 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrid-VLP: Revisiting Grid Features for Vision-Language Pre-training
Aug 21, 2021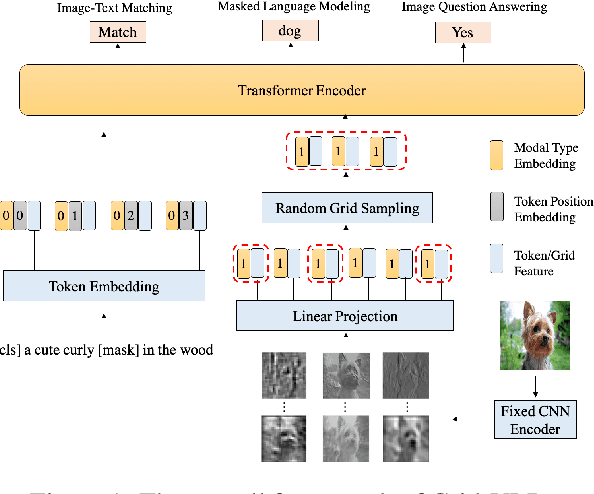
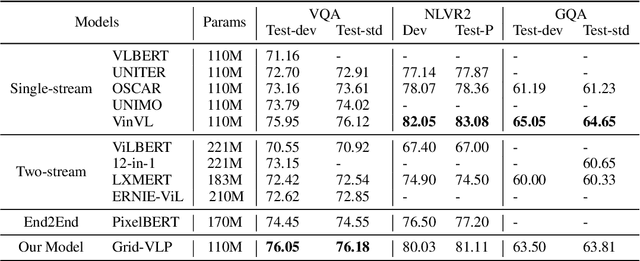
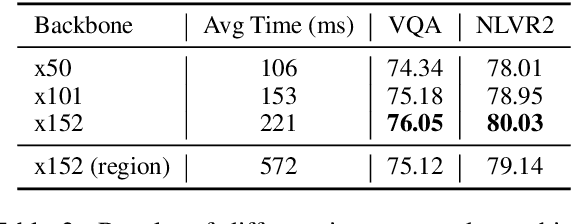
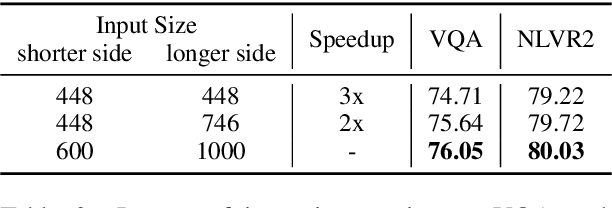
Existing approaches to vision-language pre-training (VLP) heavily rely on an object detector based on bounding boxes (regions), where salient objects are first detected from images and then a Transformer-based model is used for cross-modal fusion. Despite their superior performance, these approaches are bounded by the capability of the object detector in terms of both effectiveness and efficiency. Besides, the presence of object detection imposes unnecessary constraints on model designs and makes it difficult to support end-to-end training. In this paper, we revisit grid-based convolutional features for vision-language pre-training, skipping the expensive region-related steps. We propose a simple yet effective grid-based VLP method that works surprisingly well with the grid features. By pre-training only with in-domain datasets, the proposed Grid-VLP method can outperform most competitive region-based VLP methods on three examined vision-language understanding tasks. We hope that our findings help to further advance the state of the art of vision-language pre-training, and provide a new direction towards effective and efficient VLP.
E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning
Jun 04, 2021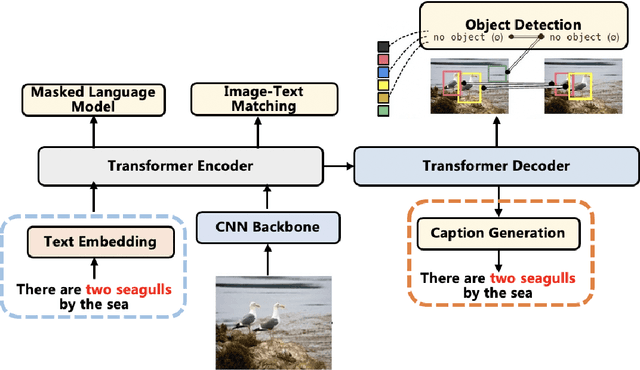
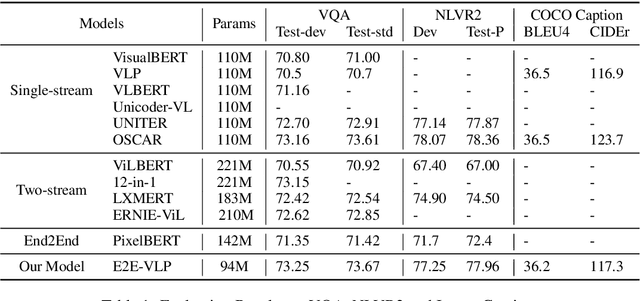
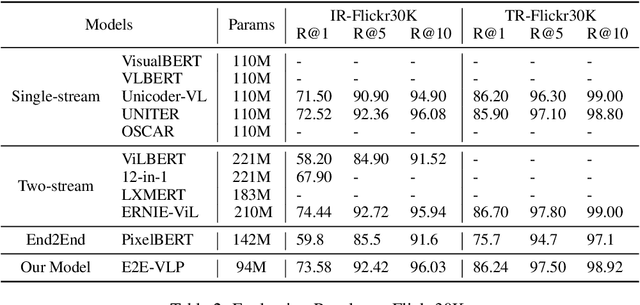
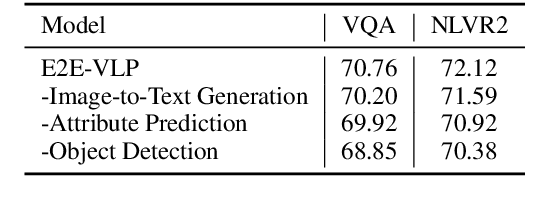
Vision-language pre-training (VLP) on large-scale image-text pairs has achieved huge success for the cross-modal downstream tasks. The most existing pre-training methods mainly adopt a two-step training procedure, which firstly employs a pre-trained object detector to extract region-based visual features, then concatenates the image representation and text embedding as the input of Transformer to train. However, these methods face problems of using task-specific visual representation of the specific object detector for generic cross-modal understanding, and the computation inefficiency of two-stage pipeline. In this paper, we propose the first end-to-end vision-language pre-trained model for both V+L understanding and generation, namely E2E-VLP, where we build a unified Transformer framework to jointly learn visual representation, and semantic alignments between image and text. We incorporate the tasks of object detection and image captioning into pre-training with a unified Transformer encoder-decoder architecture for enhancing visual learning. An extensive set of experiments have been conducted on well-established vision-language downstream tasks to demonstrate the effectiveness of this novel VLP paradigm.
StructuralLM: Structural Pre-training for Form Understanding
May 24, 2021
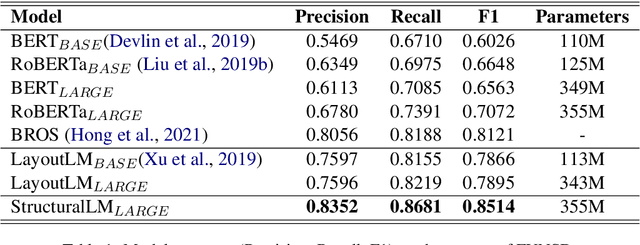
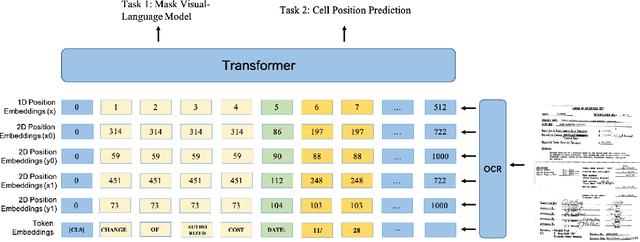
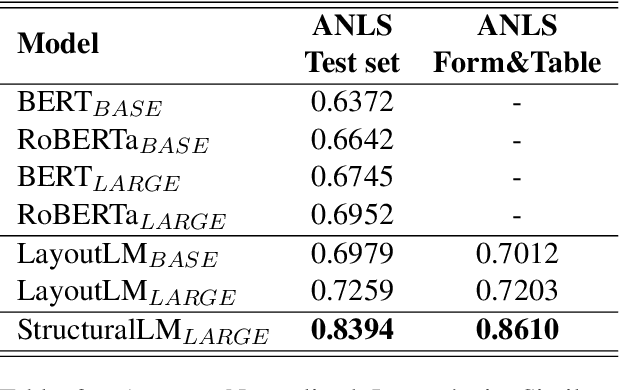
Large pre-trained language models achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, they almost exclusively focus on text-only representation, while neglecting cell-level layout information that is important for form image understanding. In this paper, we propose a new pre-training approach, StructuralLM, to jointly leverage cell and layout information from scanned documents. Specifically, we pre-train StructuralLM with two new designs to make the most of the interactions of cell and layout information: 1) each cell as a semantic unit; 2) classification of cell positions. The pre-trained StructuralLM achieves new state-of-the-art results in different types of downstream tasks, including form understanding (from 78.95 to 85.14), document visual question answering (from 72.59 to 83.94) and document image classification (from 94.43 to 96.08).
SemVLP: Vision-Language Pre-training by Aligning Semantics at Multiple Levels
Mar 14, 2021
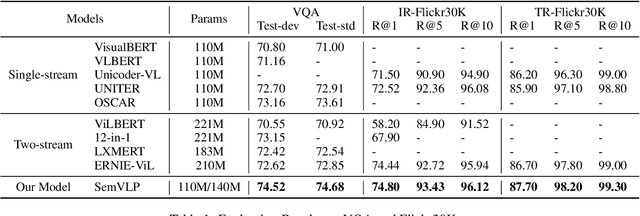
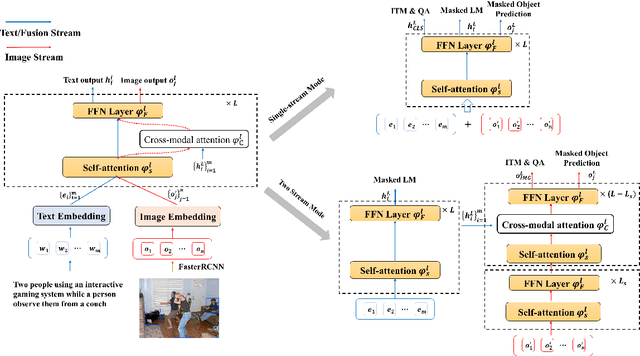

Vision-language pre-training (VLP) on large-scale image-text pairs has recently witnessed rapid progress for learning cross-modal representations. Existing pre-training methods either directly concatenate image representation and text representation at a feature level as input to a single-stream Transformer, or use a two-stream cross-modal Transformer to align the image-text representation at a high-level semantic space. In real-world image-text data, we observe that it is easy for some of the image-text pairs to align simple semantics on both modalities, while others may be related after higher-level abstraction. Therefore, in this paper, we propose a new pre-training method SemVLP, which jointly aligns both the low-level and high-level semantics between image and text representations. The model is pre-trained iteratively with two prevalent fashions: single-stream pre-training to align at a fine-grained feature level and two-stream pre-training to align high-level semantics, by employing a shared Transformer network with a pluggable cross-modal attention module. An extensive set of experiments have been conducted on four well-established vision-language understanding tasks to demonstrate the effectiveness of the proposed SemVLP in aligning cross-modal representations towards different semantic granularities.
Latent Template Induction with Gumbel-CRFs
Nov 29, 2020
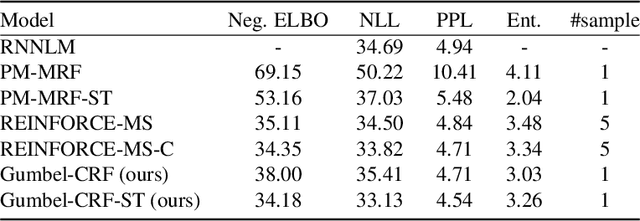
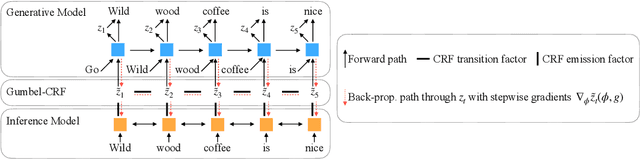
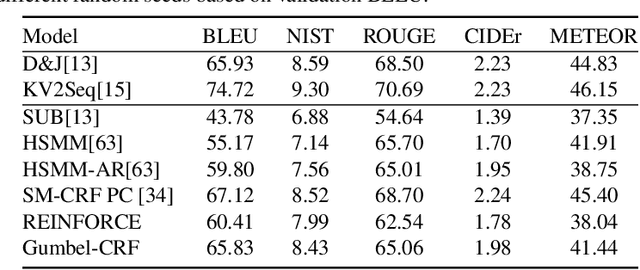
Learning to control the structure of sentences is a challenging problem in text generation. Existing work either relies on simple deterministic approaches or RL-based hard structures. We explore the use of structured variational autoencoders to infer latent templates for sentence generation using a soft, continuous relaxation in order to utilize reparameterization for training. Specifically, we propose a Gumbel-CRF, a continuous relaxation of the CRF sampling algorithm using a relaxed Forward-Filtering Backward-Sampling (FFBS) approach. As a reparameterized gradient estimator, the Gumbel-CRF gives more stable gradients than score-function based estimators. As a structured inference network, we show that it learns interpretable templates during training, which allows us to control the decoder during testing. We demonstrate the effectiveness of our methods with experiments on data-to-text generation and unsupervised paraphrase generation.
VECO: Variable Encoder-decoder Pre-training for Cross-lingual Understanding and Generation
Oct 30, 2020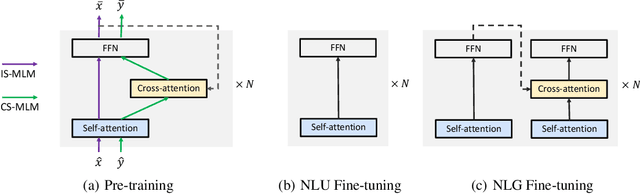
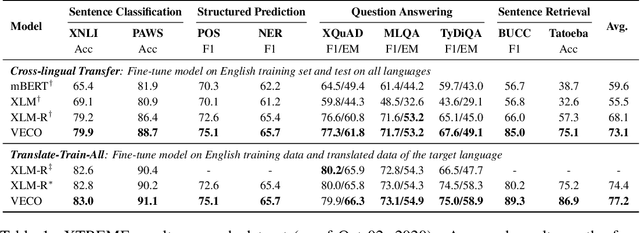

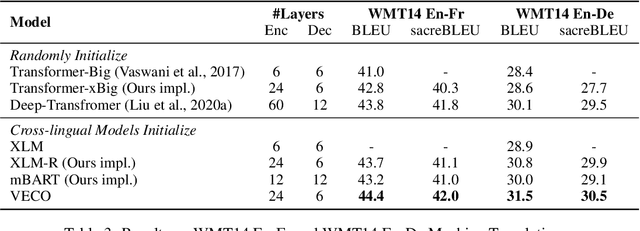
Recent studies about learning multilingual representations have achieved significant performance gains across a wide range of downstream cross-lingual tasks. They train either an encoder-only Transformer mainly for understanding tasks, or an encoder-decoder Transformer specifically for generation tasks, ignoring the correlation between the two tasks and frameworks. In contrast, this paper presents a variable encoder-decoder (VECO) pre-training approach to unify the two mainstreams in both model architectures and pre-training tasks. VECO splits the standard Transformer block into several sub-modules trained with both inner-sequence and cross-sequence masked language modeling, and correspondingly reorganizes certain sub-modules for understanding and generation tasks during inference. Such a workflow not only ensures to train the most streamlined parameters necessary for two kinds of tasks, but also enables them to boost each other via sharing common sub-modules. As a result, VECO delivers new state-of-the-art results on various cross-lingual understanding tasks of the XTREME benchmark covering text classification, sequence labeling, question answering, and sentence retrieval. For generation tasks, VECO also outperforms all existing cross-lingual models and state-of-the-art Transformer variants on WMT14 English-to-German and English-to-French translation datasets, with gains of up to 1$\sim$2 BLEU.
PALM: Pre-training an Autoencoding&Autoregressive Language Model for Context-conditioned Generation
Apr 14, 2020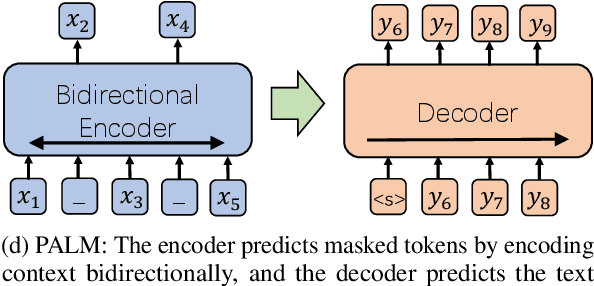

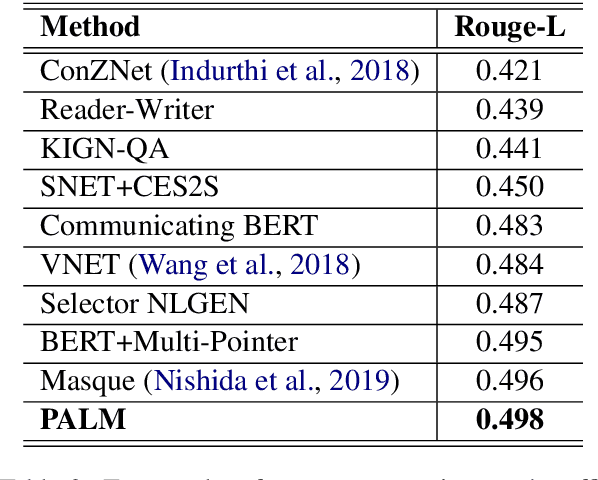
Self-supervised pre-training has emerged as a powerful technique for natural language understanding and generation, such as BERT, MASS and BART. The existing pre-training techniques employ autoencoding and/or autoregressive objectives to train Transformer-based models by recovering original word tokens from corrupted text with some masked tokens. In this work, we present PALM which pre-trains an autoencoding and autoregressive language model on a large unlabeled corpus especially for downstream generation conditioned on context, such as generative question answering and conversational response generation. PALM minimizes the mismatch introduced by the existing denoising scheme between pre-training and fine-tuning where generation is more than reconstructing original text. With a novel pre-training scheme, PALM achieves new state-of-the-art results on a variety of language generation benchmarks covering generative question answering (Rank 1 on the official MARCO leaderboard), abstractive summarization on Gigaword and conversational response generation on Cornell Movie Dialogues.
Symmetric Regularization based BERT for Pair-wise Semantic Reasoning
Sep 08, 2019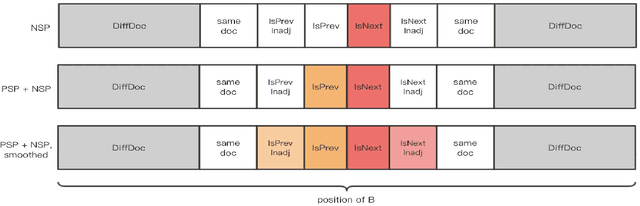
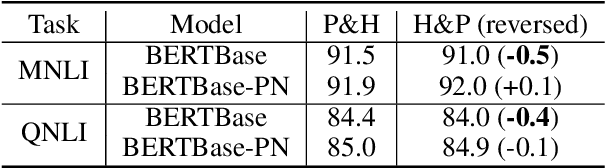
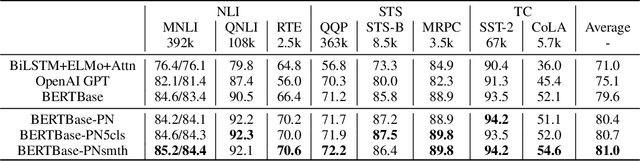
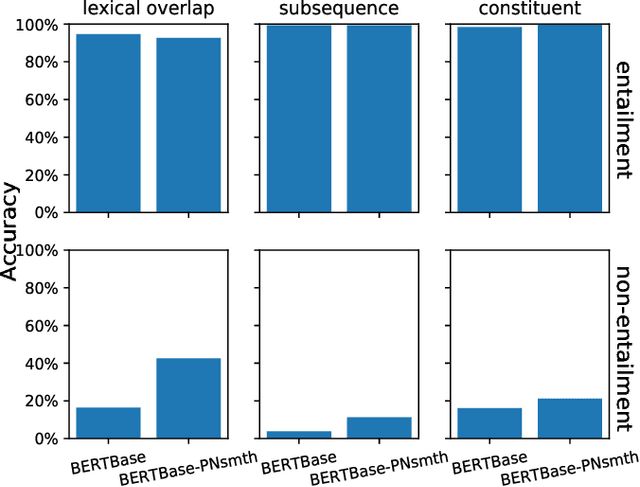
The ability of semantic reasoning over the sentence pair is essential for many natural language understanding tasks, e.g., natural language inference and machine reading comprehension. A recent significant improvement in these tasks comes from BERT. As reported, the next sentence prediction (NSP) in BERT, which learns the contextual relationship between two sentences, is of great significance for downstream problems with sentence-pair input. Despite the effectiveness of NSP, we suggest that NSP still lacks the essential signal to distinguish between entailment and shallow correlation. To remedy this, we propose to augment the NSP task to a 3-class categorization task, which includes a category for previous sentence prediction (PSP). The involvement of PSP encourages the model to focus on the informative semantics to determine the sentence order, thereby improves the ability of semantic understanding. This simple modification yields remarkable improvement against vanilla BERT. To further incorporate the document-level information, the scope of NSP and PSP is expanded into a broader range, i.e., NSP and PSP also include close but nonsuccessive sentences, the noise of which is mitigated by the label-smoothing technique. Both qualitative and quantitative experimental results demonstrate the effectiveness of the proposed method. Our method consistently improves the performance on the NLI and MRC benchmarks, including the challenging HANS dataset~\cite{hans}, suggesting that the document-level task is still promising for the pre-training.
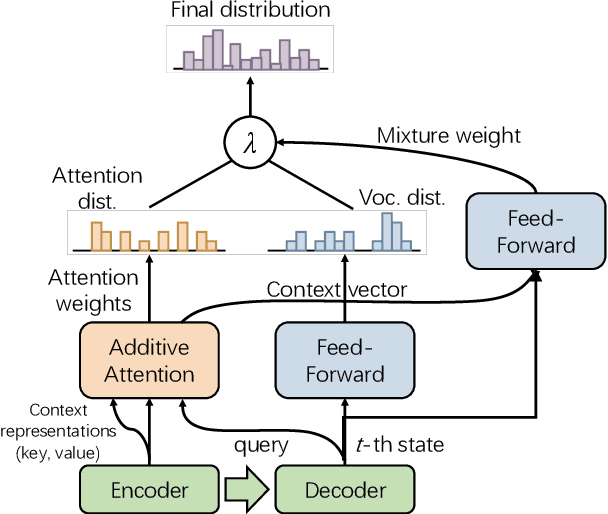
Incorporating External Knowledge into Machine Reading for Generative Question Answering
Sep 06, 2019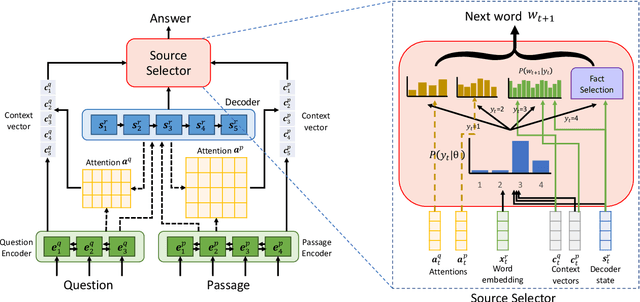
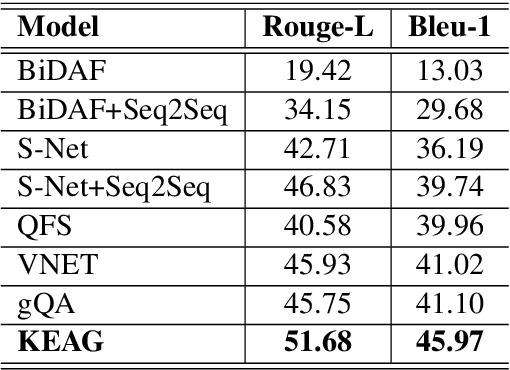
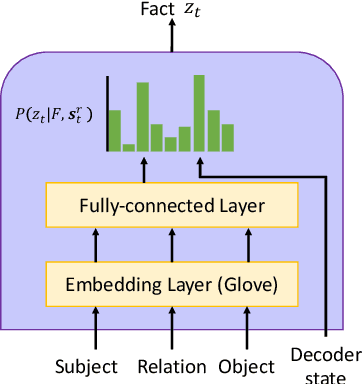
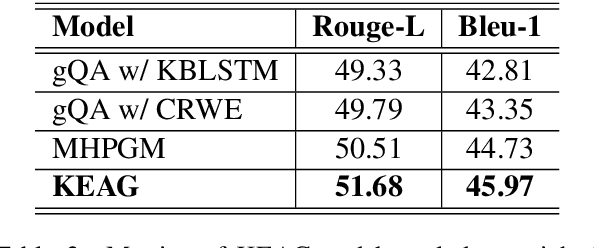
Commonsense and background knowledge is required for a QA model to answer many nontrivial questions. Different from existing work on knowledge-aware QA, we focus on a more challenging task of leveraging external knowledge to generate answers in natural language for a given question with context. In this paper, we propose a new neural model, Knowledge-Enriched Answer Generator (KEAG), which is able to compose a natural answer by exploiting and aggregating evidence from all four information sources available: question, passage, vocabulary and knowledge. During the process of answer generation, KEAG adaptively determines when to utilize symbolic knowledge and which fact from the knowledge is useful. This allows the model to exploit external knowledge that is not explicitly stated in the given text, but that is relevant for generating an answer. The empirical study on public benchmark of answer generation demonstrates that KEAG improves answer quality over models without knowledge and existing knowledge-aware models, confirming its effectiveness in leveraging knowledge.
StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding
Aug 16, 2019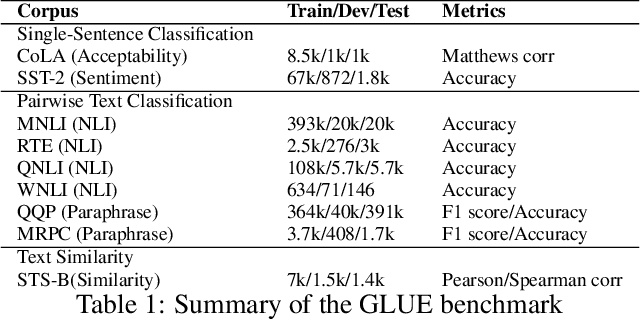
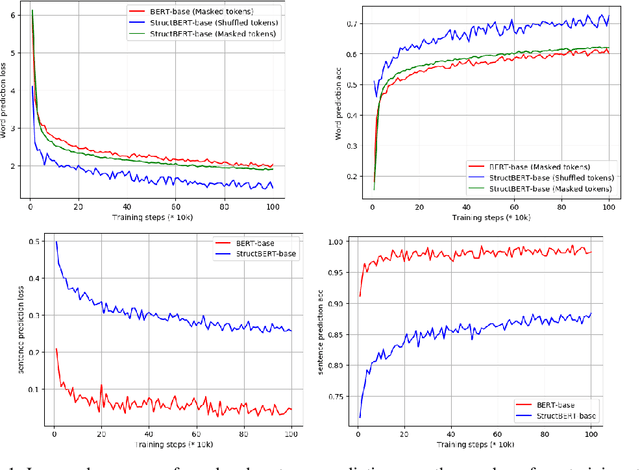
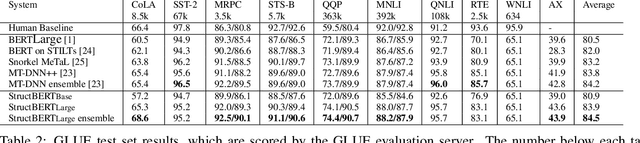

Recently, the pre-trained language model, BERT, has attracted a lot of attention in natural language understanding (NLU), and achieved state-of-the-art accuracy in various NLU tasks, such as sentiment classification, natural language inference, semantic textual similarity and question answering. Inspired by the linearization exploration work of Elman, we extend BERT to a new model, StructBERT, by incorporating language structures into pre-training. Specifically, we pre-train StructBERT with two auxiliary tasks to make the most of the sequential order of words and sentences, which leverage language structures at the word and sentence levels, respectively. As a result, the new model is adapted to different levels of language understanding required by downstream tasks. The StructBERT with structural pre-training gives surprisingly good empirical results on a variety of downstream tasks, including pushing the state-of-the-art on the GLUE benchmark to 84.5 (with Top 1 achievement on the Leaderboard at the time of paper submission), the F1 score on SQuAD v1.1 question answering to 93.0, the accuracy on SNLI to 91.7.