 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Deep Learning Learn to Abstract? A Systematic Probing Framework
Feb 23, 2023



Abstraction is a desirable capability for deep learning models, which means to induce abstract concepts from concrete instances and flexibly apply them beyond the learning context. At the same time, there is a lack of clear understanding about both the presence and further characteristics of this capability in deep learning models. In this paper, we introduce a systematic probing framework to explore the abstraction capability of deep learning models from a transferability perspective. A set of controlled experiments are conducted based on this framework, providing strong evidence that two probed pre-trained language models (PLMs), T5 and GPT2, have the abstraction capability. We also conduct in-depth analysis, thus shedding further light: (1) the whole training phase exhibits a "memorize-then-abstract" two-stage process; (2) the learned abstract concepts are gathered in a few middle-layer attention heads, rather than being evenly distributed throughout the model; (3) the probed abstraction capabilities exhibit robustness against concept mutations, and are more robust to low-level/source-side mutations than high-level/target-side ones; (4) generic pre-training is critical to the emergence of abstraction capability, and PLMs exhibit better abstraction with larger model sizes and data scales.
When Neural Model Meets NL2Code: A Survey
Dec 19, 2022Given a natural language that describes the user's demands, the NL2Code task aims to generate code that addresses the demands. This is a critical but challenging task that mirrors the capabilities of AI-powered programming. The NL2Code task is inherently versatile, diverse and complex. For example, a demand can be described in different languages, in different formats, and at different levels of granularity. This inspired us to do this survey for NL2Code. In this survey, we focus on how does neural network (NN) solves NL2Code. We first propose a comprehensive framework, which is able to cover all studies in this field. Then, we in-depth parse the existing studies into this framework. We create an online website to record the parsing results, which tracks existing and recent NL2Code progress. In addition, we summarize the current challenges of NL2Code as well as its future directions. We hope that this survey can foster the evolution of this field.
When Language Model Meets Private Library
Oct 31, 2022



With the rapid development of pre-training techniques, a number of language models have been pre-trained on large-scale code corpora and perform well in code generation. In this paper, we investigate how to equip pre-trained language models with the ability of code generation for private libraries. In practice, it is common for programmers to write code using private libraries. However, this is a challenge for language models since they have never seen private APIs during training. Motivated by the fact that private libraries usually come with elaborate API documentation, we propose a novel framework with two modules: the APIRetriever finds useful APIs, and then the APICoder generates code using these APIs. For APIRetriever, we present a dense retrieval system and also design a friendly interaction to involve uses. For APICoder, we can directly use off-the-shelf language models, or continually pre-train the base model on a code corpus containing API information. Both modules are trained with data from public libraries and can be generalized to private ones. Furthermore, we craft three benchmarks for private libraries, named TorchDataEval, MonkeyEval, and BeatNumEval. Experimental results demonstrate the impressive performance of our framework.
CodeT: Code Generation with Generated Tests
Jul 21, 2022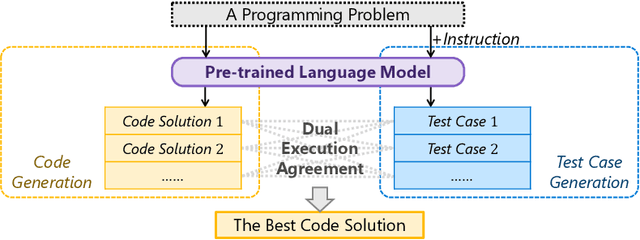
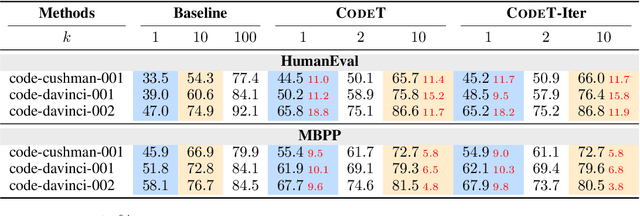

Given a programming problem, pre-trained language models such as Codex have demonstrated the ability to generate multiple different code solutions via sampling. However, selecting a correct or best solution from those samples still remains a challenge. While an easy way to verify the correctness of a code solution is through executing test cases, producing high-quality test cases is prohibitively expensive. In this paper, we explore the use of pre-trained language models to automatically generate test cases, calling our method CodeT: Code generation with generated Tests. CodeT executes the code solutions using the generated test cases, and then chooses the best solution based on a dual execution agreement with both the generated test cases and other generated solutions. We evaluate CodeT on five different pre-trained models with both HumanEval and MBPP benchmarks. Extensive experimental results demonstrate CodeT can achieve significant, consistent, and surprising improvements over previous methods. For example, CodeT improves the pass@1 on HumanEval to 65.8%, an increase of absolute 18.8% on the code-davinci-002 model, and an absolute 20+% improvement over previous state-of-the-art results.
CERT: Continual Pre-Training on Sketches for Library-Oriented Code Generation
Jun 14, 2022
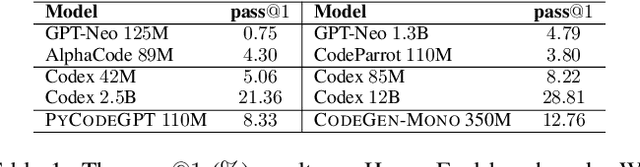

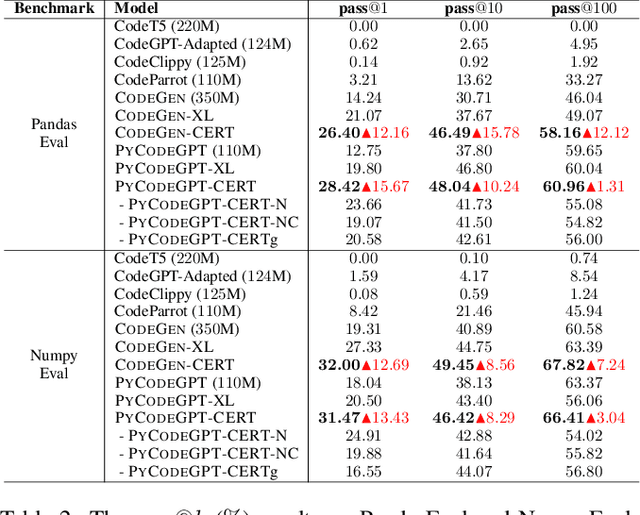
Code generation is a longstanding challenge, aiming to generate a code snippet based on a natural language description. Usually, expensive text-code paired data is essential for training a code generation model. Recently, thanks to the success of pre-training techniques, large language models are trained on large-scale unlabelled code corpora and perform well in code generation. In this paper, we investigate how to leverage an unlabelled code corpus to train a model for library-oriented code generation. Since it is a common practice for programmers to reuse third-party libraries, in which case the text-code paired data are harder to obtain due to the huge number of libraries. We observe that library-oriented code snippets are more likely to share similar code sketches. Hence, we present CERT with two steps: a sketcher generates the sketch, then a generator fills the details in the sketch. Both the sketcher and the generator are continually pre-trained upon a base model using unlabelled data. Furthermore, we craft two benchmarks named PandasEval and NumpyEval to evaluate library-oriented code generation. Experimental results demonstrate the impressive performance of CERT. For example, it surpasses the base model by an absolute 15.67% improvement in terms of pass@1 on PandasEval. Our work is available at https://github.com/microsoft/PyCodeGPT.
On the Advance of Making Language Models Better Reasoners
Jun 07, 2022
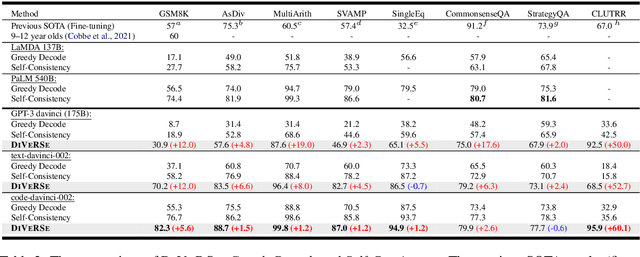

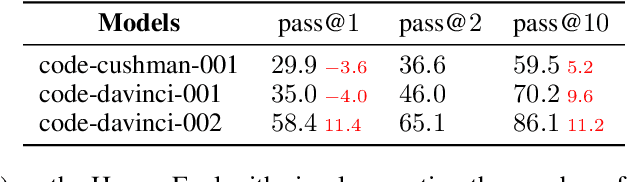
Large language models such as GPT-3 and PaLM have shown remarkable performance in few-shot learning. However, they still struggle with reasoning tasks such as the arithmetic benchmark GSM8K. Recent advances deliberately guide the language model to generate a chain of reasoning steps before producing the final answer, successfully boosting the GSM8K benchmark from 17.9% to 58.1% in terms of problem solving rate. In this paper, we propose a new approach, DiVeRSe (Diverse Verifier on Reasoning Step), to further advance their reasoning capability. DiVeRSe first explores different prompts to enhance the diversity in reasoning paths. Second, DiVeRSe introduces a verifier to distinguish good answers from bad answers for a better weighted voting. Finally, DiVeRSe verifies the correctness of each single step rather than all the steps in a whole. We conduct extensive experiments using the latest language model code-davinci-002 and demonstrate that DiVeRSe can achieve new state-of-the-art performance on six out of eight reasoning benchmarks (e.g., GSM8K 74.4% to 83.2%), outperforming the PaLM model with 540B parameters.
DialogZoo: Large-Scale Dialog-Oriented Task Learning
May 25, 2022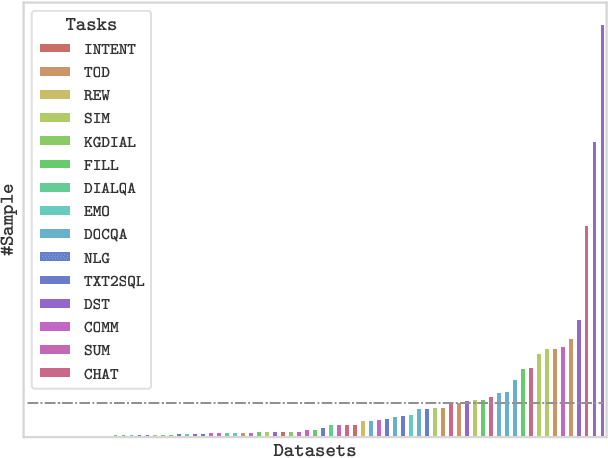
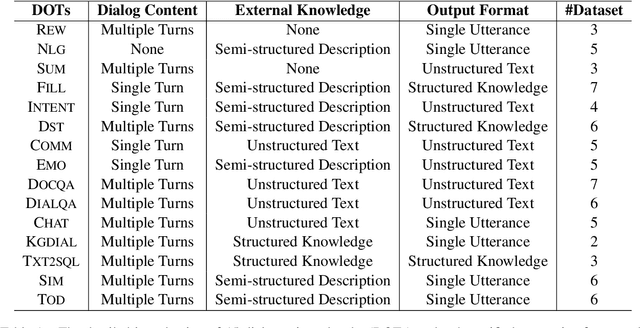
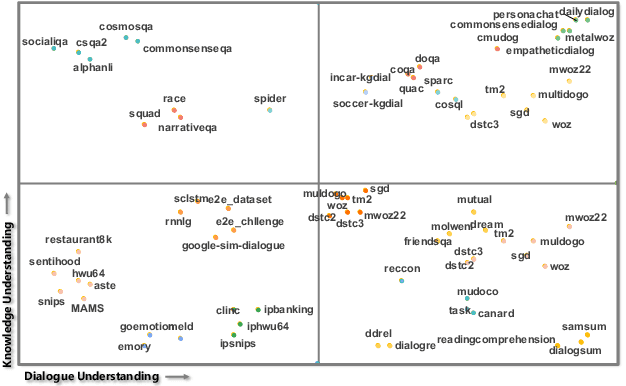
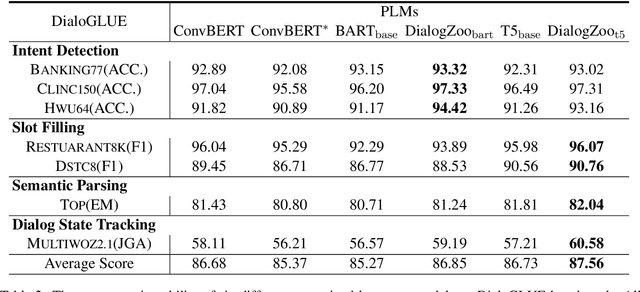
Building unified conversational agents has been a long-standing goal of the dialogue research community. Most previous works only focus on a subset of various dialogue tasks. In this work, we aim to build a unified foundation model which can solve massive diverse dialogue tasks. To achieve this goal, we first collect a large-scale well-labeled dialogue dataset from 73 publicly available datasets. In addition to this dataset, we further propose two dialogue-oriented self-supervised tasks, and finally use the mixture of supervised and self-supervised datasets to train our foundation model. The supervised examples make the model learn task-specific skills, while the self-supervised examples make the model learn more general skills. We evaluate our model on various downstream dialogue tasks. The experimental results show that our method not only improves the ability of dialogue generation and knowledge distillation, but also the representation ability of models.
UniDU: Towards A Unified Generative Dialogue Understanding Framework
Apr 10, 2022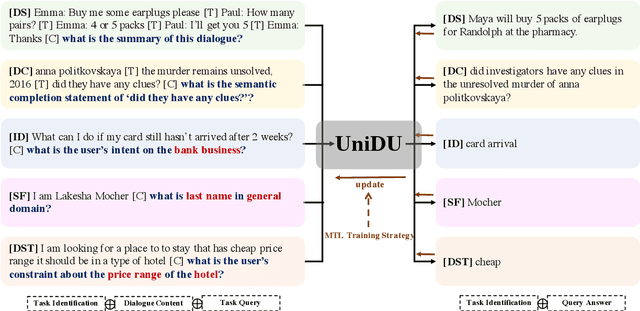
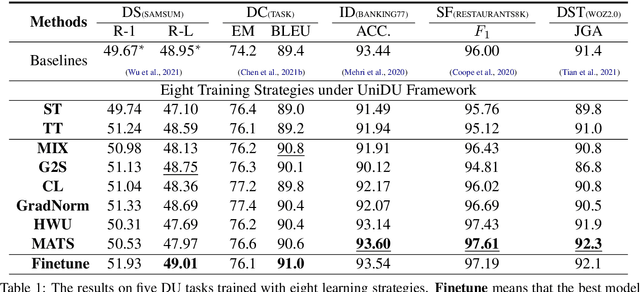

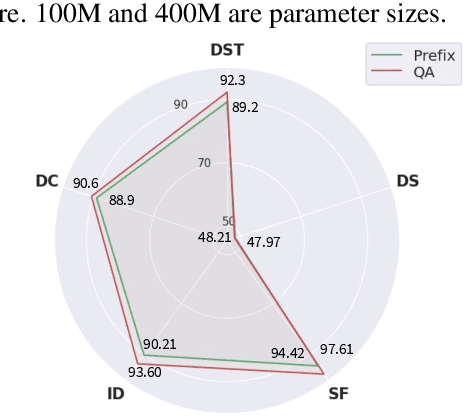
With the development of pre-trained language models, remarkable success has been witnessed in dialogue understanding (DU) direction. However, the current DU approaches just employ an individual model for each DU task, independently, without considering the shared knowledge across different DU tasks. In this paper, we investigate a unified generative dialogue understanding framework, namely UniDU, to achieve information exchange among DU tasks. Specifically, we reformulate the DU tasks into unified generative paradigm. In addition, to consider different training data for each task, we further introduce model-agnostic training strategy to optimize unified model in a balanced manner. We conduct the experiments on ten dialogue understanding datasets, which span five fundamental tasks: dialogue summary, dialogue completion, slot filling, intent detection and dialogue state tracking. The proposed UniDU framework outperforms task-specific well-designed methods on all 5 tasks. We further conduct comprehensive analysis experiments to study the effect factors. The experimental results also show that the proposed method obtains promising performance on unseen dialogue domain.
Input-Tuning: Adapting Unfamiliar Inputs to Frozen Pretrained Models
Mar 07, 2022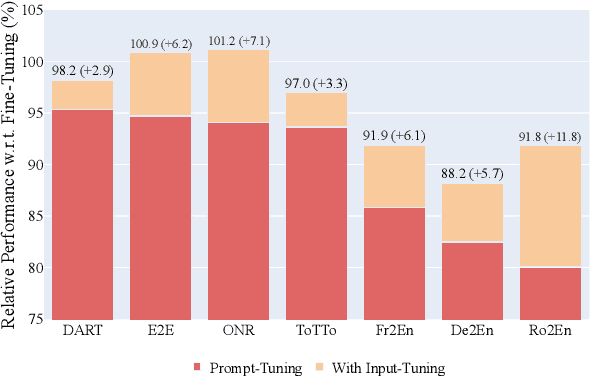

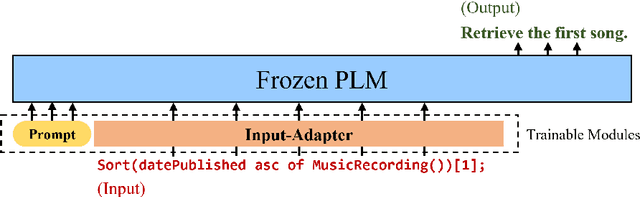
Recently the prompt-tuning paradigm has attracted significant attention. By only tuning continuous prompts with a frozen pre-trained language model (PLM), prompt-tuning takes a step towards deploying a shared frozen PLM to serve numerous downstream tasks. Although prompt-tuning shows good performance on certain natural language understanding (NLU) tasks, its effectiveness on natural language generation (NLG) tasks is still under-explored. In this paper, we argue that one of the factors hindering the development of prompt-tuning on NLG tasks is the unfamiliar inputs (i.e., inputs are linguistically different from the pretraining corpus). For example, our preliminary exploration reveals a large performance gap between prompt-tuning and fine-tuning when unfamiliar inputs occur frequently in NLG tasks. This motivates us to propose input-tuning, which fine-tunes both the continuous prompts and the input representations, leading to a more effective way to adapt unfamiliar inputs to frozen PLMs. Our proposed input-tuning is conceptually simple and empirically powerful. Experimental results on seven NLG tasks demonstrate that input-tuning is significantly and consistently better than prompt-tuning. Furthermore, on three of these tasks, input-tuning can achieve a comparable or even better performance than fine-tuning.
Reasoning Like Program Executors
Jan 27, 2022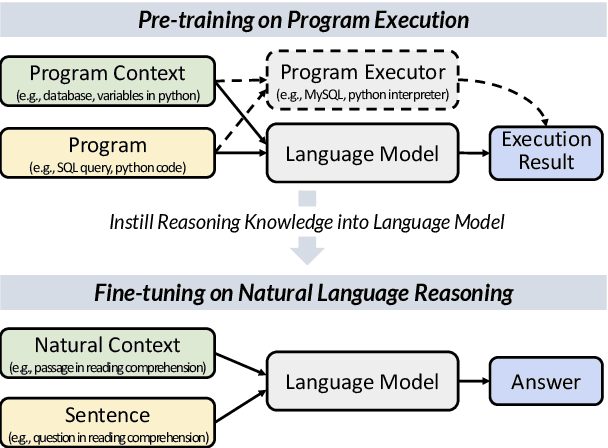

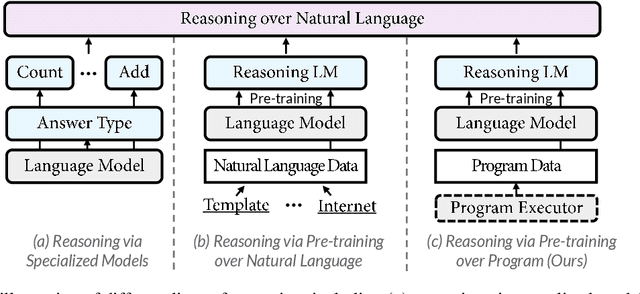
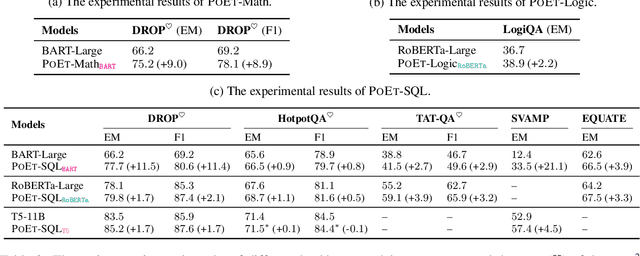
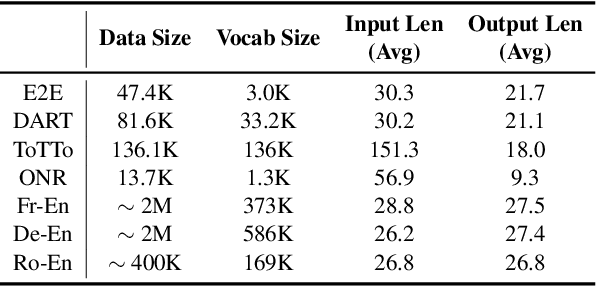
Reasoning over natural language is a long-standing goal for the research community. However, studies have shown that existing language models are inadequate in reasoning. To address the issue, we present POET, a new pre-training paradigm. Through pre-training language models with programs and their execution results, POET empowers language models to harvest the reasoning knowledge possessed in program executors via a data-driven approach. POET is conceptually simple and can be instantiated by different kinds of programs. In this paper, we show three empirically powerful instances, i.e., POET-Math, POET-Logic, and POET-SQL. Experimental results on six benchmarks demonstrate that POET can significantly boost model performance on natural language reasoning, such as numerical reasoning, logical reasoning, and multi-hop reasoning. Taking the DROP benchmark as a representative example, POET improves the F1 metric of BART from 69.2% to 80.6%. Furthermore, POET shines in giant language models, pushing the F1 metric of T5-11B to 87.6% and achieving a new state-of-the-art performance on DROP. POET opens a new gate on reasoning-enhancement pre-training and we hope our analysis would shed light on the future research of reasoning like program executors.