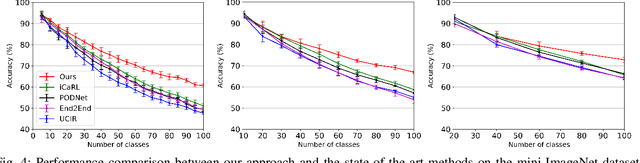
Continual learning of new knowledge over time is one desirable capability for intelligent systems to recognize more and more classes of objects. Without or with very limited amount of old data stored, an intelligent system often catastrophically forgets previously learned old knowledge when learning new knowledge. Recently, various approaches have been proposed to alleviate the catastrophic forgetting issue. However, old knowledge learned earlier is commonly less preserved than that learned more recently. In order to reduce the forgetting of particularly earlier learned old knowledge and improve the overall continual learning performance, we propose a simple yet effective fusion mechanism by including all the previously learned feature extractors into the intelligent model. In addition, a new feature extractor is included to the model when learning a new set of classes each time, and a feature extractor pruning is also applied to prevent the whole model size from growing rapidly. Experiments on multiple classification tasks show that the proposed approach can effectively reduce the forgetting of old knowledge, achieving state-of-the-art continual learning performance.