 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Modeling with Wasserstein Autoencoders
Jul 24, 2019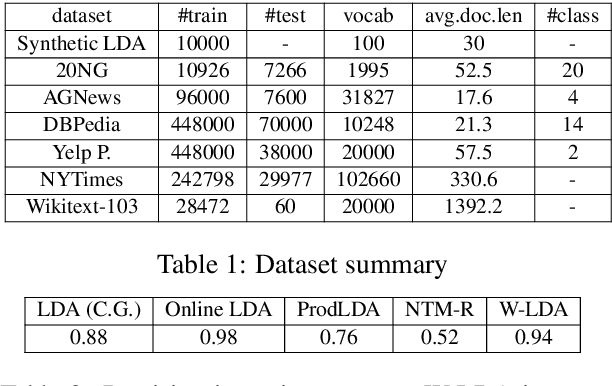
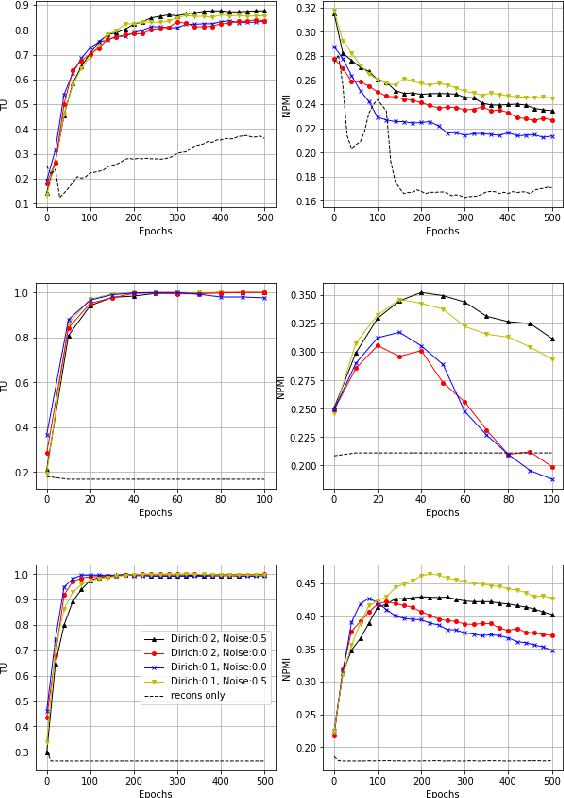

We propose a novel neural topic model in the Wasserstein autoencoders (WAE) framework. Unlike existing variational autoencoder based models, we directly enforce Dirichlet prior on the latent document-topic vectors. We exploit the structure of the latent space and apply a suitable kernel in minimizing the Maximum Mean Discrepancy (MMD) to perform distribution matching. We discover that MMD performs much better than the Generative Adversarial Network (GAN) in matching high dimensional Dirichlet distribution. We further discover that incorporating randomness in the encoder output during training leads to significantly more coherent topics. To measure the diversity of the produced topics, we propose a simple topic uniqueness metric. Together with the widely used coherence measure NPMI, we offer a more wholistic evaluation of topic quality. Experiments on several real datasets show that our model produces significantly better topics than existing topic models.
Passage Ranking with Weak Supervision
Jun 04, 2019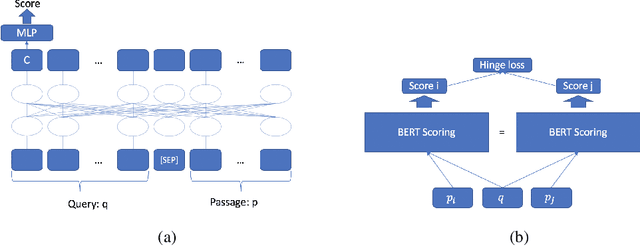

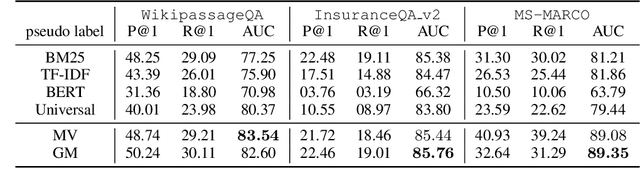
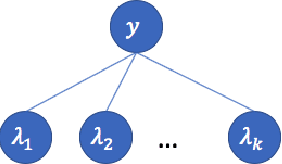
In this paper, we propose a \textit{weak supervision} framework for neural ranking tasks based on the data programming paradigm \citep{Ratner2016}, which enables us to leverage multiple weak supervision signals from different sources. Empirically, we consider two sources of weak supervision signals, unsupervised ranking functions and semantic feature similarities. We train a BERT-based passage-ranking model (which achieves new state-of-the-art performances on two benchmark datasets with full supervision) in our weak supervision framework. Without using ground-truth training labels, BERT-PR models outperform BM25 baseline by a large margin on all three datasets and even beat the previous state-of-the-art results with full supervision on two of the datasets.
* 6 pages, 1 figure
WeNet: Weighted Networks for Recurrent Network Architecture Search
Apr 08, 2019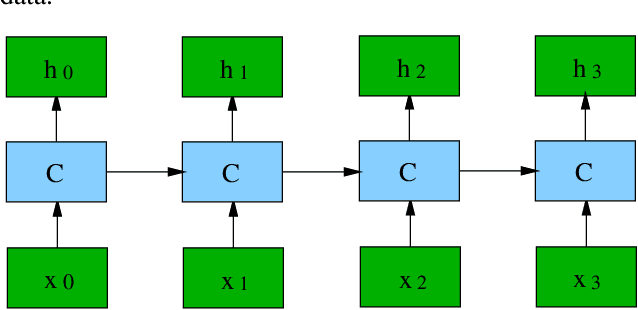
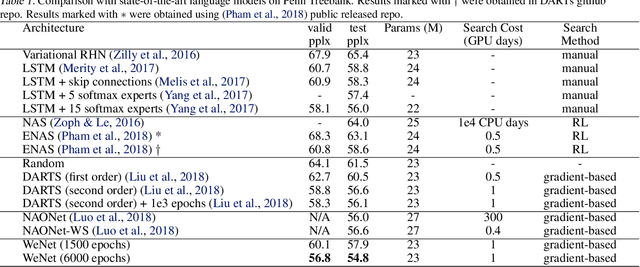
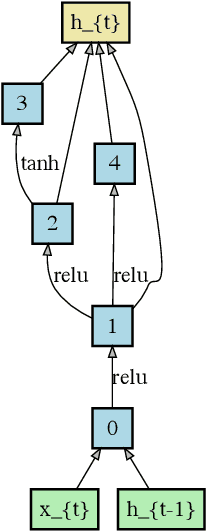
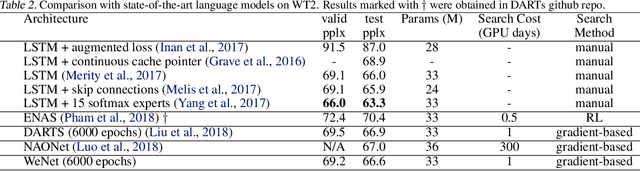
In recent years, there has been increasing demand for automatic architecture search in deep learning. Numerous approaches have been proposed and led to state-of-the-art results in various applications, including image classification and language modeling. In this paper, we propose a novel way of architecture search by means of weighted networks (WeNet), which consist of a number of networks, with each assigned a weight. These weights are updated with back-propagation to reflect the importance of different networks. Such weighted networks bear similarity to mixture of experts. We conduct experiments on Penn Treebank and WikiText-2. We show that the proposed WeNet can find recurrent architectures which result in state-of-the-art performance.
OCGAN: One-class Novelty Detection Using GANs with Constrained Latent Representations
Mar 20, 2019
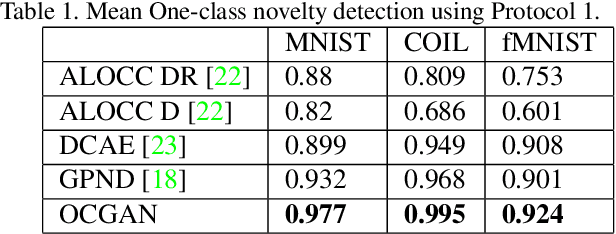
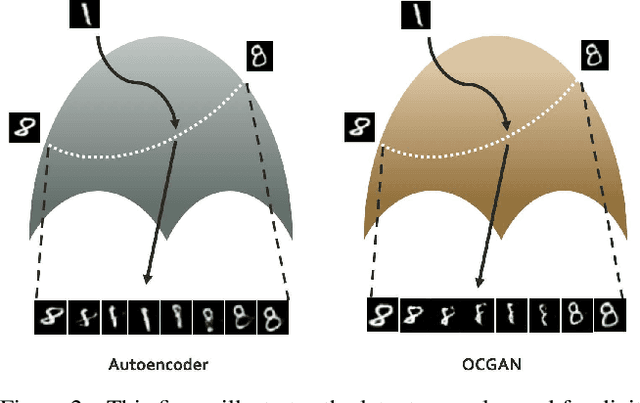
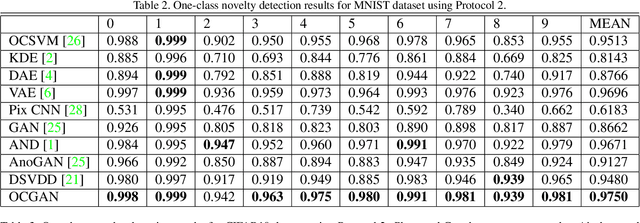
We present a novel model called OCGAN for the classical problem of one-class novelty detection, where, given a set of examples from a particular class, the goal is to determine if a query example is from the same class. Our solution is based on learning latent representations of in-class examples using a denoising auto-encoder network. The key contribution of our work is our proposal to explicitly constrain the latent space to exclusively represent the given class. In order to accomplish this goal, firstly, we force the latent space to have bounded support by introducing a tanh activation in the encoder's output layer. Secondly, using a discriminator in the latent space that is trained adversarially, we ensure that encoded representations of in-class examples resemble uniform random samples drawn from the same bounded space. Thirdly, using a second adversarial discriminator in the input space, we ensure all randomly drawn latent samples generate examples that look real. Finally, we introduce a gradient-descent based sampling technique that explores points in the latent space that generate potential out-of-class examples, which are fed back to the network to further train it to generate in-class examples from those points. The effectiveness of the proposed method is measured across four publicly available datasets using two one-class novelty detection protocols where we achieve state-of-the-art results.
Coherence-Aware Neural Topic Modeling
Sep 07, 2018
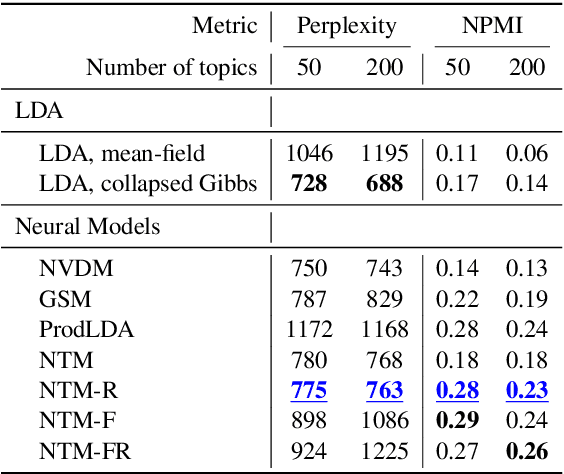
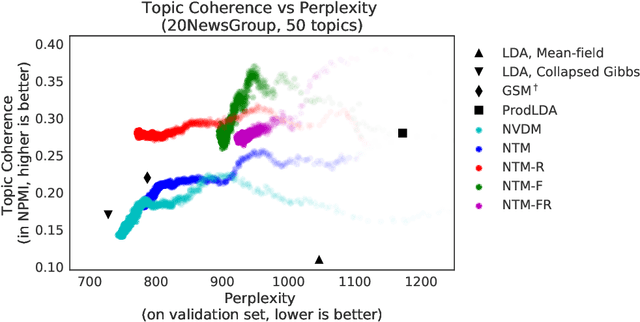
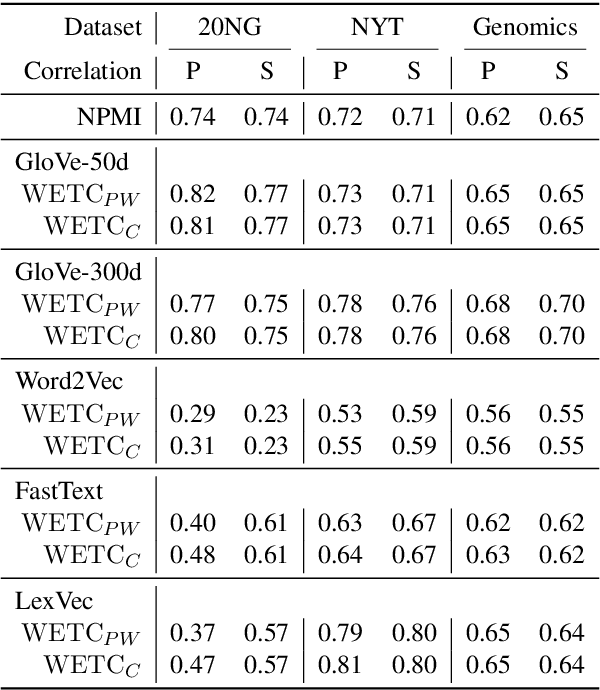
Topic models are evaluated based on their ability to describe documents well (i.e. low perplexity) and to produce topics that carry coherent semantic meaning. In topic modeling so far, perplexity is a direct optimization target. However, topic coherence, owing to its challenging computation, is not optimized for and is only evaluated after training. In this work, under a neural variational inference framework, we propose methods to incorporate a topic coherence objective into the training process. We demonstrate that such a coherence-aware topic model exhibits a similar level of perplexity as baseline models but achieves substantially higher topic coherence.
ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs
Jun 25, 2018How to model a pair of sentences is a critical issue in many NLP tasks such as answer selection (AS), paraphrase identification (PI) and textual entailment (TE). Most prior work (i) deals with one individual task by fine-tuning a specific system; (ii) models each sentence's representation separately, rarely considering the impact of the other sentence; or (iii) relies fully on manually designed, task-specific linguistic features. This work presents a general Attention Based Convolutional Neural Network (ABCNN) for modeling a pair of sentences. We make three contributions. (i) ABCNN can be applied to a wide variety of tasks that require modeling of sentence pairs. (ii) We propose three attention schemes that integrate mutual influence between sentences into CNN; thus, the representation of each sentence takes into consideration its counterpart. These interdependent sentence pair representations are more powerful than isolated sentence representations. (iii) ABCNN achieves state-of-the-art performance on AS, PI and TE tasks.
Neural Coreference Resolution with Deep Biaffine Attention by Joint Mention Detection and Mention Clustering
May 13, 2018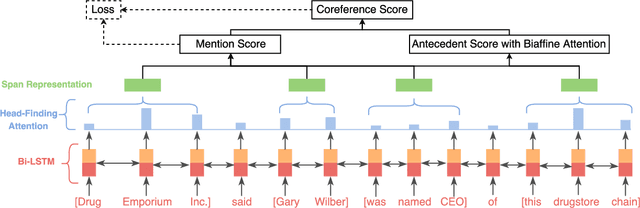
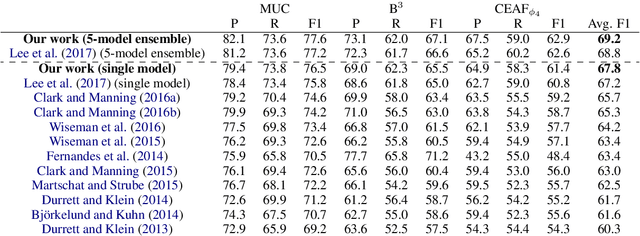
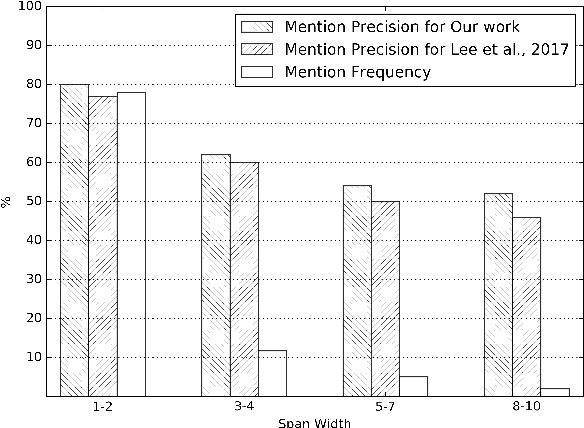

Coreference resolution aims to identify in a text all mentions that refer to the same real-world entity. The state-of-the-art end-to-end neural coreference model considers all text spans in a document as potential mentions and learns to link an antecedent for each possible mention. In this paper, we propose to improve the end-to-end coreference resolution system by (1) using a biaffine attention model to get antecedent scores for each possible mention, and (2) jointly optimizing the mention detection accuracy and the mention clustering log-likelihood given the mention cluster labels. Our model achieves the state-of-the-art performance on the CoNLL-2012 Shared Task English test set.
Group Sparse CNNs for Question Classification with Answer Sets
Oct 07, 2017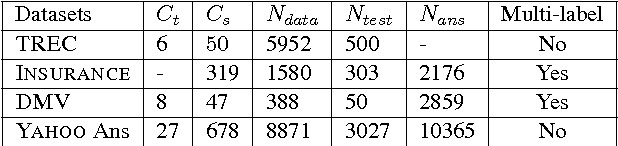

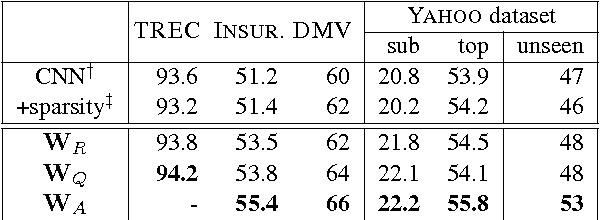
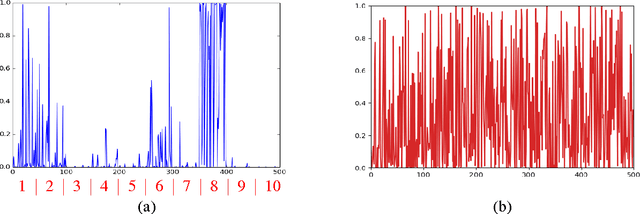
Question classification is an important task with wide applications. However, traditional techniques treat questions as general sentences, ignoring the corresponding answer data. In order to consider answer information into question modeling, we first introduce novel group sparse autoencoders which refine question representation by utilizing group information in the answer set. We then propose novel group sparse CNNs which naturally learn question representation with respect to their answers by implanting group sparse autoencoders into traditional CNNs. The proposed model significantly outperform strong baselines on four datasets.
GaDei: On Scale-up Training As A Service For Deep Learning
Oct 03, 2017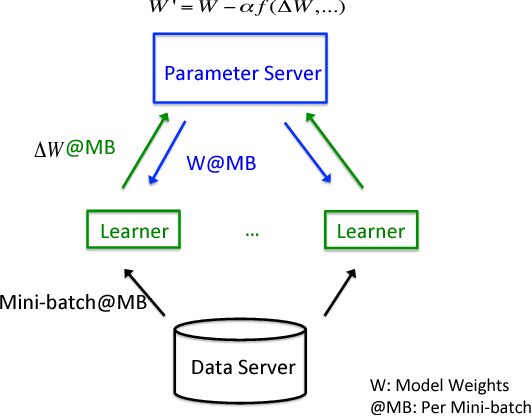
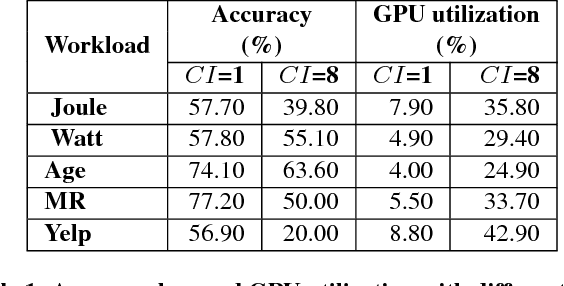
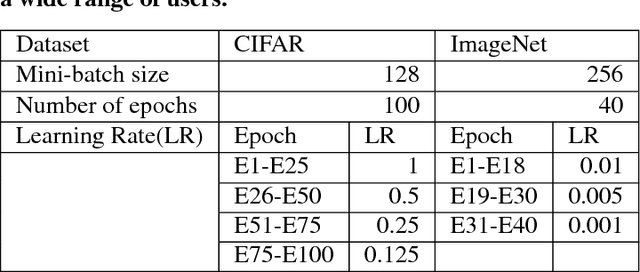
Deep learning (DL) training-as-a-service (TaaS) is an important emerging industrial workload. The unique challenge of TaaS is that it must satisfy a wide range of customers who have no experience and resources to tune DL hyper-parameters, and meticulous tuning for each user's dataset is prohibitively expensive. Therefore, TaaS hyper-parameters must be fixed with values that are applicable to all users. IBM Watson Natural Language Classifier (NLC) service, the most popular IBM cognitive service used by thousands of enterprise-level clients around the globe, is a typical TaaS service. By evaluating the NLC workloads, we show that only the conservative hyper-parameter setup (e.g., small mini-batch size and small learning rate) can guarantee acceptable model accuracy for a wide range of customers. We further justify theoretically why such a setup guarantees better model convergence in general. Unfortunately, the small mini-batch size causes a high volume of communication traffic in a parameter-server based system. We characterize the high communication bandwidth requirement of TaaS using representative industrial deep learning workloads and demonstrate that none of the state-of-the-art scale-up or scale-out solutions can satisfy such a requirement. We then present GaDei, an optimized shared-memory based scale-up parameter server design. We prove that the designed protocol is deadlock-free and it processes each gradient exactly once. Our implementation is evaluated on both commercial benchmarks and public benchmarks to demonstrate that it significantly outperforms the state-of-the-art parameter-server based implementation while maintaining the required accuracy and our implementation reaches near the best possible runtime performance, constrained only by the hardware limitation. Furthermore, to the best of our knowledge, GaDei is the only scale-up DL system that provides fault-tolerance.
Jointly Trained Sequential Labeling and Classification by Sparse Attention Neural Networks
Sep 28, 2017
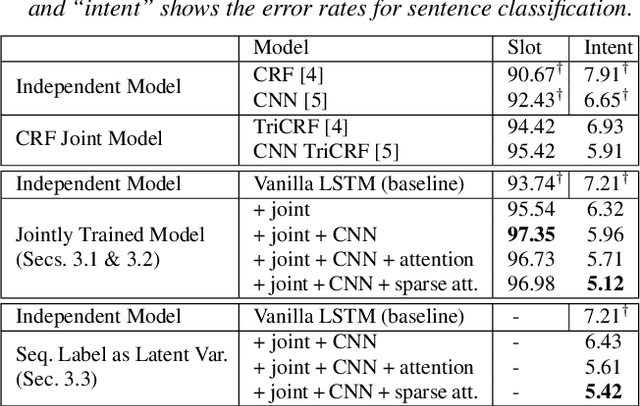
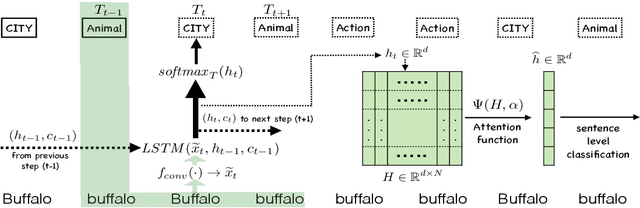
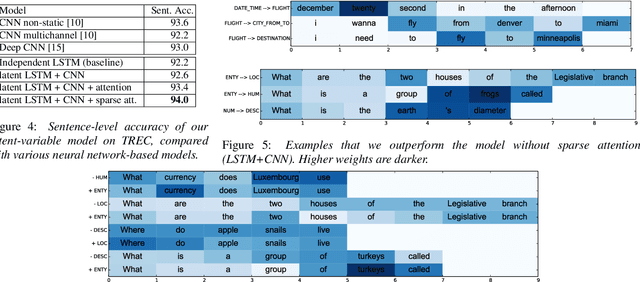
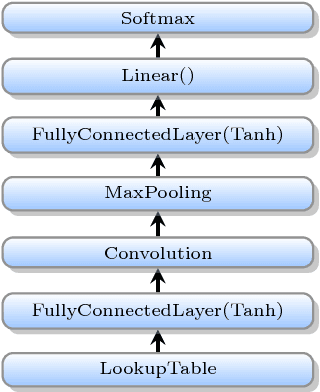
Sentence-level classification and sequential labeling are two fundamental tasks in language understanding. While these two tasks are usually modeled separately, in reality, they are often correlated, for example in intent classification and slot filling, or in topic classification and named-entity recognition. In order to utilize the potential benefits from their correlations, we propose a jointly trained model for learning the two tasks simultaneously via Long Short-Term Memory (LSTM) networks. This model predicts the sentence-level category and the word-level label sequence from the stepwise output hidden representations of LSTM. We also introduce a novel mechanism of "sparse attention" to weigh words differently based on their semantic relevance to sentence-level classification. The proposed method outperforms baseline models on ATIS and TREC datasets.