 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRA_2: Overcoming Bottlenecks in AI Research Agents
Mar 27, 2026Existing research has identified three structural performance bottlenecks in AI research agents: (1) synchronous single-GPU execution constrains sample throughput, limiting the benefit of search; (2) a generalization gap where validation-based selection causes performance to degrade over extended search horizons; and (3) the limited capability of fixed, single-turn LLM operators imposes a ceiling on search performance. We introduce AIRA$_2$, which addresses these bottlenecks through three architectural choices: an asynchronous multi-GPU worker pool that increases experiment throughput linearly; a Hidden Consistent Evaluation protocol that delivers a reliable evaluation signal; and ReAct agents that dynamically scope their actions and debug interactively. On MLE-bench-30, AIRA$_2$ achieves a mean Percentile Rank of 71.8% at 24 hours - surpassing the previous best of 69.9% - and steadily improves to 76.0% at 72 hours. Ablation studies reveal that each component is necessary and that the "overfitting" reported in prior work was driven by evaluation noise rather than true data memorization.
APRES: An Agentic Paper Revision and Evaluation System
Mar 03, 2026Scientific discoveries must be communicated clearly to realize their full potential. Without effective communication, even the most groundbreaking findings risk being overlooked or misunderstood. The primary way scientists communicate their work and receive feedback from the community is through peer review. However, the current system often provides inconsistent feedback between reviewers, ultimately hindering the improvement of a manuscript and limiting its potential impact. In this paper, we introduce a novel method APRES powered by Large Language Models (LLMs) to update a scientific papers text based on an evaluation rubric. Our automated method discovers a rubric that is highly predictive of future citation counts, and integrate it with APRES in an automated system that revises papers to enhance their quality and impact. Crucially, this objective should be met without altering the core scientific content. We demonstrate the success of APRES, which improves future citation prediction by 19.6% in mean averaged error over the next best baseline, and show that our paper revision process yields papers that are preferred over the originals by human expert evaluators 79% of the time. Our findings provide strong empirical support for using LLMs as a tool to help authors stress-test their manuscripts before submission. Ultimately, our work seeks to augment, not replace, the essential role of human expert reviewers, for it should be humans who discern which discoveries truly matter, guiding science toward advancing knowledge and enriching lives.
AIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
Souper-Model: How Simple Arithmetic Unlocks State-of-the-Art LLM Performance
Nov 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse domains, but their training remains resource- and time-intensive, requiring massive compute power and careful orchestration of training procedures. Model souping-the practice of averaging weights from multiple models of the same architecture-has emerged as a promising pre- and post-training technique that can enhance performance without expensive retraining. In this paper, we introduce Soup Of Category Experts (SoCE), a principled approach for model souping that utilizes benchmark composition to identify optimal model candidates and applies non-uniform weighted averaging to maximize performance. Contrary to previous uniform-averaging approaches, our method leverages the observation that benchmark categories often exhibit low inter-correlations in model performance. SoCE identifies "expert" models for each weakly-correlated category cluster and combines them using optimized weighted averaging rather than uniform weights. We demonstrate that the proposed method improves performance and robustness across multiple domains, including multilingual capabilities, tool calling, and math and achieves state-of-the-art results on the Berkeley Function Calling Leaderboard.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
MLGym: A New Framework and Benchmark for Advancing AI Research Agents
Feb 20, 2025



We introduce Meta MLGym and MLGym-Bench, a new framework and benchmark for evaluating and developing LLM agents on AI research tasks. This is the first Gym environment for machine learning (ML) tasks, enabling research on reinforcement learning (RL) algorithms for training such agents. MLGym-bench consists of 13 diverse and open-ended AI research tasks from diverse domains such as computer vision, natural language processing, reinforcement learning, and game theory. Solving these tasks requires real-world AI research skills such as generating new ideas and hypotheses, creating and processing data, implementing ML methods, training models, running experiments, analyzing the results, and iterating through this process to improve on a given task. We evaluate a number of frontier large language models (LLMs) on our benchmarks such as Claude-3.5-Sonnet, Llama-3.1 405B, GPT-4o, o1-preview, and Gemini-1.5 Pro. Our MLGym framework makes it easy to add new tasks, integrate and evaluate models or agents, generate synthetic data at scale, as well as develop new learning algorithms for training agents on AI research tasks. We find that current frontier models can improve on the given baselines, usually by finding better hyperparameters, but do not generate novel hypotheses, algorithms, architectures, or substantial improvements. We open-source our framework and benchmark to facilitate future research in advancing the AI research capabilities of LLM agents.
Acyclicity Notions for Existential Rules and Their Application to Query Answering in Ontologies
Feb 04, 2014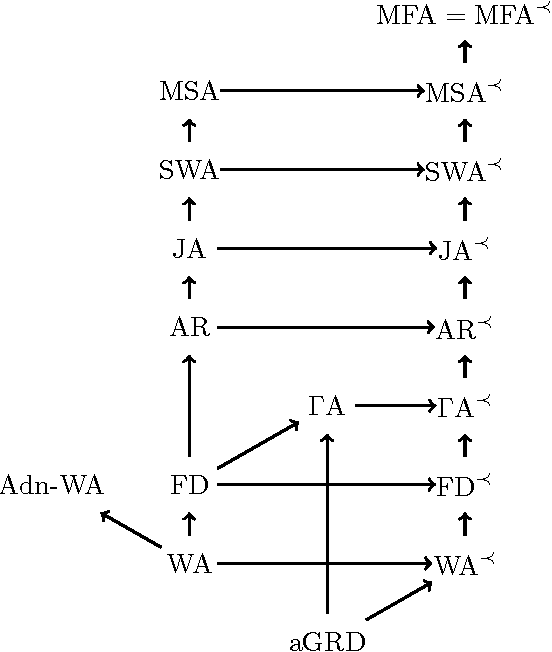
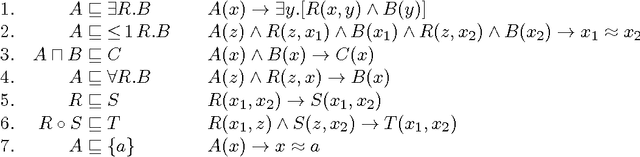
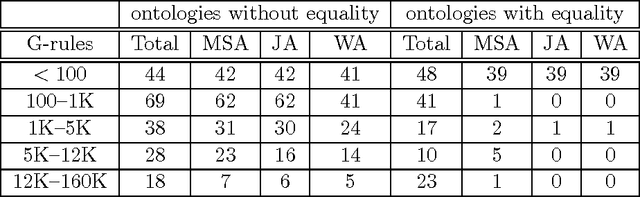
Answering conjunctive queries (CQs) over a set of facts extended with existential rules is a prominent problem in knowledge representation and databases. This problem can be solved using the chase algorithm, which extends the given set of facts with fresh facts in order to satisfy the rules. If the chase terminates, then CQs can be evaluated directly in the resulting set of facts. The chase, however, does not terminate necessarily, and checking whether the chase terminates on a given set of rules and facts is undecidable. Numerous acyclicity notions were proposed as sufficient conditions for chase termination. In this paper, we present two new acyclicity notions called model-faithful acyclicity (MFA) and model-summarising acyclicity (MSA). Furthermore, we investigate the landscape of the known acyclicity notions and establish a complete taxonomy of all notions known to us. Finally, we show that MFA and MSA generalise most of these notions. Existential rules are closely related to the Horn fragments of the OWL 2 ontology language; furthermore, several prominent OWL 2 reasoners implement CQ answering by using the chase to materialise all relevant facts. In order to avoid termination problems, many of these systems handle only the OWL 2 RL profile of OWL 2; furthermore, some systems go beyond OWL 2 RL, but without any termination guarantees. In this paper we also investigate whether various acyclicity notions can provide a principled and practical solution to these problems. On the theoretical side, we show that query answering for acyclic ontologies is of lower complexity than for general ontologies. On the practical side, we show that many of the commonly used OWL 2 ontologies are MSA, and that the number of facts obtained by materialisation is not too large. Our results thus suggest that principled development of materialisation-based OWL 2 reasoners is practically feasible.