 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep-Learning-Aided Pipeline for Efficient Post-Silicon Tuning
Jul 01, 2022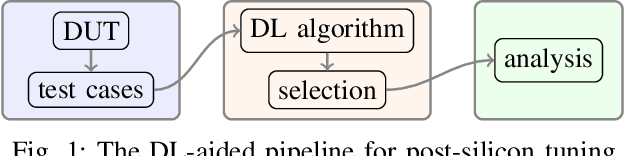
In post-silicon validation, tuning is to find the values for the tuning knobs, potentially as a function of process parameters and/or known operating conditions. In this sense, an more efficient tuning requires identifying the most critical tuning knobs and process parameters in terms of a given figure-of-merit for a Device Under Test (DUT). This is often manually conducted by experienced experts. However, with increasingly complex chips, manual inspection on a large amount of raw variables has become more challenging. In this work, we leverage neural networks to efficiently select the most relevant variables and present a corresponding deep-learning-aided pipeline for efficient tuning.
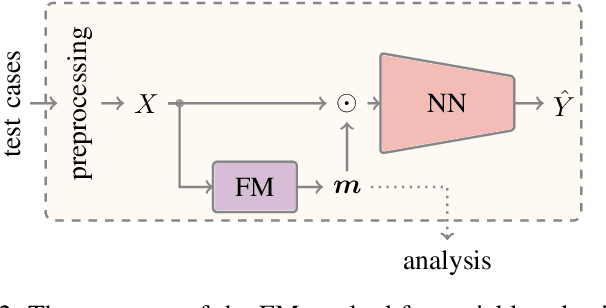
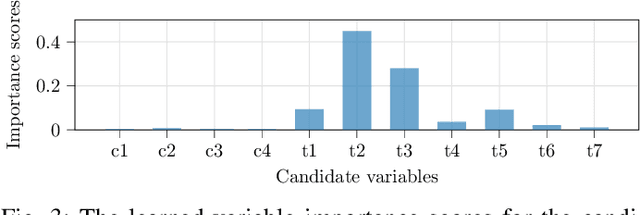
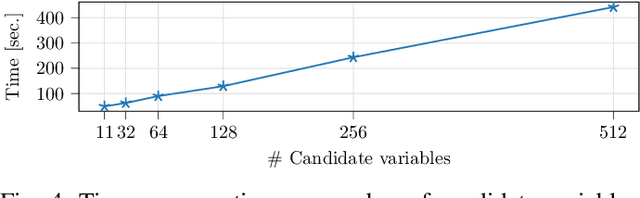
Conditional Variable Selection for Intelligent Test
Jul 01, 2022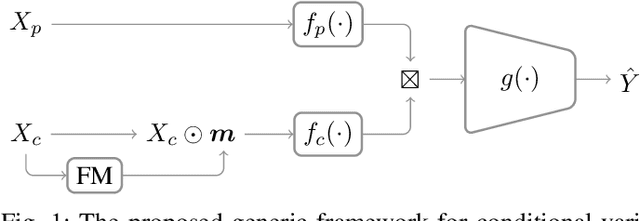
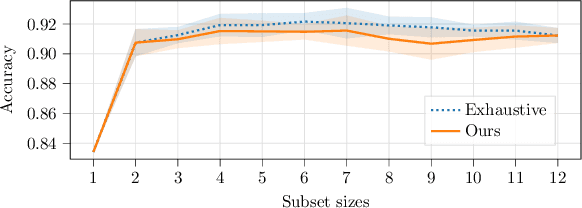
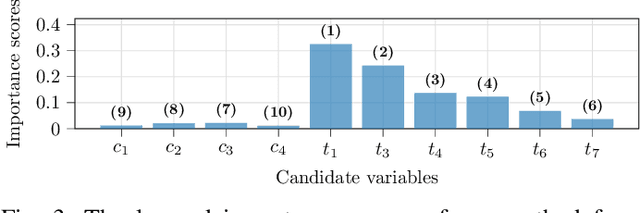
Intelligent test requires efficient and effective analysis of high-dimensional data in a large scale. Traditionally, the analysis is often conducted by human experts, but it is not scalable in the era of big data. To tackle this challenge, variable selection has been recently introduced to intelligent test. However, in practice, we encounter scenarios where certain variables (e.g. some specific processing conditions for a device under test) must be maintained after variable selection. We call this conditional variable selection, which has not been well investigated for embedded or deep-learning-based variable selection methods. In this paper, we discuss a novel conditional variable selection framework that can select the most important candidate variables given a set of preselected variables.
RetroGraph: Retrosynthetic Planning with Graph Search
Jun 23, 2022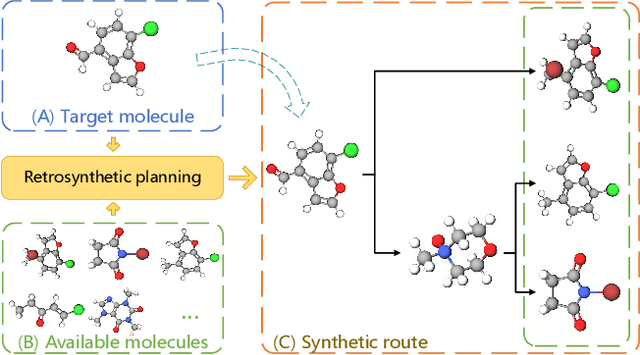
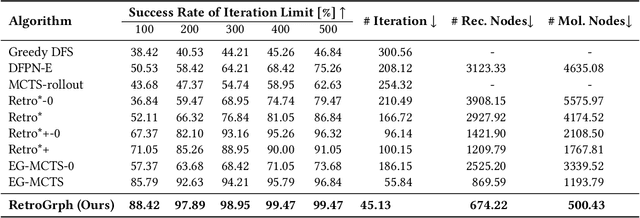
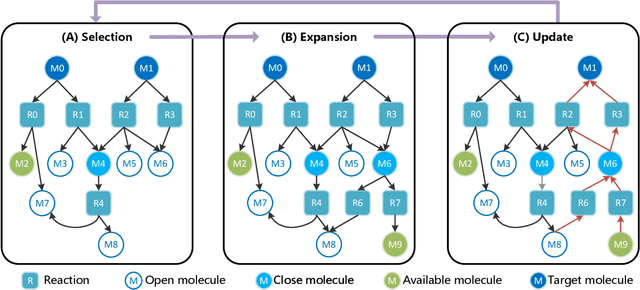

Retrosynthetic planning, which aims to find a reaction pathway to synthesize a target molecule, plays an important role in chemistry and drug discovery. This task is usually modeled as a search problem. Recently, data-driven methods have attracted many research interests and shown promising results for retrosynthetic planning. We observe that the same intermediate molecules are visited many times in the searching process, and they are usually independently treated in previous tree-based methods (e.g., AND-OR tree search, Monte Carlo tree search). Such redundancies make the search process inefficient. We propose a graph-based search policy that eliminates the redundant explorations of any intermediate molecules. As searching over a graph is more complicated than over a tree, we further adopt a graph neural network to guide the search over graphs. Meanwhile, our method can search a batch of targets together in the graph and remove the inter-target duplication in the tree-based search methods. Experimental results on two datasets demonstrate the effectiveness of our method. Especially on the widely used USPTO benchmark, we improve the search success rate to 99.47%, advancing previous state-of-the-art performance for 2.6 points.
Federated Latent Class Regression for Hierarchical Data
Jun 22, 2022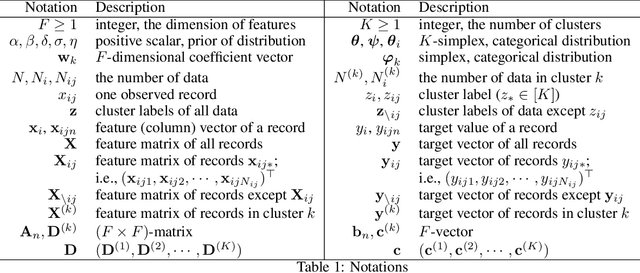
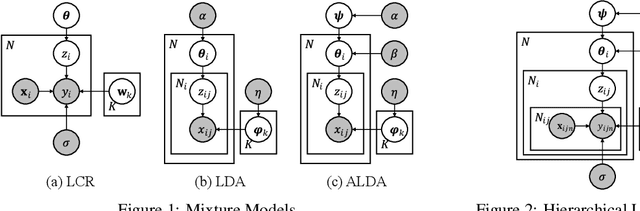
Federated Learning (FL) allows a number of agents to participate in training a global machine learning model without disclosing locally stored data. Compared to traditional distributed learning, the heterogeneity (non-IID) of the agents slows down the convergence in FL. Furthermore, many datasets, being too noisy or too small, are easily overfitted by complex models, such as deep neural networks. Here, we consider the problem of using FL regression on noisy, hierarchical and tabular datasets in which user distributions are significantly different. Inspired by Latent Class Regression (LCR), we propose a novel probabilistic model, Hierarchical Latent Class Regression (HLCR), and its extension to Federated Learning, FEDHLCR. FEDHLCR consists of a mixture of linear regression models, allowing better accuracy than simple linear regression, while at the same time maintaining its analytical properties and avoiding overfitting. Our inference algorithm, being derived from Bayesian theory, provides strong convergence guarantees and good robustness to overfitting. Experimental results show that FEDHLCR offers fast convergence even in non-IID datasets.
Conditional Seq2Seq model for the time-dependent two-level system
Jun 06, 2022
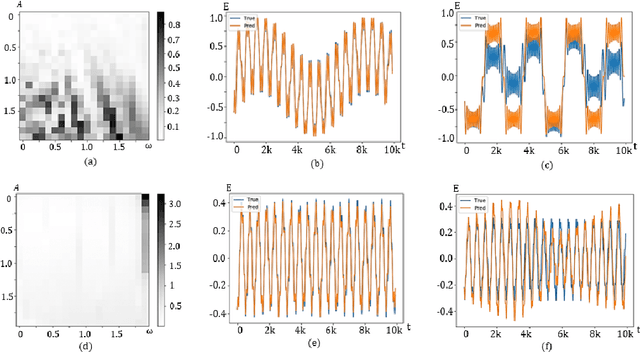
We apply the deep learning neural network architecture to the two-level system in quantum optics to solve the time-dependent Schrodinger equation. By carefully designing the network structure and tuning parameters, above 90 percent accuracy in super long-term predictions can be achieved in the case of random electric fields, which indicates a promising new method to solve the time-dependent equation for two-level systems. By slightly modifying this network, we think that this method can solve the two- or three-dimensional time-dependent Schrodinger equation more efficiently than traditional approaches.
TTAPS: Test-Time Adaption by Aligning Prototypes using Self-Supervision
May 18, 2022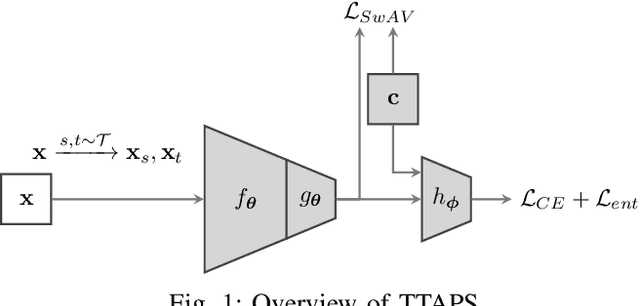
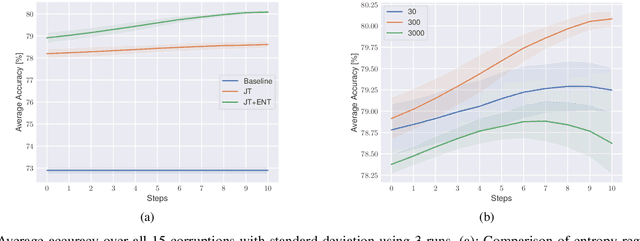
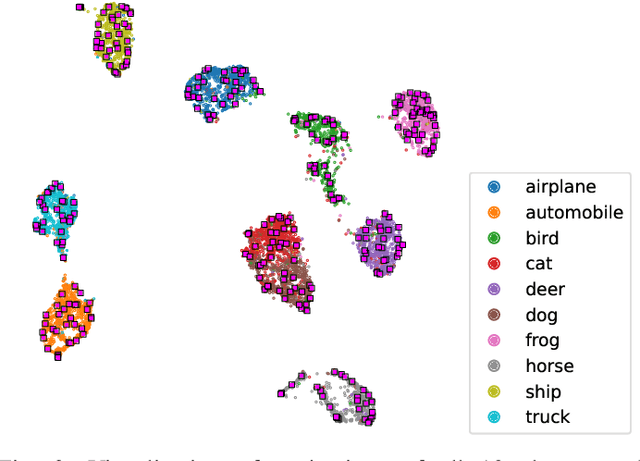

Nowadays, deep neural networks outperform humans in many tasks. However, if the input distribution drifts away from the one used in training, their performance drops significantly. Recently published research has shown that adapting the model parameters to the test sample can mitigate this performance degradation. In this paper, we therefore propose a novel modification of the self-supervised training algorithm SwAV that adds the ability to adapt to single test samples. Using the provided prototypes of SwAV and our derived test-time loss, we align the representation of unseen test samples with the self-supervised learned prototypes. We show the success of our method on the common benchmark dataset CIFAR10-C.
$(O,G)$-granular variable precision fuzzy rough sets based on overlap and grouping functions
May 18, 2022
Since Bustince et al. introduced the concepts of overlap and grouping functions, these two types of aggregation functions have attracted a lot of interest in both theory and applications. In this paper, the depiction of $(O,G)$-granular variable precision fuzzy rough sets ($(O,G)$-GVPFRSs for short) is first given based on overlap and grouping functions. Meanwhile, to work out the approximation operators efficiently, we give another expression of upper and lower approximation operators by means of fuzzy implications and co-implications. Furthermore, starting from the perspective of construction methods, $(O,G)$-GVPFRSs are represented under diverse fuzzy relations. Finally, some conclusions on the granular variable precision fuzzy rough sets (GVPFRSs for short) are extended to $(O,G)$-GVPFRSs under some additional conditions.
Some neighborhood-related fuzzy covering-based rough set models and their applications for decision making
May 13, 2022
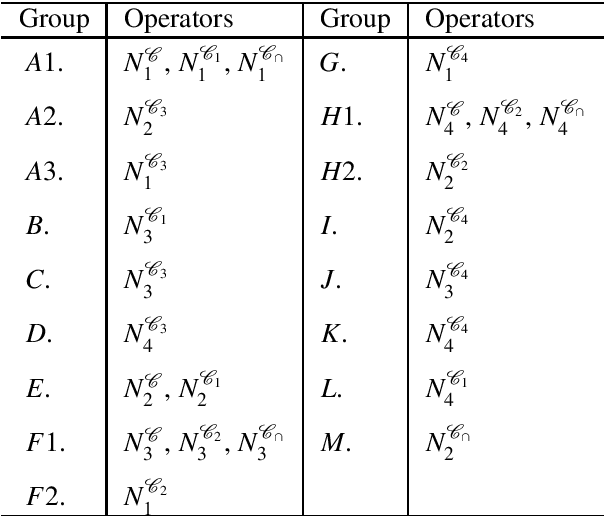
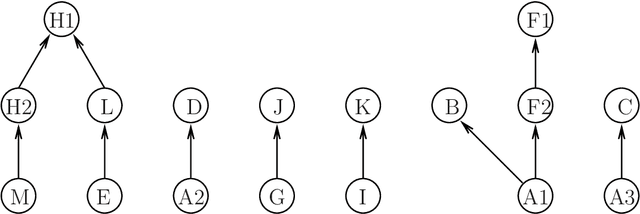
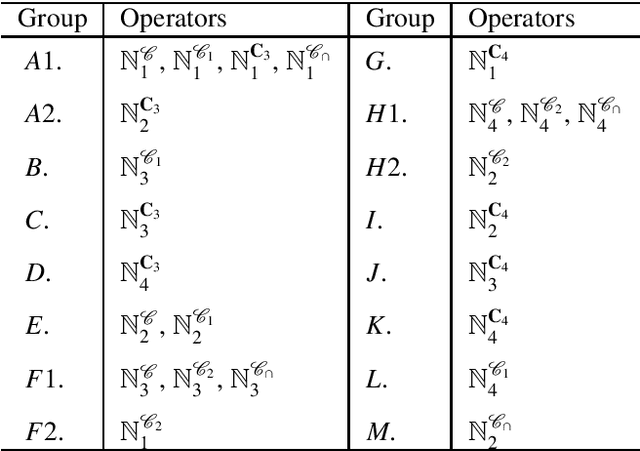
Fuzzy rough set (FRS) has a great effect on data mining processes and the fuzzy logical operators play a key role in the development of FRS theory. In order to further generalize the FRS theory to more complicated data environments, we firstly propose four types of fuzzy neighborhood operators based on fuzzy covering by overlap functions and their implicators in this paper. Meanwhile, the derived fuzzy coverings from an original fuzzy covering are defined and the equalities among overlap function-based fuzzy neighborhood operators based on a finite fuzzy covering are also investigated. Secondly, we prove that new operators can be divided into seventeen groups according to equivalence relations, and the partial order relations among these seventeen classes of operators are discussed, as well. Go further, the comparisons with $ t$-norm-based fuzzy neighborhood operators given by D'eer et al. are also made and two types of neighborhood-related fuzzy covering-based rough set models, which are defined via different fuzzy neighborhood operators that are on the basis of diverse kinds of fuzzy logical operators proposed. Furthermore, the groupings and partially order relations are also discussed. Finally, a novel fuzzy TOPSIS methodology is put forward to solve a biosynthetic nanomaterials select issue, and the rationality and enforceability of our new approach is verified by comparing its results with nine different methods.
Triformer: Triangular, Variable-Specific Attentions for Long Sequence Multivariate Time Series Forecasting--Full Version
Apr 28, 2022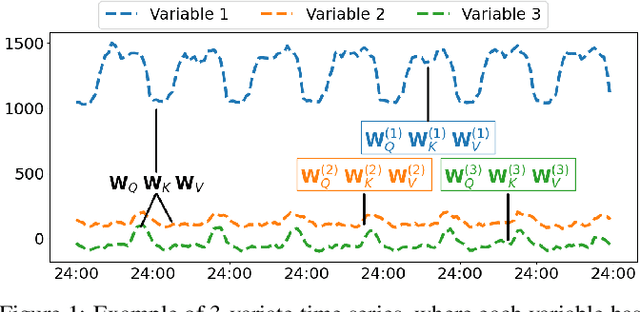
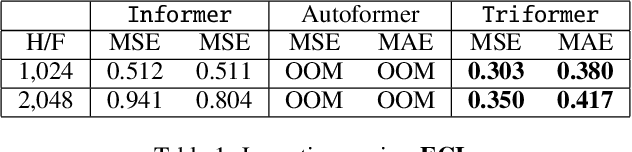
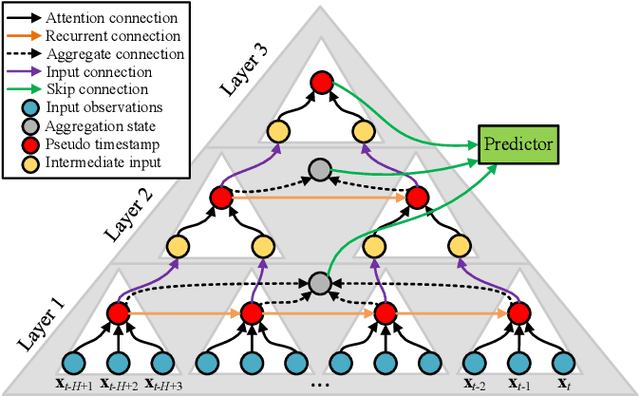
A variety of real-world applications rely on far future information to make decisions, thus calling for efficient and accurate long sequence multivariate time series forecasting. While recent attention-based forecasting models show strong abilities in capturing long-term dependencies, they still suffer from two key limitations. First, canonical self attention has a quadratic complexity w.r.t. the input time series length, thus falling short in efficiency. Second, different variables' time series often have distinct temporal dynamics, which existing studies fail to capture, as they use the same model parameter space, e.g., projection matrices, for all variables' time series, thus falling short in accuracy. To ensure high efficiency and accuracy, we propose Triformer, a triangular, variable-specific attention. (i) Linear complexity: we introduce a novel patch attention with linear complexity. When stacking multiple layers of the patch attentions, a triangular structure is proposed such that the layer sizes shrink exponentially, thus maintaining linear complexity. (ii) Variable-specific parameters: we propose a light-weight method to enable distinct sets of model parameters for different variables' time series to enhance accuracy without compromising efficiency and memory usage. Strong empirical evidence on four datasets from multiple domains justifies our design choices, and it demonstrates that Triformer outperforms state-of-the-art methods w.r.t. both accuracy and efficiency. This is an extended version of "Triformer: Triangular, Variable-Specific Attentions for Long Sequence Multivariate Time Series Forecasting", to appear in IJCAI 2022 [Cirstea et al., 2022a], including additional experimental results.
Improving the estimation of directional area scattering factor (DASF) from canopy reflectance: theoretical basis and validation
Apr 28, 2022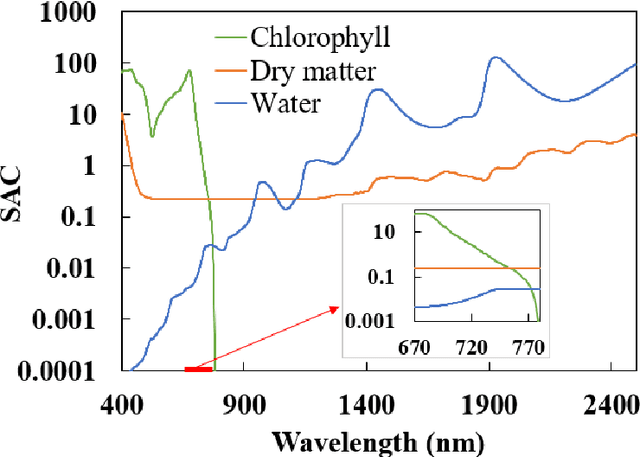
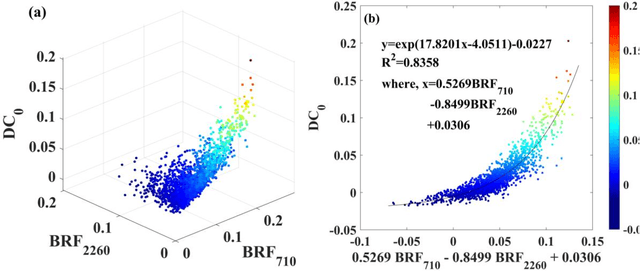
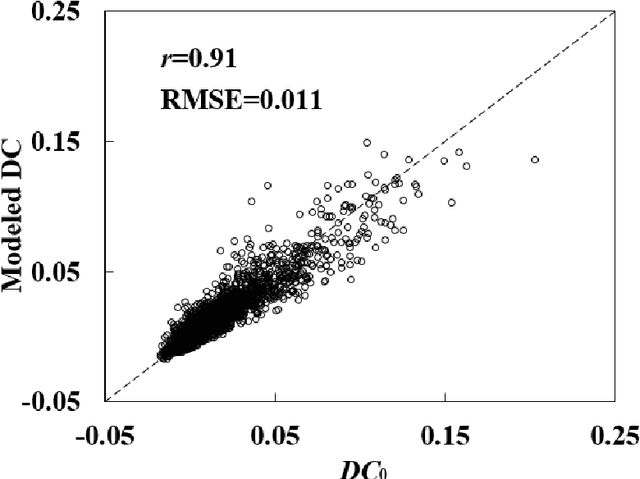
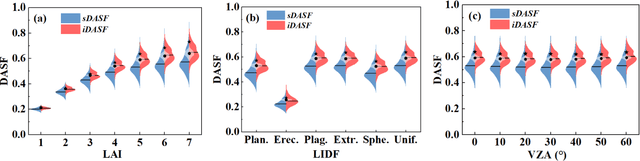
Directional area scattering factor (DASF) is a critical canopy structural parameter for vegetation monitoring. It provides an efficient tool for decoupling of canopy structure and leaf optics from canopy reflectance. Current standard approach to estimate DASF from canopy bidirectional reflectance factor (BRF) is based on the assumption that in the weakly absorbing 710 to 790 nm spectral interval, leaf scattering does not change much with the concentration of dry matter and thus its variation can be neglected. This results in biased estimates of DASF and consequently leads to uncertainty in DASF-related applications. This study proposes a new approach to account for variations in concentrations of this biochemical constituent, which additionally uses the canopy BRF at 2260 nm. In silico analysis of the proposed approach suggests significant increase in accuracy over the standard technique by a relative root mean square error (rRMSE) of 49% and 34% for one- and three dimensional scenes, respectively. When compared with indoor multi-angular hyperspectral measurements reported in literature, the mean absolute error has reduced by 68% for needle leaf and 20% for broadleaf canopies. Thus, the proposed DASF estimation approach outperforms the current one and can be used more reliably in DASF-related applications, such as vegetation monitoring of functional traits, dynamics, and radiation budget.