 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025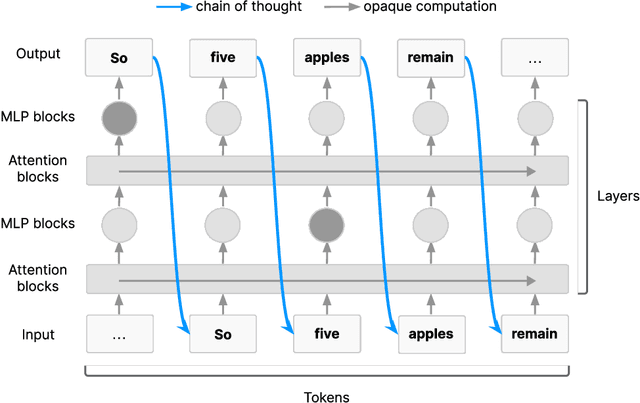
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Towards evaluations-based safety cases for AI scheming
Nov 07, 2024



We sketch how developers of frontier AI systems could construct a structured rationale -- a 'safety case' -- that an AI system is unlikely to cause catastrophic outcomes through scheming. Scheming is a potential threat model where AI systems could pursue misaligned goals covertly, hiding their true capabilities and objectives. In this report, we propose three arguments that safety cases could use in relation to scheming. For each argument we sketch how evidence could be gathered from empirical evaluations, and what assumptions would need to be met to provide strong assurance. First, developers of frontier AI systems could argue that AI systems are not capable of scheming (Scheming Inability). Second, one could argue that AI systems are not capable of posing harm through scheming (Harm Inability). Third, one could argue that control measures around the AI systems would prevent unacceptable outcomes even if the AI systems intentionally attempted to subvert them (Harm Control). Additionally, we discuss how safety cases might be supported by evidence that an AI system is reasonably aligned with its developers (Alignment). Finally, we point out that many of the assumptions required to make these safety arguments have not been confidently satisfied to date and require making progress on multiple open research problems.
Taken out of context: On measuring situational awareness in LLMs
Sep 01, 2023We aim to better understand the emergence of `situational awareness' in large language models (LLMs). A model is situationally aware if it's aware that it's a model and can recognize whether it's currently in testing or deployment. Today's LLMs are tested for safety and alignment before they are deployed. An LLM could exploit situational awareness to achieve a high score on safety tests, while taking harmful actions after deployment. Situational awareness may emerge unexpectedly as a byproduct of model scaling. One way to better foresee this emergence is to run scaling experiments on abilities necessary for situational awareness. As such an ability, we propose `out-of-context reasoning' (in contrast to in-context learning). We study out-of-context reasoning experimentally. First, we finetune an LLM on a description of a test while providing no examples or demonstrations. At test time, we assess whether the model can pass the test. To our surprise, we find that LLMs succeed on this out-of-context reasoning task. Their success is sensitive to the training setup and only works when we apply data augmentation. For both GPT-3 and LLaMA-1, performance improves with model size. These findings offer a foundation for further empirical study, towards predicting and potentially controlling the emergence of situational awareness in LLMs. Code is available at: https://github.com/AsaCooperStickland/situational-awareness-evals.
Model evaluation for extreme risks
May 24, 2023



Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through "dangerous capability evaluations") and the propensity of models to apply their capabilities for harm (through "alignment evaluations"). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.