 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing CNN Loss and Gradients for Pose Estimation with Riemannian Geometry
Paper and Code
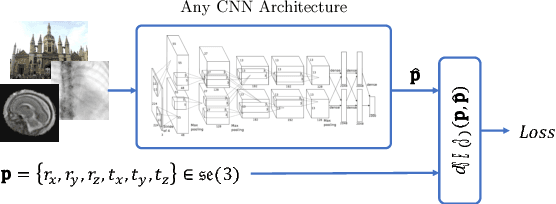
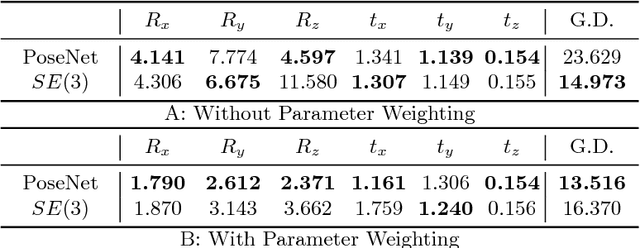
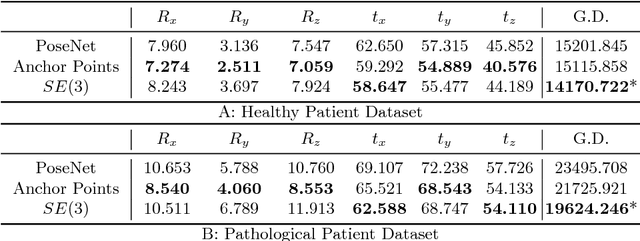

Pose estimation, i.e. predicting a 3D rigid transformation with respect to a fixed co-ordinate frame in, SE(3), is an omnipresent problem in medical image analysis with applications such as: image rigid registration, anatomical standard plane detection, tracking and device/camera pose estimation. Deep learning methods often parameterise a pose with a representation that separates rotation and translation. As commonly available frameworks do not provide means to calculate loss on a manifold, regression is usually performed using the L2-norm independently on the rotation's and the translation's parameterisations, which is a metric for linear spaces that does not take into account the Lie group structure of SE(3). In this paper, we propose a general Riemannian formulation of the pose estimation problem. We propose to train the CNN directly on SE(3) equipped with a left-invariant Riemannian metric, coupling the prediction of the translation and rotation defining the pose. At each training step, the ground truth and predicted pose are elements of the manifold, where the loss is calculated as the Riemannian geodesic distance. We then compute the optimisation direction by back-propagating the gradient with respect to the predicted pose on the tangent space of the manifold SE(3) and update the network weights. We thoroughly evaluate the effectiveness of our loss function by comparing its performance with popular and most commonly used existing methods, on tasks such as image-based localisation and intensity-based 2D/3D registration. We also show that hyper-parameters, used in our loss function to weight the contribution between rotations and translations, can be intrinsically calculated from the dataset to achieve greater performance margins.