 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty quantification in non-rigid image registration via stochastic gradient Markov chain Monte Carlo
Oct 25, 2021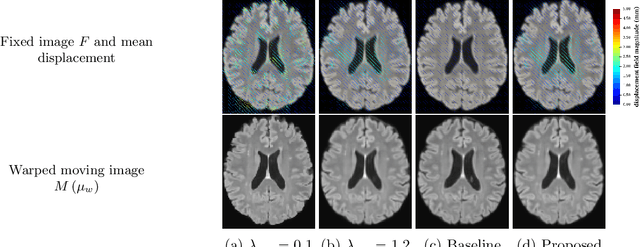
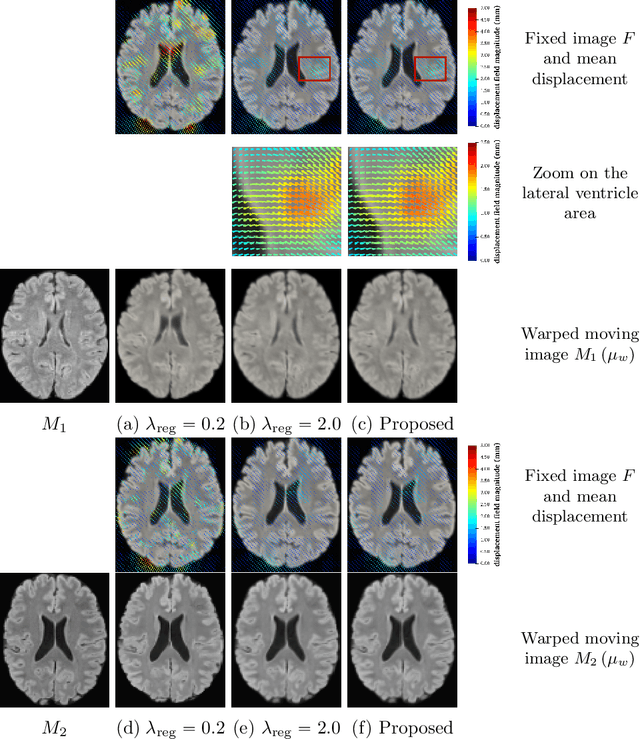

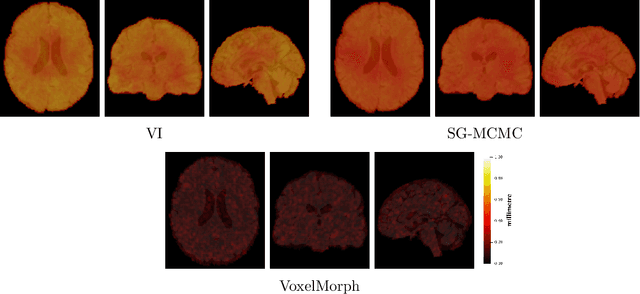
We develop a new Bayesian model for non-rigid registration of three-dimensional medical images, with a focus on uncertainty quantification. Probabilistic registration of large images with calibrated uncertainty estimates is difficult for both computational and modelling reasons. To address the computational issues, we explore connections between the Markov chain Monte Carlo by backpropagation and the variational inference by backpropagation frameworks, in order to efficiently draw samples from the posterior distribution of transformation parameters. To address the modelling issues, we formulate a Bayesian model for image registration that overcomes the existing barriers when using a dense, high-dimensional, and diffeomorphic transformation parametrisation. This results in improved calibration of uncertainty estimates. We compare the model in terms of both image registration accuracy and uncertainty quantification to VoxelMorph, a state-of-the-art image registration model based on deep learning.
Self-Supervised Out-of-Distribution Detection and Localization with Natural Synthetic Anomalies (NSA)
Sep 30, 2021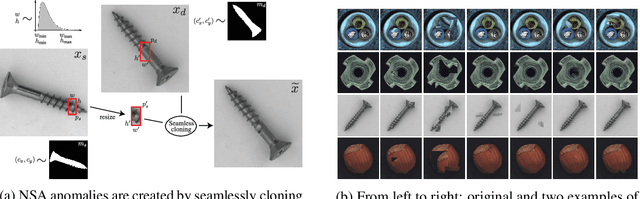
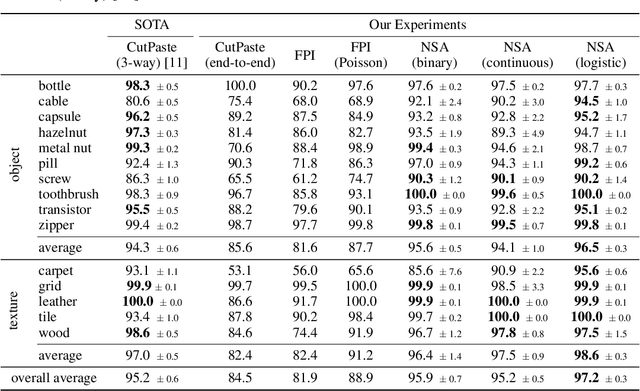
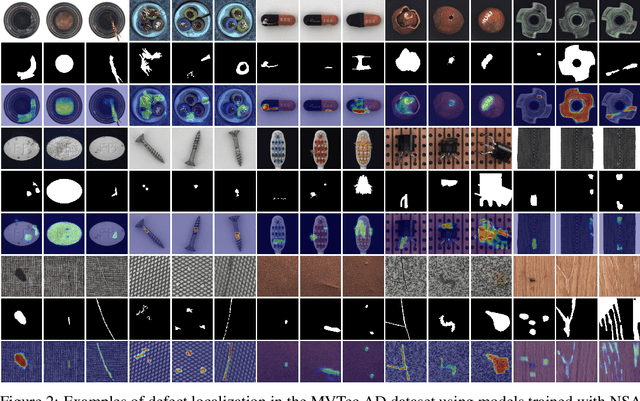
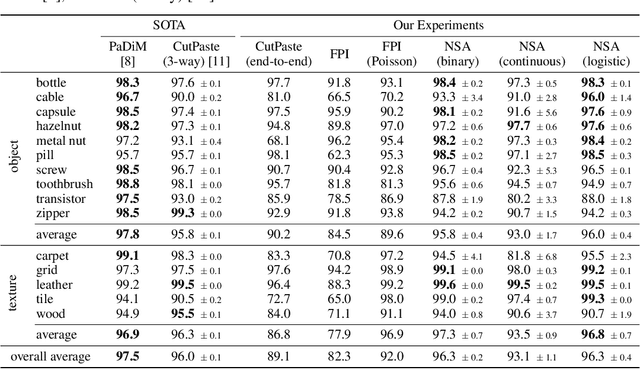
We introduce a new self-supervised task, NSA, for training an end-to-end model for anomaly detection and localization using only normal data. NSA uses Poisson image editing to seamlessly blend scaled patches of various sizes from separate images. This creates a wide range of synthetic anomalies which are more similar to natural sub-image irregularities than previous data-augmentation strategies for self-supervised anomaly detection. We evaluate the proposed method using natural and medical images. Our experiments with the MVTec AD dataset show that a model trained to localize NSA anomalies generalizes well to detecting real-world a priori unknown types of manufacturing defects. Our method achieves an overall detection AUROC of 97.2 outperforming all previous methods that learn from scratch without pre-training datasets.
Estimating the probabilities of causation via deep monotonic twin networks
Sep 07, 2021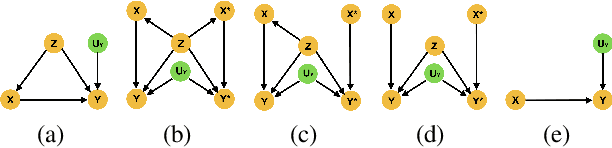

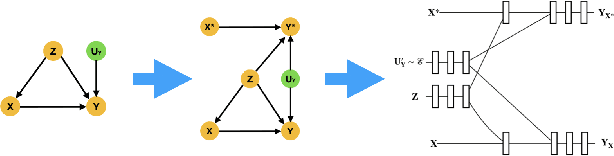

There has been much recent work using machine learning to answer causal queries. Most focus on interventional queries, such as the conditional average treatment effect. However, as noted by Pearl, interventional queries only form part of a larger hierarchy of causal queries, with counterfactuals sitting at the top. Despite this, our community has not fully succeeded in adapting machine learning tools to answer counterfactual queries. This work addresses this challenge by showing how to implement twin network counterfactual inference -- an alternative to abduction, action, & prediction counterfactual inference -- with deep learning to estimate counterfactual queries. We show how the graphical nature of twin networks makes them particularly amenable to deep learning, yielding simple neural network architectures that, when trained, are capable of counterfactual inference. Importantly, we show how to enforce known identifiability constraints during training, ensuring the answer to each counterfactual query is uniquely determined. We demonstrate our approach by using it to accurately estimate the probabilities of causation -- important counterfactual queries that quantify the degree to which one event was a necessary or sufficient cause of another -- on both synthetic and real data.
PialNN: A Fast Deep Learning Framework for Cortical Pial Surface Reconstruction
Sep 06, 2021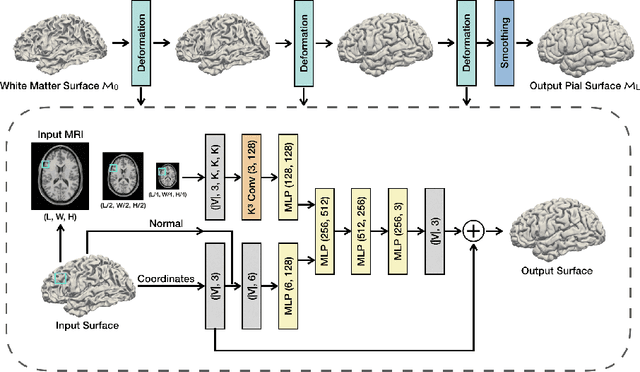
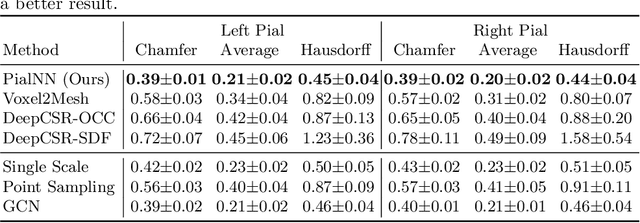
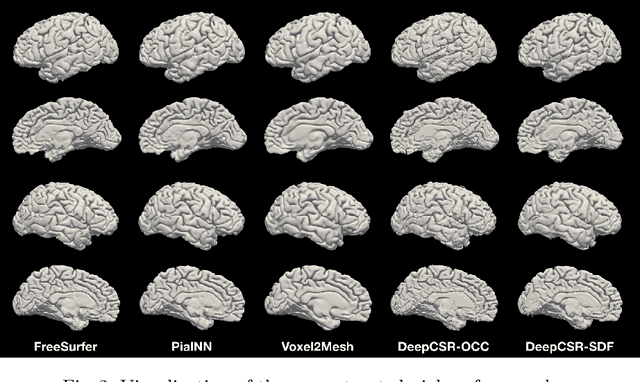
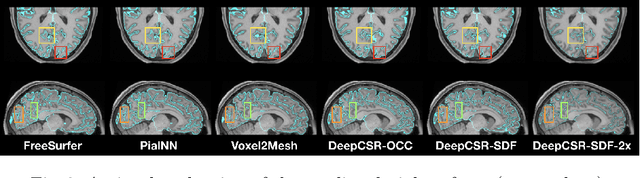
Traditional cortical surface reconstruction is time consuming and limited by the resolution of brain Magnetic Resonance Imaging (MRI). In this work, we introduce Pial Neural Network (PialNN), a 3D deep learning framework for pial surface reconstruction. PialNN is trained end-to-end to deform an initial white matter surface to a target pial surface by a sequence of learned deformation blocks. A local convolutional operation is incorporated in each block to capture the multi-scale MRI information of each vertex and its neighborhood. This is fast and memory-efficient, which allows reconstructing a pial surface mesh with 150k vertices in one second. The performance is evaluated on the Human Connectome Project (HCP) dataset including T1-weighted MRI scans of 300 subjects. The experimental results demonstrate that PialNN reduces the geometric error of the predicted pial surface by 30% compared to state-of-the-art deep learning approaches.
Contrastive Learning for View Classification of Echocardiograms
Aug 06, 2021



Analysis of cardiac ultrasound images is commonly performed in routine clinical practice for quantification of cardiac function. Its increasing automation frequently employs deep learning networks that are trained to predict disease or detect image features. However, such models are extremely data-hungry and training requires labelling of many thousands of images by experienced clinicians. Here we propose the use of contrastive learning to mitigate the labelling bottleneck. We train view classification models for imbalanced cardiac ultrasound datasets and show improved performance for views/classes for which minimal labelled data is available. Compared to a naive baseline model, we achieve an improvement in F1 score of up to 26% in those views while maintaining state-of-the-art performance for the views with sufficiently many labelled training observations.
Can non-specialists provide high quality gold standard labels in challenging modalities?
Jul 30, 2021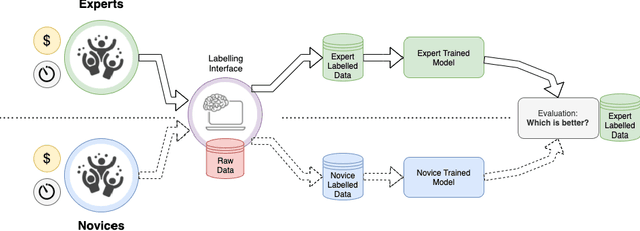
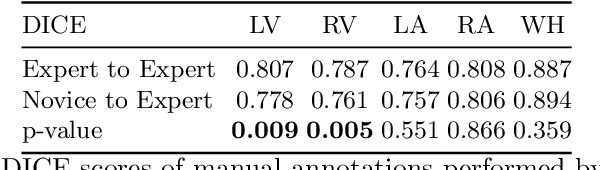
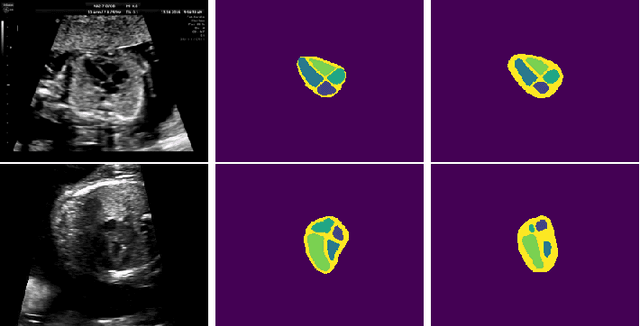
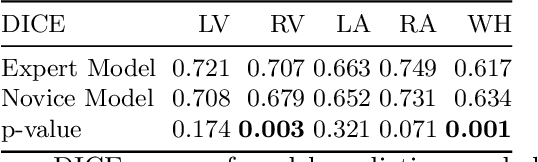
Probably yes. -- Supervised Deep Learning dominates performance scores for many computer vision tasks and defines the state-of-the-art. However, medical image analysis lags behind natural image applications. One of the many reasons is the lack of well annotated medical image data available to researchers. One of the first things researchers are told is that we require significant expertise to reliably and accurately interpret and label such data. We see significant inter- and intra-observer variability between expert annotations of medical images. Still, it is a widely held assumption that novice annotators are unable to provide useful annotations for use by clinical Deep Learning models. In this work we challenge this assumption and examine the implications of using a minimally trained novice labelling workforce to acquire annotations for a complex medical image dataset. We study the time and cost implications of using novice annotators, the raw performance of novice annotators compared to gold-standard expert annotators, and the downstream effects on a trained Deep Learning segmentation model's performance for detecting a specific congenital heart disease (hypoplastic left heart syndrome) in fetal ultrasound imaging.
Detecting Hypo-plastic Left Heart Syndrome in Fetal Ultrasound via Disease-specific Atlas Maps
Jul 06, 2021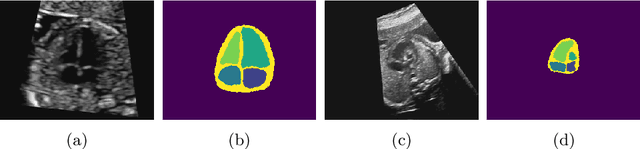
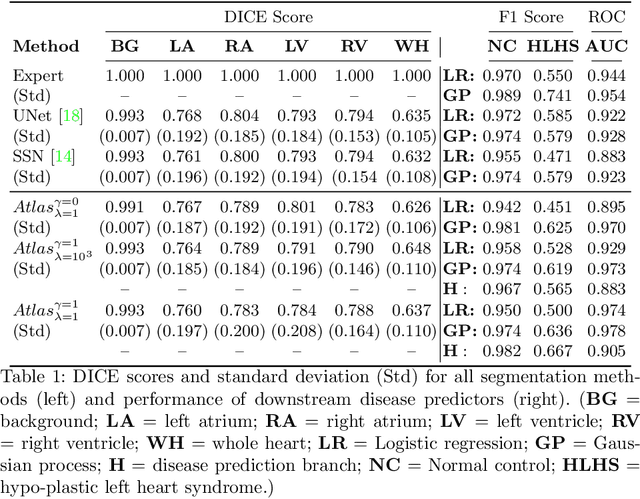

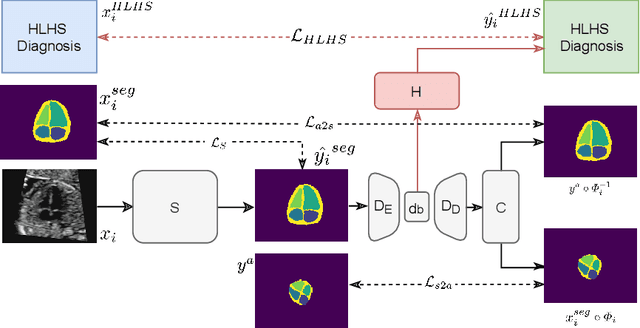
Fetal ultrasound screening during pregnancy plays a vital role in the early detection of fetal malformations which have potential long-term health impacts. The level of skill required to diagnose such malformations from live ultrasound during examination is high and resources for screening are often limited. We present an interpretable, atlas-learning segmentation method for automatic diagnosis of Hypo-plastic Left Heart Syndrome (HLHS) from a single `4 Chamber Heart' view image. We propose to extend the recently introduced Image-and-Spatial Transformer Networks (Atlas-ISTN) into a framework that enables sensitising atlas generation to disease. In this framework we can jointly learn image segmentation, registration, atlas construction and disease prediction while providing a maximum level of clinical interpretability compared to direct image classification methods. As a result our segmentation allows diagnoses competitive with expert-derived manual diagnosis and yields an AUC-ROC of 0.978 (1043 cases for training, 260 for validation and 325 for testing).
Detecting Outliers with Poisson Image Interpolation
Jul 06, 2021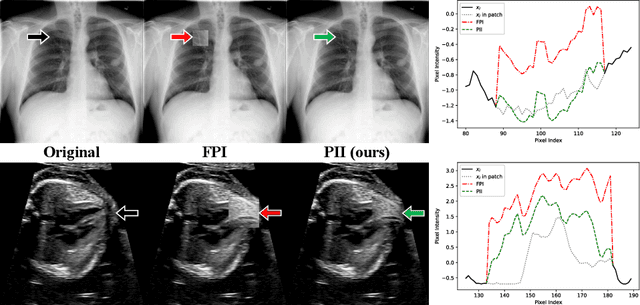
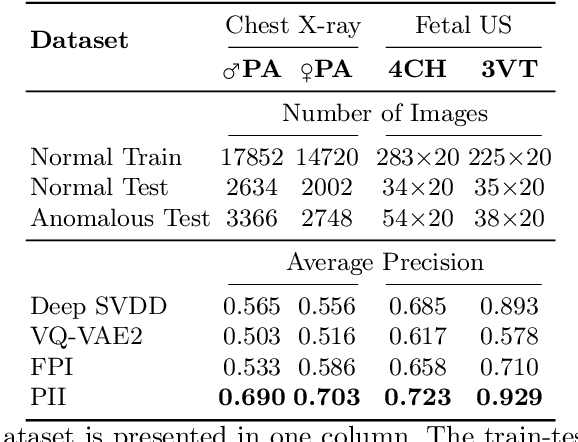
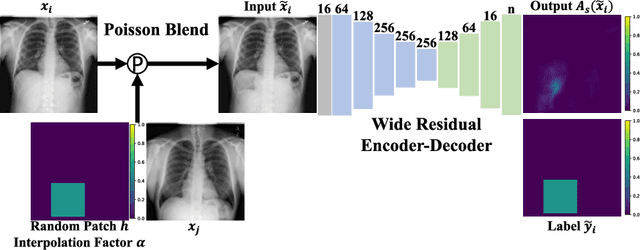
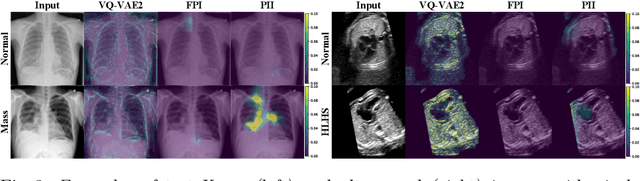
Supervised learning of every possible pathology is unrealistic for many primary care applications like health screening. Image anomaly detection methods that learn normal appearance from only healthy data have shown promising results recently. We propose an alternative to image reconstruction-based and image embedding-based methods and propose a new self-supervised method to tackle pathological anomaly detection. Our approach originates in the foreign patch interpolation (FPI) strategy that has shown superior performance on brain MRI and abdominal CT data. We propose to use a better patch interpolation strategy, Poisson image interpolation (PII), which makes our method suitable for applications in challenging data regimes. PII outperforms state-of-the-art methods by a good margin when tested on surrogate tasks like identifying common lung anomalies in chest X-rays or hypo-plastic left heart syndrome in prenatal, fetal cardiac ultrasound images. Code available at https://github.com/jemtan/PII.
RATCHET: Medical Transformer for Chest X-ray Diagnosis and Reporting
Jul 05, 2021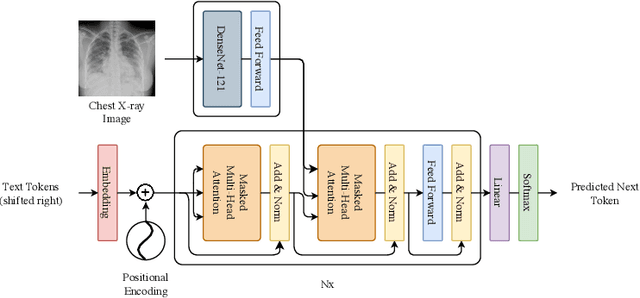
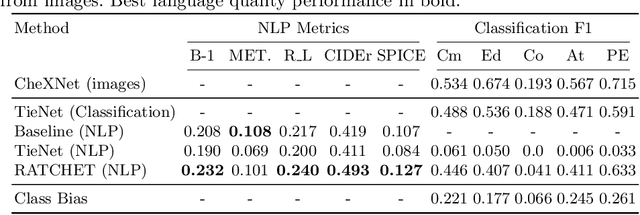
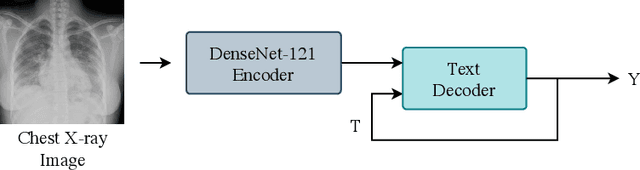
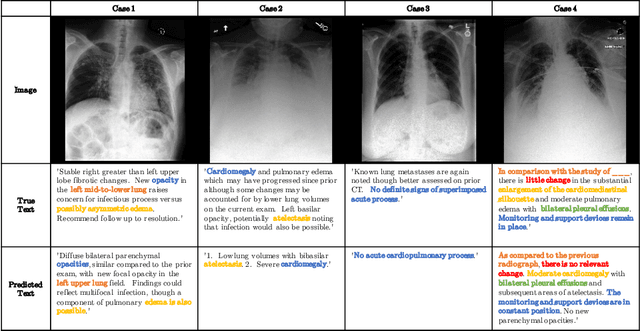
Chest radiographs are one of the most common diagnostic modalities in clinical routine. It can be done cheaply, requires minimal equipment, and the image can be diagnosed by every radiologists. However, the number of chest radiographs obtained on a daily basis can easily overwhelm the available clinical capacities. We propose RATCHET: RAdiological Text Captioning for Human Examined Thoraces. RATCHET is a CNN-RNN-based medical transformer that is trained end-to-end. It is capable of extracting image features from chest radiographs, and generates medically accurate text reports that fit seamlessly into clinical work flows. The model is evaluated for its natural language generation ability using common metrics from NLP literature, as well as its medically accuracy through a surrogate report classification task. The model is available for download at: http://www.github.com/farrell236/RATCHET.
Ultrasound Video Transformers for Cardiac Ejection Fraction Estimation
Jul 02, 2021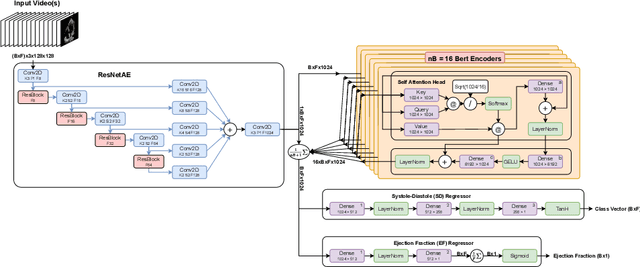
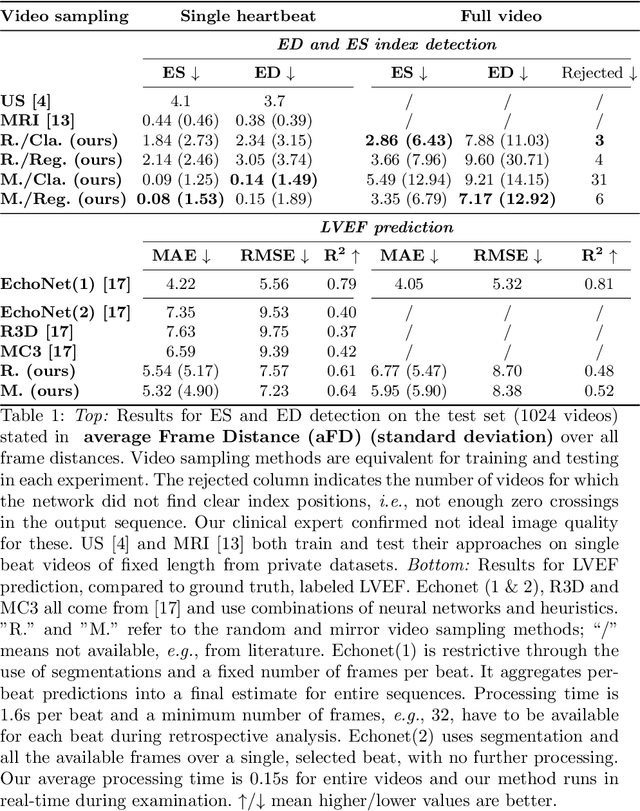
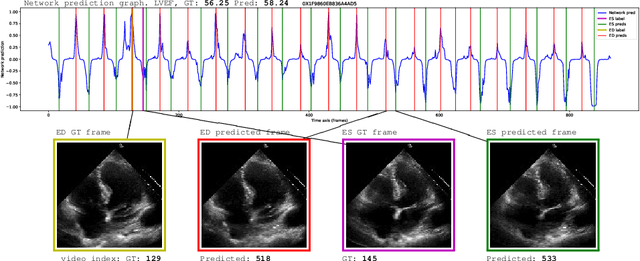
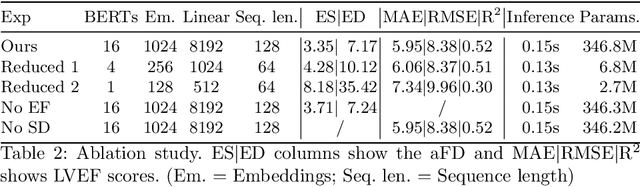
Cardiac ultrasound imaging is used to diagnose various heart diseases. Common analysis pipelines involve manual processing of the video frames by expert clinicians. This suffers from intra- and inter-observer variability. We propose a novel approach to ultrasound video analysis using a transformer architecture based on a Residual Auto-Encoder Network and a BERT model adapted for token classification. This enables videos of any length to be processed. We apply our model to the task of End-Systolic (ES) and End-Diastolic (ED) frame detection and the automated computation of the left ventricular ejection fraction. We achieve an average frame distance of 3.36 frames for the ES and 7.17 frames for the ED on videos of arbitrary length. Our end-to-end learnable approach can estimate the ejection fraction with a MAE of 5.95 and $R^2$ of 0.52 in 0.15s per video, showing that segmentation is not the only way to predict ejection fraction. Code and models are available at https://github.com/HReynaud/UVT.