 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Approach to Distributed Multi-Class SVM
Dec 07, 2015



With data sizes constantly expanding, and with classical machine learning algorithms that analyze such data requiring larger and larger amounts of computation time and storage space, the need to distribute computation and memory requirements among several computers has become apparent. Although substantial work has been done in developing distributed binary SVM algorithms and multi-class SVM algorithms individually, the field of multi-class distributed SVMs remains largely unexplored. This research proposes a novel algorithm that implements the Support Vector Machine over a multi-class dataset and is efficient in a distributed environment (here, Hadoop). The idea is to divide the dataset into half recursively and thus compute the optimal Support Vector Machine for this half during the training phase, much like a divide and conquer approach. While testing, this structure has been effectively exploited to significantly reduce the prediction time. Our algorithm has shown better computation time during the prediction phase than the traditional sequential SVM methods (One vs. One, One vs. Rest) and out-performs them as the size of the dataset grows. This approach also classifies the data with higher accuracy than the traditional multi-class algorithms.
* 8 Pages
Centroid Based Binary Tree Structured SVM for Multi Classification
Dec 02, 2015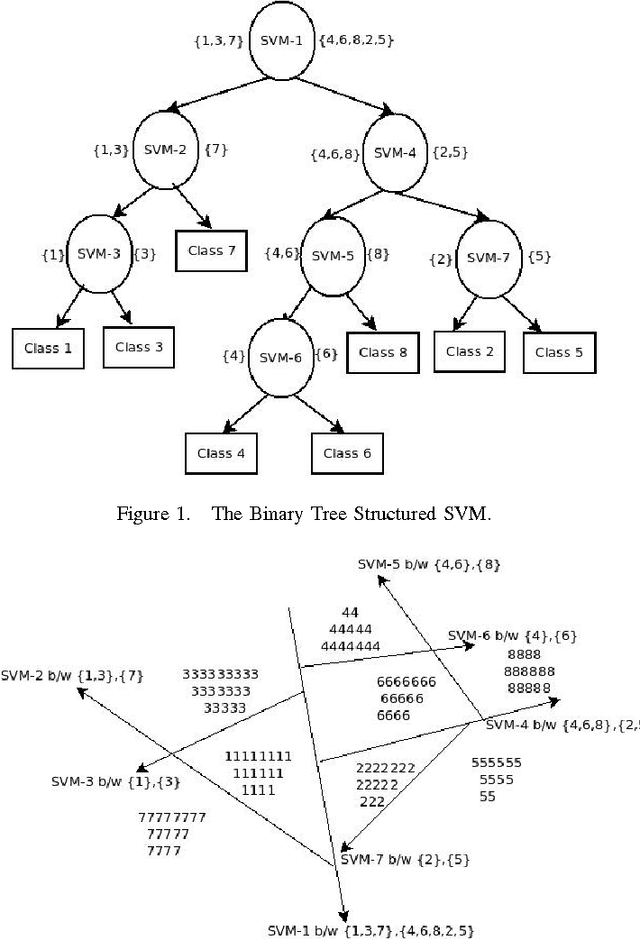



Support Vector Machines (SVMs) were primarily designed for 2-class classification. But they have been extended for N-class classification also based on the requirement of multiclasses in the practical applications. Although N-class classification using SVM has considerable research attention, getting minimum number of classifiers at the time of training and testing is still a continuing research. We propose a new algorithm CBTS-SVM (Centroid based Binary Tree Structured SVM) which addresses this issue. In this we build a binary tree of SVM models based on the similarity of the class labels by finding their distance from the corresponding centroids at the root level. The experimental results demonstrates the comparable accuracy for CBTS with OVO with reasonable gamma and cost values. On the other hand when CBTS is compared with OVA, it gives the better accuracy with reduced training time and testing time. Furthermore CBTS is also scalable as it is able to handle the large data sets.
* Presented in ICACCI, Kochi, India, 2015