 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIVE: Structured Spatiotemporal Exploration for Reinforcement Learning in Video Question Answering
Apr 02, 2026We introduce STRIVE (SpatioTemporal Reinforcement with Importance-aware Variant Exploration), a structured reinforcement learning framework for video question answering. While group-based policy optimization methods have shown promise in large multimodal models, they often suffer from low reward variance when responses exhibit similar correctness, leading to weak or unstable advantage estimates. STRIVE addresses this limitation by constructing multiple spatiotemporal variants of each input video and performing joint normalization across both textual generations and visual variants. By expanding group comparisons beyond linguistic diversity to structured visual perturbations, STRIVE enriches reward signals and promotes more stable and informative policy updates. To ensure exploration remains semantically grounded, we introduce an importance-aware sampling mechanism that prioritizes frames most relevant to the input question while preserving temporal coverage. This design encourages robust reasoning across complementary visual perspectives rather than overfitting to a single spatiotemporal configuration. Experiments on six challenging video reasoning benchmarks including VideoMME, TempCompass, VideoMMMU, MMVU, VSI-Bench, and PerceptionTest demonstrate consistent improvements over strong reinforcement learning baselines across multiple large multimodal models. Our results highlight the role of structured spatiotemporal exploration as a principled mechanism for stabilizing multimodal reinforcement learning and improving video reasoning performance.
AIRA_2: Overcoming Bottlenecks in AI Research Agents
Mar 27, 2026Existing research has identified three structural performance bottlenecks in AI research agents: (1) synchronous single-GPU execution constrains sample throughput, limiting the benefit of search; (2) a generalization gap where validation-based selection causes performance to degrade over extended search horizons; and (3) the limited capability of fixed, single-turn LLM operators imposes a ceiling on search performance. We introduce AIRA$_2$, which addresses these bottlenecks through three architectural choices: an asynchronous multi-GPU worker pool that increases experiment throughput linearly; a Hidden Consistent Evaluation protocol that delivers a reliable evaluation signal; and ReAct agents that dynamically scope their actions and debug interactively. On MLE-bench-30, AIRA$_2$ achieves a mean Percentile Rank of 71.8% at 24 hours - surpassing the previous best of 69.9% - and steadily improves to 76.0% at 72 hours. Ablation studies reveal that each component is necessary and that the "overfitting" reported in prior work was driven by evaluation noise rather than true data memorization.
AIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
DocSLM: A Small Vision-Language Model for Long Multimodal Document Understanding
Nov 17, 2025



Large Vision-Language Models (LVLMs) have demonstrated strong multimodal reasoning capabilities on long and complex documents. However, their high memory footprint makes them impractical for deployment on resource-constrained edge devices. We present DocSLM, an efficient Small Vision-Language Model designed for long-document understanding under constrained memory resources. DocSLM incorporates a Hierarchical Multimodal Compressor that jointly encodes visual, textual, and layout information from each page into a fixed-length sequence, greatly reducing memory consumption while preserving both local and global semantics. To enable scalable processing over arbitrarily long inputs, we introduce a Streaming Abstention mechanism that operates on document segments sequentially and filters low-confidence responses using an entropy-based uncertainty calibrator. Across multiple long multimodal document benchmarks, DocSLM matches or surpasses state-of-the-art methods while using 82\% fewer visual tokens, 75\% fewer parameters, and 71\% lower latency, delivering reliable multimodal document understanding on lightweight edge devices. Code is available in the supplementary material.
DeltaLLM: Compress LLMs with Low-Rank Deltas between Shared Weights
Jan 30, 2025We introduce DeltaLLM, a new post-training compression technique to reduce the memory footprint of LLMs. We propose an alternative way of structuring LLMs with weight sharing between layers in subsequent Transformer blocks, along with additional low-rank difference matrices between them. For training, we adopt the progressing module replacement method and show that the lightweight training of the low-rank modules with approximately 30M-40M tokens is sufficient to achieve performance on par with LLMs of comparable sizes trained from scratch. We release the resultant models, DeltaLLAMA and DeltaPHI, with a 12% parameter reduction, retaining 90% of the performance of the base Llama and Phi models on common knowledge and reasoning benchmarks. Our method also outperforms compression techniques JointDrop, LaCo, ShortGPT and SliceGPT with the same number of parameters removed. For example, DeltaPhi 2.9B with a 24% reduction achieves similar average zero-shot accuracies as recovery fine-tuned SlicedPhi 3.3B with a 12% reduction, despite being approximately 400M parameters smaller with no fine-tuning applied. This work provides new insights into LLM architecture design and compression methods when storage space is critical.
Generative Multi-Stream Architecture For American Sign Language Recognition
Mar 09, 2020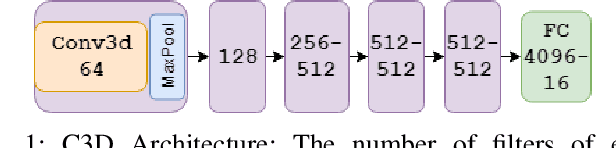
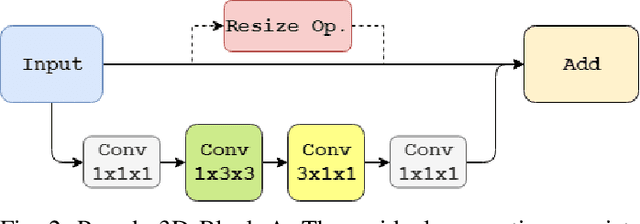

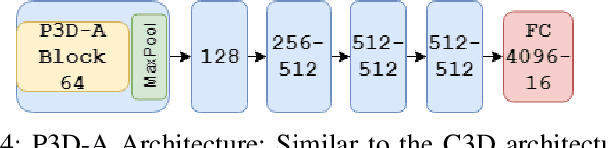
With advancements in deep model architectures, tasks in computer vision can reach optimal convergence provided proper data preprocessing and model parameter initialization. However, training on datasets with low feature-richness for complex applications limit and detriment optimal convergence below human performance. In past works, researchers have provided external sources of complementary data at the cost of supplementary hardware, which are fed in streams to counteract this limitation and boost performance. We propose a generative multi-stream architecture, eliminating the need for additional hardware with the intent to improve feature richness without risking impracticability. We also introduce the compact spatio-temporal residual block to the standard 3-dimensional convolutional model, C3D. Our rC3D model performs comparatively to the top C3D residual variant architecture, the pseudo-3D model, on the FASL-RGB dataset. Our methods have achieved 95.62% validation accuracy with a variance of 1.42% from training, outperforming past models by 0.45% in validation accuracy and 5.53% in variance.
FineHand: Learning Hand Shapes for American Sign Language Recognition
Mar 04, 2020
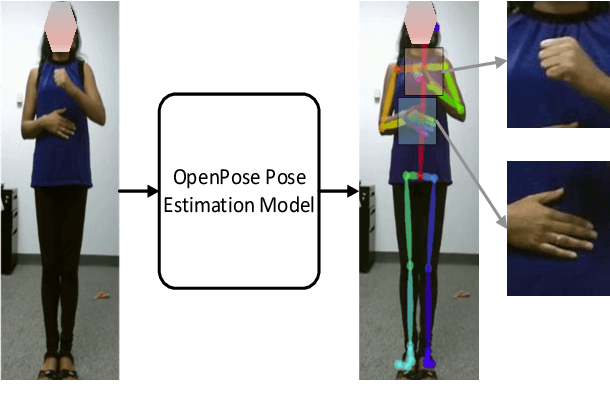

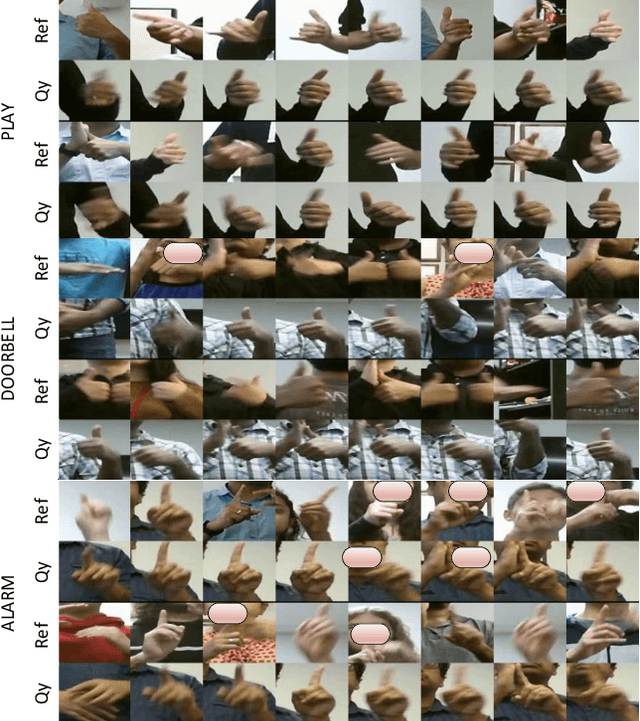
American Sign Language recognition is a difficult gesture recognition problem, characterized by fast, highly articulate gestures. These are comprised of arm movements with different hand shapes, facial expression and head movements. Among these components, hand shape is the vital, often the most discriminative part of a gesture. In this work, we present an approach for effective learning of hand shape embeddings, which are discriminative for ASL gestures. For hand shape recognition our method uses a mix of manually labelled hand shapes and high confidence predictions to train deep convolutional neural network (CNN). The sequential gesture component is captured by recursive neural network (RNN) trained on the embeddings learned in the first stage. We will demonstrate that higher quality hand shape models can significantly improve the accuracy of final video gesture classification in challenging conditions with variety of speakers, different illumination and significant motion blurr. We compare our model to alternative approaches exploiting different modalities and representations of the data and show improved video gesture recognition accuracy on GMU-ASL51 benchmark dataset
Sign Language Recognition Analysis using Multimodal Data
Sep 24, 2019
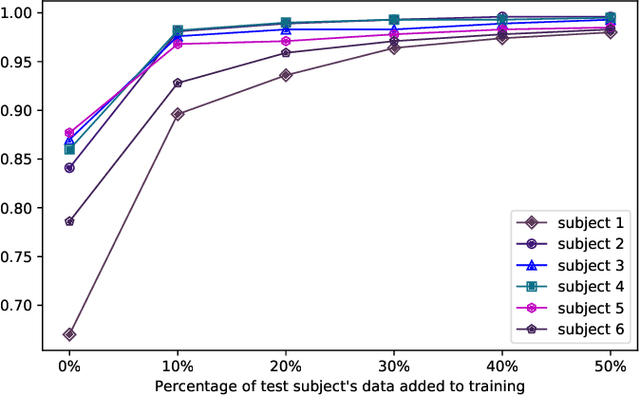
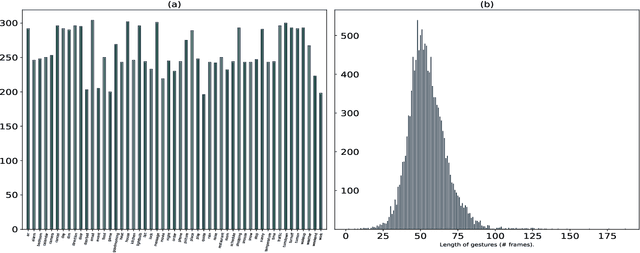

Voice-controlled personal and home assistants (such as the Amazon Echo and Apple Siri) are becoming increasingly popular for a variety of applications. However, the benefits of these technologies are not readily accessible to Deaf or Hard-ofHearing (DHH) users. The objective of this study is to develop and evaluate a sign recognition system using multiple modalities that can be used by DHH signers to interact with voice-controlled devices. With the advancement of depth sensors, skeletal data is used for applications like video analysis and activity recognition. Despite having similarity with the well-studied human activity recognition, the use of 3D skeleton data in sign language recognition is rare. This is because unlike activity recognition, sign language is mostly dependent on hand shape pattern. In this work, we investigate the feasibility of using skeletal and RGB video data for sign language recognition using a combination of different deep learning architectures. We validate our results on a large-scale American Sign Language (ASL) dataset of 12 users and 13107 samples across 51 signs. It is named as GMUASL51. We collected the dataset over 6 months and it will be publicly released in the hope of spurring further machine learning research towards providing improved accessibility for digital assistants.