 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Self-Supervised Learning for Recommendation
Mar 21, 2023



Graph neural networks (GNNs) have emerged as the state-of-the-art paradigm for collaborative filtering (CF). To improve the representation quality over limited labeled data, contrastive learning has attracted attention in recommendation and benefited graph-based CF model recently. However, the success of most contrastive methods heavily relies on manually generating effective contrastive views for heuristic-based data augmentation. This does not generalize across different datasets and downstream recommendation tasks, which is difficult to be adaptive for data augmentation and robust to noise perturbation. To fill this crucial gap, this work proposes a unified Automated Collaborative Filtering (AutoCF) to automatically perform data augmentation for recommendation. Specifically, we focus on the generative self-supervised learning framework with a learnable augmentation paradigm that benefits the automated distillation of important self-supervised signals. To enhance the representation discrimination ability, our masked graph autoencoder is designed to aggregate global information during the augmentation via reconstructing the masked subgraph structures. Experiments and ablation studies are performed on several public datasets for recommending products, venues, and locations. Results demonstrate the superiority of AutoCF against various baseline methods. We release the model implementation at https://github.com/HKUDS/AutoCF.
Lexical Knowledge Internalization for Neural Dialog Generation
May 04, 2022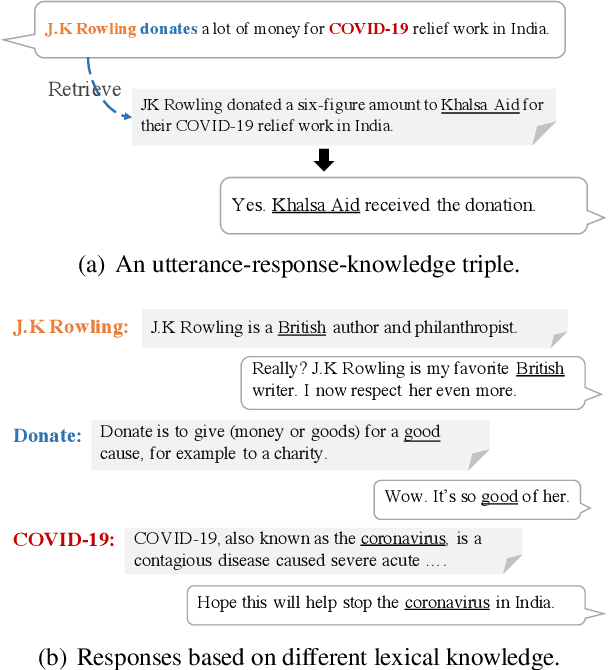
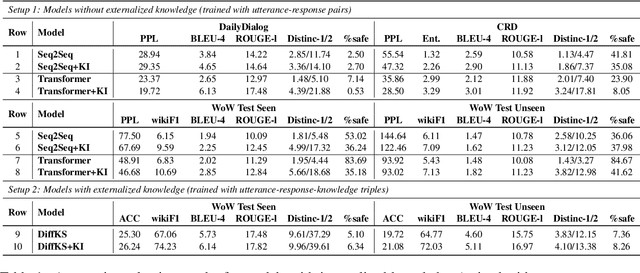

We propose knowledge internalization (KI), which aims to complement the lexical knowledge into neural dialog models. Instead of further conditioning the knowledge-grounded dialog (KGD) models on externally retrieved knowledge, we seek to integrate knowledge about each input token internally into the model's parameters. To tackle the challenge due to the large scale of lexical knowledge, we adopt the contrastive learning approach and create an effective token-level lexical knowledge retriever that requires only weak supervision mined from Wikipedia. We demonstrate the effectiveness and general applicability of our approach on various datasets and diversified model structures.
Reinforced Meta-path Selection for Recommendation on Heterogeneous Information Networks
Dec 28, 2021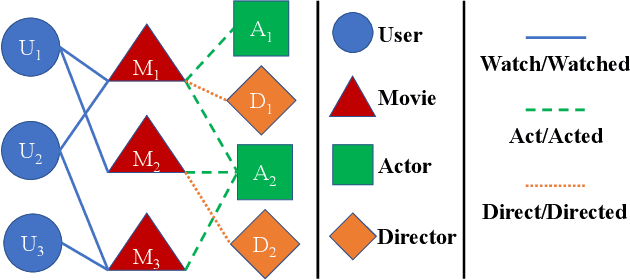
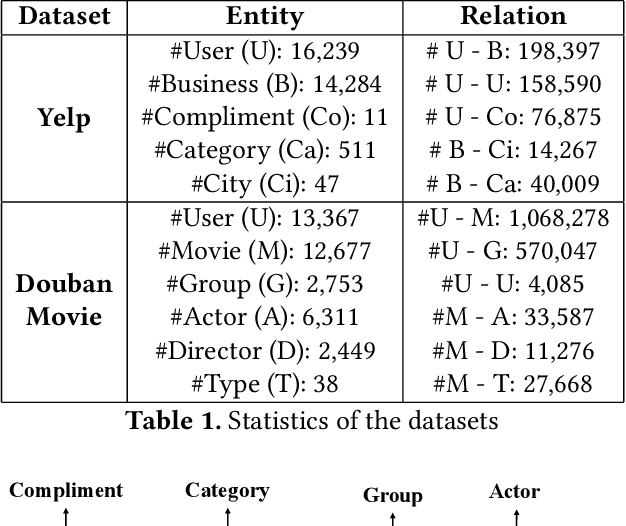
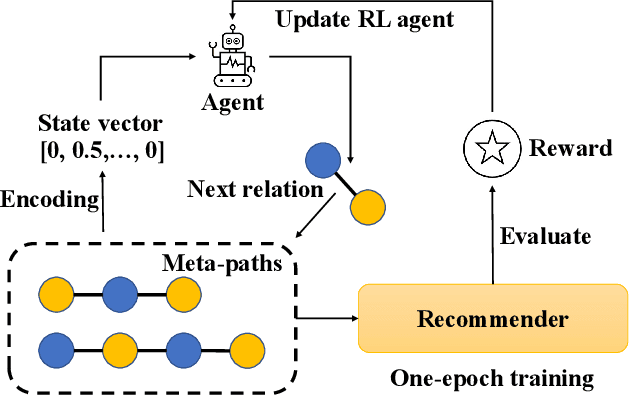
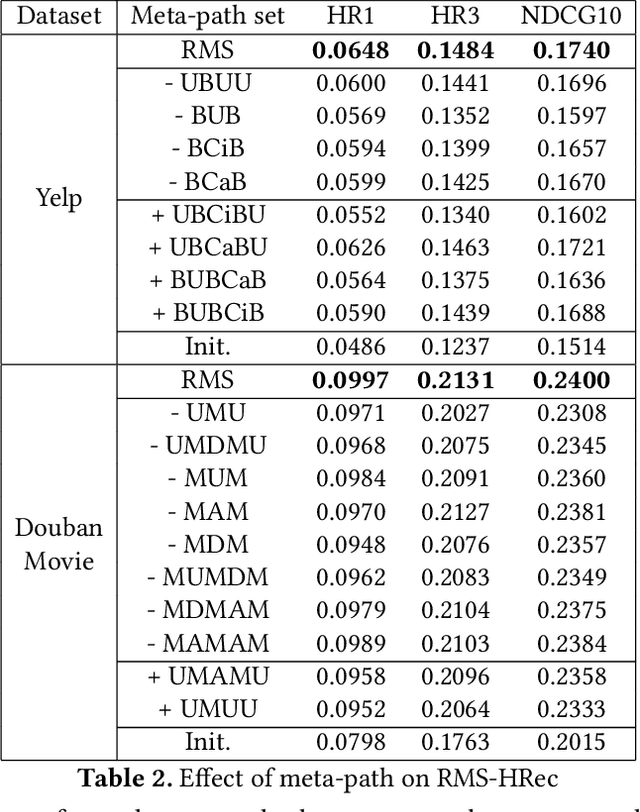
Heterogeneous Information Networks (HINs) capture complex relations among entities of various kinds and have been used extensively to improve the effectiveness of various data mining tasks, such as in recommender systems. Many existing HIN-based recommendation algorithms utilize hand-crafted meta-paths to extract semantic information from the networks. These algorithms rely on extensive domain knowledge with which the best set of meta-paths can be selected. For applications where the HINs are highly complex with numerous node and link types, the approach of hand-crafting a meta-path set is too tedious and error-prone. To tackle this problem, we propose the Reinforcement learning-based Meta-path Selection (RMS) framework to select effective meta-paths and to incorporate them into existing meta-path-based recommenders. To identify high-quality meta-paths, RMS trains a reinforcement learning (RL) based policy network(agent), which gets rewards from the performance on the downstream recommendation tasks. We design a HIN-based recommendation model, HRec, that effectively uses the meta-path information. We further integrate HRec with RMS and derive our recommendation solution, RMS-HRec, that automatically utilizes the effective meta-paths. Experiments on real datasets show that our algorithm can significantly improve the performance of recommendation models by capturing important meta-paths automatically.
Good for Misconceived Reasons: An Empirical Revisiting on the Need for Visual Context in Multimodal Machine Translation
May 30, 2021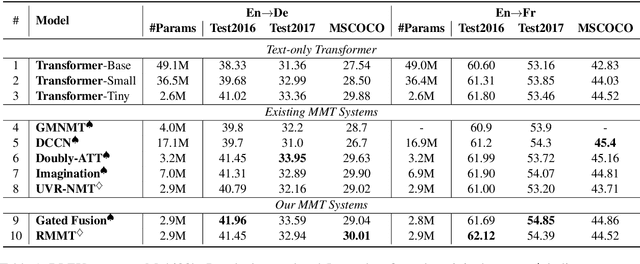
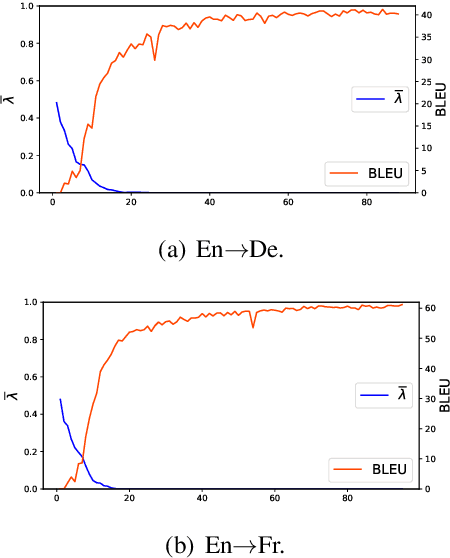
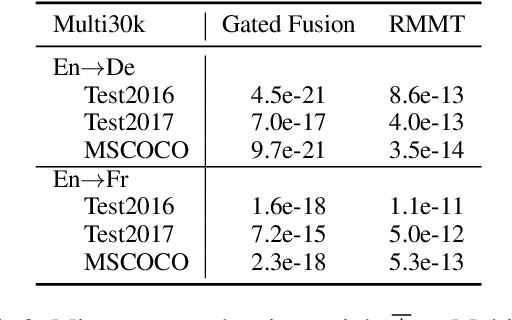
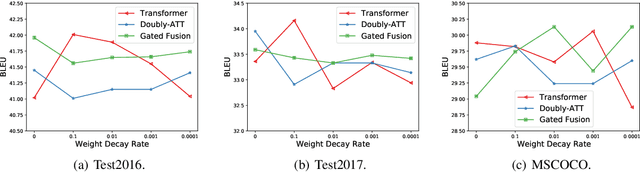
A neural multimodal machine translation (MMT) system is one that aims to perform better translation by extending conventional text-only translation models with multimodal information. Many recent studies report improvements when equipping their models with the multimodal module, despite the controversy of whether such improvements indeed come from the multimodal part. We revisit the contribution of multimodal information in MMT by devising two interpretable MMT models. To our surprise, although our models replicate similar gains as recently developed multimodal-integrated systems achieved, our models learn to ignore the multimodal information. Upon further investigation, we discover that the improvements achieved by the multimodal models over text-only counterparts are in fact results of the regularization effect. We report empirical findings that highlight the importance of MMT models' interpretability, and discuss how our findings will benefit future research.
Leveraging Meta-path Contexts for Classification in Heterogeneous Information Networks
Dec 18, 2020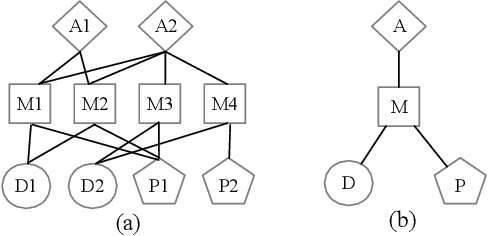
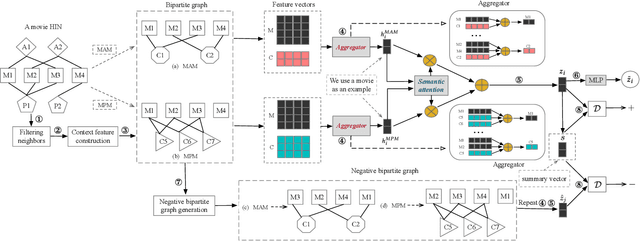
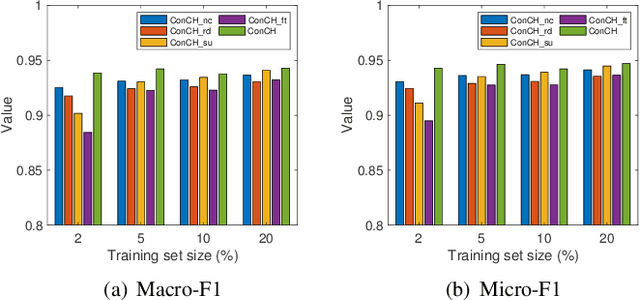
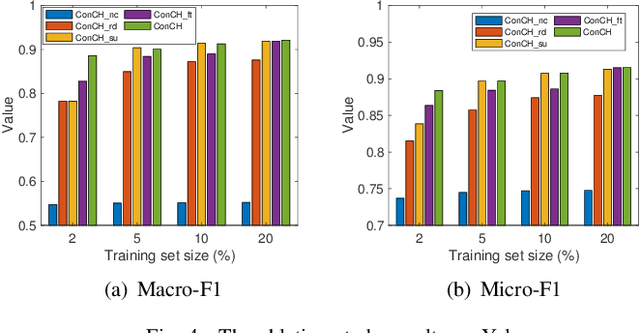
A heterogeneous information network (HIN) has as vertices objects of different types and as edges the relations between objects, which are also of various types. We study the problem of classifying objects in HINs. Most existing methods perform poorly when given scarce labeled objects as training sets, and methods that improve classification accuracy under such scenarios are often computationally expensive. To address these problems, we propose ConCH, a graph neural network model. ConCH formulates the classification problem as a multi-task learning problem that combines semi-supervised learning with self-supervised learning to learn from both labeled and unlabeled data. ConCH employs meta-paths, which are sequences of object types that capture semantic relationships between objects. Based on meta-paths, it considers two sources of information for an object x: (1) Meta-path-based neighbors of x are retrieved and ranked, and the top-k neighbors are retained. (2) The meta-path instances of x to its selected neighbors are used to derive meta-path-based contexts. ConCH utilizes the above information to co-derive object embeddings and context embeddings via graph convolution. It also uses the attention mechanism to fuse the embeddings of x generated from various meta-paths to obtain x's final embedding. We conduct extensive experiments to evaluate the performance of ConCH against other 14 classification methods. Our results show that ConCH is an effective and efficient method for HIN classification.
CAST: A Correlation-based Adaptive Spectral Clustering Algorithm on Multi-scale Data
Jun 08, 2020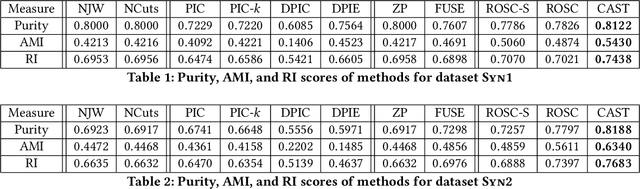
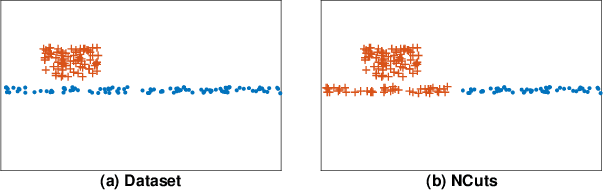
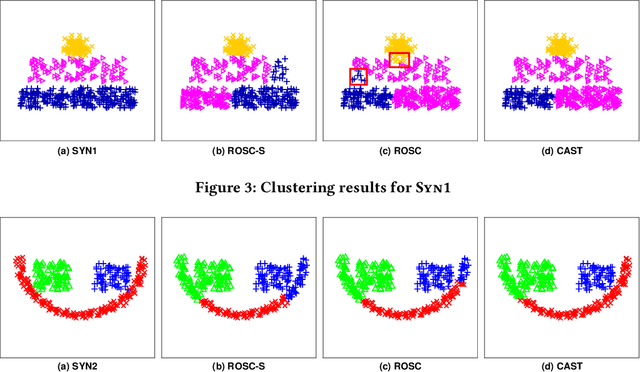
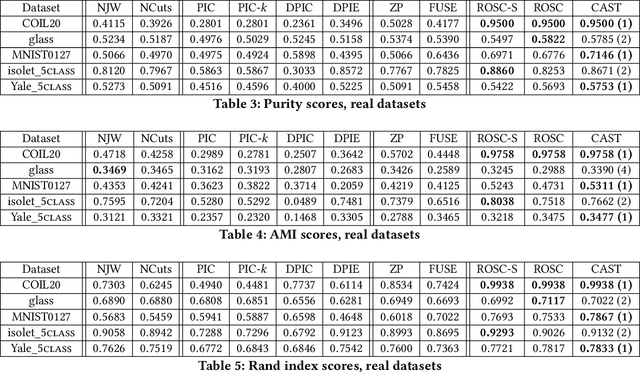
We study the problem of applying spectral clustering to cluster multi-scale data, which is data whose clusters are of various sizes and densities. Traditional spectral clustering techniques discover clusters by processing a similarity matrix that reflects the proximity of objects. For multi-scale data, distance-based similarity is not effective because objects of a sparse cluster could be far apart while those of a dense cluster have to be sufficiently close. Following [16], we solve the problem of spectral clustering on multi-scale data by integrating the concept of objects' "reachability similarity" with a given distance-based similarity to derive an objects' coefficient matrix. We propose the algorithm CAST that applies trace Lasso to regularize the coefficient matrix. We prove that the resulting coefficient matrix has the "grouping effect" and that it exhibits "sparsity". We show that these two characteristics imply very effective spectral clustering. We evaluate CAST and 10 other clustering methods on a wide range of datasets w.r.t. various measures. Experimental results show that CAST provides excellent performance and is highly robust across test cases of multi-scale data.
Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT
Apr 30, 2020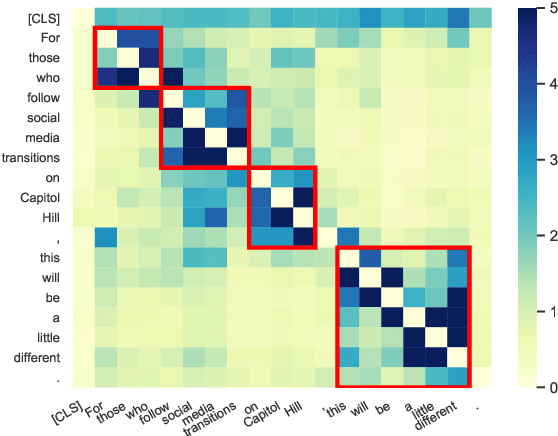
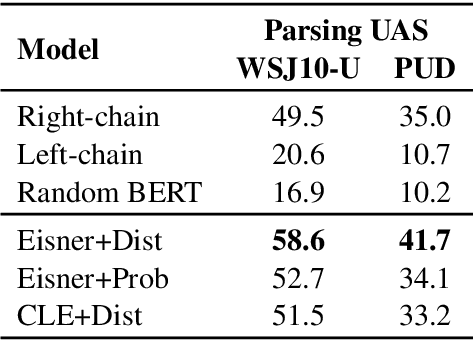
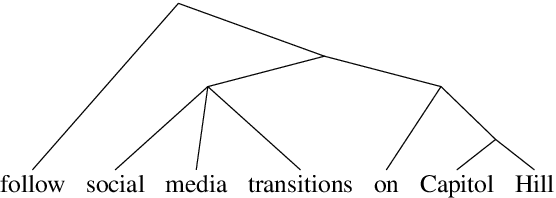
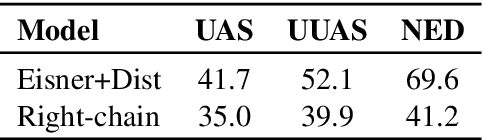
By introducing a small set of additional parameters, a probe learns to solve specific linguistic tasks (e.g., dependency parsing) in a supervised manner using feature representations (e.g., contextualized embeddings). The effectiveness of such probing tasks is taken as evidence that the pre-trained model encodes linguistic knowledge. However, this approach of evaluating a language model is undermined by the uncertainty of the amount of knowledge that is learned by the probe itself. Complementary to those works, we propose a parameter-free probing technique for analyzing pre-trained language models (e.g., BERT). Our method does not require direct supervision from the probing tasks, nor do we introduce additional parameters to the probing process. Our experiments on BERT show that syntactic trees recovered from BERT using our method are significantly better than linguistically-uninformed baselines. We further feed the empirically induced dependency structures into a downstream sentiment classification task and find its improvement compatible with or even superior to a human-designed dependency schema.
Neural Enquirer: Learning to Query Tables with Natural Language
Jan 21, 2016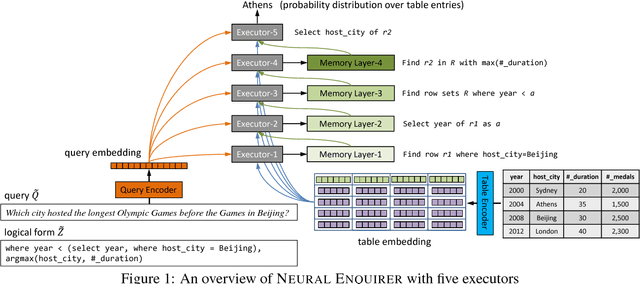
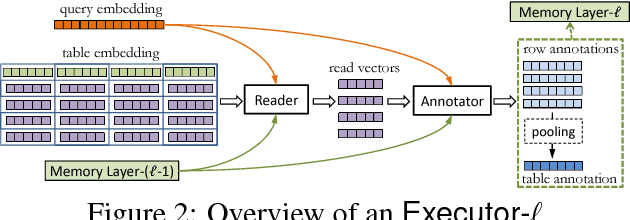
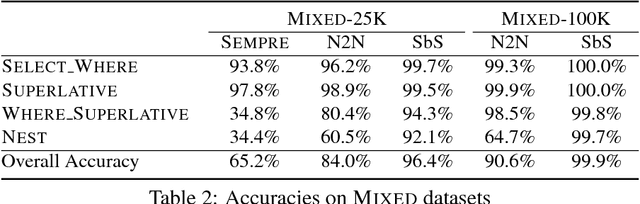
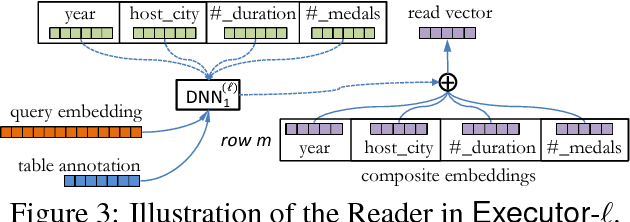
We proposed Neural Enquirer as a neural network architecture to execute a natural language (NL) query on a knowledge-base (KB) for answers. Basically, Neural Enquirer finds the distributed representation of a query and then executes it on knowledge-base tables to obtain the answer as one of the values in the tables. Unlike similar efforts in end-to-end training of semantic parsers, Neural Enquirer is fully "neuralized": it not only gives distributional representation of the query and the knowledge-base, but also realizes the execution of compositional queries as a series of differentiable operations, with intermediate results (consisting of annotations of the tables at different levels) saved on multiple layers of memory. Neural Enquirer can be trained with gradient descent, with which not only the parameters of the controlling components and semantic parsing component, but also the embeddings of the tables and query words can be learned from scratch. The training can be done in an end-to-end fashion, but it can take stronger guidance, e.g., the step-by-step supervision for complicated queries, and benefit from it. Neural Enquirer is one step towards building neural network systems which seek to understand language by executing it on real-world. Our experiments show that Neural Enquirer can learn to execute fairly complicated NL queries on tables with rich structures.