 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplicative Position-aware Transformer Models for Language Understanding
Sep 27, 2021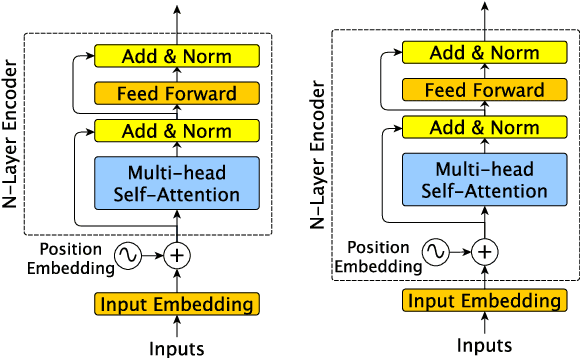

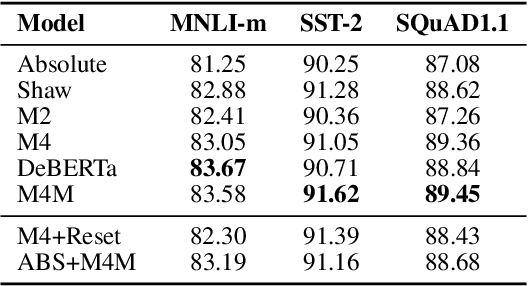
Transformer models, which leverage architectural improvements like self-attention, perform remarkably well on Natural Language Processing (NLP) tasks. The self-attention mechanism is position agnostic. In order to capture positional ordering information, various flavors of absolute and relative position embeddings have been proposed. However, there is no systematic analysis on their contributions and a comprehensive comparison of these methods is missing in the literature. In this paper, we review major existing position embedding methods and compare their accuracy on downstream NLP tasks, using our own implementations. We also propose a novel multiplicative embedding method which leads to superior accuracy when compared to existing methods. Finally, we show that our proposed embedding method, served as a drop-in replacement of the default absolute position embedding, can improve the RoBERTa-base and RoBERTa-large models on SQuAD1.1 and SQuAD2.0 datasets.
Pairwise Supervised Contrastive Learning of Sentence Representations
Sep 12, 2021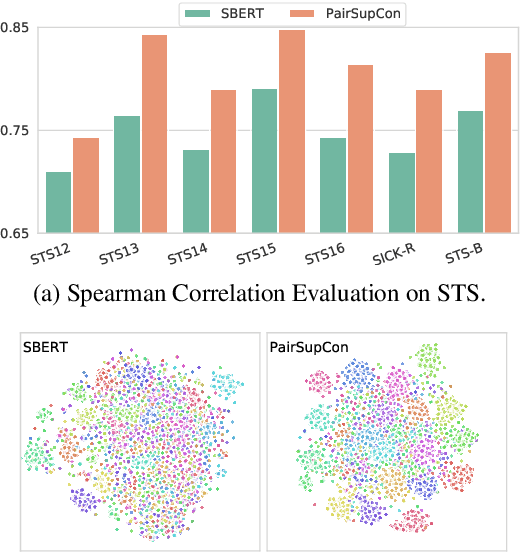
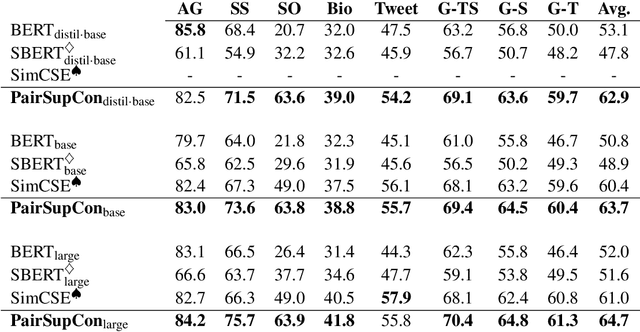
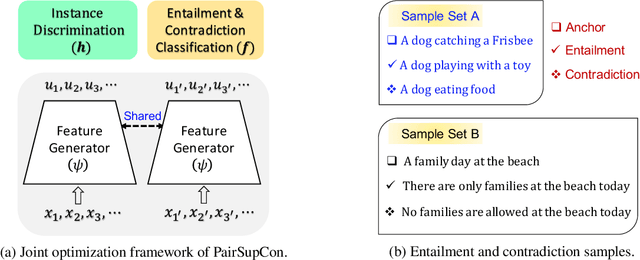
Many recent successes in sentence representation learning have been achieved by simply fine-tuning on the Natural Language Inference (NLI) datasets with triplet loss or siamese loss. Nevertheless, they share a common weakness: sentences in a contradiction pair are not necessarily from different semantic categories. Therefore, optimizing the semantic entailment and contradiction reasoning objective alone is inadequate to capture the high-level semantic structure. The drawback is compounded by the fact that the vanilla siamese or triplet losses only learn from individual sentence pairs or triplets, which often suffer from bad local optima. In this paper, we propose PairSupCon, an instance discrimination based approach aiming to bridge semantic entailment and contradiction understanding with high-level categorical concept encoding. We evaluate PairSupCon on various downstream tasks that involve understanding sentence semantics at different granularities. We outperform the previous state-of-the-art method with $10\%$--$13\%$ averaged improvement on eight clustering tasks, and $5\%$--$6\%$ averaged improvement on seven semantic textual similarity (STS) tasks.
Dual Reader-Parser on Hybrid Textual and Tabular Evidence for Open Domain Question Answering
Aug 05, 2021
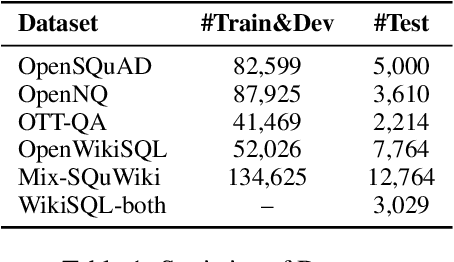
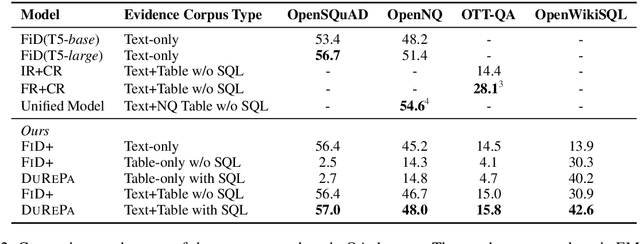
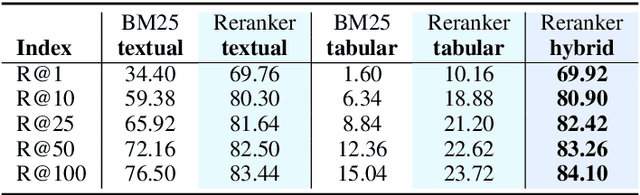
The current state-of-the-art generative models for open-domain question answering (ODQA) have focused on generating direct answers from unstructured textual information. However, a large amount of world's knowledge is stored in structured databases, and need to be accessed using query languages such as SQL. Furthermore, query languages can answer questions that require complex reasoning, as well as offering full explainability. In this paper, we propose a hybrid framework that takes both textual and tabular evidence as input and generates either direct answers or SQL queries depending on which form could better answer the question. The generated SQL queries can then be executed on the associated databases to obtain the final answers. To the best of our knowledge, this is the first paper that applies Text2SQL to ODQA tasks. Empirically, we demonstrate that on several ODQA datasets, the hybrid methods consistently outperforms the baseline models that only take homogeneous input by a large margin. Specifically we achieve state-of-the-art performance on OpenSQuAD dataset using a T5-base model. In a detailed analysis, we demonstrate that the being able to generate structural SQL queries can always bring gains, especially for those questions that requires complex reasoning.
Joint Text and Label Generation for Spoken Language Understanding
May 11, 2021

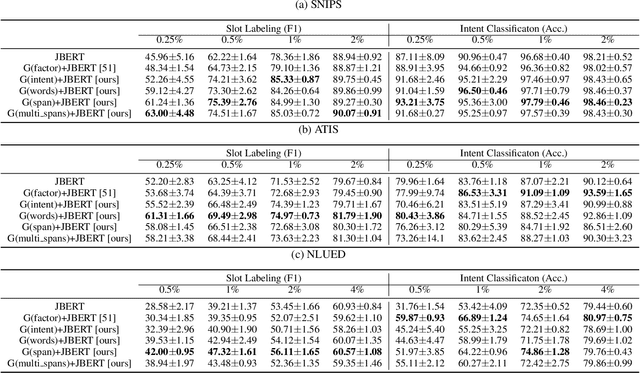
Generalization is a central problem in machine learning, especially when data is limited. Using prior information to enforce constraints is the principled way of encouraging generalization. In this work, we propose to leverage the prior information embedded in pretrained language models (LM) to improve generalization for intent classification and slot labeling tasks with limited training data. Specifically, we extract prior knowledge from pretrained LM in the form of synthetic data, which encode the prior implicitly. We fine-tune the LM to generate an augmented language, which contains not only text but also encodes both intent labels and slot labels. The generated synthetic data can be used to train a classifier later. Since the generated data may contain noise, we rephrase the learning from generated data as learning with noisy labels. We then utilize the mixout regularization for the classifier and prove its effectiveness to resist label noise in generated data. Empirically, our method demonstrates superior performance and outperforms the baseline by a large margin.
Improving Factual Consistency of Abstractive Summarization via Question Answering
May 10, 2021
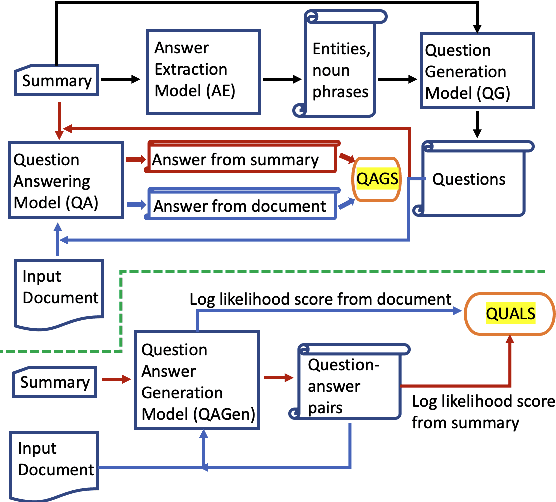
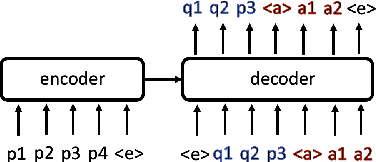
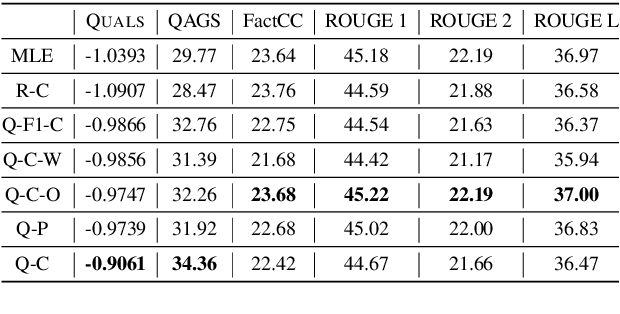
A commonly observed problem with the state-of-the art abstractive summarization models is that the generated summaries can be factually inconsistent with the input documents. The fact that automatic summarization may produce plausible-sounding yet inaccurate summaries is a major concern that limits its wide application. In this paper we present an approach to address factual consistency in summarization. We first propose an efficient automatic evaluation metric to measure factual consistency; next, we propose a novel learning algorithm that maximizes the proposed metric during model training. Through extensive experiments, we confirm that our method is effective in improving factual consistency and even overall quality of the summaries, as judged by both automatic metrics and human evaluation.
Generative Context Pair Selection for Multi-hop Question Answering
Apr 18, 2021

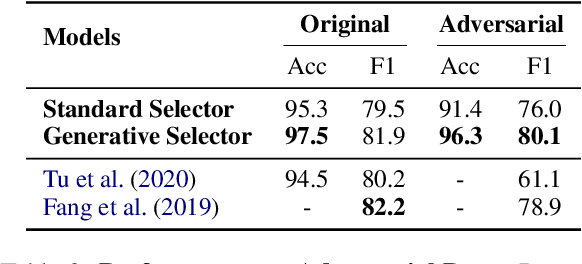

Compositional reasoning tasks like multi-hop question answering, require making latent decisions to get the final answer, given a question. However, crowdsourced datasets often capture only a slice of the underlying task distribution, which can induce unanticipated biases in models performing compositional reasoning. Furthermore, discriminatively trained models exploit such biases to get a better held-out performance, without learning the right way to reason, as they do not necessitate paying attention to the question representation (conditioning variable) in its entirety, to estimate the answer likelihood. In this work, we propose a generative context selection model for multi-hop question answering that reasons about how the given question could have been generated given a context pair. While being comparable to the state-of-the-art answering performance, our proposed generative passage selection model has a better performance (4.9% higher than baseline) on adversarial held-out set which tests robustness of model's multi-hop reasoning capabilities.
Supporting Clustering with Contrastive Learning
Mar 24, 2021
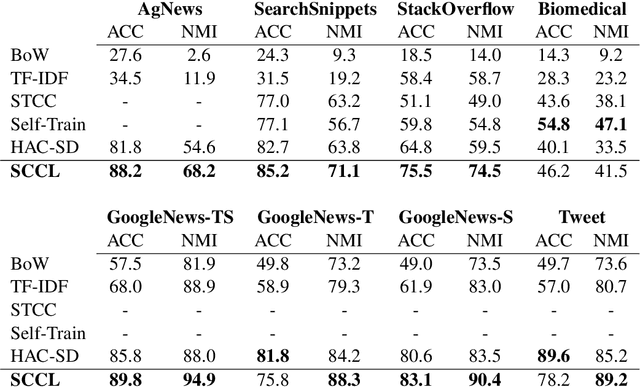
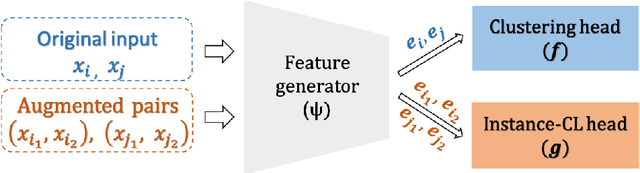
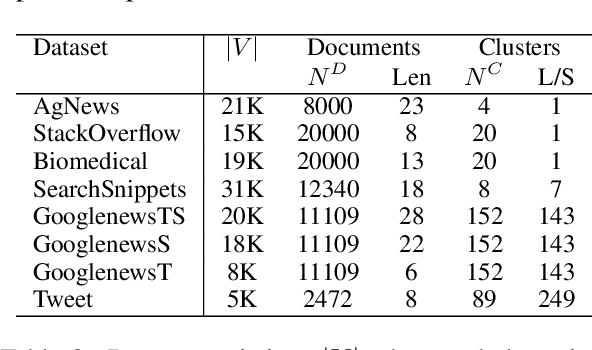
Unsupervised clustering aims at discovering the semantic categories of data according to some distance measured in the representation space. However, different categories often overlap with each other in the representation space at the beginning of the learning process, which poses a significant challenge for distance-based clustering in achieving good separation between different categories. To this end, we propose Supporting Clustering with Contrastive Learning (SCCL) -- a novel framework to leverage contrastive learning to promote better separation. We assess the performance of SCCL on short text clustering and show that SCCL significantly advances the state-of-the-art results on most benchmark datasets with 3%-11% improvement on Accuracy and 4%-15% improvement on Normalized Mutual Information. Furthermore, our quantitative analysis demonstrates the effectiveness of SCCL in leveraging the strengths of both bottom-up instance discrimination and top-down clustering to achieve better intra-cluster and inter-cluster distances when evaluated with the ground truth cluster labels
Entity-level Factual Consistency of Abstractive Text Summarization
Feb 18, 2021

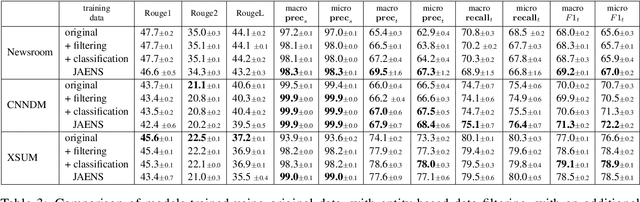

A key challenge for abstractive summarization is ensuring factual consistency of the generated summary with respect to the original document. For example, state-of-the-art models trained on existing datasets exhibit entity hallucination, generating names of entities that are not present in the source document. We propose a set of new metrics to quantify the entity-level factual consistency of generated summaries and we show that the entity hallucination problem can be alleviated by simply filtering the training data. In addition, we propose a summary-worthy entity classification task to the training process as well as a joint entity and summary generation approach, which yield further improvements in entity level metrics.
Structured Prediction as Translation between Augmented Natural Languages
Jan 28, 2021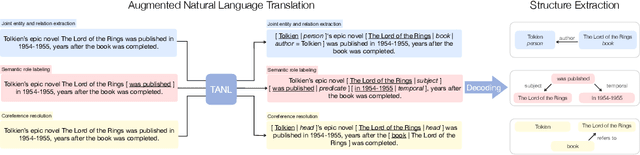
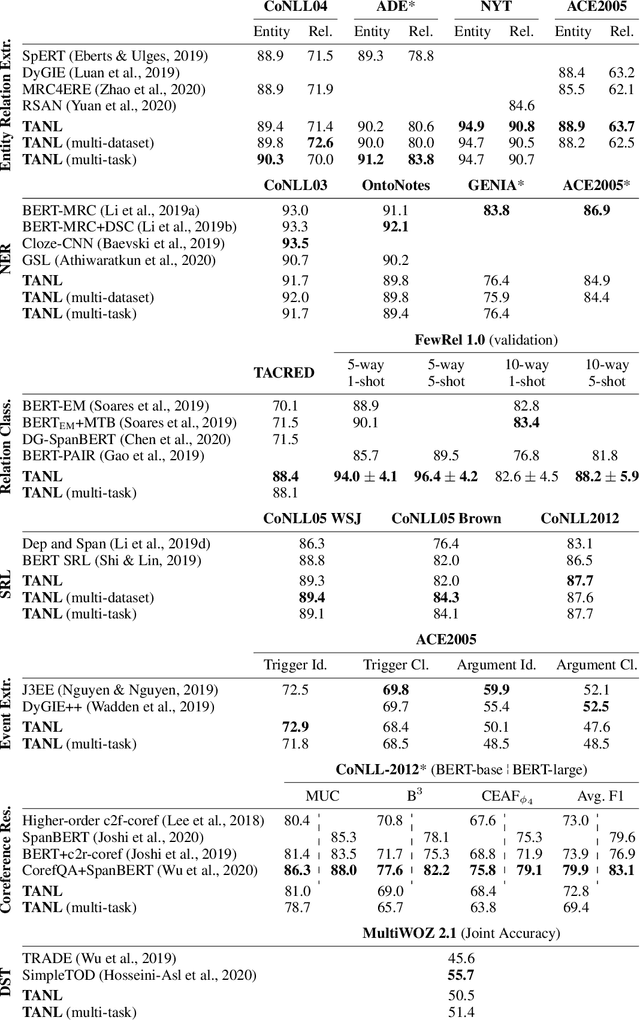
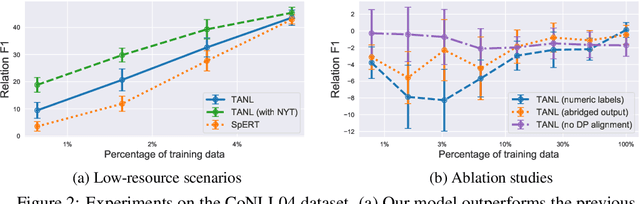
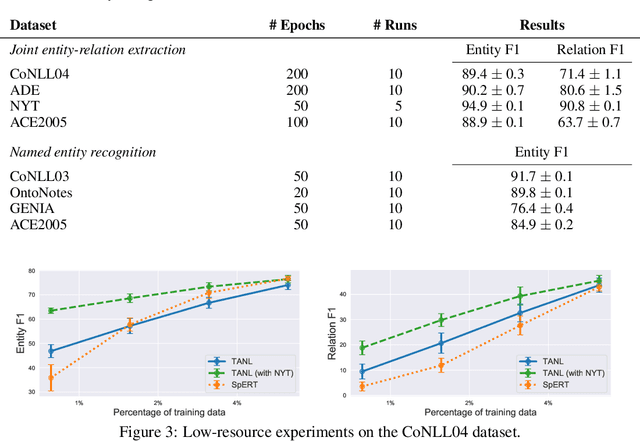
We propose a new framework, Translation between Augmented Natural Languages (TANL), to solve many structured prediction language tasks including joint entity and relation extraction, nested named entity recognition, relation classification, semantic role labeling, event extraction, coreference resolution, and dialogue state tracking. Instead of tackling the problem by training task-specific discriminative classifiers, we frame it as a translation task between augmented natural languages, from which the task-relevant information can be easily extracted. Our approach can match or outperform task-specific models on all tasks, and in particular, achieves new state-of-the-art results on joint entity and relation extraction (CoNLL04, ADE, NYT, and ACE2005 datasets), relation classification (FewRel and TACRED), and semantic role labeling (CoNLL-2005 and CoNLL-2012). We accomplish this while using the same architecture and hyperparameters for all tasks and even when training a single model to solve all tasks at the same time (multi-task learning). Finally, we show that our framework can also significantly improve the performance in a low-resource regime, thanks to better use of label semantics.
Learning Contextual Representations for Semantic Parsing with Generation-Augmented Pre-Training
Dec 18, 2020
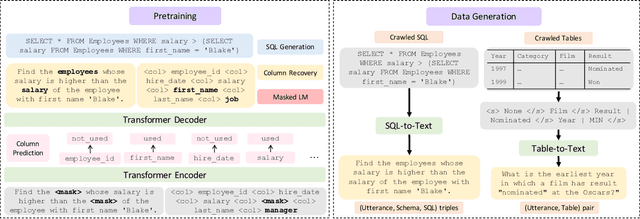
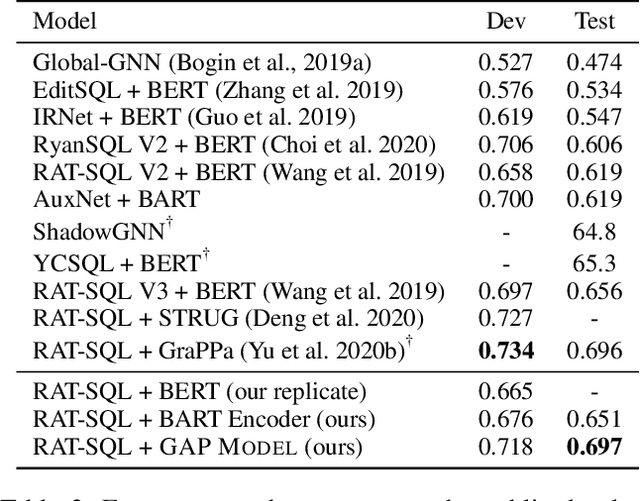
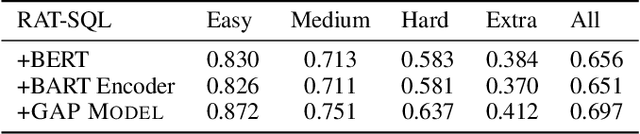
Most recently, there has been significant interest in learning contextual representations for various NLP tasks, by leveraging large scale text corpora to train large neural language models with self-supervised learning objectives, such as Masked Language Model (MLM). However, based on a pilot study, we observe three issues of existing general-purpose language models when they are applied to text-to-SQL semantic parsers: fail to detect column mentions in the utterances, fail to infer column mentions from cell values, and fail to compose complex SQL queries. To mitigate these issues, we present a model pre-training framework, Generation-Augmented Pre-training (GAP), that jointly learns representations of natural language utterances and table schemas by leveraging generation models to generate pre-train data. GAP MODEL is trained on 2M utterance-schema pairs and 30K utterance-schema-SQL triples, whose utterances are produced by generative models. Based on experimental results, neural semantic parsers that leverage GAP MODEL as a representation encoder obtain new state-of-the-art results on both SPIDER and CRITERIA-TO-SQL benchmarks.