 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgebi-modal textual prompt learning for vision-language models in remote sensing
Jan 28, 2026Prompt learning (PL) has emerged as an effective strategy to adapt vision-language models (VLMs), such as CLIP, for downstream tasks under limited supervision. While PL has demonstrated strong generalization on natural image datasets, its transferability to remote sensing (RS) imagery remains underexplored. RS data present unique challenges, including multi-label scenes, high intra-class variability, and diverse spatial resolutions, that hinder the direct applicability of existing PL methods. In particular, current prompt-based approaches often struggle to identify dominant semantic cues and fail to generalize to novel classes in RS scenarios. To address these challenges, we propose BiMoRS, a lightweight bi-modal prompt learning framework tailored for RS tasks. BiMoRS employs a frozen image captioning model (e.g., BLIP-2) to extract textual semantic summaries from RS images. These captions are tokenized using a BERT tokenizer and fused with high-level visual features from the CLIP encoder. A lightweight cross-attention module then conditions a learnable query prompt on the fused textual-visual representation, yielding contextualized prompts without altering the CLIP backbone. We evaluate BiMoRS on four RS datasets across three domain generalization (DG) tasks and observe consistent performance gains, outperforming strong baselines by up to 2% on average. Codes are available at https://github.com/ipankhi/BiMoRS.
MMLGNet: Cross-Modal Alignment of Remote Sensing Data using CLIP
Jan 13, 2026In this paper, we propose a novel multimodal framework, Multimodal Language-Guided Network (MMLGNet), to align heterogeneous remote sensing modalities like Hyperspectral Imaging (HSI) and LiDAR with natural language semantics using vision-language models such as CLIP. With the increasing availability of multimodal Earth observation data, there is a growing need for methods that effectively fuse spectral, spatial, and geometric information while enabling semantic-level understanding. MMLGNet employs modality-specific encoders and aligns visual features with handcrafted textual embeddings in a shared latent space via bi-directional contrastive learning. Inspired by CLIP's training paradigm, our approach bridges the gap between high-dimensional remote sensing data and language-guided interpretation. Notably, MMLGNet achieves strong performance with simple CNN-based encoders, outperforming several established multimodal visual-only methods on two benchmark datasets, demonstrating the significant benefit of language supervision. Codes are available at https://github.com/AdityaChaudhary2913/CLIP_HSI.
SDHSI-Net: Learning Better Representations for Hyperspectral Images via Self-Distillation
Jan 12, 2026Hyperspectral image (HSI) classification presents unique challenges due to its high spectral dimensionality and limited labeled data. Traditional deep learning models often suffer from overfitting and high computational costs. Self-distillation (SD), a variant of knowledge distillation where a network learns from its own predictions, has recently emerged as a promising strategy to enhance model performance without requiring external teacher networks. In this work, we explore the application of SD to HSI by treating earlier outputs as soft targets, thereby enforcing consistency between intermediate and final predictions. This process improves intra-class compactness and inter-class separability in the learned feature space. Our approach is validated on two benchmark HSI datasets and demonstrates significant improvements in classification accuracy and robustness, highlighting the effectiveness of SD for spectral-spatial learning. Codes are available at https://github.com/Prachet-Dev-Singh/SDHSI.
Reconstruction Guided Few-shot Network For Remote Sensing Image Classification
Jan 12, 2026Few-shot remote sensing image classification is challenging due to limited labeled samples and high variability in land-cover types. We propose a reconstruction-guided few-shot network (RGFS-Net) that enhances generalization to unseen classes while preserving consistency for seen categories. Our method incorporates a masked image reconstruction task, where parts of the input are occluded and reconstructed to encourage semantically rich feature learning. This auxiliary task strengthens spatial understanding and improves class discrimination under low-data settings. We evaluated the efficacy of EuroSAT and PatternNet datasets under 1-shot and 5-shot protocols, our approach consistently outperforms existing baselines. The proposed method is simple, effective, and compatible with standard backbones, offering a robust solution for few-shot remote sensing classification. Codes are available at https://github.com/stark0908/RGFS.
FedMVP: Federated Multi-modal Visual Prompt Tuning for Vision-Language Models
Apr 29, 2025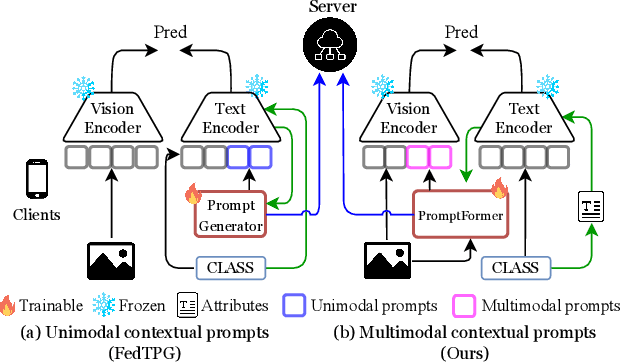
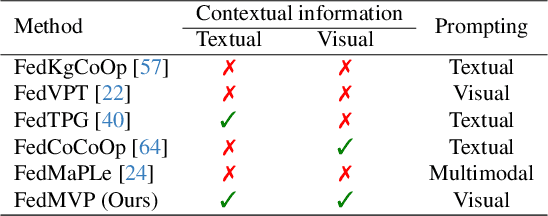
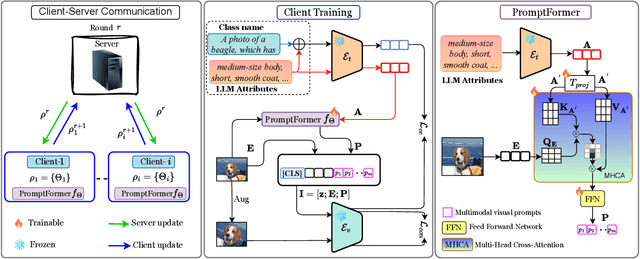
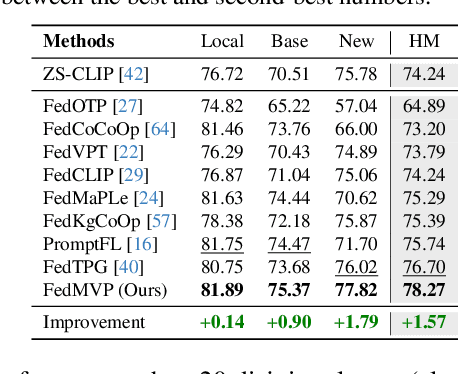
Textual prompt tuning adapts Vision-Language Models (e.g., CLIP) in federated learning by tuning lightweight input tokens (or prompts) on local client data, while keeping network weights frozen. Post training, only the prompts are shared by the clients with the central server for aggregation. However, textual prompt tuning often struggles with overfitting to known concepts and may be overly reliant on memorized text features, limiting its adaptability to unseen concepts. To address this limitation, we propose Federated Multimodal Visual Prompt Tuning (FedMVP) that conditions the prompts on comprehensive contextual information -- image-conditioned features and textual attribute features of a class -- that is multimodal in nature. At the core of FedMVP is a PromptFormer module that synergistically aligns textual and visual features through cross-attention, enabling richer contexual integration. The dynamically generated multimodal visual prompts are then input to the frozen vision encoder of CLIP, and trained with a combination of CLIP similarity loss and a consistency loss. Extensive evaluation on 20 datasets spanning three generalization settings demonstrates that FedMVP not only preserves performance on in-distribution classes and domains, but also displays higher generalizability to unseen classes and domains when compared to state-of-the-art methods. Codes will be released upon acceptance.
FrogDogNet: Fourier frequency Retained visual prompt Output Guidance for Domain Generalization of CLIP in Remote Sensing
Apr 23, 2025In recent years, large-scale vision-language models (VLMs) like CLIP have gained attention for their zero-shot inference using instructional text prompts. While these models excel in general computer vision, their potential for domain generalization in remote sensing (RS) remains underexplored. Existing approaches enhance prompt learning by generating visual prompt tokens but rely on full-image features, introducing noise and background artifacts that vary within a class, causing misclassification. To address this, we propose FrogDogNet, a novel prompt learning framework integrating Fourier frequency filtering and self-attention to improve RS scene classification and domain generalization. FrogDogNet selectively retains invariant low-frequency components while eliminating noise and irrelevant backgrounds, ensuring robust feature representation across domains. The model first extracts significant features via projection and self-attention, then applies frequency-based filtering to preserve essential structural information for prompt learning. Extensive experiments on four RS datasets and three domain generalization tasks show that FrogDogNet consistently outperforms state-of-the-art prompt learning methods, demonstrating superior adaptability across domain shifts. Our findings highlight the effectiveness of frequency-based invariant feature retention in generalization, paving the way for broader applications. Our code is available at https://github.com/HariseetharamG/FrogDogNet
AerOSeg: Harnessing SAM for Open-Vocabulary Segmentation in Remote Sensing Images
Apr 12, 2025



Image segmentation beyond predefined categories is a key challenge in remote sensing, where novel and unseen classes often emerge during inference. Open-vocabulary image Segmentation addresses these generalization issues in traditional supervised segmentation models while reducing reliance on extensive per-pixel annotations, which are both expensive and labor-intensive to obtain. Most Open-Vocabulary Segmentation (OVS) methods are designed for natural images but struggle with remote sensing data due to scale variations, orientation changes, and complex scene compositions. This necessitates the development of OVS approaches specifically tailored for remote sensing. In this context, we propose AerOSeg, a novel OVS approach for remote sensing data. First, we compute robust image-text correlation features using multiple rotated versions of the input image and domain-specific prompts. These features are then refined through spatial and class refinement blocks. Inspired by the success of the Segment Anything Model (SAM) in diverse domains, we leverage SAM features to guide the spatial refinement of correlation features. Additionally, we introduce a semantic back-projection module and loss to ensure the seamless propagation of SAM's semantic information throughout the segmentation pipeline. Finally, we enhance the refined correlation features using a multi-scale attention-aware decoder to produce the final segmentation map. We validate our SAM-guided Open-Vocabulary Remote Sensing Segmentation model on three benchmark remote sensing datasets: iSAID, DLRSD, and OpenEarthMap. Our model outperforms state-of-the-art open-vocabulary segmentation methods, achieving an average improvement of 2.54 h-mIoU.
MIMRS: A Survey on Masked Image Modeling in Remote Sensing
Apr 07, 2025


Masked Image Modeling (MIM) is a self-supervised learning technique that involves masking portions of an image, such as pixels, patches, or latent representations, and training models to predict the missing information using the visible context. This approach has emerged as a cornerstone in self-supervised learning, unlocking new possibilities in visual understanding by leveraging unannotated data for pre-training. In remote sensing, MIM addresses challenges such as incomplete data caused by cloud cover, occlusions, and sensor limitations, enabling applications like cloud removal, multi-modal data fusion, and super-resolution. By synthesizing and critically analyzing recent advancements, this survey (MIMRS) is a pioneering effort to chart the landscape of mask image modeling in remote sensing. We highlight state-of-the-art methodologies, applications, and future research directions, providing a foundational review to guide innovation in this rapidly evolving field.
REJEPA: A Novel Joint-Embedding Predictive Architecture for Efficient Remote Sensing Image Retrieval
Apr 04, 2025



The rapid expansion of remote sensing image archives demands the development of strong and efficient techniques for content-based image retrieval (RS-CBIR). This paper presents REJEPA (Retrieval with Joint-Embedding Predictive Architecture), an innovative self-supervised framework designed for unimodal RS-CBIR. REJEPA utilises spatially distributed context token encoding to forecast abstract representations of target tokens, effectively capturing high-level semantic features and eliminating unnecessary pixel-level details. In contrast to generative methods that focus on pixel reconstruction or contrastive techniques that depend on negative pairs, REJEPA functions within feature space, achieving a reduction in computational complexity of 40-60% when compared to pixel-reconstruction baselines like Masked Autoencoders (MAE). To guarantee strong and varied representations, REJEPA incorporates Variance-Invariance-Covariance Regularisation (VICReg), which prevents encoder collapse by promoting feature diversity and reducing redundancy. The method demonstrates an estimated enhancement in retrieval accuracy of 5.1% on BEN-14K (S1), 7.4% on BEN-14K (S2), 6.0% on FMoW-RGB, and 10.1% on FMoW-Sentinel compared to prominent SSL techniques, including CSMAE-SESD, Mask-VLM, SatMAE, ScaleMAE, and SatMAE++, on extensive RS benchmarks BEN-14K (multispectral and SAR data), FMoW-RGB and FMoW-Sentinel. Through effective generalisation across sensor modalities, REJEPA establishes itself as a sensor-agnostic benchmark for efficient, scalable, and precise RS-CBIR, addressing challenges like varying resolutions, high object density, and complex backgrounds with computational efficiency.
When Domain Generalization meets Generalized Category Discovery: An Adaptive Task-Arithmetic Driven Approach
Mar 21, 2025Generalized Class Discovery (GCD) clusters base and novel classes in a target domain using supervision from a source domain with only base classes. Current methods often falter with distribution shifts and typically require access to target data during training, which can sometimes be impractical. To address this issue, we introduce the novel paradigm of Domain Generalization in GCD (DG-GCD), where only source data is available for training, while the target domain, with a distinct data distribution, remains unseen until inference. To this end, our solution, DG2CD-Net, aims to construct a domain-independent, discriminative embedding space for GCD. The core innovation is an episodic training strategy that enhances cross-domain generalization by adapting a base model on tasks derived from source and synthetic domains generated by a foundation model. Each episode focuses on a cross-domain GCD task, diversifying task setups over episodes and combining open-set domain adaptation with a novel margin loss and representation learning for optimizing the feature space progressively. To capture the effects of fine-tuning on the base model, we extend task arithmetic by adaptively weighting the local task vectors concerning the fine-tuned models based on their GCD performance on a validation distribution. This episodic update mechanism boosts the adaptability of the base model to unseen targets. Experiments across three datasets confirm that DG2CD-Net outperforms existing GCD methods customized for DG-GCD.