 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVecGlypher: Unified Vector Glyph Generation with Language Models
Feb 25, 2026Vector glyphs are the atomic units of digital typography, yet most learning-based pipelines still depend on carefully curated exemplar sheets and raster-to-vector postprocessing, which limits accessibility and editability. We introduce VecGlypher, a single multimodal language model that generates high-fidelity vector glyphs directly from text descriptions or image exemplars. Given a style prompt, optional reference glyph images, and a target character, VecGlypher autoregressively emits SVG path tokens, avoiding raster intermediates and producing editable, watertight outlines in one pass. A typography-aware data and training recipe makes this possible: (i) a large-scale continuation stage on 39K noisy Envato fonts to master SVG syntax and long-horizon geometry, followed by (ii) post-training on 2.5K expert-annotated Google Fonts with descriptive tags and exemplars to align language and imagery with geometry; preprocessing normalizes coordinate frames, canonicalizes paths, de-duplicates families, and quantizes coordinates for stable long-sequence decoding. On cross-family OOD evaluation, VecGlypher substantially outperforms both general-purpose LLMs and specialized vector-font baselines for text-only generation, while image-referenced generation reaches a state-of-the-art performance, with marked gains over DeepVecFont-v2 and DualVector. Ablations show that model scale and the two-stage recipe are critical and that absolute-coordinate serialization yields the best geometry. VecGlypher lowers the barrier to font creation by letting users design with words or exemplars, and provides a scalable foundation for future multimodal design tools.
AIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
Souper-Model: How Simple Arithmetic Unlocks State-of-the-Art LLM Performance
Nov 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse domains, but their training remains resource- and time-intensive, requiring massive compute power and careful orchestration of training procedures. Model souping-the practice of averaging weights from multiple models of the same architecture-has emerged as a promising pre- and post-training technique that can enhance performance without expensive retraining. In this paper, we introduce Soup Of Category Experts (SoCE), a principled approach for model souping that utilizes benchmark composition to identify optimal model candidates and applies non-uniform weighted averaging to maximize performance. Contrary to previous uniform-averaging approaches, our method leverages the observation that benchmark categories often exhibit low inter-correlations in model performance. SoCE identifies "expert" models for each weakly-correlated category cluster and combines them using optimized weighted averaging rather than uniform weights. We demonstrate that the proposed method improves performance and robustness across multiple domains, including multilingual capabilities, tool calling, and math and achieves state-of-the-art results on the Berkeley Function Calling Leaderboard.
Centroid Based Binary Tree Structured SVM for Multi Classification
Dec 02, 2015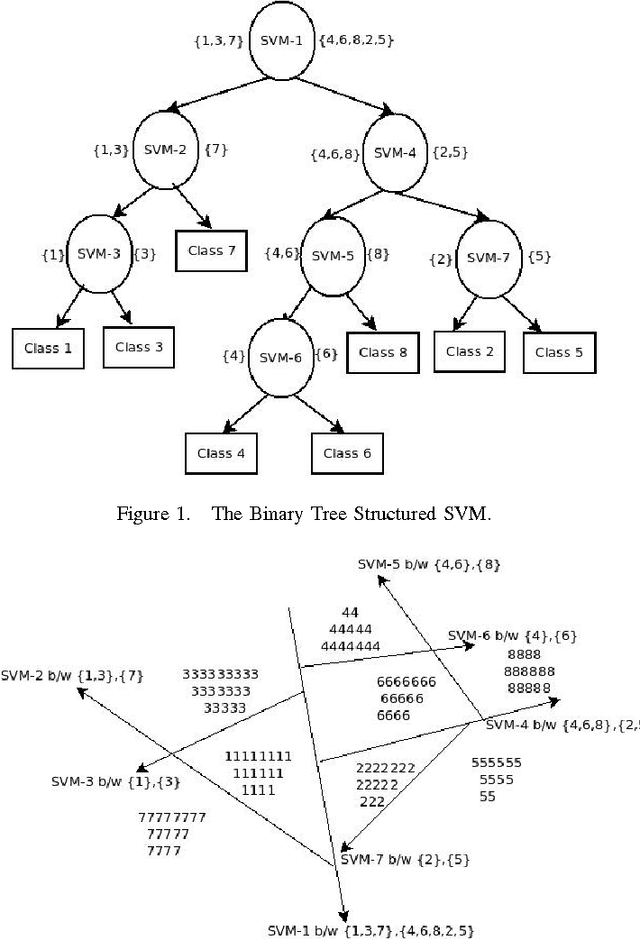



Support Vector Machines (SVMs) were primarily designed for 2-class classification. But they have been extended for N-class classification also based on the requirement of multiclasses in the practical applications. Although N-class classification using SVM has considerable research attention, getting minimum number of classifiers at the time of training and testing is still a continuing research. We propose a new algorithm CBTS-SVM (Centroid based Binary Tree Structured SVM) which addresses this issue. In this we build a binary tree of SVM models based on the similarity of the class labels by finding their distance from the corresponding centroids at the root level. The experimental results demonstrates the comparable accuracy for CBTS with OVO with reasonable gamma and cost values. On the other hand when CBTS is compared with OVA, it gives the better accuracy with reduced training time and testing time. Furthermore CBTS is also scalable as it is able to handle the large data sets.
* Presented in ICACCI, Kochi, India, 2015