 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState2Explanation: Concept-Based Explanations to Benefit Agent Learning and User Understanding
Sep 21, 2023



With more complex AI systems used by non-AI experts to complete daily tasks, there is an increasing effort to develop methods that produce explanations of AI decision making understandable by non-AI experts. Towards this effort, leveraging higher-level concepts and producing concept-based explanations have become a popular method. Most concept-based explanations have been developed for classification techniques, and we posit that the few existing methods for sequential decision making are limited in scope. In this work, we first contribute a desiderata for defining "concepts" in sequential decision making settings. Additionally, inspired by the Protege Effect which states explaining knowledge often reinforces one's self-learning, we explore the utility of concept-based explanations providing a dual benefit to the RL agent by improving agent learning rate, and to the end-user by improving end-user understanding of agent decision making. To this end, we contribute a unified framework, State2Explanation (S2E), that involves learning a joint embedding model between state-action pairs and concept-based explanations, and leveraging such learned model to both (1) inform reward shaping during an agent's training, and (2) provide explanations to end-users at deployment for improved task performance. Our experimental validations, in Connect 4 and Lunar Lander, demonstrate the success of S2E in providing a dual-benefit, successfully informing reward shaping and improving agent learning rate, as well as significantly improving end user task performance at deployment time.
Don't trust your eyes: on the reliability of feature visualizations
Jun 21, 2023



How do neural networks extract patterns from pixels? Feature visualizations attempt to answer this important question by visualizing highly activating patterns through optimization. Today, visualization methods form the foundation of our knowledge about the internal workings of neural networks, as a type of mechanistic interpretability. Here we ask: How reliable are feature visualizations? We start our investigation by developing network circuits that trick feature visualizations into showing arbitrary patterns that are completely disconnected from normal network behavior on natural input. We then provide evidence for a similar phenomenon occurring in standard, unmanipulated networks: feature visualizations are processed very differently from standard input, casting doubt on their ability to "explain" how neural networks process natural images. We underpin this empirical finding by theory proving that the set of functions that can be reliably understood by feature visualization is extremely small and does not include general black-box neural networks. Therefore, a promising way forward could be the development of networks that enforce certain structures in order to ensure more reliable feature visualizations.
Gaussian Process Probes (GPP) for Uncertainty-Aware Probing
May 29, 2023



Understanding which concepts models can and cannot represent has been fundamental to many tasks: from effective and responsible use of models to detecting out of distribution data. We introduce Gaussian process probes (GPP), a unified and simple framework for probing and measuring uncertainty about concepts represented by models. As a Bayesian extension of linear probing methods, GPP asks what kind of distribution over classifiers (of concepts) is induced by the model. This distribution can be used to measure both what the model represents and how confident the probe is about what the model represents. GPP can be applied to any pre-trained model with vector representations of inputs (e.g., activations). It does not require access to training data, gradients, or the architecture. We validate GPP on datasets containing both synthetic and real images. Our experiments show it can (1) probe a model's representations of concepts even with a very small number of examples, (2) accurately measure both epistemic uncertainty (how confident the probe is) and aleatory uncertainty (how fuzzy the concepts are to the model), and (3) detect out of distribution data using those uncertainty measures as well as classic methods do. By using Gaussian processes to expand what probing can offer, GPP provides a data-efficient, versatile and uncertainty-aware tool for understanding and evaluating the capabilities of machine learning models.
Model evaluation for extreme risks
May 24, 2023



Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through "dangerous capability evaluations") and the propensity of models to apply their capabilities for harm (through "alignment evaluations"). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models
Jan 10, 2023



Language models are known to learn a great quantity of factual information during pretraining, and recent work localizes this information to specific model weights like mid-layer MLP weights (Meng et al., 2022). In this paper, we find that we can change how a fact is stored in a model by editing weights that are in a different location than where existing methods suggest that the fact is stored. This is surprising because we would expect that localizing facts to specific parameters in models would tell us where to manipulate knowledge in models, and this assumption has motivated past work on model editing methods. Specifically, we show that localization conclusions from representation denoising (also known as Causal Tracing) do not provide any insight into which model MLP layer would be best to edit in order to override an existing stored fact with a new one. This finding raises questions about how past work relies on Causal Tracing to select which model layers to edit (Meng et al., 2022). Next, to better understand the discrepancy between representation denoising and weight editing, we develop several variants of the editing problem that appear more and more like representation denoising in their design and objective. Experiments show that, for one of our editing problems, editing performance does relate to localization results from representation denoising, but we find that which layer we edit is a far better predictor of performance. Our results suggest, counterintuitively, that better mechanistic understanding of how pretrained language models work may not always translate to insights about how to best change their behavior. Code is available at: https://github.com/google/belief-localization
Impossibility Theorems for Feature Attribution
Dec 22, 2022



Despite a sea of interpretability methods that can produce plausible explanations, the field has also empirically seen many failure cases of such methods. In light of these results, it remains unclear for practitioners how to use these methods and choose between them in a principled way. In this paper, we show that for even moderately rich model classes (easily satisfied by neural networks), any feature attribution method that is complete and linear--for example, Integrated Gradients and SHAP--can provably fail to improve on random guessing for inferring model behaviour. Our results apply to common end-tasks such as identifying local model behaviour, spurious feature identification, and algorithmic recourse. One takeaway from our work is the importance of concretely defining end-tasks. In particular, we show that once such an end-task is defined, a simple and direct approach of repeated model evaluations can outperform many other complex feature attribution methods.
On the Relationship Between Explanation and Prediction: A Causal View
Dec 20, 2022



Explainability has become a central requirement for the development, deployment, and adoption of machine learning (ML) models and we are yet to understand what explanation methods can and cannot do. Several factors such as data, model prediction, hyperparameters used in training the model, and random initialization can all influence downstream explanations. While previous work empirically hinted that explanations (E) may have little relationship with the prediction (Y), there is a lack of conclusive study to quantify this relationship. Our work borrows tools from causal inference to systematically assay this relationship. More specifically, we measure the relationship between E and Y by measuring the treatment effect when intervening on their causal ancestors (hyperparameters) (inputs to generate saliency-based Es or Ys). We discover that Y's relative direct influence on E follows an odd pattern; the influence is higher in the lowest-performing models than in mid-performing models, and it then decreases in the top-performing models. We believe our work is a promising first step towards providing better guidance for practitioners who can make more informed decisions in utilizing these explanations by knowing what factors are at play and how they relate to their end task.
Post hoc Explanations may be Ineffective for Detecting Unknown Spurious Correlation
Dec 09, 2022



We investigate whether three types of post hoc model explanations--feature attribution, concept activation, and training point ranking--are effective for detecting a model's reliance on spurious signals in the training data. Specifically, we consider the scenario where the spurious signal to be detected is unknown, at test-time, to the user of the explanation method. We design an empirical methodology that uses semi-synthetic datasets along with pre-specified spurious artifacts to obtain models that verifiably rely on these spurious training signals. We then provide a suite of metrics that assess an explanation method's reliability for spurious signal detection under various conditions. We find that the post hoc explanation methods tested are ineffective when the spurious artifact is unknown at test-time especially for non-visible artifacts like a background blur. Further, we find that feature attribution methods are susceptible to erroneously indicating dependence on spurious signals even when the model being explained does not rely on spurious artifacts. This finding casts doubt on the utility of these approaches, in the hands of a practitioner, for detecting a model's reliance on spurious signals.
Beyond Rewards: a Hierarchical Perspective on Offline Multiagent Behavioral Analysis
Jun 17, 2022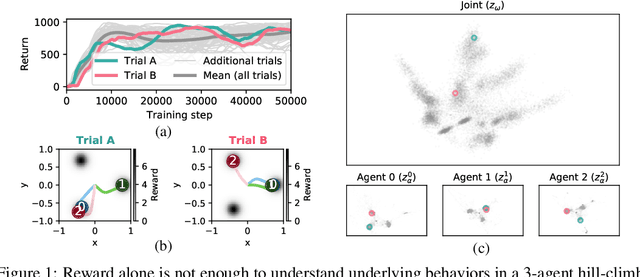
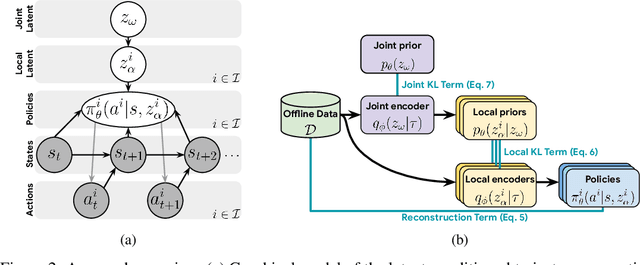
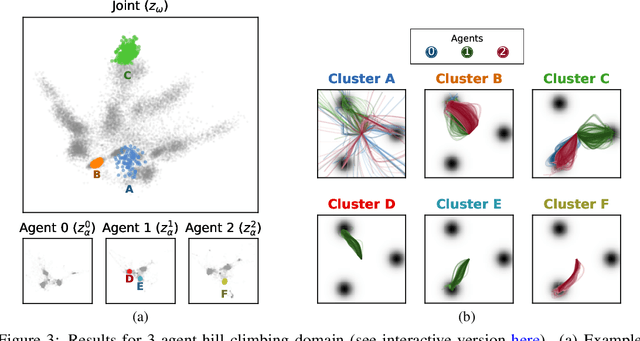

Each year, expert-level performance is attained in increasingly-complex multiagent domains, notable examples including Go, Poker, and StarCraft II. This rapid progression is accompanied by a commensurate need to better understand how such agents attain this performance, to enable their safe deployment, identify limitations, and reveal potential means of improving them. In this paper we take a step back from performance-focused multiagent learning, and instead turn our attention towards agent behavior analysis. We introduce a model-agnostic method for discovery of behavior clusters in multiagent domains, using variational inference to learn a hierarchy of behaviors at the joint and local agent levels. Our framework makes no assumption about agents' underlying learning algorithms, does not require access to their latent states or models, and can be trained using entirely offline observational data. We illustrate the effectiveness of our method for enabling the coupled understanding of behaviors at the joint and local agent level, detection of behavior changepoints throughout training, discovery of core behavioral concepts (e.g., those that facilitate higher returns), and demonstrate the approach's scalability to a high-dimensional multiagent MuJoCo control domain.
Human-Centered Concept Explanations for Neural Networks
Feb 25, 2022
Understanding complex machine learning models such as deep neural networks with explanations is crucial in various applications. Many explanations stem from the model perspective, and may not necessarily effectively communicate why the model is making its predictions at the right level of abstraction. For example, providing importance weights to individual pixels in an image can only express which parts of that particular image are important to the model, but humans may prefer an explanation which explains the prediction by concept-based thinking. In this work, we review the emerging area of concept based explanations. We start by introducing concept explanations including the class of Concept Activation Vectors (CAV) which characterize concepts using vectors in appropriate spaces of neural activations, and discuss different properties of useful concepts, and approaches to measure the usefulness of concept vectors. We then discuss approaches to automatically extract concepts, and approaches to address some of their caveats. Finally, we discuss some case studies that showcase the utility of such concept-based explanations in synthetic settings and real world applications.