 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorpho-MNIST: Quantitative Assessment and Diagnostics for Representation Learning
Paper and Code
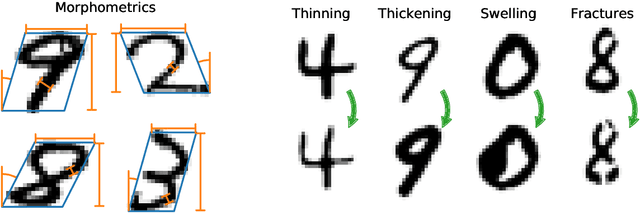


Revealing latent structure in data is an active field of research, having brought exciting new models such as variational autoencoders and generative adversarial networks, and is essential to push machine learning towards unsupervised knowledge discovery. However, a major challenge is the lack of suitable benchmarks for an objective and quantitative evaluation of learned representations. To address this issue we introduce Morpho-MNIST. We extend the popular MNIST dataset by adding a morphometric analysis enabling quantitative comparison of different models, identification of the roles of latent variables, and characterisation of sample diversity. We further propose a set of quantifiable perturbations to assess the performance of unsupervised and supervised methods on challenging tasks such as outlier detection and domain adaptation.