 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassive Inference Attacks on Split Learning via Adversarial Regularization
Oct 16, 2023



Split Learning (SL) has emerged as a practical and efficient alternative to traditional federated learning. While previous attempts to attack SL have often relied on overly strong assumptions or targeted easily exploitable models, we seek to develop more practical attacks. We introduce SDAR, a novel attack framework against SL with an honest-but-curious server. SDAR leverages auxiliary data and adversarial regularization to learn a decodable simulator of the client's private model, which can effectively infer the client's private features under the vanilla SL, and both features and labels under the U-shaped SL. We perform extensive experiments in both configurations to validate the effectiveness of our proposed attacks. Notably, in challenging but practical scenarios where existing passive attacks struggle to reconstruct the client's private data effectively, SDAR consistently achieves attack performance comparable to active attacks. On CIFAR-10, at the deep split level of 7, SDAR achieves private feature reconstruction with less than 0.025 mean squared error in both the vanilla and the U-shaped SL, and attains a label inference accuracy of over 98% in the U-shaped setting, while existing attacks fail to produce non-trivial results.
Learning in Imperfect Environment: Multi-Label Classification with Long-Tailed Distribution and Partial Labels
Apr 20, 2023Conventional multi-label classification (MLC) methods assume that all samples are fully labeled and identically distributed. Unfortunately, this assumption is unrealistic in large-scale MLC data that has long-tailed (LT) distribution and partial labels (PL). To address the problem, we introduce a novel task, Partial labeling and Long-Tailed Multi-Label Classification (PLT-MLC), to jointly consider the above two imperfect learning environments. Not surprisingly, we find that most LT-MLC and PL-MLC approaches fail to solve the PLT-MLC, resulting in significant performance degradation on the two proposed PLT-MLC benchmarks. Therefore, we propose an end-to-end learning framework: \textbf{CO}rrection $\rightarrow$ \textbf{M}odificat\textbf{I}on $\rightarrow$ balan\textbf{C}e, abbreviated as \textbf{\method{}}. Our bootstrapping philosophy is to simultaneously correct the missing labels (Correction) with convinced prediction confidence over a class-aware threshold and to learn from these recall labels during training. We next propose a novel multi-focal modifier loss that simultaneously addresses head-tail imbalance and positive-negative imbalance to adaptively modify the attention to different samples (Modification) under the LT class distribution. In addition, we develop a balanced training strategy by distilling the model's learning effect from head and tail samples, and thus design a balanced classifier (Balance) conditioned on the head and tail learning effect to maintain stable performance for all samples. Our experimental study shows that the proposed \method{} significantly outperforms general MLC, LT-MLC and PL-MLC methods in terms of effectiveness and robustness on our newly created PLT-MLC datasets.
Toward Cohort Intelligence: A Universal Cohort Representation Learning Framework for Electronic Health Record Analysis
Apr 12, 2023



Electronic Health Records (EHR) are generated from clinical routine care recording valuable information of broad patient populations, which provide plentiful opportunities for improving patient management and intervention strategies in clinical practice. To exploit the enormous potential of EHR data, a popular EHR data analysis paradigm in machine learning is EHR representation learning, which first leverages the individual patient's EHR data to learn informative representations by a backbone, and supports diverse health-care downstream tasks grounded on the representations. Unfortunately, such a paradigm fails to access the in-depth analysis of patients' relevance, which is generally known as cohort studies in clinical practice. Specifically, patients in the same cohort tend to share similar characteristics, implying their resemblance in medical conditions such as symptoms or diseases. In this paper, we propose a universal COhort Representation lEarning (CORE) framework to augment EHR utilization by leveraging the fine-grained cohort information among patients. In particular, CORE first develops an explicit patient modeling task based on the prior knowledge of patients' diagnosis codes, which measures the latent relevance among patients to adaptively divide the cohorts for each patient. Based on the constructed cohorts, CORE recodes the pre-extracted EHR data representation from intra- and inter-cohort perspectives, yielding augmented EHR data representation learning. CORE is readily applicable to diverse backbone models, serving as a universal plug-in framework to infuse cohort information into healthcare methods for boosted performance. We conduct an extensive experimental evaluation on two real-world datasets, and the experimental results demonstrate the effectiveness and generalizability of CORE.
CAusal and collaborative proxy-tasKs lEarning for Semi-Supervised Domain Adaptation
Mar 30, 2023Semi-supervised domain adaptation (SSDA) adapts a learner to a new domain by effectively utilizing source domain data and a few labeled target samples. It is a practical yet under-investigated research topic. In this paper, we analyze the SSDA problem from two perspectives that have previously been overlooked, and correspondingly decompose it into two \emph{key subproblems}: \emph{robust domain adaptation (DA) learning} and \emph{maximal cross-domain data utilization}. \textbf{(i)} From a causal theoretical view, a robust DA model should distinguish the invariant ``concept'' (key clue to image label) from the nuisance of confounding factors across domains. To achieve this goal, we propose to generate \emph{concept-invariant samples} to enable the model to classify the samples through causal intervention, yielding improved generalization guarantees; \textbf{(ii)} Based on the robust DA theory, we aim to exploit the maximal utilization of rich source domain data and a few labeled target samples to boost SSDA further. Consequently, we propose a collaboratively debiasing learning framework that utilizes two complementary semi-supervised learning (SSL) classifiers to mutually exchange their unbiased knowledge, which helps unleash the potential of source and target domain training data, thereby producing more convincing pseudo-labels. Such obtained labels facilitate cross-domain feature alignment and duly improve the invariant concept learning. In our experimental study, we show that the proposed model significantly outperforms SOTA methods in terms of effectiveness and generalisability on SSDA datasets.
FLAC: A Robust Failure-Aware Atomic Commit Protocol for Distributed Transactions
Mar 02, 2023



In distributed transaction processing, atomic commit protocol (ACP) is used to ensure database consistency. With the use of commodity compute nodes and networks, failures such as system crashes and network partitioning are common. It is therefore important for ACP to dynamically adapt to the operating condition for efficiency while ensuring the consistency of the database. Existing ACPs often assume stable operating conditions, hence, they are either non-generalizable to different environments or slow in practice. In this paper, we propose a novel and practical ACP, called Failure-Aware Atomic Commit (FLAC). In essence, FLAC includes three protocols, which are specifically designed for three different environments: (i) no failure occurs, (ii) participant nodes might crash but there is no delayed connection, or (iii) both crashed nodes and delayed connection can occur. It models these environments as the failure-free, crash-failure, and network-failure robustness levels. During its operation, FLAC can monitor if any failure occurs and dynamically switch to operate the most suitable protocol, using a robustness level state machine, whose parameters are fine-tuned by reinforcement learning. Consequently, it improves both the response time and throughput, and effectively handles nodes distributed across the Internet where crash and network failures might occur. We implement FLAC in a distributed transactional key-value storage system based on Google Percolator and evaluate its performance with both a micro benchmark and a macro benchmark of real workload. The results show that FLAC achieves up to 2.22x throughput improvement and 2.82x latency speedup, compared to existing ACPs for high-contention workloads.
IDEAL: Toward High-efficiency Device-Cloud Collaborative and Dynamic Recommendation System
Feb 14, 2023Recommendation systems have shown great potential to solve the information explosion problem and enhance user experience in various online applications, which recently present two emerging trends: (i) Collaboration: single-sided model trained on-cloud (separate learning) to the device-cloud collaborative recommendation (collaborative learning). (ii) Real-time Dynamic: the network parameters are the same across all the instances (static model) to adaptive network parameters generation conditioned on the real-time instances (dynamic model). The aforementioned two trends enable the device-cloud collaborative and dynamic recommendation, which deeply exploits the recommendation pattern among cloud-device data and efficiently characterizes different instances with different underlying distributions based on the cost of frequent device-cloud communication. Despite promising, we argue that most of the communications are unnecessary to request the new parameters of the recommendation system on the cloud since the on-device data distribution are not always changing. To alleviate this issue, we designed a Intelligent DEvice-Cloud PArameter Request ModeL (IDEAL) that can be deployed on the device to calculate the request revenue with low resource consumption, so as to ensure the adaptive device-cloud communication with high revenue. We envision a new device intelligence learning task to implement IDEAL by detecting the data out-of-domain. Moreover, we map the user's real-time behavior to a normal distribution, the uncertainty is calculated by the multi-sampling outputs to measure the generalization ability of the device model to the current user behavior. Our experimental study demonstrates IDEAL's effectiveness and generalizability on four public benchmarks, which yield a higher efficient device-cloud collaborative and dynamic recommendation paradigm.
A Dietary Nutrition-aided Healthcare Platform via Effective Food Recognition on a Localized Singaporean Food Dataset
Jan 10, 2023



Localized food datasets have profound meaning in revealing a country's special cuisines to explore people's dietary behaviors, which will shed light on their health conditions and disease development. In this paper, revolving around the demand for accurate food recognition in Singapore, we develop the FoodSG platform to incubate diverse healthcare-oriented applications as a service in Singapore, taking into account their shared requirements. We release a localized Singaporean food dataset FoodSG-233 with a systematic cleaning and curation pipeline for promoting future data management research in food computing. To overcome the hurdle in recognition performance brought by Singaporean multifarious food dishes, we propose to integrate supervised contrastive learning into our food recognition model FoodSG-SCL for the intrinsic capability to mine hard positive/negative samples and therefore boost the accuracy. Through a comprehensive evaluation, we share the insightful experience with practitioners in the data management community regarding food-related data-intensive healthcare applications. The FoodSG-233 dataset can be accessed via: https://foodlg.comp.nus.edu.sg/.
Skellam Mixture Mechanism: a Novel Approach to Federated Learning with Differential Privacy
Dec 08, 2022


Deep neural networks have strong capabilities of memorizing the underlying training data, which can be a serious privacy concern. An effective solution to this problem is to train models with differential privacy, which provides rigorous privacy guarantees by injecting random noise to the gradients. This paper focuses on the scenario where sensitive data are distributed among multiple participants, who jointly train a model through federated learning (FL), using both secure multiparty computation (MPC) to ensure the confidentiality of each gradient update, and differential privacy to avoid data leakage in the resulting model. A major challenge in this setting is that common mechanisms for enforcing DP in deep learning, which inject real-valued noise, are fundamentally incompatible with MPC, which exchanges finite-field integers among the participants. Consequently, most existing DP mechanisms require rather high noise levels, leading to poor model utility. Motivated by this, we propose Skellam mixture mechanism (SMM), an approach to enforce DP on models built via FL. Compared to existing methods, SMM eliminates the assumption that the input gradients must be integer-valued, and, thus, reduces the amount of noise injected to preserve DP. Further, SMM allows tight privacy accounting due to the nice composition and sub-sampling properties of the Skellam distribution, which are key to accurate deep learning with DP. The theoretical analysis of SMM is highly non-trivial, especially considering (i) the complicated math of differentially private deep learning in general and (ii) the fact that the mixture of two Skellam distributions is rather complex, and to our knowledge, has not been studied in the DP literature. Extensive experiments on various practical settings demonstrate that SMM consistently and significantly outperforms existing solutions in terms of the utility of the resulting model.
Sense The Physical, Walkthrough The Virtual, Manage The Metaverse: A Data-centric Perspective
Jun 14, 2022
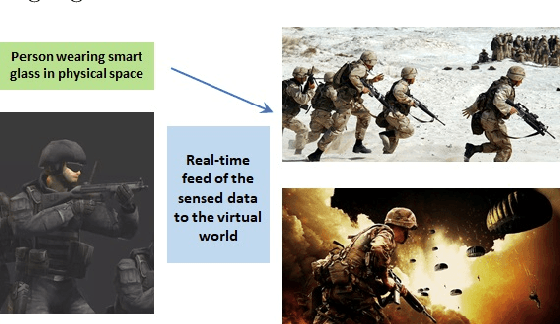
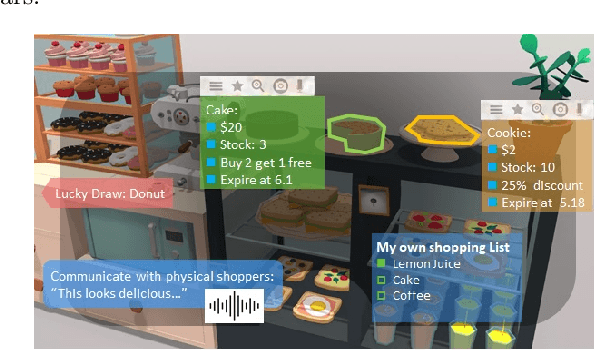

In the Metaverse, the physical space and the virtual space co-exist, and interact simultaneously. While the physical space is virtually enhanced with information, the virtual space is continuously refreshed with real-time, real-world information. To allow users to process and manipulate information seamlessly between the real and digital spaces, novel technologies must be developed. These include smart interfaces, new augmented realities, efficient storage and data management and dissemination techniques. In this paper, we first discuss some promising co-space applications. These applications offer experiences and opportunities that neither of the spaces can realize on its own. We then argue that the database community has much to offer to this field. Finally, we present several challenges that we, as a community, can contribute towards managing the Metaverse.
BoostMIS: Boosting Medical Image Semi-supervised Learning with Adaptive Pseudo Labeling and Informative Active Annotation
Mar 21, 2022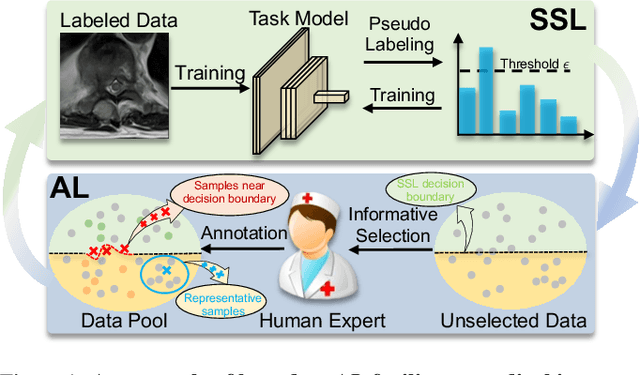
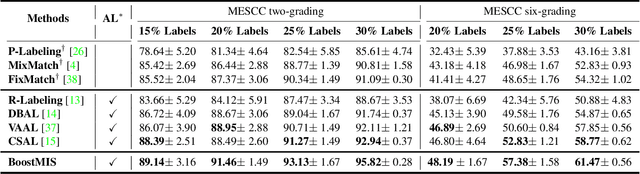
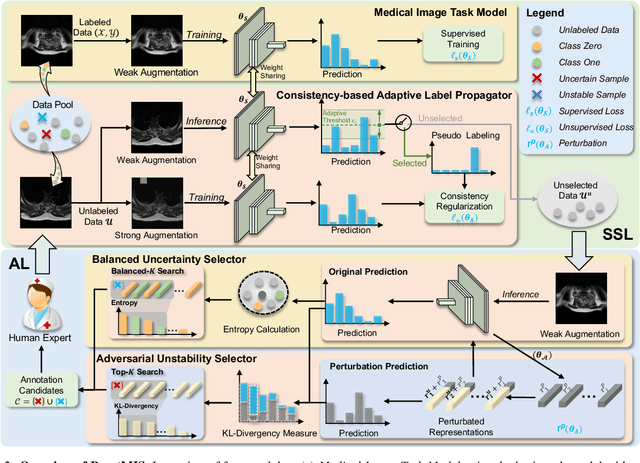
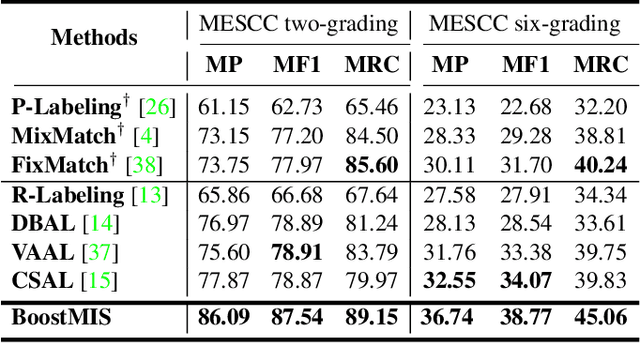
In this paper, we propose a novel semi-supervised learning (SSL) framework named BoostMIS that combines adaptive pseudo labeling and informative active annotation to unleash the potential of medical image SSL models: (1) BoostMIS can adaptively leverage the cluster assumption and consistency regularization of the unlabeled data according to the current learning status. This strategy can adaptively generate one-hot "hard" labels converted from task model predictions for better task model training. (2) For the unselected unlabeled images with low confidence, we introduce an Active learning (AL) algorithm to find the informative samples as the annotation candidates by exploiting virtual adversarial perturbation and model's density-aware entropy. These informative candidates are subsequently fed into the next training cycle for better SSL label propagation. Notably, the adaptive pseudo-labeling and informative active annotation form a learning closed-loop that are mutually collaborative to boost medical image SSL. To verify the effectiveness of the proposed method, we collected a metastatic epidural spinal cord compression (MESCC) dataset that aims to optimize MESCC diagnosis and classification for improved specialist referral and treatment. We conducted an extensive experimental study of BoostMIS on MESCC and another public dataset COVIDx. The experimental results verify our framework's effectiveness and generalisability for different medical image datasets with a significant improvement over various state-of-the-art methods.
* 11 pages